 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust data analysis and imaging with computational ghost imaging
Nov 06, 2021
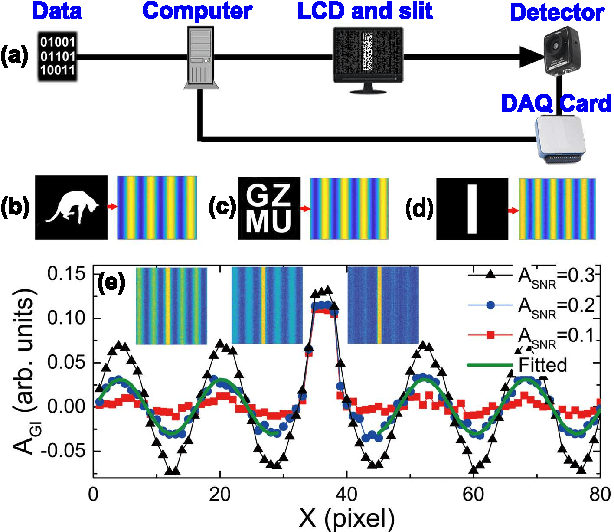
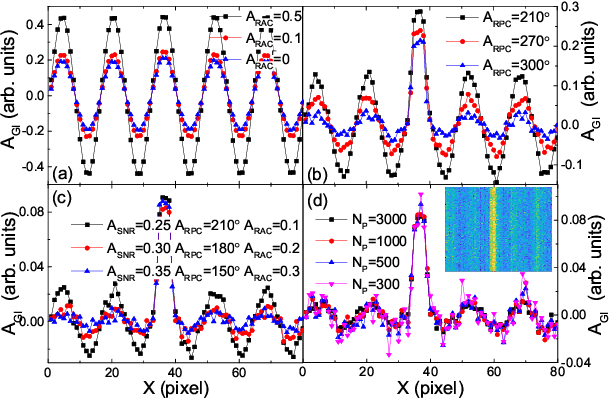
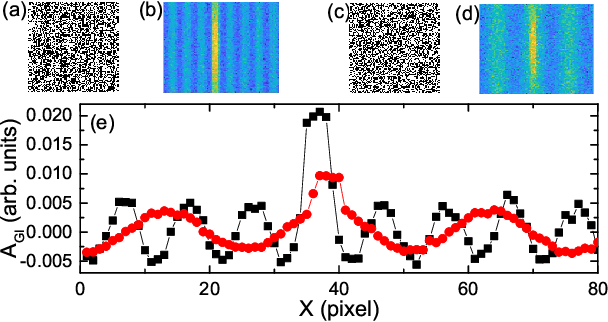
Nowadays the world has entered into the digital age, in which the data analysis and visualization have become more and more important. In analogy to imaging the real object, we demonstrate that the computational ghost imaging can image the digital data to show their characteristics, such as periodicity. Furthermore, our experimental results show that the use of optical imaging methods to analyse data exhibits unique advantages, especially in anti-interference. The data analysis with computational ghost imaging can be well performed against strong noise, random amplitude and phase changes in the binarized signals. Such robust data data analysis and imaging has an important application prospect in big data analysis, meteorology, astronomy, economics and many other fields.
Come-Closer-Diffuse-Faster: Accelerating Conditional Diffusion Models for Inverse Problems through Stochastic Contraction
Dec 09, 2021



Diffusion models have recently attained significant interest within the community owing to their strong performance as generative models. Furthermore, its application to inverse problems have demonstrated state-of-the-art performance. Unfortunately, diffusion models have a critical downside - they are inherently slow to sample from, needing few thousand steps of iteration to generate images from pure Gaussian noise. In this work, we show that starting from Gaussian noise is unnecessary. Instead, starting from a single forward diffusion with better initialization significantly reduces the number of sampling steps in the reverse conditional diffusion. This phenomenon is formally explained by the contraction theory of the stochastic difference equations like our conditional diffusion strategy - the alternating applications of reverse diffusion followed by a non-expansive data consistency step. The new sampling strategy, dubbed Come-Closer-Diffuse-Faster (CCDF), also reveals a new insight on how the existing feed-forward neural network approaches for inverse problems can be synergistically combined with the diffusion models. Experimental results with super-resolution, image inpainting, and compressed sensing MRI demonstrate that our method can achieve state-of-the-art reconstruction performance at significantly reduced sampling steps.
Deep Learning Based Automated COVID-19 Classification from Computed Tomography Images
Nov 22, 2021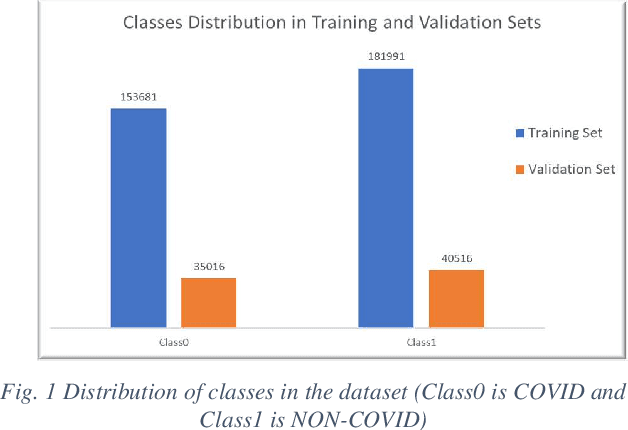
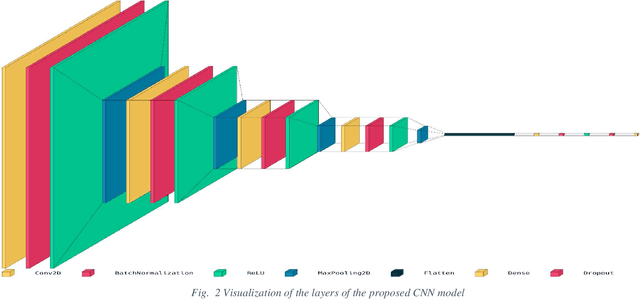
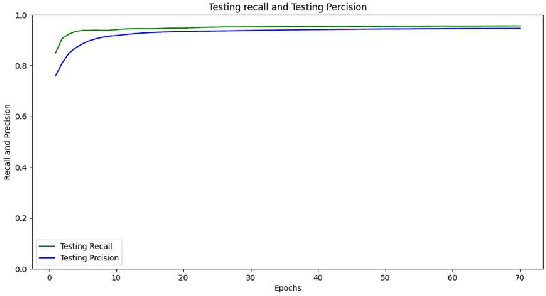
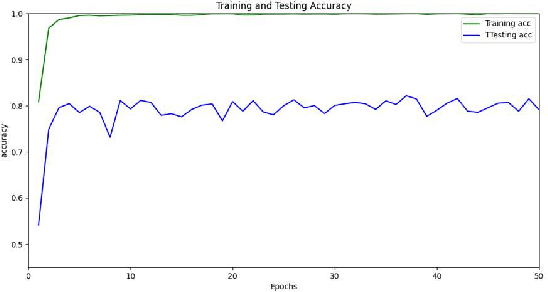
The paper presents a Convolutional Neural Networks (CNN) model for image classification, aiming at increasing predictive performance for COVID-19 diagnosis while avoiding deeper and thus more complex alternatives. The proposed model includes four similar convolutional layers followed by a flattening and two dense layers. This work proposes a less complex solution based on simply classifying 2D CT-Scan slices of images using their pixels via a 2D CNN model. Despite the simplicity in architecture, the proposed model showed improved quantitative results exceeding state-of-the-art on the same dataset of images, in terms of the macro f1 score. In this case study, extracting features from images, segmenting parts of the images, or other more complex techniques, ultimately aiming at images classification, do not yield better results. With that, this paper introduces a simple yet powerful deep learning based solution for automated COVID-19 classification.
CyTran: Cycle-Consistent Transformers for Non-Contrast to Contrast CT Translation
Oct 21, 2021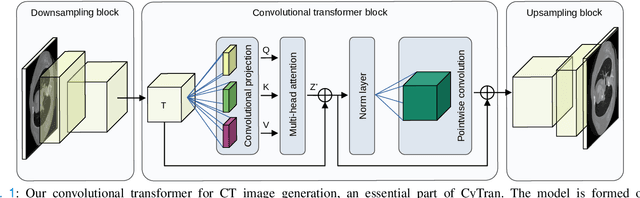
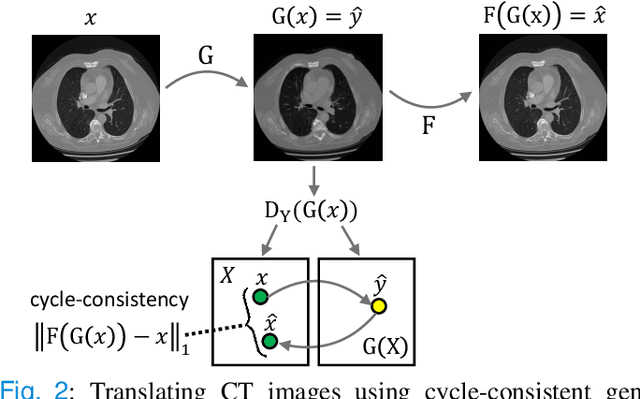
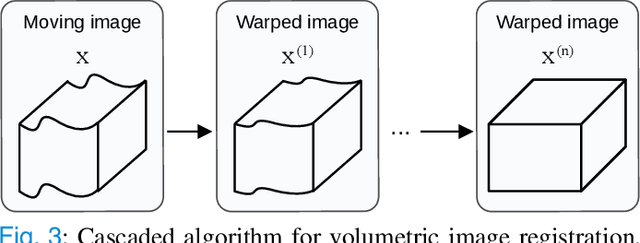
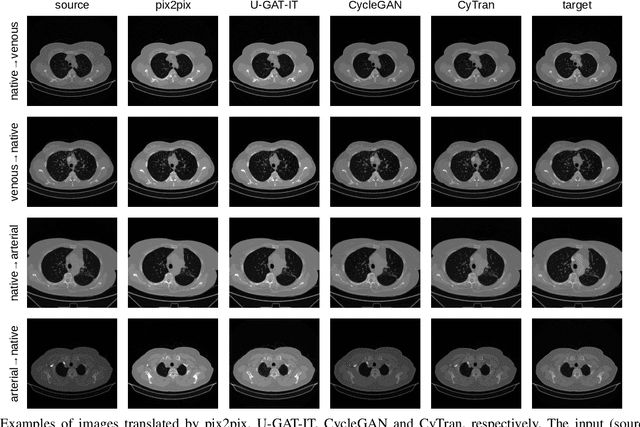
We propose a novel approach to translate unpaired contrast computed tomography (CT) scans to non-contrast CT scans and the other way around. Solving this task has two important applications: (i) to automatically generate contrast CT scans for patients for whom injecting contrast substance is not an option, and (ii) to enhance alignment between contrast and non-contrast CT by reducing the differences induced by the contrast substance before registration. Our approach is based on cycle-consistent generative adversarial convolutional transformers, for short, CyTran. Our neural model can be trained on unpaired images, due to the integration of a cycle-consistency loss. To deal with high-resolution images, we design a hybrid architecture based on convolutional and multi-head attention layers. In addition, we introduce a novel data set, Coltea-Lung-CT-100W, containing 3D triphasic lung CT scans (with a total of 37,290 images) collected from 100 female patients. Each scan contains three phases (non-contrast, early portal venous, and late arterial), allowing us to perform experiments to compare our novel approach with state-of-the-art methods for image style transfer. Our empirical results show that CyTran outperforms all competing methods. Moreover, we show that CyTran can be employed as a preliminary step to improve a state-of-the-art medical image alignment method. We release our novel model and data set as open source at: https://github.com/ristea/cycle-transformer.
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Dec 14, 2021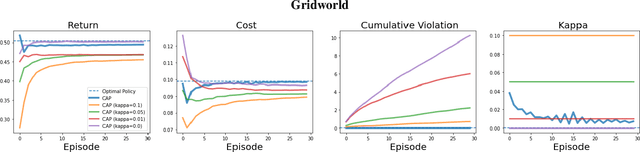
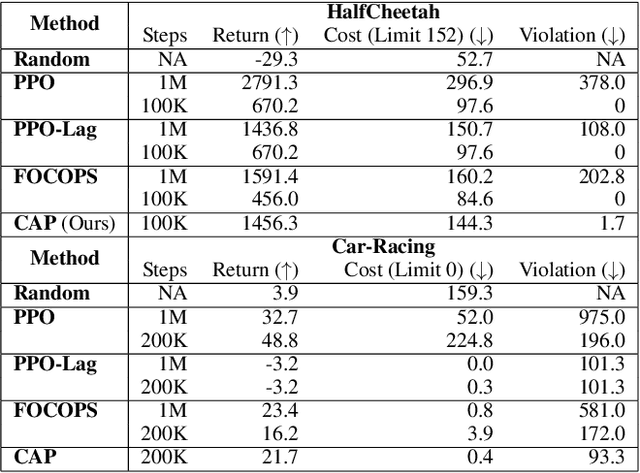
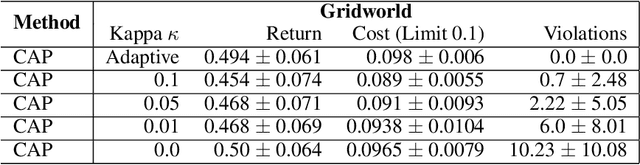
Reinforcement Learning (RL) agents in the real world must satisfy safety constraints in addition to maximizing a reward objective. Model-based RL algorithms hold promise for reducing unsafe real-world actions: they may synthesize policies that obey all constraints using simulated samples from a learned model. However, imperfect models can result in real-world constraint violations even for actions that are predicted to satisfy all constraints. We propose Conservative and Adaptive Penalty (CAP), a model-based safe RL framework that accounts for potential modeling errors by capturing model uncertainty and adaptively exploiting it to balance the reward and the cost objectives. First, CAP inflates predicted costs using an uncertainty-based penalty. Theoretically, we show that policies that satisfy this conservative cost constraint are guaranteed to also be feasible in the true environment. We further show that this guarantees the safety of all intermediate solutions during RL training. Further, CAP adaptively tunes this penalty during training using true cost feedback from the environment. We evaluate this conservative and adaptive penalty-based approach for model-based safe RL extensively on state and image-based environments. Our results demonstrate substantial gains in sample-efficiency while incurring fewer violations than prior safe RL algorithms. Code is available at: https://github.com/Redrew/CAP
Meta-Learning Initializations for Image Segmentation
Dec 13, 2019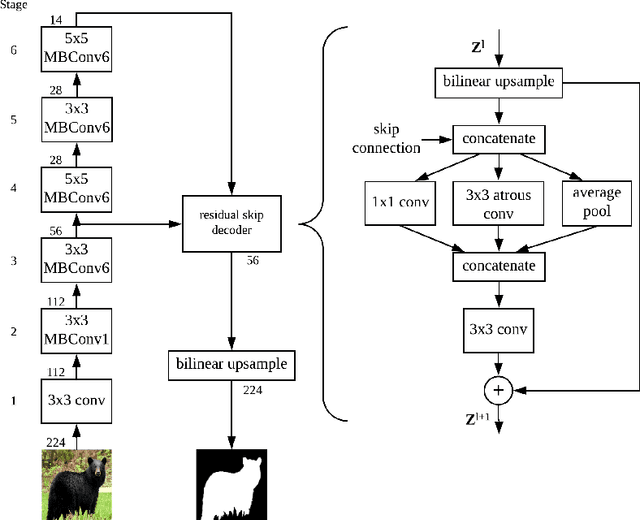


While meta-learning approaches that utilize neural network representations have made progress in few-shot image classification, reinforcement learning, and, more recently, image semantic segmentation, the training algorithms and model architectures have become increasingly specialized to the few-shot domain. A natural question that arises is how to develop learning systems that scale from few-shot to many-shot settings while yielding competitive performance in both. One scalable potential approach that does not require ensembling many models nor the computational costs of relation networks, is to meta-learn an initialization. In this work, we study first-order meta-learning of initializations for deep neural networks that must produce dense, structured predictions given an arbitrary amount of training data for a new task. Our primary contributions include (1), an extension and experimental analysis of first-order model agnostic meta-learning algorithms (including FOMAML and Reptile) to image segmentation, (2) a novel neural network architecture built for parameter efficiency and fast learning which we call EfficientLab, (3) a formalization of the generalization error of meta-learning algorithms, which we leverage to decrease error on unseen tasks, and (4) a small benchmark dataset, FP-k, for the empirical study of how meta-learning systems perform in both few- and many-shot settings. We show that meta-learned initializations for image segmentation provide value for both canonical few-shot learning problems and larger datasets, outperforming ImageNet-trained initializations for up to 400 densely labeled examples. We find that our network, with an empirically estimated optimal update procedure, yields state of the art results on the FSS-1000 dataset while only requiring one forward pass through a single model at evaluation time.
Fast Neural Representations for Direct Volume Rendering
Dec 02, 2021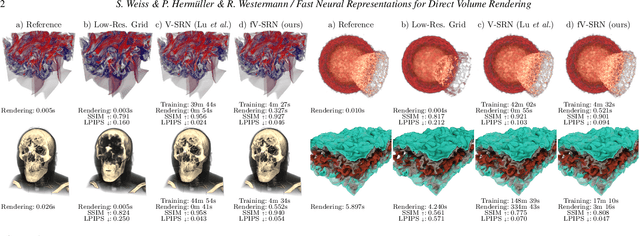

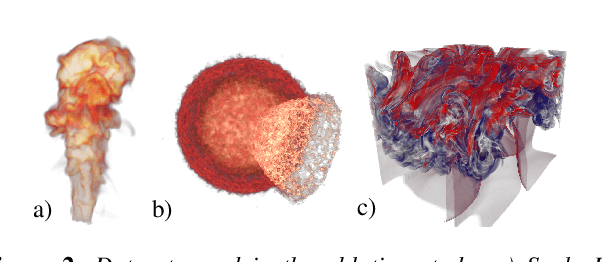
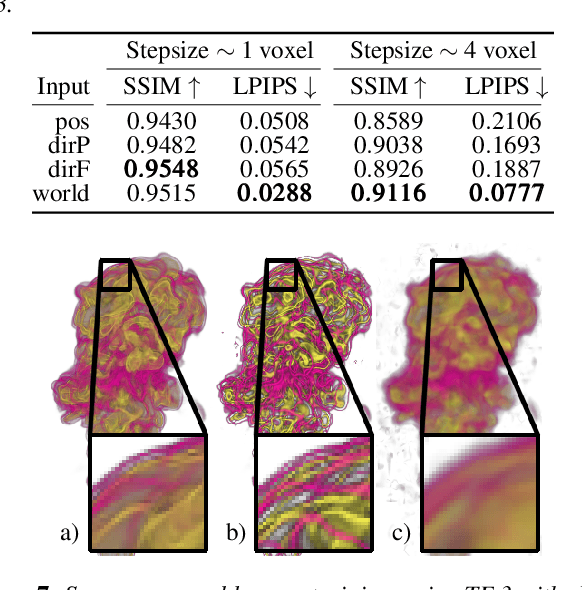
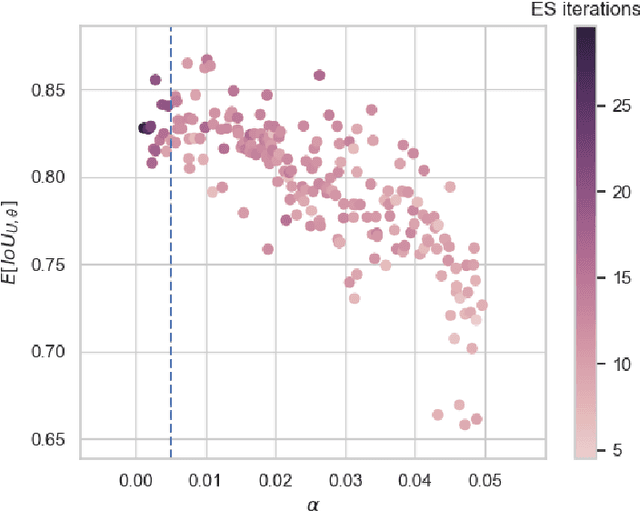
Despite the potential of neural scene representations to effectively compress 3D scalar fields at high reconstruction quality, the computational complexity of the training and data reconstruction step using scene representation networks limits their use in practical applications. In this paper, we analyze whether scene representation networks can be modified to reduce these limitations and whether these architectures can also be used for temporal reconstruction tasks. We propose a novel design of scene representation networks using GPU tensor cores to integrate the reconstruction seamlessly into on-chip raytracing kernels. Furthermore, we investigate the use of image-guided network training as an alternative to classical data-driven approaches, and we explore the potential strengths and weaknesses of this alternative regarding quality and speed. As an alternative to spatial super-resolution approaches for time-varying fields, we propose a solution that builds upon latent-space interpolation to enable random access reconstruction at arbitrary granularity. We summarize our findings in the form of an assessment of the strengths and limitations of scene representation networks for scientific visualization tasks and outline promising future research directions in this field.
Stereo Endoscopic Image Super-Resolution Using Disparity-Constrained Parallel Attention
Mar 19, 2020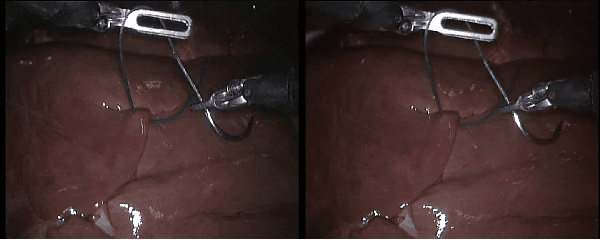
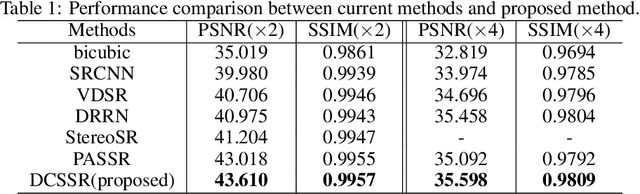
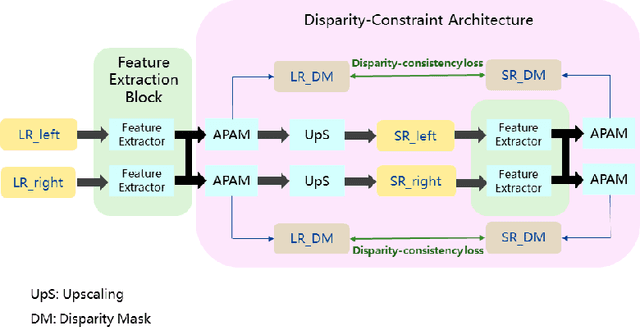
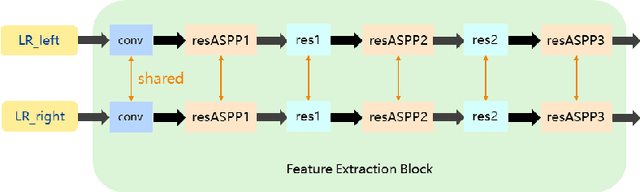
With the popularity of stereo cameras in computer assisted surgery techniques, a second viewpoint would provide additional information in surgery. However, how to effectively access and use stereo information for the super-resolution (SR) purpose is often a challenge. In this paper, we propose a disparity-constrained stereo super-resolution network (DCSSRnet) to simultaneously compute a super-resolved image in a stereo image pair. In particular, we incorporate a disparity-based constraint mechanism into the generation of SR images in a deep neural network framework with an additional atrous parallax-attention modules. Experiment results on laparoscopic images demonstrate that the proposed framework outperforms current SR methods on both quantitative and qualitative evaluations. Our DCSSRnet provides a promising solution on enhancing spatial resolution of stereo image pairs, which will be extremely beneficial for the endoscopic surgery.
Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark
Aug 13, 2021
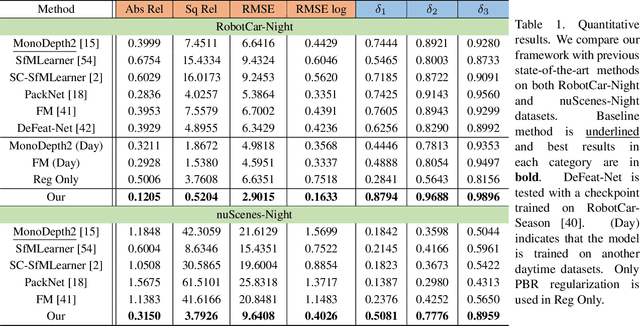
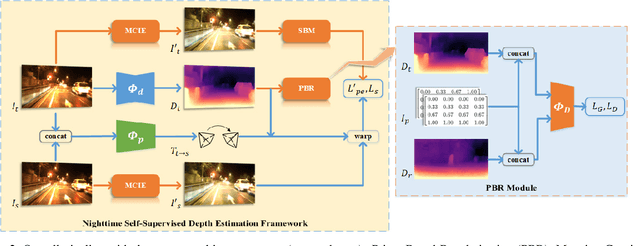
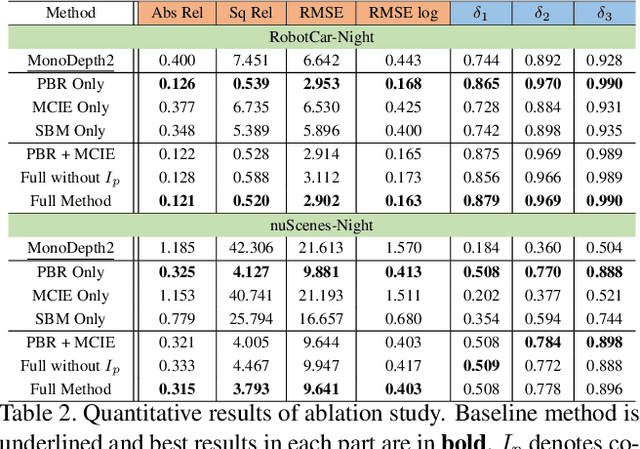
Monocular depth estimation aims at predicting depth from a single image or video. Recently, self-supervised methods draw much attention since they are free of depth annotations and achieve impressive performance on several daytime benchmarks. However, they produce weird outputs in more challenging nighttime scenarios because of low visibility and varying illuminations, which bring weak textures and break brightness-consistency assumption, respectively. To address these problems, in this paper we propose a novel framework with several improvements: (1) we introduce Priors-Based Regularization to learn distribution knowledge from unpaired depth maps and prevent model from being incorrectly trained; (2) we leverage Mapping-Consistent Image Enhancement module to enhance image visibility and contrast while maintaining brightness consistency; and (3) we present Statistics-Based Mask strategy to tune the number of removed pixels within textureless regions, using dynamic statistics. Experimental results demonstrate the effectiveness of each component. Meanwhile, our framework achieves remarkable improvements and state-of-the-art results on two nighttime datasets.
Adaptively Aligned Image Captioning via Adaptive Attention Time
Sep 19, 2019
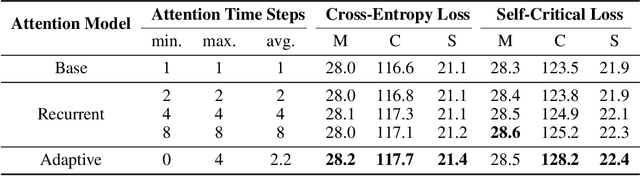
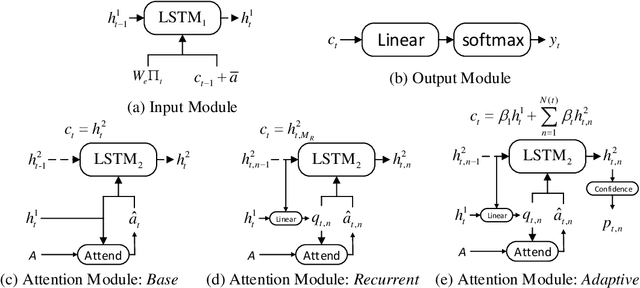

Recent neural models for image captioning usually employs an encoder-decoder framework with attention mechanism. However, the attention mechanism in such a framework aligns one single (attended) image feature vector to one caption word, assuming one-to-one mapping from source image regions and target caption words, which is never possible. In this paper, we propose a novel attention model, namely Adaptive Attention Time (AAT), which can adaptively align source to target for image captioning. AAT allows the framework to learn how many attention steps to take to output a caption word at each decoding step. With AAT, image regions and caption words can be aligned adaptively in the decoding process: an image region can be mapped to arbitrary number of caption words while a caption word can also attend to arbitrary number of image regions. AAT is deterministic and differentiable, and doesn't introduce any noise to the parameter gradients. AAT is also generic and can be employed by any sequence-to-sequence learning task. In this paper, we empirically show that AAT improves over state-of-the-art methods on the task of image captioning.