 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Normalized and Geometry-Aware Self-Attention Network for Image Captioning
Mar 19, 2020
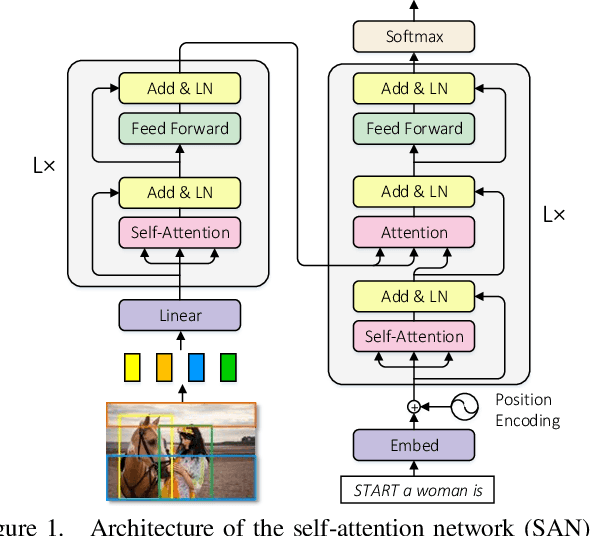
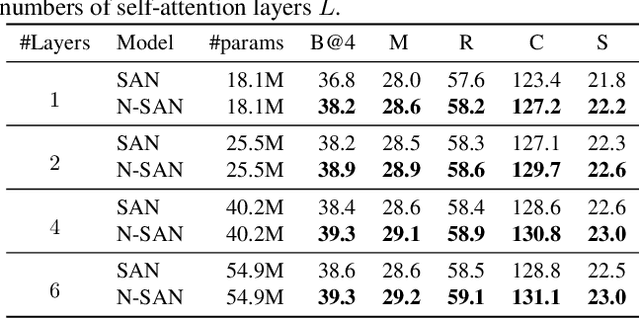
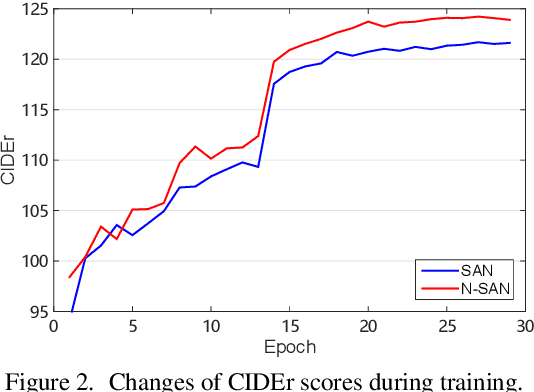
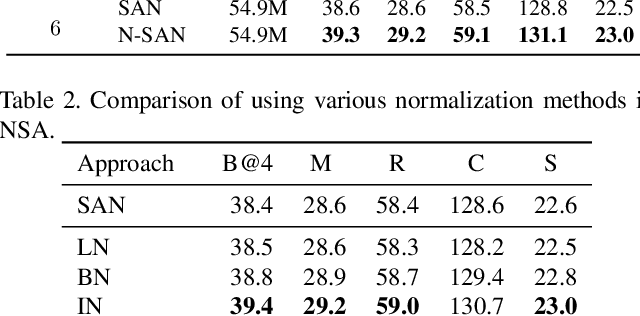
Self-attention (SA) network has shown profound value in image captioning. In this paper, we improve SA from two aspects to promote the performance of image captioning. First, we propose Normalized Self-Attention (NSA), a reparameterization of SA that brings the benefits of normalization inside SA. While normalization is previously only applied outside SA, we introduce a novel normalization method and demonstrate that it is both possible and beneficial to perform it on the hidden activations inside SA. Second, to compensate for the major limit of Transformer that it fails to model the geometry structure of the input objects, we propose a class of Geometry-aware Self-Attention (GSA) that extends SA to explicitly and efficiently consider the relative geometry relations between the objects in the image. To construct our image captioning model, we combine the two modules and apply it to the vanilla self-attention network. We extensively evaluate our proposals on MS-COCO image captioning dataset and superior results are achieved when comparing to state-of-the-art approaches. Further experiments on three challenging tasks, i.e. video captioning, machine translation, and visual question answering, show the generality of our methods.
FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval
May 20, 2020
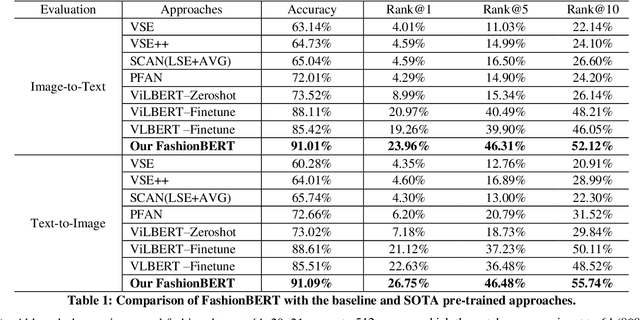
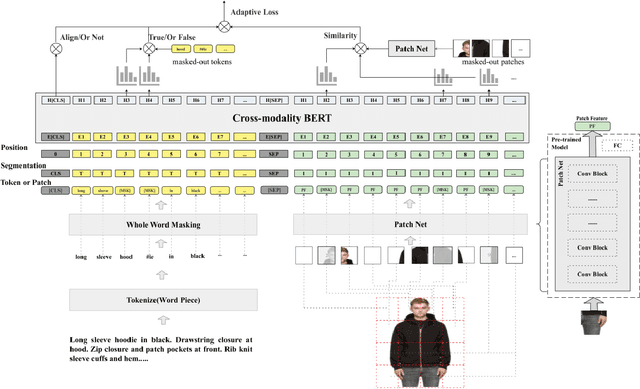
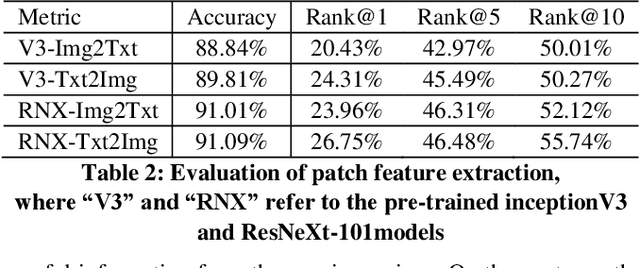
In this paper, we address the text and image matching in cross-modal retrieval of the fashion industry. Different from the matching in the general domain, the fashion matching is required to pay much more attention to the fine-grained information in the fashion images and texts. Pioneer approaches detect the region of interests (i.e., RoIs) from images and use the RoI embeddings as image representations. In general, RoIs tend to represent the "object-level" information in the fashion images, while fashion texts are prone to describe more detailed information, e.g. styles, attributes. RoIs are thus not fine-grained enough for fashion text and image matching. To this end, we propose FashionBERT, which leverages patches as image features. With the pre-trained BERT model as the backbone network, FashionBERT learns high level representations of texts and images. Meanwhile, we propose an adaptive loss to trade off multitask learning in the FashionBERT modeling. Two tasks (i.e., text and image matching and cross-modal retrieval) are incorporated to evaluate FashionBERT. On the public dataset, experiments demonstrate FashionBERT achieves significant improvements in performances than the baseline and state-of-the-art approaches. In practice, FashionBERT is applied in a concrete cross-modal retrieval application. We provide the detailed matching performance and inference efficiency analysis.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021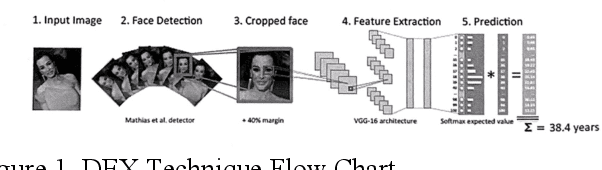
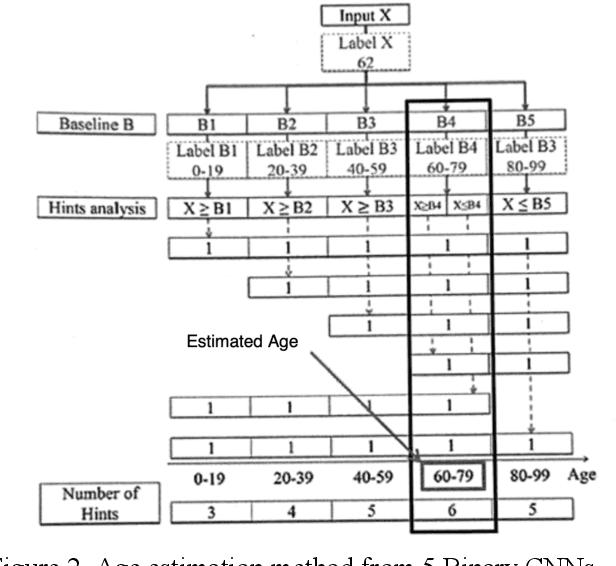
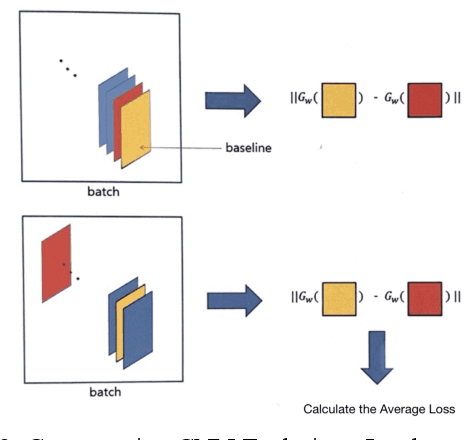
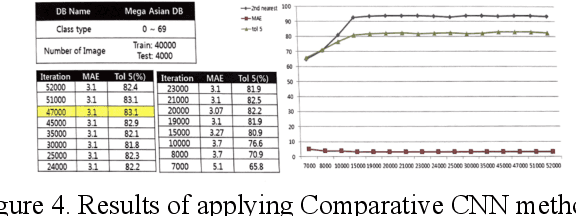
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Fusion of CNNs and statistical indicators to improve image classification
Dec 20, 2020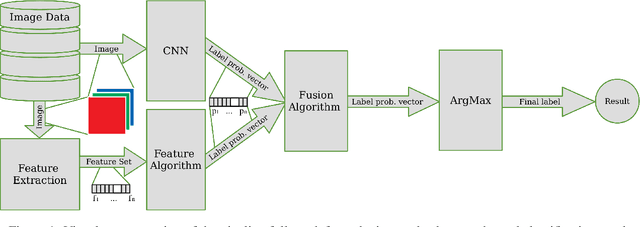

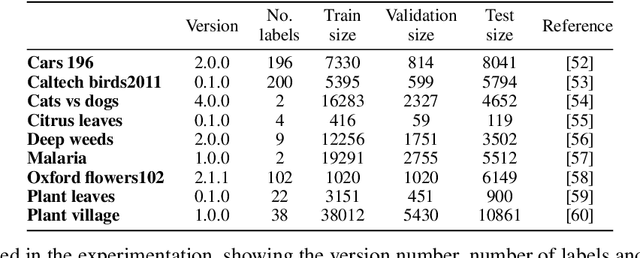
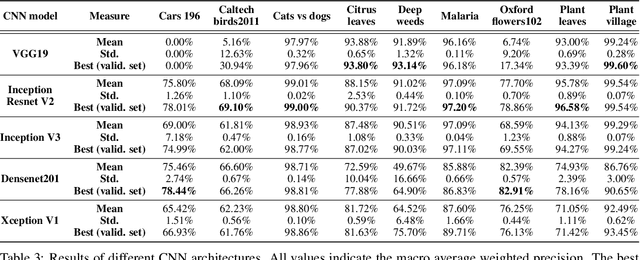
Convolutional Networks have dominated the field of computer vision for the last ten years, exhibiting extremely powerful feature extraction capabilities and outstanding classification performance. The main strategy to prolong this trend relies on further upscaling networks in size. However, costs increase rapidly while performance improvements may be marginal. We hypothesise that adding heterogeneous sources of information may be more cost-effective to a CNN than building a bigger network. In this paper, an ensemble method is proposed for accurate image classification, fusing automatically detected features through Convolutional Neural Network architectures with a set of manually defined statistical indicators. Through a combination of the predictions of a CNN and a secondary classifier trained on statistical features, better classification performance can be cheaply achieved. We test multiple learning algorithms and CNN architectures on a diverse number of datasets to validate our proposal, making public all our code and data via GitHub. According to our results, the inclusion of additional indicators and an ensemble classification approach helps to increase the performance in 8 of 9 datasets, with a remarkable increase of more than 10% precision in two of them.
PolyWorld: Polygonal Building Extraction with Graph Neural Networks in Satellite Images
Nov 30, 2021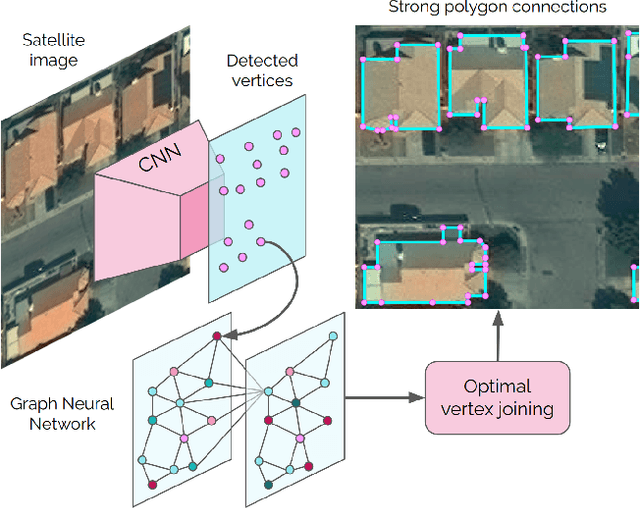
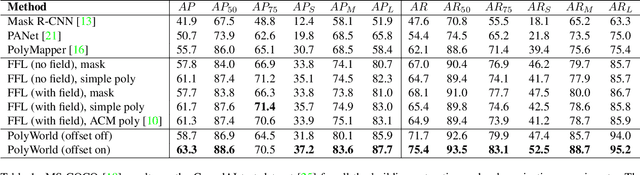
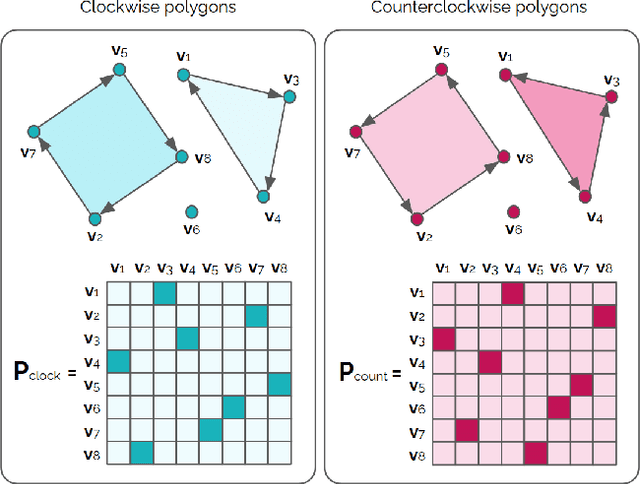
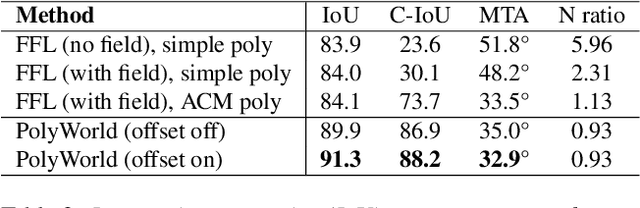
Most state-of-the-art instance segmentation methods produce binary segmentation masks, however, geographic and cartographic applications typically require precise vector polygons of extracted objects instead of rasterized output. This paper introduces PolyWorld, a neural network that directly extracts building vertices from an image and connects them correctly to create precise polygons. The model predicts the connection strength between each pair of vertices using a graph neural network and estimates the assignments by solving a differentiable optimal transport problem. Moreover, the vertex positions are optimized by minimizing a combined segmentation and polygonal angle difference loss. PolyWorld significantly outperforms the state-of-the-art in building polygonization and achieves not only notable quantitative results, but also produces visually pleasing building polygons. Code and trained weights will be soon available on github.
Deep Low-Shot Learning for Biological Image Classification and Visualization from Limited Training Samples
Oct 20, 2020
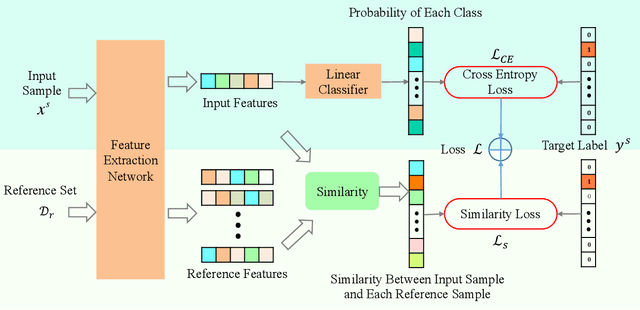
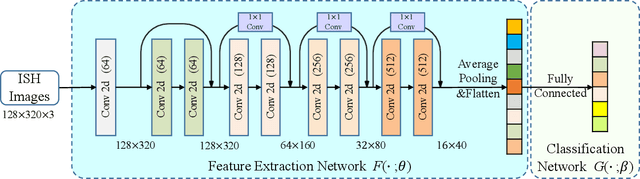
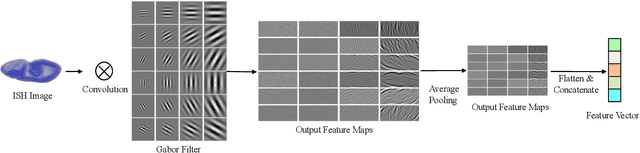
Predictive modeling is useful but very challenging in biological image analysis due to the high cost of obtaining and labeling training data. For example, in the study of gene interaction and regulation in Drosophila embryogenesis, the analysis is most biologically meaningful when in situ hybridization (ISH) gene expression pattern images from the same developmental stage are compared. However, labeling training data with precise stages is very time-consuming even for evelopmental biologists. Thus, a critical challenge is how to build accurate computational models for precise developmental stage classification from limited training samples. In addition, identification and visualization of developmental landmarks are required to enable biologists to interpret prediction results and calibrate models. To address these challenges, we propose a deep two-step low-shot learning framework to accurately classify ISH images using limited training images. Specifically, to enable accurate model training on limited training samples, we formulate the task as a deep low-shot learning problem and develop a novel two-step learning approach, including data-level learning and feature-level learning. We use a deep residual network as our base model and achieve improved performance in the precise stage prediction task of ISH images. Furthermore, the deep model can be interpreted by computing saliency maps, which consist of pixel-wise contributions of an image to its prediction result. In our task, saliency maps are used to assist the identification and visualization of developmental landmarks. Our experimental results show that the proposed model can not only make accurate predictions, but also yield biologically meaningful interpretations. We anticipate our methods to be easily generalizable to other biological image classification tasks with small training datasets.
Image Aesthetics Prediction Using Multiple Patches Preserving the Original Aspect Ratio of Contents
Jul 05, 2020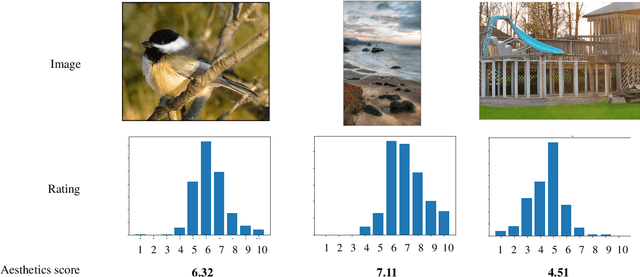
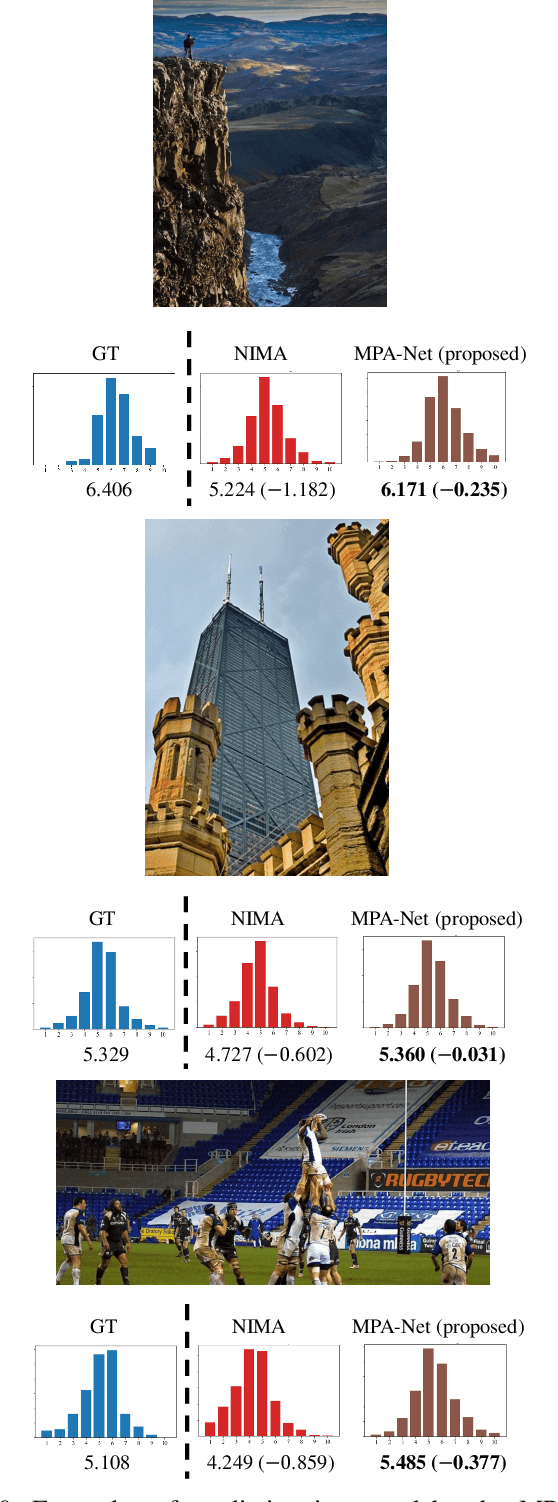
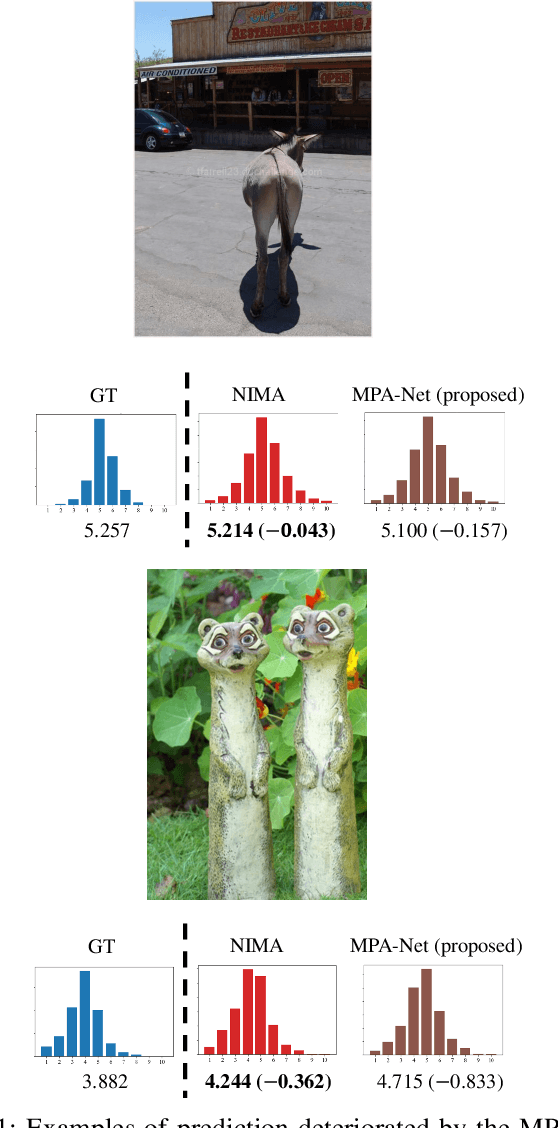
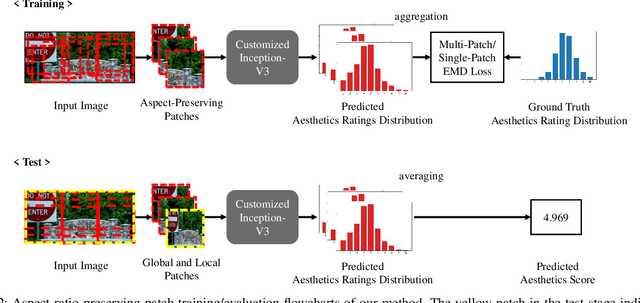
The spread of social networking services has created an increasing demand for selecting, editing, and generating impressive images. This trend increases the importance of evaluating image aesthetics as a complementary function of automatic image processing. We propose a multi-patch method, named MPA-Net (Multi-Patch Aggregation Network), to predict image aesthetics scores by maintaining the original aspect ratios of contents in the images. Through an experiment involving the large-scale AVA dataset, which contains 250,000 images, we show that the effectiveness of the equal-interval multi-patch selection approach for aesthetics score prediction is significant compared to the single-patch prediction and random patch selection approaches. For this dataset, MPA-Net outperforms the neural image assessment algorithm, which was regarded as a baseline method. In particular, MPA-Net yields a 0.073 (11.5%) higher linear correlation coefficient (LCC) of aesthetics scores and a 0.088 (14.4%) higher Spearman's rank correlation coefficient (SRCC). MPA-Net also reduces the mean square error (MSE) by 0.0115 (4.18%) and achieves results for the LCC and SRCC that are comparable to those of the state-of-the-art continuous aesthetics score prediction methods. Most notably, MPA-Net yields a significant lower MSE especially for images with aspect ratios far from 1.0, indicating that MPA-Net is useful for a wide range of image aspect ratios. MPA-Net uses only images and does not require external information during the training nor prediction stages. Therefore, MPA-Net has great potential for applications aside from aesthetics score prediction such as other human subjectivity prediction.
Mammographic Image Enhancement using Digital Image Processing Technique
Jun 29, 2018
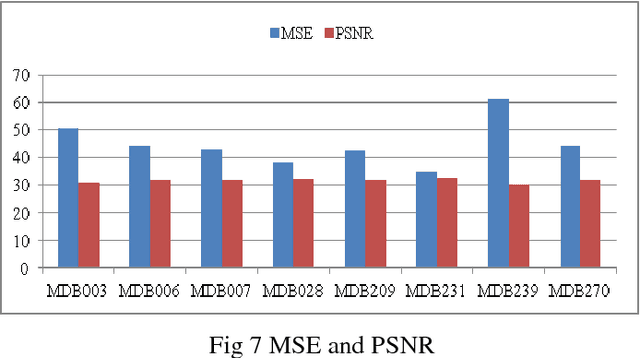
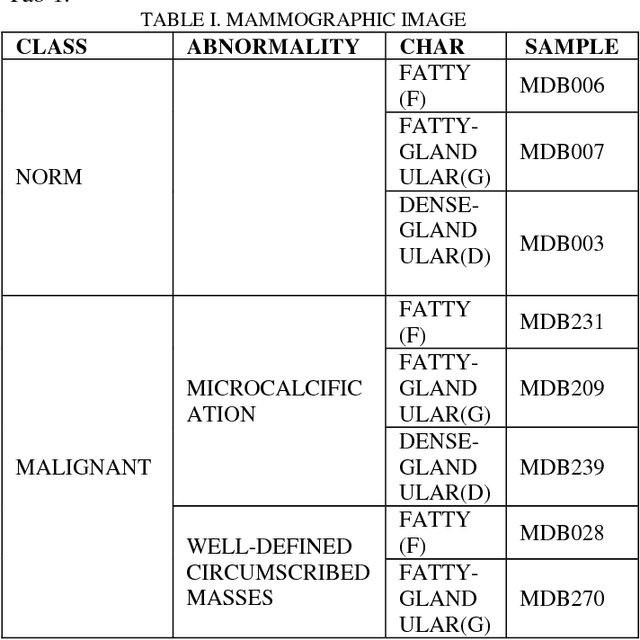
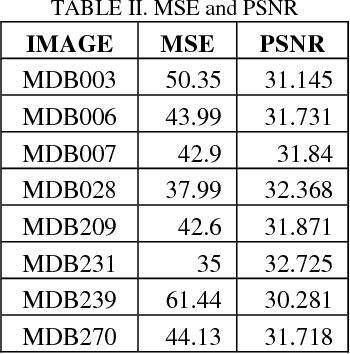
Abstract PURPOSES this study aims to perform microcalsification detection by performing image enhancement in mammography image by using transformation of negative image and histogram equalization. image mammography with .pgm format changed to. jpg format then processed into negative image result then processed again using histogram equalization. the results of the image enhancement process using negative image techniques and equalization histograms are compared and validated with MSE and PSNR on each mammographic image. CONCLUSION: Image enhancement process on mammography image can be done, however there are only some image that have improved quality, this affected by threshold usage, which have important role to get better visualization on mammographic image. Keywords-component; Image enhancement, image negative, histogram equalization, mammographic, breast cancer
Enhanced Object Detection in Floor-plan through Super Resolution
Dec 18, 2021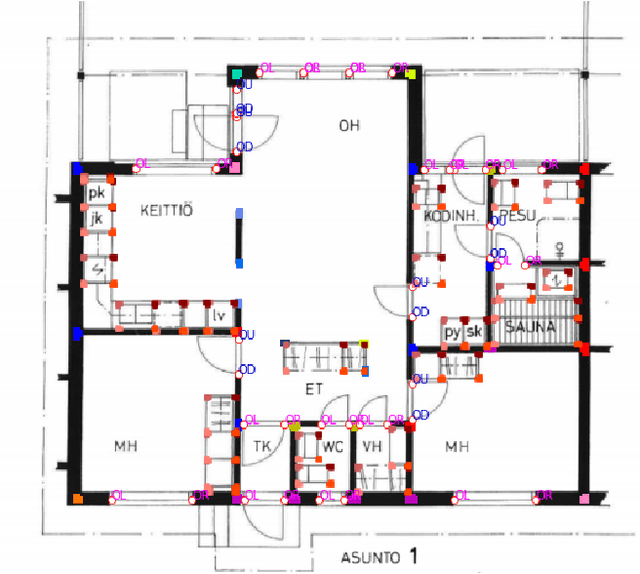
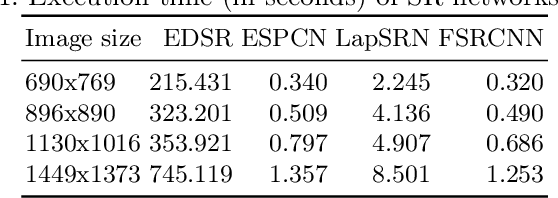
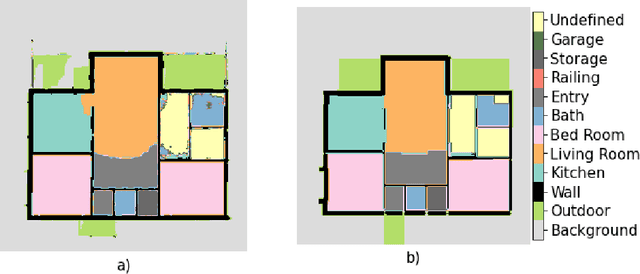
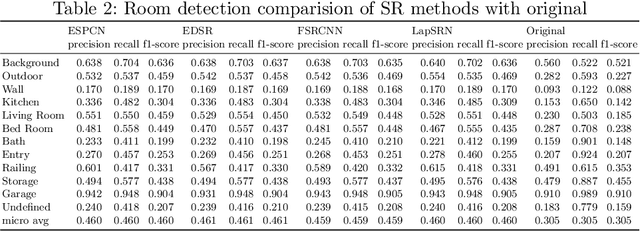
Building Information Modelling (BIM) software use scalable vector formats to enable flexible designing of floor plans in the industry. Floor plans in the architectural domain can come from many sources that may or may not be in scalable vector format. The conversion of floor plan images to fully annotated vector images is a process that can now be realized by computer vision. Novel datasets in this field have been used to train Convolutional Neural Network (CNN) architectures for object detection. Image enhancement through Super-Resolution (SR) is also an established CNN based network in computer vision that is used for converting low resolution images to high resolution ones. This work focuses on creating a multi-component module that stacks a SR model on a floor plan object detection model. The proposed stacked model shows greater performance than the corresponding vanilla object detection model. For the best case, the the inclusion of SR showed an improvement of 39.47% in object detection over the vanilla network. Data and code are made publicly available at https://github.com/rbg-research/Floor-Plan-Detection.
Adversarially Robust Classification by Conditional Generative Model Inversion
Jan 12, 2022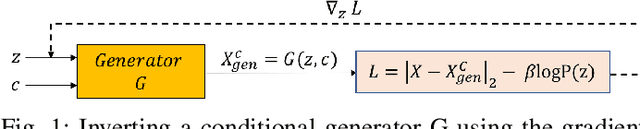

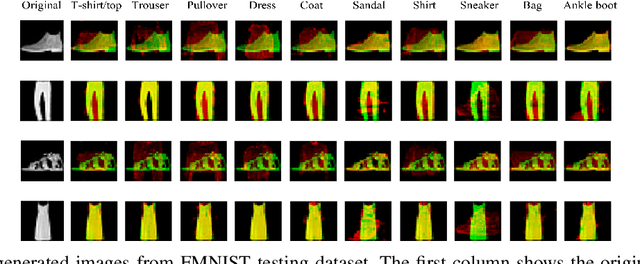

Most adversarial attack defense methods rely on obfuscating gradients. These methods are successful in defending against gradient-based attacks; however, they are easily circumvented by attacks which either do not use the gradient or by attacks which approximate and use the corrected gradient. Defenses that do not obfuscate gradients such as adversarial training exist, but these approaches generally make assumptions about the attack such as its magnitude. We propose a classification model that does not obfuscate gradients and is robust by construction without assuming prior knowledge about the attack. Our method casts classification as an optimization problem where we "invert" a conditional generator trained on unperturbed, natural images to find the class that generates the closest sample to the query image. We hypothesize that a potential source of brittleness against adversarial attacks is the high-to-low-dimensional nature of feed-forward classifiers which allows an adversary to find small perturbations in the input space that lead to large changes in the output space. On the other hand, a generative model is typically a low-to-high-dimensional mapping. While the method is related to Defense-GAN, the use of a conditional generative model and inversion in our model instead of the feed-forward classifier is a critical difference. Unlike Defense-GAN, which was shown to generate obfuscated gradients that are easily circumvented, we show that our method does not obfuscate gradients. We demonstrate that our model is extremely robust against black-box attacks and has improved robustness against white-box attacks compared to naturally trained, feed-forward classifiers.