 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-task manifold learning for small sample size datasets
Nov 24, 2021
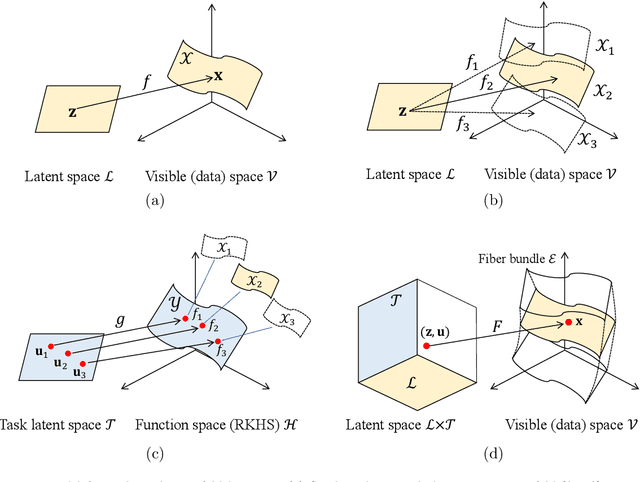
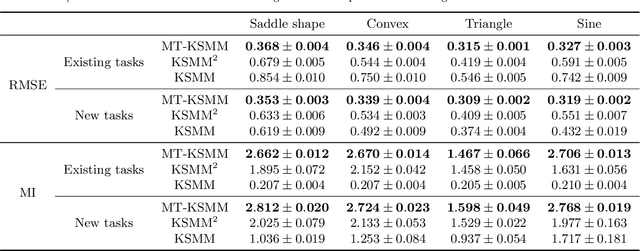
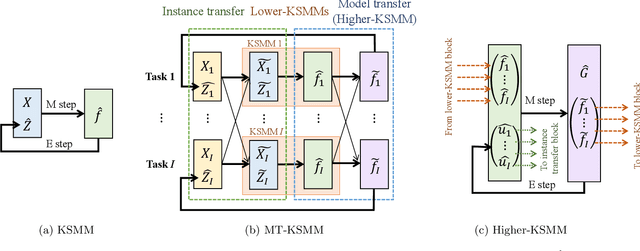

In this study, we develop a method for multi-task manifold learning. The method aims to improve the performance of manifold learning for multiple tasks, particularly when each task has a small number of samples. Furthermore, the method also aims to generate new samples for new tasks, in addition to new samples for existing tasks. In the proposed method, we use two different types of information transfer: instance transfer and model transfer. For instance transfer, datasets are merged among similar tasks, whereas for model transfer, the manifold models are averaged among similar tasks. For this purpose, the proposed method consists of a set of generative manifold models corresponding to the tasks, which are integrated into a general model of a fiber bundle. We applied the proposed method to artificial datasets and face image sets, and the results showed that the method was able to estimate the manifolds, even for a tiny number of samples.
Evaluating Generic Auto-ML Tools for Computational Pathology
Dec 07, 2021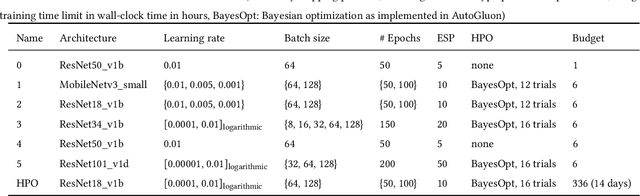
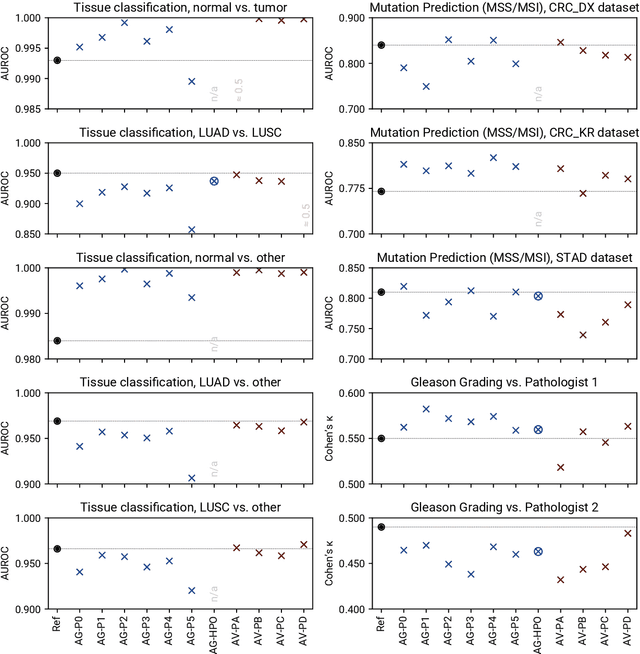

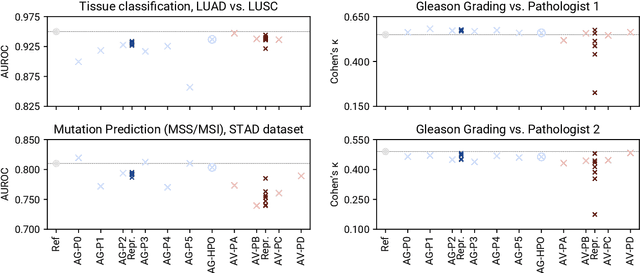
Image analysis tasks in computational pathology are commonly solved using convolutional neural networks (CNNs). The selection of a suitable CNN architecture and hyperparameters is usually done through exploratory iterative optimization, which is computationally expensive and requires substantial manual work. The goal of this article is to evaluate how generic tools for neural network architecture search and hyperparameter optimization perform for common use cases in computational pathology. For this purpose, we evaluated one on-premises and one cloud-based tool for three different classification tasks for histological images: tissue classification, mutation prediction, and grading. We found that the default CNN architectures and parameterizations of the evaluated AutoML tools already yielded classification performance on par with the original publications. Hyperparameter optimization for these tasks did not substantially improve performance, despite the additional computational effort. However, performance varied substantially between classifiers obtained from individual AutoML runs due to non-deterministic effects. Generic CNN architectures and AutoML tools could thus be a viable alternative to manually optimizing CNN architectures and parametrizations. This would allow developers of software solutions for computational pathology to focus efforts on harder-to-automate tasks such as data curation.
2nd Place Solution for SODA10M Challenge 2021 -- Continual Detection Track
Oct 25, 2021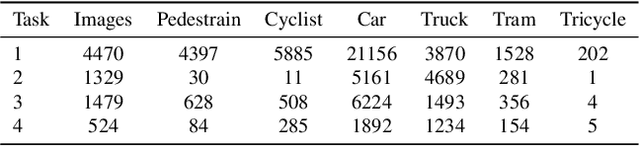
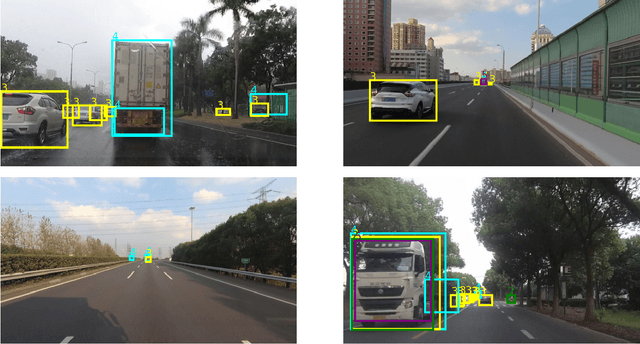
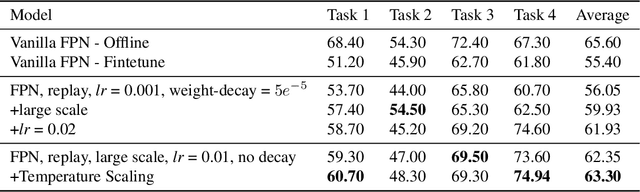

In this technical report, we present our approaches for the continual object detection track of the SODA10M challenge. We adapt ResNet50-FPN as the baseline and try several improvements for the final submission model. We find that task-specific replay scheme, learning rate scheduling, model calibration, and using original image scale helps to improve performance for both large and small objects in images. Our team `hypertune28' secured the second position among 52 participants in the challenge. This work will be presented at the ICCV 2021 Workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving (SSLAD).
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 15, 2019
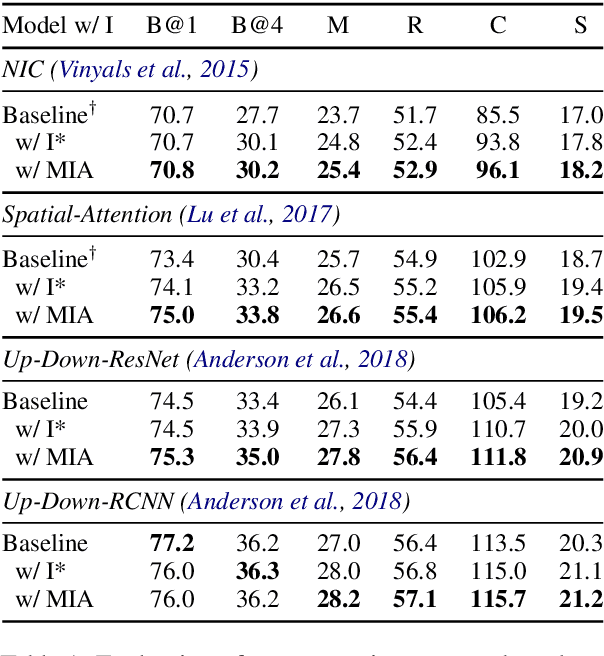
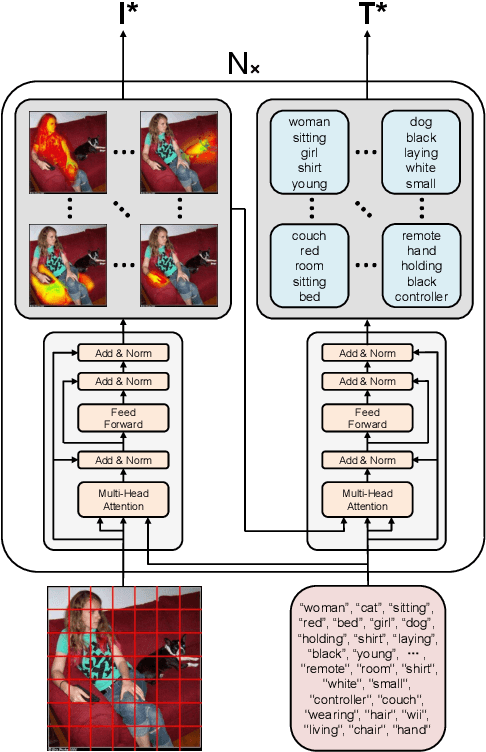
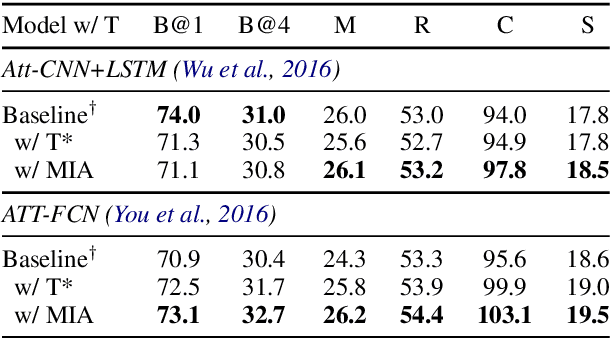
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
Single Image Optical Flow Estimation with an Event Camera
Apr 01, 2020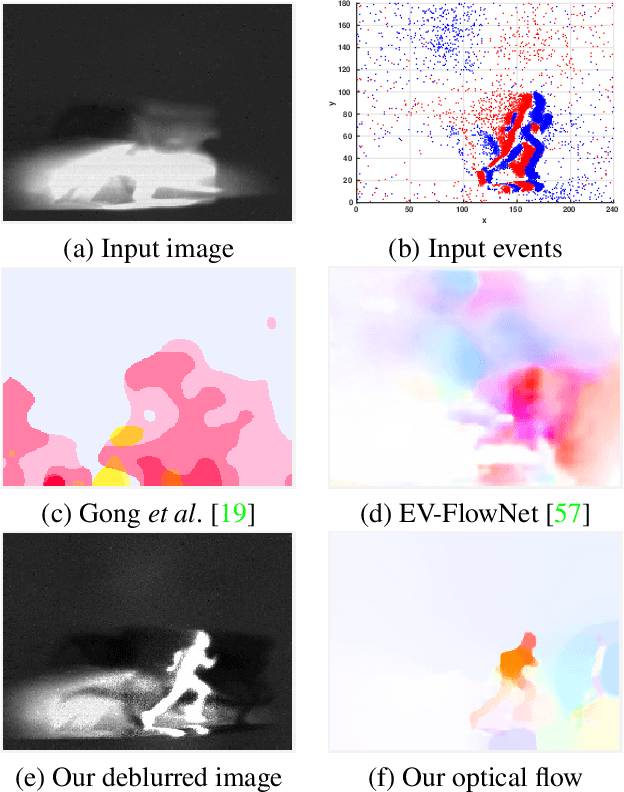

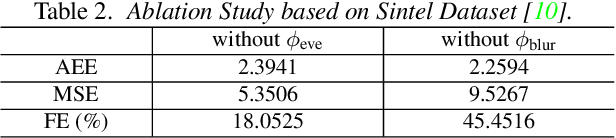
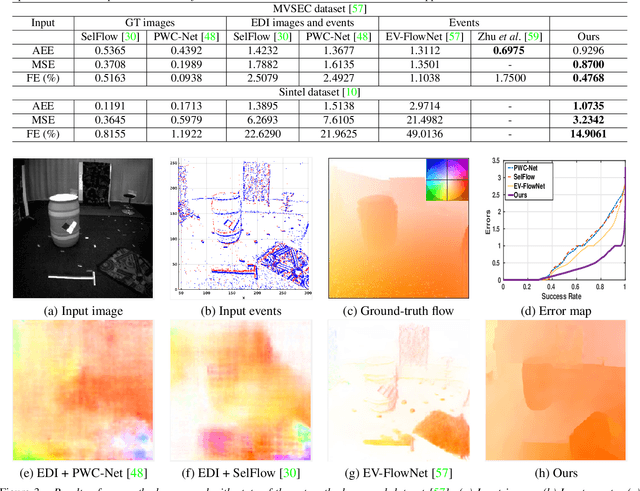
Event cameras are bio-inspired sensors that asynchronously report intensity changes in microsecond resolution. DAVIS can capture high dynamics of a scene and simultaneously output high temporal resolution events and low frame-rate intensity images. In this paper, we propose a single image (potentially blurred) and events based optical flow estimation approach. First, we demonstrate how events can be used to improve flow estimates. To this end, we encode the relation between flow and events effectively by presenting an event-based photometric consistency formulation. Then, we consider the special case of image blur caused by high dynamics in the visual environments and show that including the blur formation in our model further constrains flow estimation. This is in sharp contrast to existing works that ignore the blurred images while our formulation can naturally handle either blurred or sharp images to achieve accurate flow estimation. Finally, we reduce flow estimation, as well as image deblurring, to an alternative optimization problem of an objective function using the primal-dual algorithm. Experimental results on both synthetic and real data (with blurred and non-blurred images) show the superiority of our model in comparison to state-of-the-art approaches.
DeepFLASH: An Efficient Network for Learning-based Medical Image Registration
Apr 05, 2020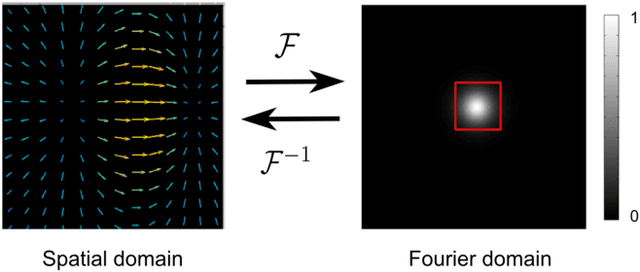
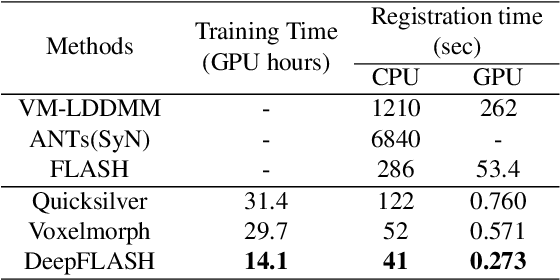
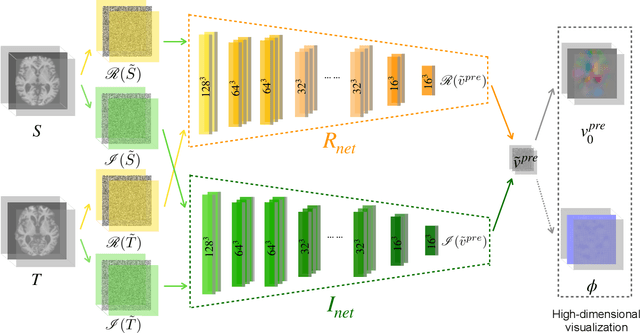

This paper presents DeepFLASH, a novel network with efficient training and inference for learning-based medical image registration. In contrast to existing approaches that learn spatial transformations from training data in the high dimensional imaging space, we develop a new registration network entirely in a low dimensional bandlimited space. This dramatically reduces the computational cost and memory footprint of an expensive training and inference. To achieve this goal, we first introduce complex-valued operations and representations of neural architectures that provide key components for learning-based registration models. We then construct an explicit loss function of transformation fields fully characterized in a bandlimited space with much fewer parameterizations. Experimental results show that our method is significantly faster than the state-of-the-art deep learning based image registration methods, while producing equally accurate alignment. We demonstrate our algorithm in two different applications of image registration: 2D synthetic data and 3D real brain magnetic resonance (MR) images. Our code is available at https://github.com/jw4hv/deepflash.
Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 13, 2021

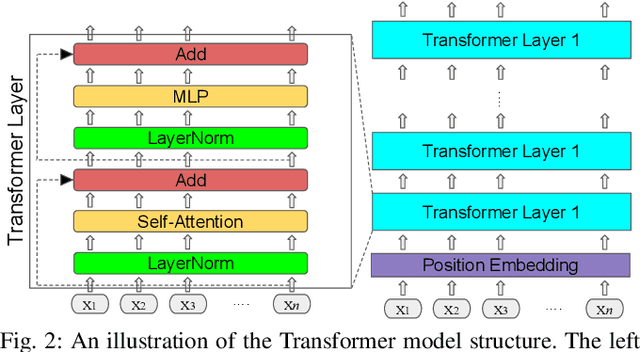
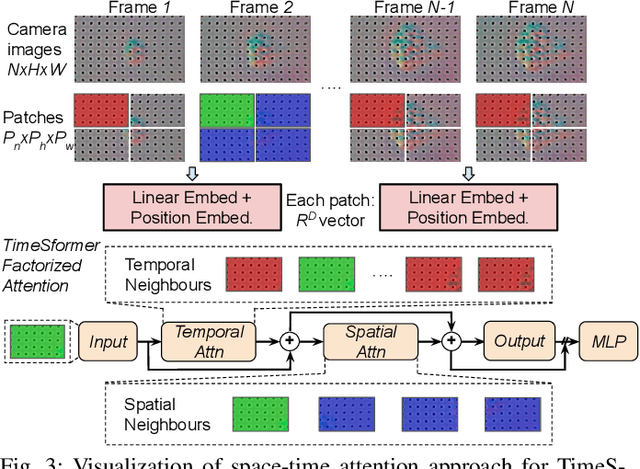
Reliable robotic grasping, especially with deformable objects, (e.g. fruit), remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics, and variable object geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a final grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper is commanded with a safe grasping strength for the grasping tasks via inference. Compared with convolutional recurrent networks, the Transformer models can capture the long-term dependencies across the image sequences and process the spatial-temporal features simultaneously. We first benchmark the proposed Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our own fruit grasping dataset and conduct the online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are made public on GitHub.
Quick Annotator: an open-source digital pathology based rapid image annotation tool
Jan 06, 2021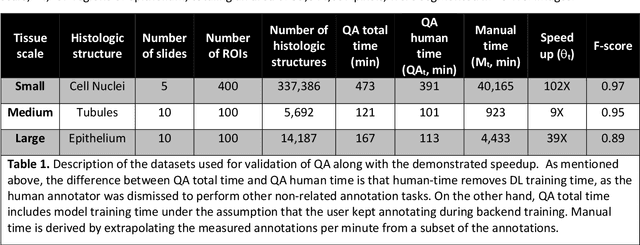
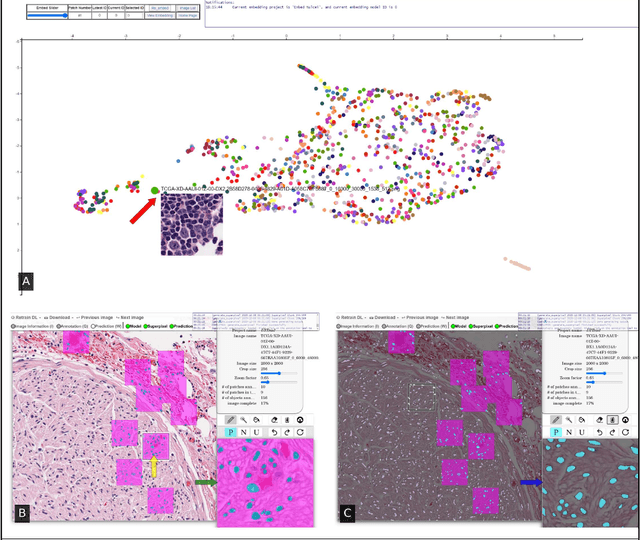
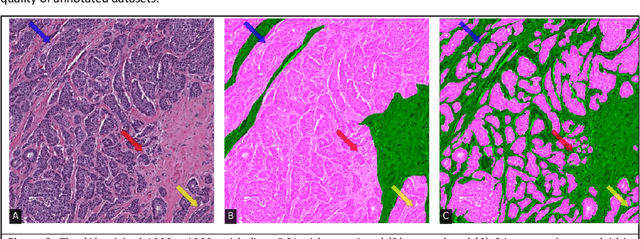
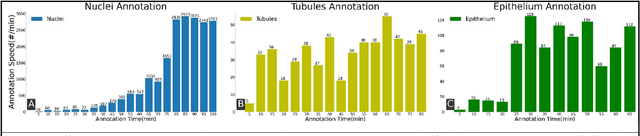
Image based biomarker discovery typically requires an accurate segmentation of histologic structures (e.g., cell nuclei, tubules, epithelial regions) in digital pathology Whole Slide Images (WSI). Unfortunately, annotating each structure of interest is laborious and often intractable even in moderately sized cohorts. Here, we present an open-source tool, Quick Annotator (QA), designed to improve annotation efficiency of histologic structures by orders of magnitude. While the user annotates regions of interest (ROI) via an intuitive web interface, a deep learning (DL) model is concurrently optimized using these annotations and applied to the ROI. The user iteratively reviews DL results to either (a) accept accurately annotated regions, or (b) correct erroneously segmented structures to improve subsequent model suggestions, before transitioning to other ROIs. We demonstrate the effectiveness of QA over comparable manual efforts via three use cases. These include annotating (a) 337,386 nuclei in 5 pancreatic WSIs, (b) 5,692 tubules in 10 colorectal WSIs, and (c) 14,187 regions of epithelium in 10 breast WSIs. Efficiency gains in terms of annotations per second of 102x, 9x, and 39x were respectively witnessed while retaining f-scores >.95, suggesting QA may be a valuable tool for efficiently fully annotating WSIs employed in downstream biomarker studies.
A Cross-Modal Image Fusion Theory Guided by Human Visual Characteristics
Dec 18, 2019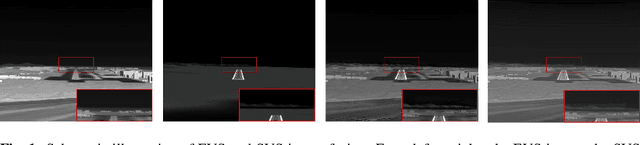
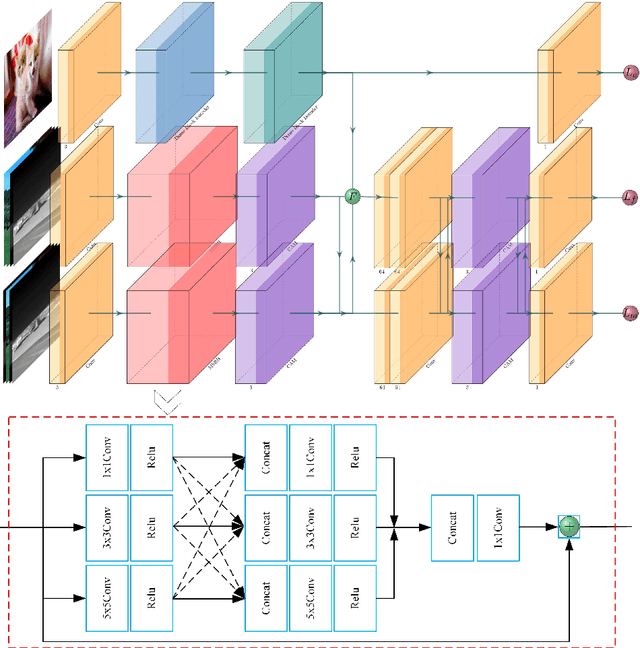
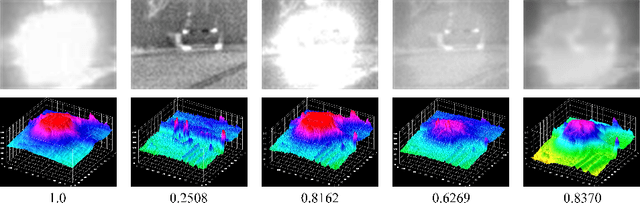

The characteristics of feature selection, nonlinear combination and multi-task auxiliary learning mechanism of human visual perception system play an important role in real-world scenarios, but the research of image fusion theory based on the characteristics of human visual perception is less. Inspired by the characteristics of human visual perception, we propose a robust multi-task auxiliary learning optimization image fusion theory. Firstly, we combine channel attention model with nonlinear convolutional neural network to select features and fuse nonlinear features. Then, we analyze the impact of the existing image fusion loss on the image fusion quality, and establish the multi-loss function model of unsupervised learning network. Secondly, aiming at the multi-task auxiliary learning mechanism of human visual perception system, we study the influence of multi-task auxiliary learning mechanism on image fusion task on the basis of single task multi-loss network model. By simulating the three characteristics of human visual perception system, the fused image is more consistent with the mechanism of human brain image fusion. Finally, in order to verify the superiority of our algorithm, we carried out experiments on the combined vision system image data set, and extended our algorithm to the infrared and visible image and the multi-focus image public data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in generality and robustness.
Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
Oct 14, 2021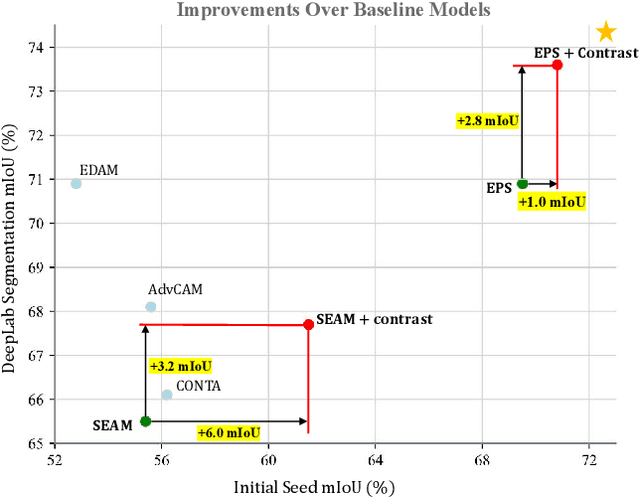
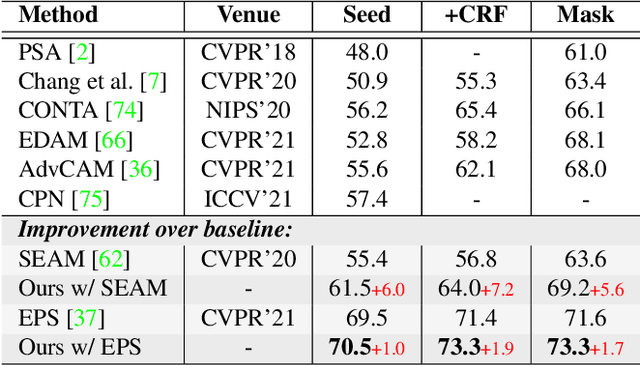
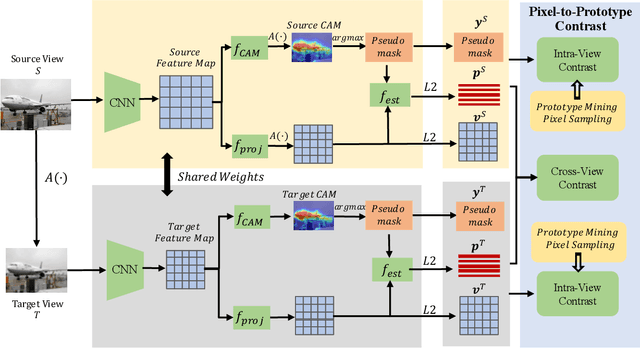
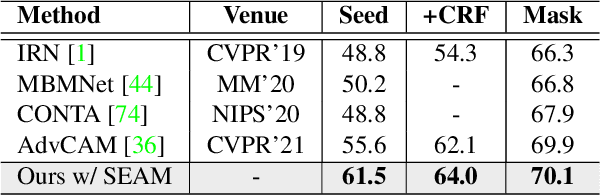
Though image-level weakly supervised semantic segmentation (WSSS) has achieved great progress with Class Activation Map (CAM) as the cornerstone, the large supervision gap between classification and segmentation still hampers the model to generate more complete and precise pseudo masks for segmentation. In this study, we explore two implicit but intuitive constraints, i.e., cross-view feature semantic consistency and intra(inter)-class compactness(dispersion), to narrow the supervision gap. To this end, we propose two novel pixel-to-prototype contrast regularization terms that are conducted cross different views and within per single view of an image, respectively. Besides, we adopt two sample mining strategies, named semi-hard prototype mining and hard pixel sampling, to better leverage hard examples while reducing incorrect contrasts caused due to the absence of precise pixel-wise labels. Our method can be seamlessly incorporated into existing WSSS models without any changes to the base network and does not incur any extra inference burden. Experiments on standard benchmark show that our method consistently improves two strong baselines by large margins, demonstrating the effectiveness of our method. Specifically, built on top of SEAM, we improve the initial seed mIoU on PASCAL VOC 2012 from 55.4% to 61.5%. Moreover, armed with our method, we increase the segmentation mIoU of EPS from 70.8% to 73.6%, achieving new state-of-the-art.