 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
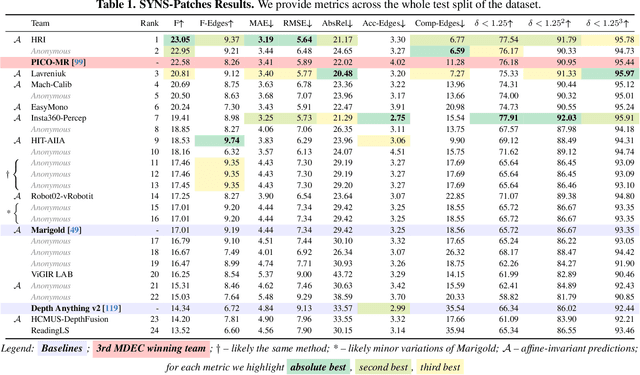
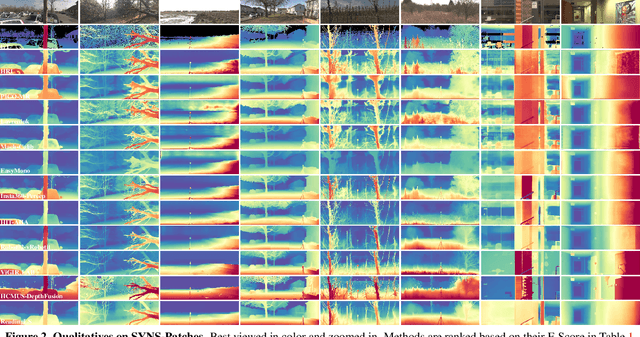
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark
Aug 13, 2021
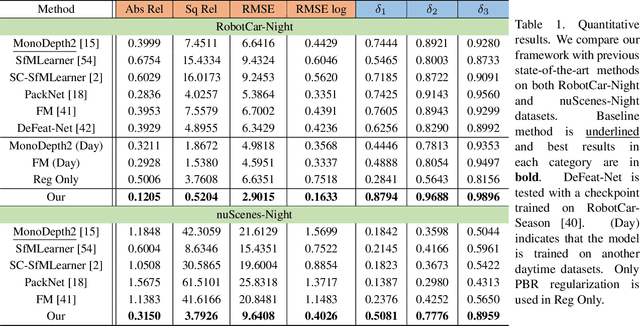
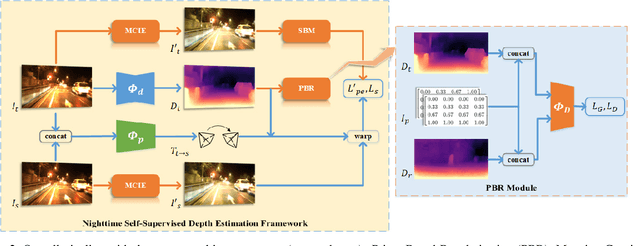
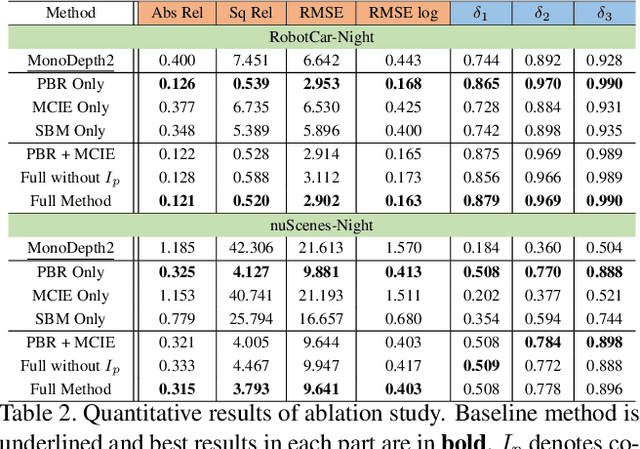
Monocular depth estimation aims at predicting depth from a single image or video. Recently, self-supervised methods draw much attention since they are free of depth annotations and achieve impressive performance on several daytime benchmarks. However, they produce weird outputs in more challenging nighttime scenarios because of low visibility and varying illuminations, which bring weak textures and break brightness-consistency assumption, respectively. To address these problems, in this paper we propose a novel framework with several improvements: (1) we introduce Priors-Based Regularization to learn distribution knowledge from unpaired depth maps and prevent model from being incorrectly trained; (2) we leverage Mapping-Consistent Image Enhancement module to enhance image visibility and contrast while maintaining brightness consistency; and (3) we present Statistics-Based Mask strategy to tune the number of removed pixels within textureless regions, using dynamic statistics. Experimental results demonstrate the effectiveness of each component. Meanwhile, our framework achieves remarkable improvements and state-of-the-art results on two nighttime datasets.
RigNet: Repetitive Image Guided Network for Depth Completion
Jul 29, 2021
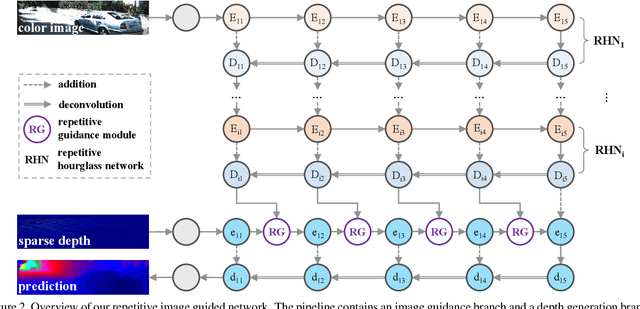
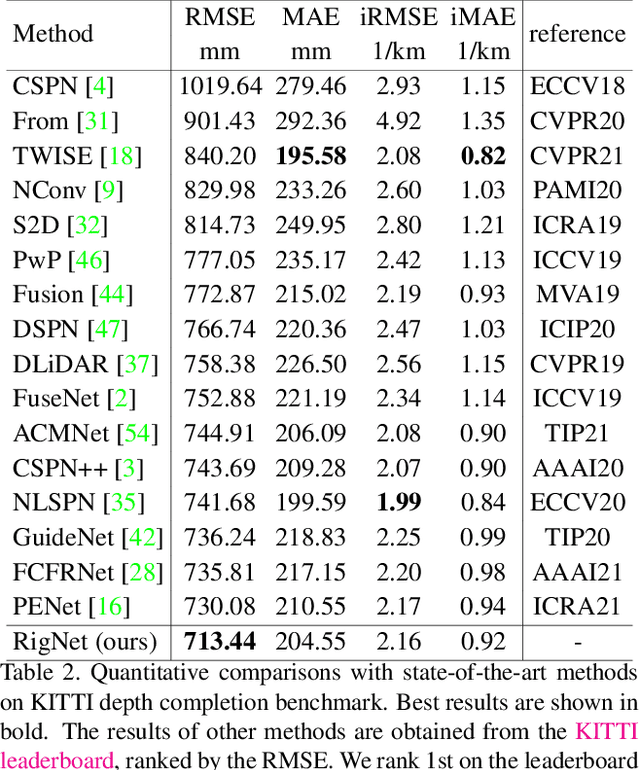
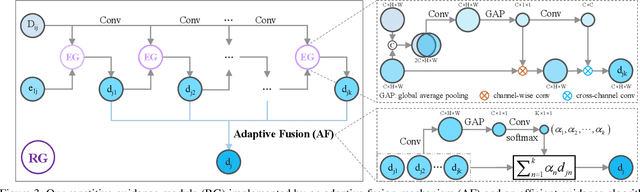
Depth completion deals with the problem of recovering dense depth maps from sparse ones, where color images are often used to facilitate this completion. Recent approaches mainly focus on image guided learning to predict dense results. However, blurry image guidance and object structures in depth still impede the performance of image guided frameworks. To tackle these problems, we explore a repetitive design in our image guided network to sufficiently and gradually recover depth values. Specifically, the repetition is embodied in a color image guidance branch and a depth generation branch. In the former branch, we design a repetitive hourglass network to extract higher-level image features of complex environments, which can provide powerful context guidance for depth prediction. In the latter branch, we design a repetitive guidance module based on dynamic convolution where the convolution factorization is applied to simultaneously reduce its complexity and progressively model high-frequency structures, e.g., boundaries. Further, in this module, we propose an adaptive fusion mechanism to effectively aggregate multi-step depth features. Extensive experiments show that our method achieves state-of-the-art result on the NYUv2 dataset and ranks 1st on the KITTI benchmark at the time of submission.