 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation
Jan 20, 2026Despite recent progress in 3D Gaussian-based head avatar modeling, efficiently generating high fidelity avatars remains a challenge. Current methods typically rely on extensive multi-view capture setups or monocular videos with per-identity optimization during inference, limiting their scalability and ease of use on unseen subjects. To overcome these efficiency drawbacks, we propose \OURS, a feed-forward method to generate high-quality Gaussian head avatars from only a few input images while supporting real-time animation. Our approach directly learns a per-pixel Gaussian representation from the input images, and aggregates multi-view information using a transformer-based encoder that fuses image features from both DINOv3 and Stable Diffusion VAE. For real-time animation, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from expression codes. Furthermore, to enhance geometric smoothness of the 3D head, we employ point maps from a pre-trained large reconstruction model as geometry supervision. Experiments show that our approach significantly outperforms existing methods in both rendering quality and inference efficiency, while supporting real-time dynamic avatar animation.
RelightAnyone: A Generalized Relightable 3D Gaussian Head Model
Jan 06, 20263D Gaussian Splatting (3DGS) has become a standard approach to reconstruct and render photorealistic 3D head avatars. A major challenge is to relight the avatars to match any scene illumination. For high quality relighting, existing methods require subjects to be captured under complex time-multiplexed illumination, such as one-light-at-a-time (OLAT). We propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. Our core idea is to learn a mapping from flat-lit 3DGS avatars to corresponding relightable Gaussian parameters for that avatar. Our model consists of two stages: a first stage that models flat-lit 3DGS avatars without OLAT lighting, and a second stage that learns the mapping to physically-based reflectance parameters for high-quality relighting. This two-stage design allows us to train the first stage across diverse existing multi-view datasets without OLAT lighting ensuring cross-subject generalization, where we learn a dataset-specific lighting code for self-supervised lighting alignment. Subsequently, the second stage can be trained on a significantly smaller dataset of subjects captured under OLAT illumination. Together, this allows our method to generalize well and relight any subject from the first stage as if we had captured them under OLAT lighting. Furthermore, we can fit our model to unseen subjects from as little as a single image, allowing several applications in novel view synthesis and relighting for digital avatars.
Monocular Facial Appearance Capture in the Wild
Dec 17, 2024



We present a new method for reconstructing the appearance properties of human faces from a lightweight capture procedure in an unconstrained environment. Our method recovers the surface geometry, diffuse albedo, specular intensity and specular roughness from a monocular video containing a simple head rotation in-the-wild. Notably, we make no simplifying assumptions on the environment lighting, and we explicitly take visibility and occlusions into account. As a result, our method can produce facial appearance maps that approach the fidelity of studio-based multi-view captures, but with a far easier and cheaper procedure.
Gaussian Billboards: Expressive 2D Gaussian Splatting with Textures
Dec 17, 2024Gaussian Splatting has recently emerged as the go-to representation for reconstructing and rendering 3D scenes. The transition from 3D to 2D Gaussian primitives has further improved multi-view consistency and surface reconstruction accuracy. In this work we highlight the similarity between 2D Gaussian Splatting (2DGS) and billboards from traditional computer graphics. Both use flat semi-transparent 2D geometry that is positioned, oriented and scaled in 3D space. However 2DGS uses a solid color per splat and an opacity modulated by a Gaussian distribution, where billboards are more expressive, modulating the color with a uv-parameterized texture. We propose to unify these concepts by presenting Gaussian Billboards, a modification of 2DGS to add spatially-varying color achieved using per-splat texture interpolation. The result is a mixture of the two representations, which benefits from both the robust scene optimization power of 2DGS and the expressiveness of texture mapping. We show that our method can improve the sharpness and quality of the scene representation in a wide range of qualitative and quantitative evaluations compared to the original 2DGS implementation.
Multimodal Conditional 3D Face Geometry Generation
Jul 01, 2024



We present a new method for multimodal conditional 3D face geometry generation that allows user-friendly control over the output identity and expression via a number of different conditioning signals. Within a single model, we demonstrate 3D faces generated from artistic sketches, 2D face landmarks, Canny edges, FLAME face model parameters, portrait photos, or text prompts. Our approach is based on a diffusion process that generates 3D geometry in a 2D parameterized UV domain. Geometry generation passes each conditioning signal through a set of cross-attention layers (IP-Adapter), one set for each user-defined conditioning signal. The result is an easy-to-use 3D face generation tool that produces high resolution geometry with fine-grain user control.
Artist-Friendly Relightable and Animatable Neural Heads
Dec 06, 2023



An increasingly common approach for creating photo-realistic digital avatars is through the use of volumetric neural fields. The original neural radiance field (NeRF) allowed for impressive novel view synthesis of static heads when trained on a set of multi-view images, and follow up methods showed that these neural representations can be extended to dynamic avatars. Recently, new variants also surpassed the usual drawback of baked-in illumination in neural representations, showing that static neural avatars can be relit in any environment. In this work we simultaneously tackle both the motion and illumination problem, proposing a new method for relightable and animatable neural heads. Our method builds on a proven dynamic avatar approach based on a mixture of volumetric primitives, combined with a recently-proposed lightweight hardware setup for relightable neural fields, and includes a novel architecture that allows relighting dynamic neural avatars performing unseen expressions in any environment, even with nearfield illumination and viewpoints.
Fast Neural Representations for Direct Volume Rendering
Dec 02, 2021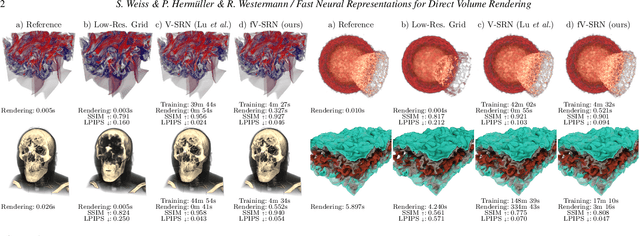

Despite the potential of neural scene representations to effectively compress 3D scalar fields at high reconstruction quality, the computational complexity of the training and data reconstruction step using scene representation networks limits their use in practical applications. In this paper, we analyze whether scene representation networks can be modified to reduce these limitations and whether these architectures can also be used for temporal reconstruction tasks. We propose a novel design of scene representation networks using GPU tensor cores to integrate the reconstruction seamlessly into on-chip raytracing kernels. Furthermore, we investigate the use of image-guided network training as an alternative to classical data-driven approaches, and we explore the potential strengths and weaknesses of this alternative regarding quality and speed. As an alternative to spatial super-resolution approaches for time-varying fields, we propose a solution that builds upon latent-space interpolation to enable random access reconstruction at arbitrary granularity. We summarize our findings in the form of an assessment of the strengths and limitations of scene representation networks for scientific visualization tasks and outline promising future research directions in this field.
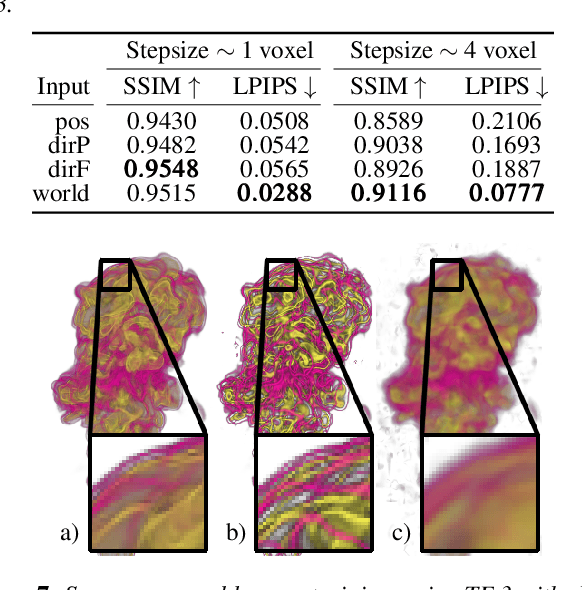
Learning Adaptive Sampling and Reconstruction for Volume Visualization
Jul 20, 2020
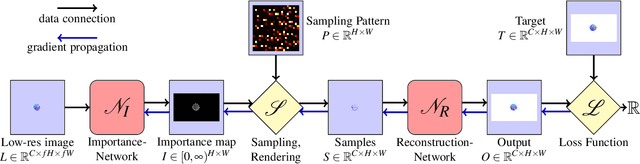
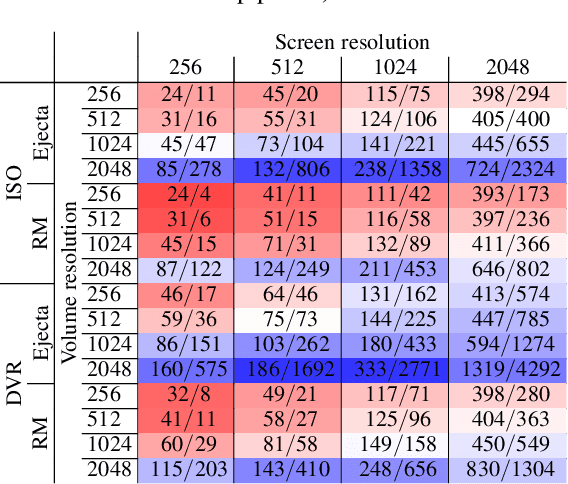
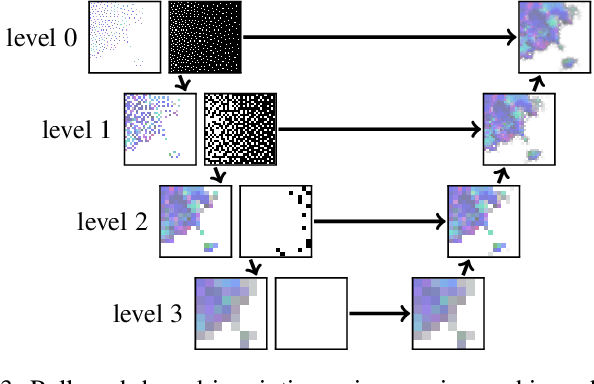
A central challenge in data visualization is to understand which data samples are required to generate an image of a data set in which the relevant information is encoded. In this work, we make a first step towards answering the question of whether an artificial neural network can predict where to sample the data with higher or lower density, by learning of correspondences between the data, the sampling patterns and the generated images. We introduce a novel neural rendering pipeline, which is trained end-to-end to generate a sparse adaptive sampling structure from a given low-resolution input image, and reconstructs a high-resolution image from the sparse set of samples. For the first time, to the best of our knowledge, we demonstrate that the selection of structures that are relevant for the final visual representation can be jointly learned together with the reconstruction of this representation from these structures. Therefore, we introduce differentiable sampling and reconstruction stages, which can leverage back-propagation based on supervised losses solely on the final image. We shed light on the adaptive sampling patterns generated by the network pipeline and analyze its use for volume visualization including isosurface and direct volume rendering.
Volumetric Isosurface Rendering with Deep Learning-Based Super-Resolution
Jun 15, 2019
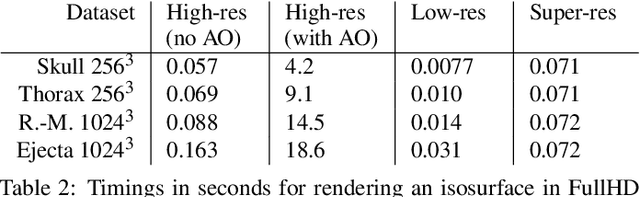
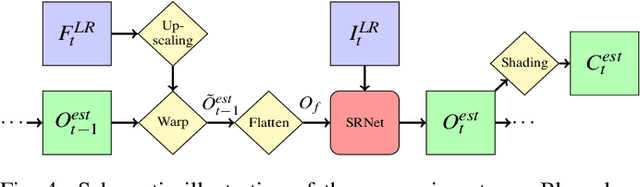
Rendering an accurate image of an isosurface in a volumetric field typically requires large numbers of data samples. Reducing the number of required samples lies at the core of research in volume rendering. With the advent of deep learning networks, a number of architectures have been proposed recently to infer missing samples in multi-dimensional fields, for applications such as image super-resolution and scan completion. In this paper, we investigate the use of such architectures for learning the upscaling of a low-resolution sampling of an isosurface to a higher resolution, with high fidelity reconstruction of spatial detail and shading. We introduce a fully convolutional neural network, to learn a latent representation generating a smooth, edge-aware normal field and ambient occlusions from a low-resolution normal and depth field. By adding a frame-to-frame motion loss into the learning stage, the upscaling can consider temporal variations and achieves improved frame-to-frame coherence. We demonstrate the quality of the network for isosurfaces which were never seen during training, and discuss remote and in-situ visualization as well as focus+context visualization as potential applications