 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy on the Helpfulness of Explainable Artificial Intelligence
Oct 14, 2024Explainable Artificial Intelligence (XAI) is essential for building advanced machine learning-powered applications, especially in critical domains such as medical diagnostics or autonomous driving. Legal, business, and ethical requirements motivate using effective XAI, but the increasing number of different methods makes it challenging to pick the right ones. Further, as explanations are highly context-dependent, measuring the effectiveness of XAI methods without users can only reveal a limited amount of information, excluding human factors such as the ability to understand it. We propose to evaluate XAI methods via the user's ability to successfully perform a proxy task, designed such that a good performance is an indicator for the explanation to provide helpful information. In other words, we address the helpfulness of XAI for human decision-making. Further, a user study on state-of-the-art methods was conducted, showing differences in their ability to generate trust and skepticism and the ability to judge the rightfulness of an AI decision correctly. Based on the results, we highly recommend using and extending this approach for more objective-based human-centered user studies to measure XAI performance in an end-to-end fashion.
* World Conference on Explainable Artificial Intelligence
Recommendations on test datasets for evaluating AI solutions in pathology
Apr 21, 2022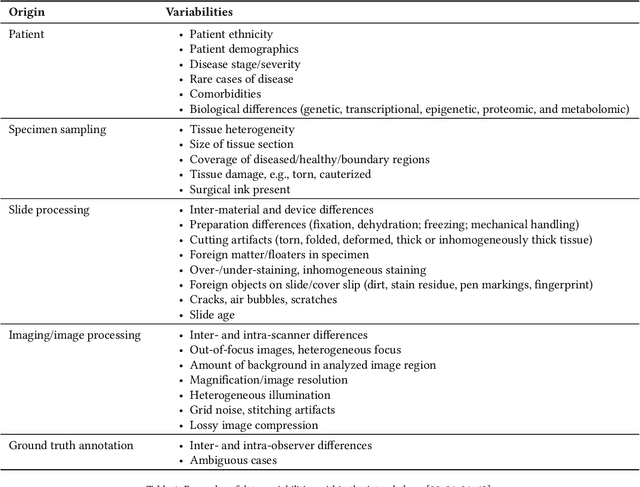
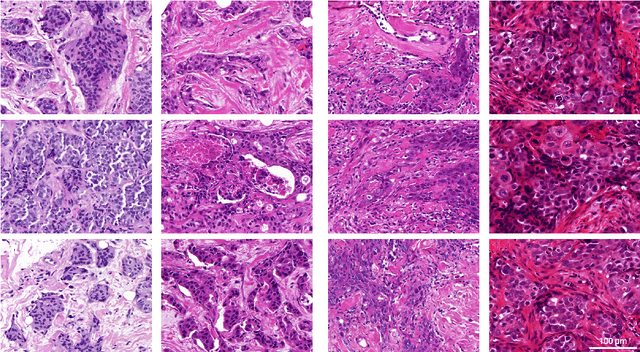

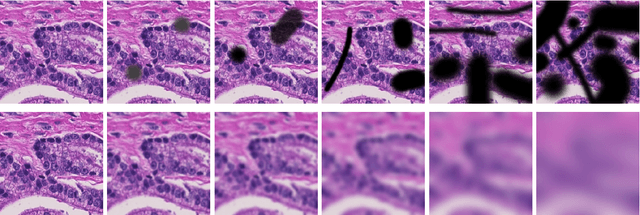
Artificial intelligence (AI) solutions that automatically extract information from digital histology images have shown great promise for improving pathological diagnosis. Prior to routine use, it is important to evaluate their predictive performance and obtain regulatory approval. This assessment requires appropriate test datasets. However, compiling such datasets is challenging and specific recommendations are missing. A committee of various stakeholders, including commercial AI developers, pathologists, and researchers, discussed key aspects and conducted extensive literature reviews on test datasets in pathology. Here, we summarize the results and derive general recommendations for the collection of test datasets. We address several questions: Which and how many images are needed? How to deal with low-prevalence subsets? How can potential bias be detected? How should datasets be reported? What are the regulatory requirements in different countries? The recommendations are intended to help AI developers demonstrate the utility of their products and to help regulatory agencies and end users verify reported performance measures. Further research is needed to formulate criteria for sufficiently representative test datasets so that AI solutions can operate with less user intervention and better support diagnostic workflows in the future.
Evaluating Generic Auto-ML Tools for Computational Pathology
Dec 07, 2021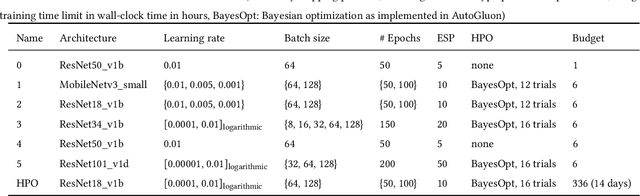
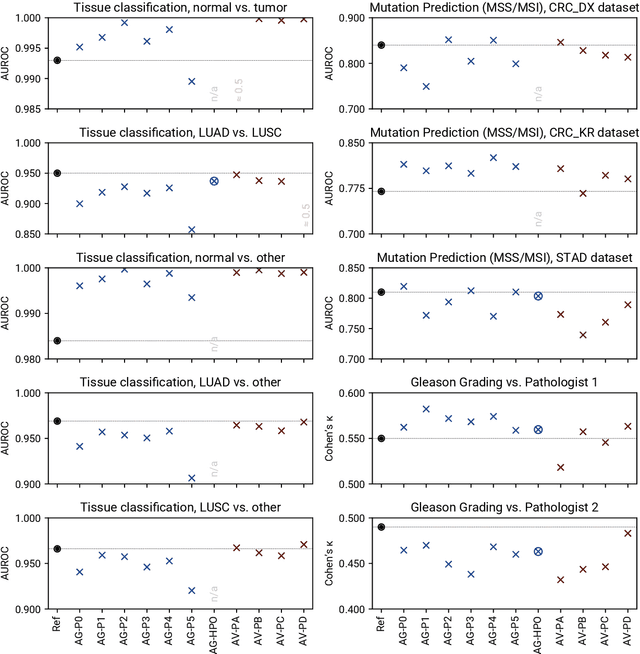

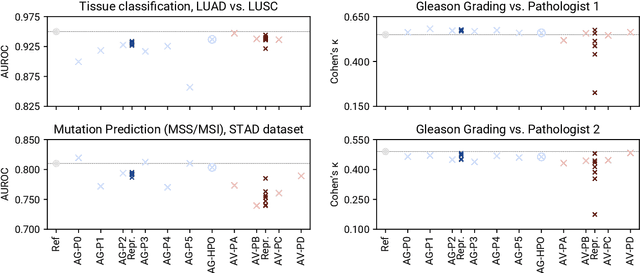
Image analysis tasks in computational pathology are commonly solved using convolutional neural networks (CNNs). The selection of a suitable CNN architecture and hyperparameters is usually done through exploratory iterative optimization, which is computationally expensive and requires substantial manual work. The goal of this article is to evaluate how generic tools for neural network architecture search and hyperparameter optimization perform for common use cases in computational pathology. For this purpose, we evaluated one on-premises and one cloud-based tool for three different classification tasks for histological images: tissue classification, mutation prediction, and grading. We found that the default CNN architectures and parameterizations of the evaluated AutoML tools already yielded classification performance on par with the original publications. Hyperparameter optimization for these tasks did not substantially improve performance, despite the additional computational effort. However, performance varied substantially between classifiers obtained from individual AutoML runs due to non-deterministic effects. Generic CNN architectures and AutoML tools could thus be a viable alternative to manually optimizing CNN architectures and parametrizations. This would allow developers of software solutions for computational pathology to focus efforts on harder-to-automate tasks such as data curation.
Graduated Optimization of Black-Box Functions
Jun 04, 2019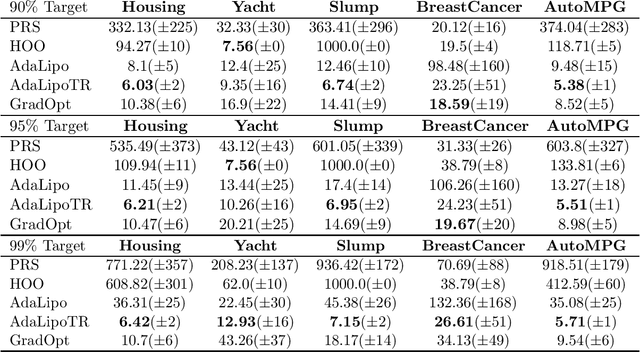
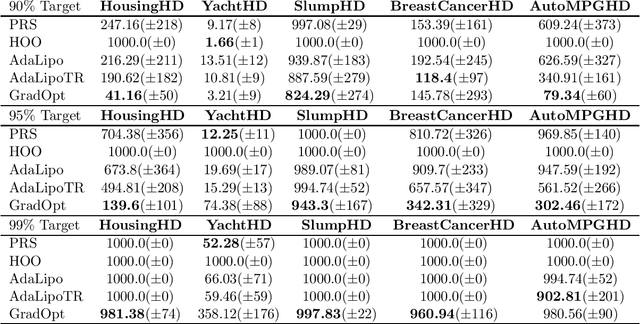
Motivated by the problem of tuning hyperparameters in machine learning, we present a new approach for gradually and adaptively optimizing an unknown function using estimated gradients. We validate the empirical performance of the proposed idea on both low and high dimensional problems. The experimental results demonstrate the advantages of our approach for tuning high dimensional hyperparameters in machine learning.