 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extensions of Karger's Algorithm: Why They Fail in Theory and How They Are Useful in Practice
Oct 05, 2021
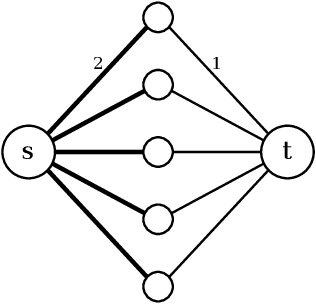
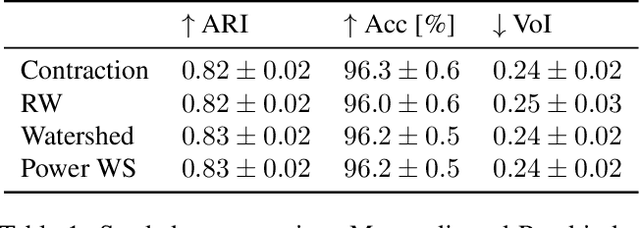
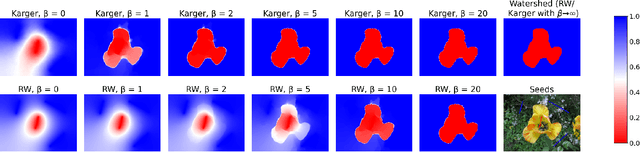
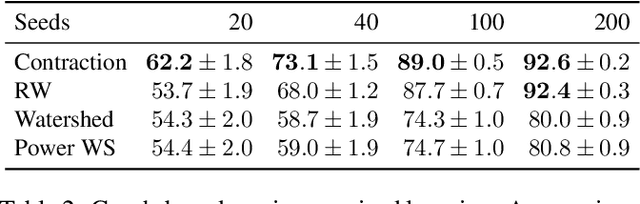
The minimum graph cut and minimum $s$-$t$-cut problems are important primitives in the modeling of combinatorial problems in computer science, including in computer vision and machine learning. Some of the most efficient algorithms for finding global minimum cuts are randomized algorithms based on Karger's groundbreaking contraction algorithm. Here, we study whether Karger's algorithm can be successfully generalized to other cut problems. We first prove that a wide class of natural generalizations of Karger's algorithm cannot efficiently solve the $s$-$t$-mincut or the normalized cut problem to optimality. However, we then present a simple new algorithm for seeded segmentation / graph-based semi-supervised learning that is closely based on Karger's original algorithm, showing that for these problems, extensions of Karger's algorithm can be useful. The new algorithm has linear asymptotic runtime and yields a potential that can be interpreted as the posterior probability of a sample belonging to a given seed / class. We clarify its relation to the random walker algorithm / harmonic energy minimization in terms of distributions over spanning forests. On classical problems from seeded image segmentation and graph-based semi-supervised learning on image data, the method performs at least as well as the random walker / harmonic energy minimization / Gaussian processes.
Detection of Large Vessel Occlusions using Deep Learning by Deforming Vessel Tree Segmentations
Dec 10, 2021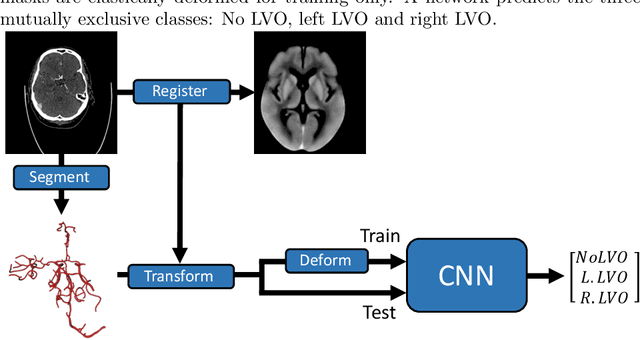
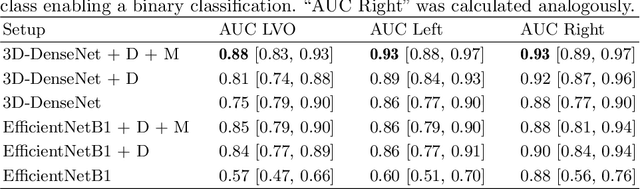
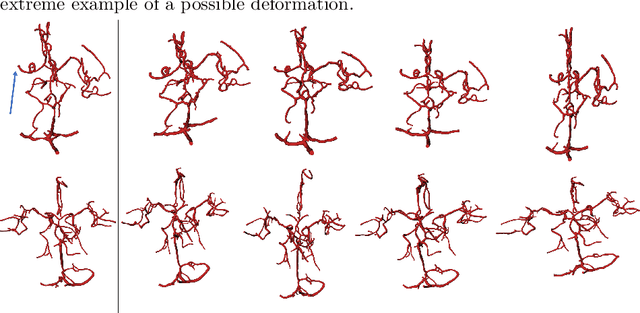
Computed Tomography Angiography is a key modality providing insights into the cerebrovascular vessel tree that are crucial for the diagnosis and treatment of ischemic strokes, in particular in cases of large vessel occlusions (LVO). Thus, the clinical workflow greatly benefits from an automated detection of patients suffering from LVOs. This work uses convolutional neural networks for case-level classification trained with elastic deformation of the vessel tree segmentation masks to artificially augment training data. Using only masks as the input to our model uniquely allows us to apply such deformations much more aggressively than one could with conventional image volumes while retaining sample realism. The neural network classifies the presence of an LVO and the affected hemisphere. In a 5-fold cross validated ablation study, we demonstrate that the use of the suggested augmentation enables us to train robust models even from few data sets. Training the EfficientNetB1 architecture on 100 data sets, the proposed augmentation scheme was able to raise the ROC AUC to 0.85 from a baseline value of 0.56 using no augmentation. The best performance was achieved using a 3D-DenseNet yielding an AUC of 0.87. The augmentation had positive impact in classification of the affected hemisphere as well, where the 3D-DenseNet reached an AUC of 0.93 on both sides.
Network-Aware 5G Edge Computing for Object Detection: Augmenting Wearables to "See'' More, Farther and Faster
Dec 25, 2021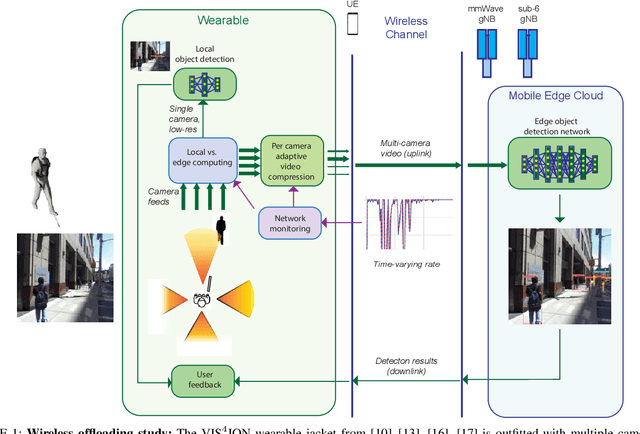
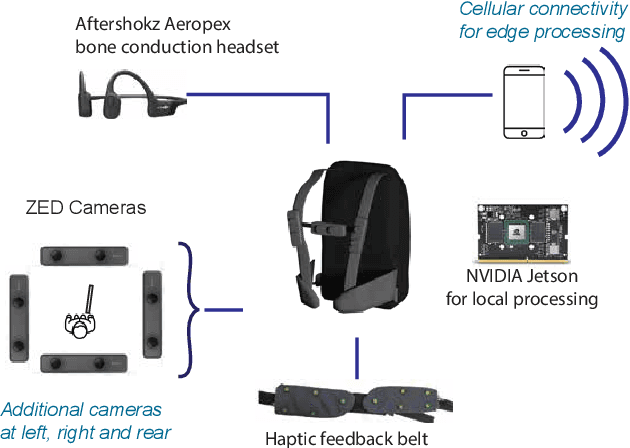
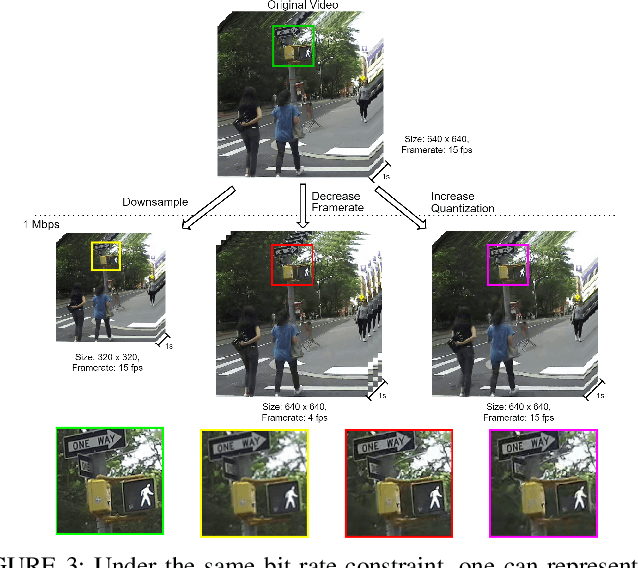
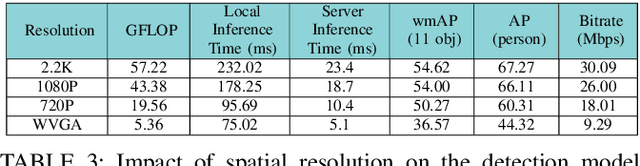
Advanced wearable devices are increasingly incorporating high-resolution multi-camera systems. As state-of-the-art neural networks for processing the resulting image data are computationally demanding, there has been growing interest in leveraging fifth generation (5G) wireless connectivity and mobile edge computing for offloading this processing to the cloud. To assess this possibility, this paper presents a detailed simulation and evaluation of 5G wireless offloading for object detection within a powerful, new smart wearable called VIS4ION, for the Blind-and-Visually Impaired (BVI). The current VIS4ION system is an instrumented book-bag with high-resolution cameras, vision processing and haptic and audio feedback. The paper considers uploading the camera data to a mobile edge cloud to perform real-time object detection and transmitting the detection results back to the wearable. To determine the video requirements, the paper evaluates the impact of video bit rate and resolution on object detection accuracy and range. A new street scene dataset with labeled objects relevant to BVI navigation is leveraged for analysis. The vision evaluation is combined with a detailed full-stack wireless network simulation to determine the distribution of throughputs and delays with real navigation paths and ray-tracing from new high-resolution 3D models in an urban environment. For comparison, the wireless simulation considers both a standard 4G-Long Term Evolution (LTE) carrier and high-rate 5G millimeter-wave (mmWave) carrier. The work thus provides a thorough and realistic assessment of edge computing with mmWave connectivity in an application with both high bandwidth and low latency requirements.
An Auto-Encoder Strategy for Adaptive Image Segmentation
Apr 29, 2020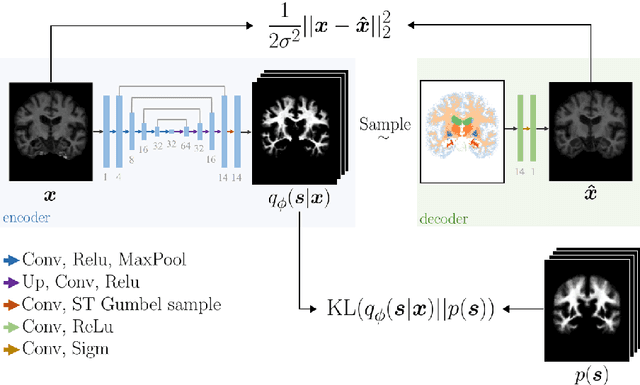
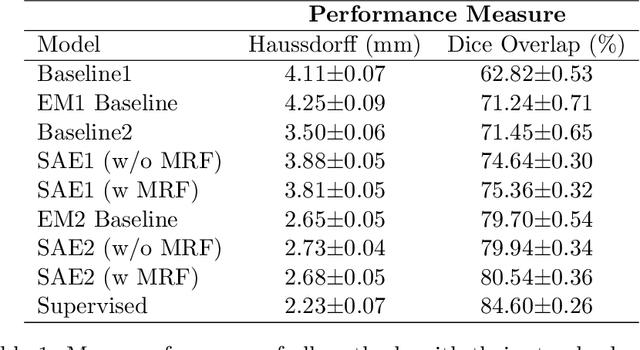
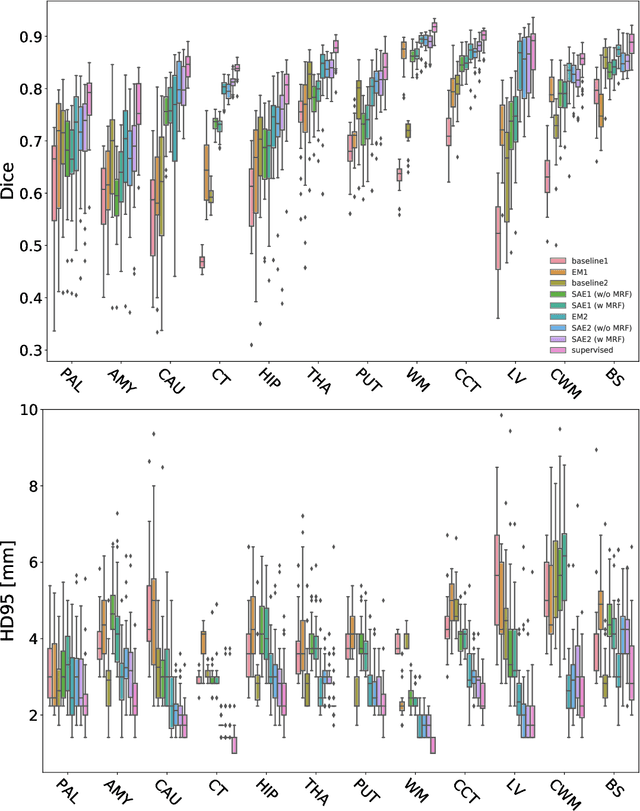
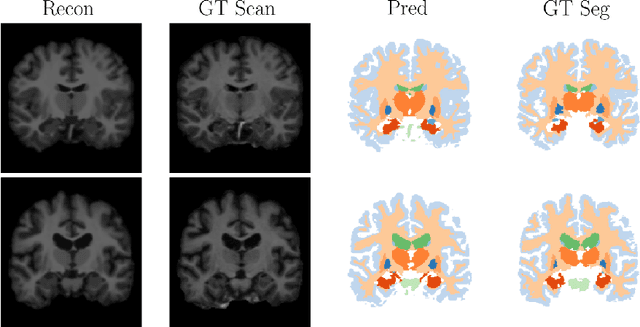
Deep neural networks are powerful tools for biomedical image segmentation. These models are often trained with heavy supervision, relying on pairs of images and corresponding voxel-level labels. However, obtaining segmentations of anatomical regions on a large number of cases can be prohibitively expensive. Thus there is a strong need for deep learning-based segmentation tools that do not require heavy supervision and can continuously adapt. In this paper, we propose a novel perspective of segmentation as a discrete representation learning problem, and present a variational autoencoder segmentation strategy that is flexible and adaptive. Our method, called Segmentation Auto-Encoder (SAE), leverages all available unlabeled scans and merely requires a segmentation prior, which can be a single unpaired segmentation image. In experiments, we apply SAE to brain MRI scans. Our results show that SAE can produce good quality segmentations, particularly when the prior is good. We demonstrate that a Markov Random Field prior can yield significantly better results than a spatially independent prior. Our code is freely available at https://github.com/evanmy/sae.
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles
Sep 28, 2021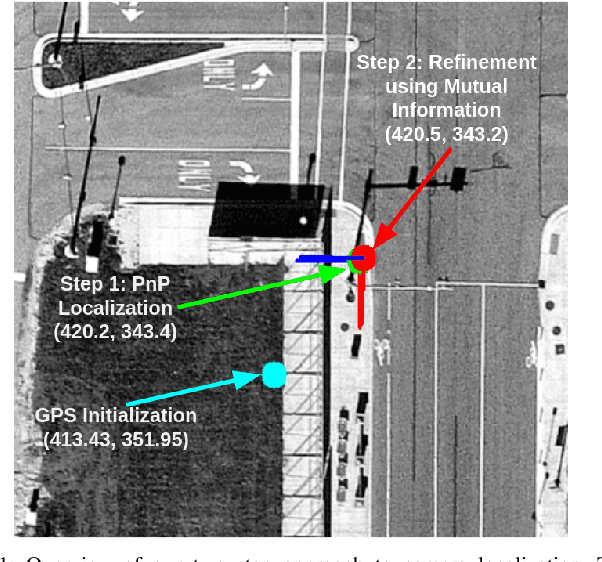


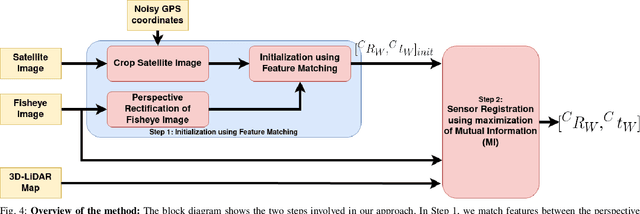
This work presents a technique for localization of a smart infrastructure node, consisting of a fisheye camera, in a prior map. These cameras can detect objects that are outside the line of sight of the autonomous vehicles (AV) and send that information to AVs using V2X technology. However, in order for this information to be of any use to the AV, the detected objects should be provided in the reference frame of the prior map that the AV uses for its own navigation. Therefore, it is important to know the accurate pose of the infrastructure camera with respect to the prior map. Here we propose to solve this localization problem in two steps, \textit{(i)} we perform feature matching between perspective projection of fisheye image and bird's eye view (BEV) satellite imagery from the prior map to estimate an initial camera pose, \textit{(ii)} we refine the initialization by maximizing the Mutual Information (MI) between intensity of pixel values of fisheye image and reflectivity of 3D LiDAR points in the map data. We validate our method on simulated data and also present results with real world data.
Color Image Segmentation using Adaptive Particle Swarm Optimization and Fuzzy C-means
Apr 18, 2020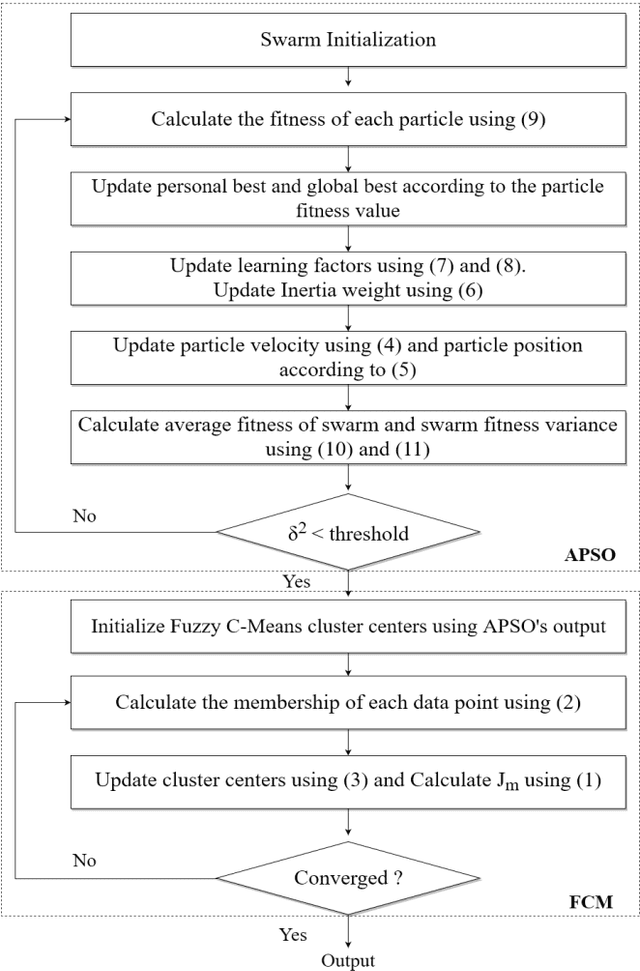

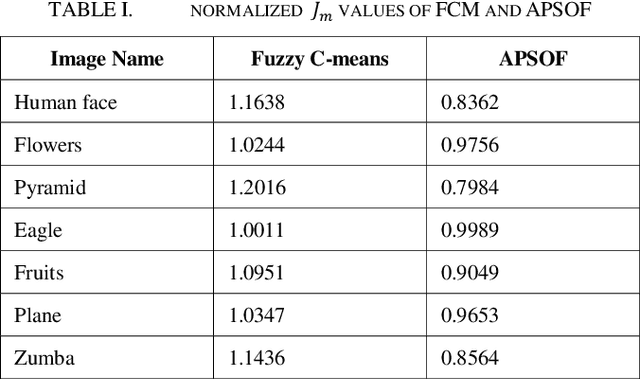
Segmentation partitions an image into different regions containing pixels with similar attributes. A standard non-contextual variant of Fuzzy C-means clustering algorithm (FCM), considering its simplicity is generally used in image segmentation. Using FCM has its disadvantages like it is dependent on the initial guess of the number of clusters and highly sensitive to noise. Satisfactory visual segments cannot be obtained using FCM. Particle Swarm Optimization (PSO) belongs to the class of evolutionary algorithms and has good convergence speed and fewer parameters compared to Genetic Algorithms (GAs). An optimized version of PSO can be combined with FCM to act as a proper initializer for the algorithm thereby reducing its sensitivity to initial guess. A hybrid PSO algorithm named Adaptive Particle Swarm Optimization (APSO) which improves in the calculation of various hyper parameters like inertia weight, learning factors over standard PSO, using insights from swarm behaviour, leading to improvement in cluster quality can be used. This paper presents a new image segmentation algorithm called Adaptive Particle Swarm Optimization and Fuzzy C-means Clustering Algorithm (APSOF), which is based on Adaptive Particle Swarm Optimization (APSO) and Fuzzy C-means clustering. Experimental results show that APSOF algorithm has edge over FCM in correctly identifying the optimum cluster centers, there by leading to accurate classification of the image pixels. Hence, APSOF algorithm has superior performance in comparison with classic Particle Swarm Optimization (PSO) and Fuzzy C-means clustering algorithm (FCM) for image segmentation.
TermiNeRF: Ray Termination Prediction for Efficient Neural Rendering
Nov 05, 2021
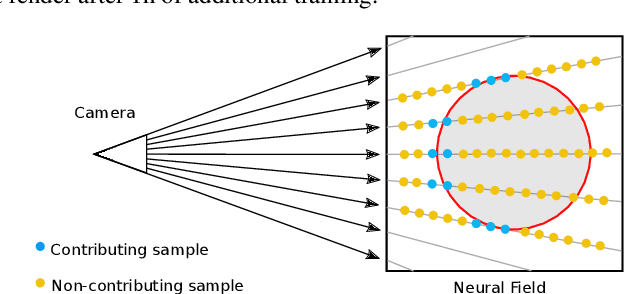

Volume rendering using neural fields has shown great promise in capturing and synthesizing novel views of 3D scenes. However, this type of approach requires querying the volume network at multiple points along each viewing ray in order to render an image, resulting in very slow rendering times. In this paper, we present a method that overcomes this limitation by learning a direct mapping from camera rays to locations along the ray that are most likely to influence the pixel's final appearance. Using this approach we are able to render, train and fine-tune a volumetrically-rendered neural field model an order of magnitude faster than standard approaches. Unlike existing methods, our approach works with general volumes and can be trained end-to-end.
Signature Verification using Geometrical Features and Artificial Neural Network Classifier
Aug 04, 2021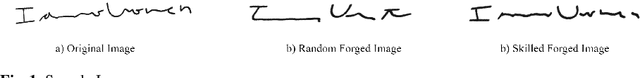
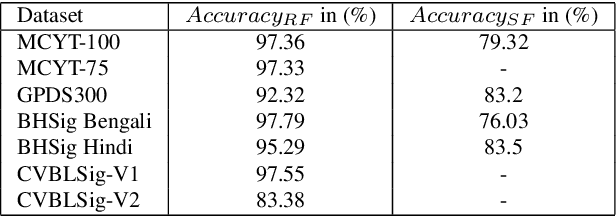
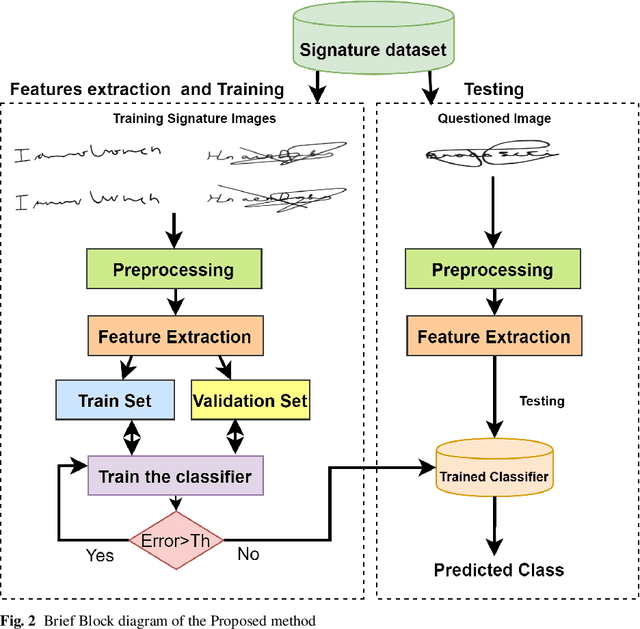
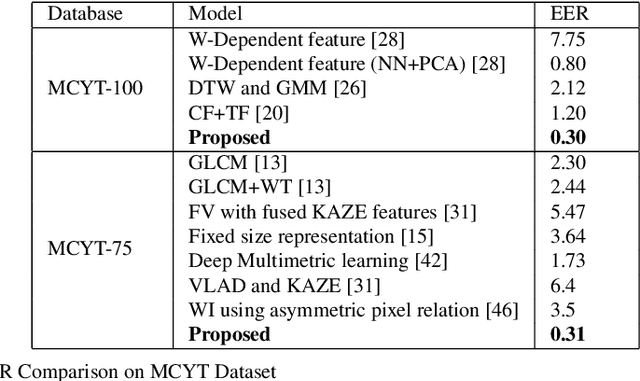
Signature verification has been one of the major researched areas in the field of computer vision. Many financial and legal organizations use signature verification as access control and authentication. Signature images are not rich in texture; however, they have much vital geometrical information. Through this work, we have proposed a signature verification methodology that is simple yet effective. The technique presented in this paper harnesses the geometrical features of a signature image like center, isolated points, connected components, etc., and with the power of Artificial Neural Network (ANN) classifier, classifies the signature image based on their geometrical features. Publicly available dataset MCYT, BHSig260 (contains the image of two regional languages Bengali and Hindi) has been used in this paper to test the effectiveness of the proposed method. We have received a lower Equal Error Rate (EER) on MCYT 100 dataset and higher accuracy on the BHSig260 dataset.
Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning
Apr 24, 2020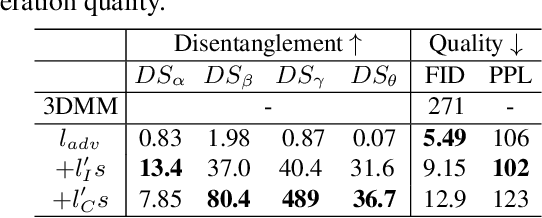
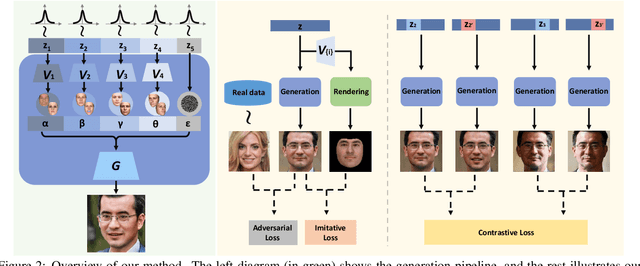
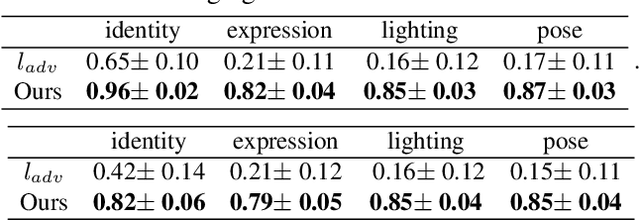
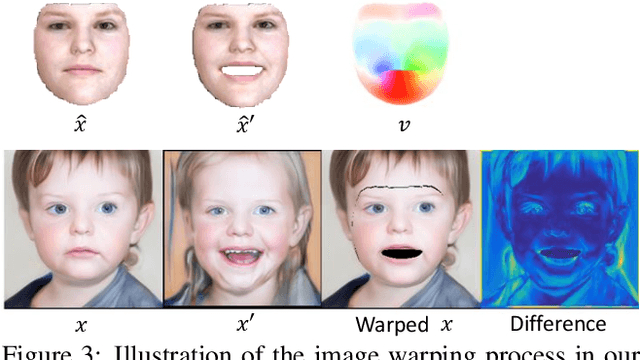
We propose an approach for face image generation of virtual people with disentangled, precisely-controllable latent representations for identity of non-existing people, expression, pose, and illumination. We embed 3D priors into adversarial learning and train the network to imitate the image formation of an analytic 3D face deformation and rendering process. To deal with the generation freedom induced by the domain gap between real and rendered faces, we further introduce contrastive learning to promote disentanglement by comparing pairs of generated images. Experiments show that through our imitative-contrastive learning, the factor variations are very well disentangled and the properties of a generated face can be precisely controlled. We also analyze the learned latent space and present several meaningful properties supporting factor disentanglement. Our method can also be used to embed real images into the disentangled latent space. We hope our method could provide new understandings of the relationship between physical properties and deep image synthesis.
Transformers Can Do Bayesian Inference
Dec 20, 2021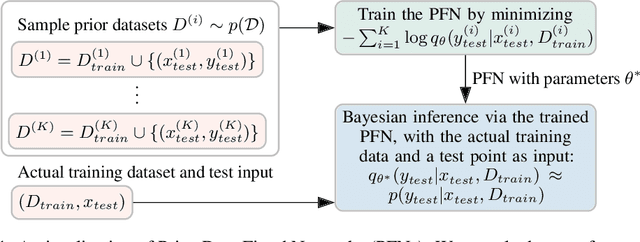
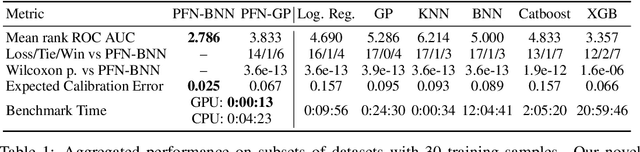
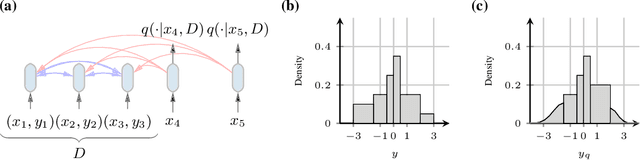

Currently, it is hard to reap the benefits of deep learning for Bayesian methods, which allow the explicit specification of prior knowledge and accurately capture model uncertainty. We present Prior-Data Fitted Networks (PFNs). PFNs leverage large-scale machine learning techniques to approximate a large set of posteriors. The only requirement for PFNs to work is the ability to sample from a prior distribution over supervised learning tasks (or functions). Our method restates the objective of posterior approximation as a supervised classification problem with a set-valued input: it repeatedly draws a task (or function) from the prior, draws a set of data points and their labels from it, masks one of the labels and learns to make probabilistic predictions for it based on the set-valued input of the rest of the data points. Presented with a set of samples from a new supervised learning task as input, PFNs make probabilistic predictions for arbitrary other data points in a single forward propagation, having learned to approximate Bayesian inference. We demonstrate that PFNs can near-perfectly mimic Gaussian processes and also enable efficient Bayesian inference for intractable problems, with over 200-fold speedups in multiple setups compared to current methods. We obtain strong results in very diverse areas such as Gaussian process regression, Bayesian neural networks, classification for small tabular data sets, and few-shot image classification, demonstrating the generality of PFNs. Code and trained PFNs are released at https://github.com/automl/TransformersCanDoBayesianInference.