 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and Light-Weight Network for Single Frame Structured Illumination Microscopy Super-Resolution
Nov 17, 2021
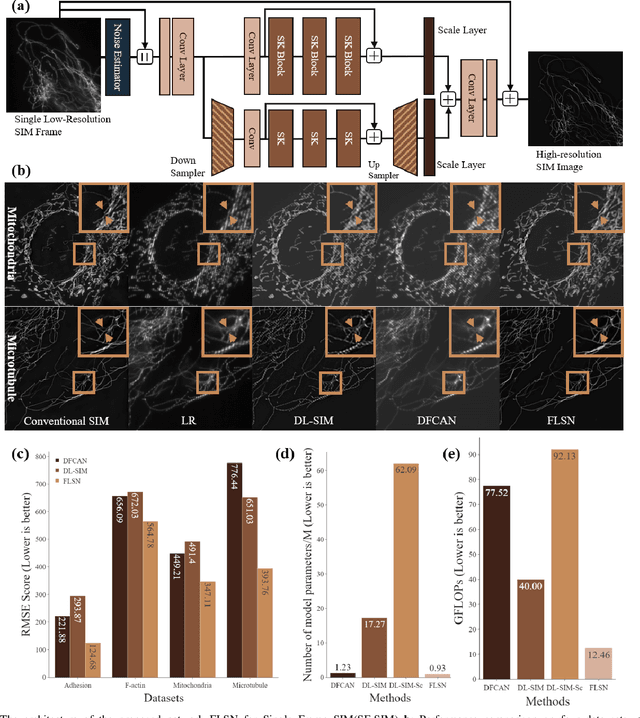
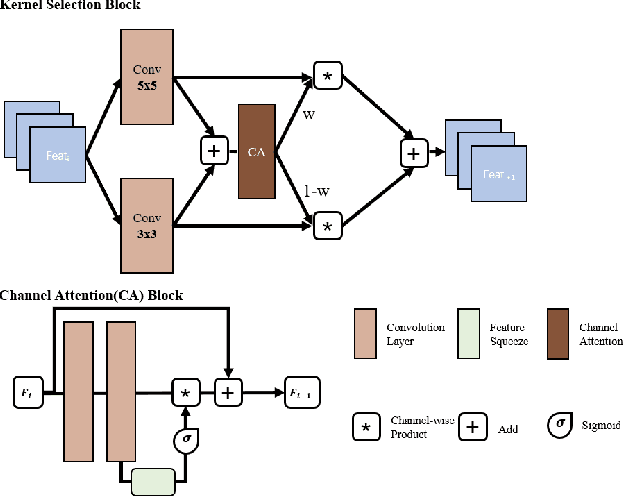
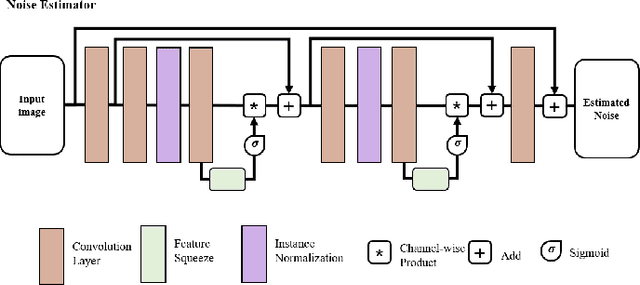
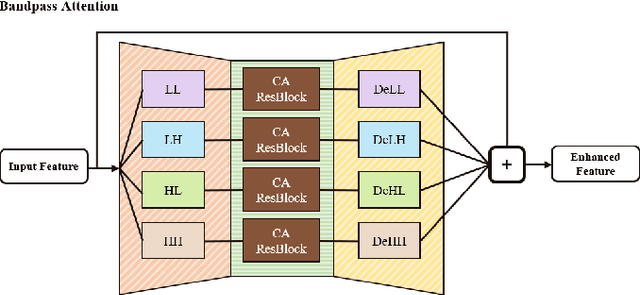
Structured illumination microscopy (SIM) is an important super-resolution based microscopy technique that breaks the diffraction limit and enhances optical microscopy systems. With the development of biology and medical engineering, there is a high demand for real-time and robust SIM imaging under extreme low light and short exposure environments. Existing SIM techniques typically require multiple structured illumination frames to produce a high-resolution image. In this paper, we propose a single-frame structured illumination microscopy (SF-SIM) based on deep learning. Our SF-SIM only needs one shot of a structured illumination frame and generates similar results compared with the traditional SIM systems that typically require 15 shots. In our SF-SIM, we propose a noise estimator which can effectively suppress the noise in the image and enable our method to work under the low light and short exposure environment, without the need for stacking multiple frames for non-local denoising. We also design a bandpass attention module that makes our deep network more sensitive to the change of frequency and enhances the imaging quality. Our proposed SF-SIM is almost 14 times faster than traditional SIM methods when achieving similar results. Therefore, our method is significantly valuable for the development of microbiology and medicine.
HyperionSolarNet: Solar Panel Detection from Aerial Images
Jan 06, 2022

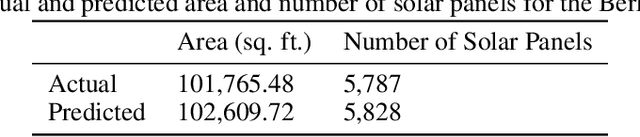
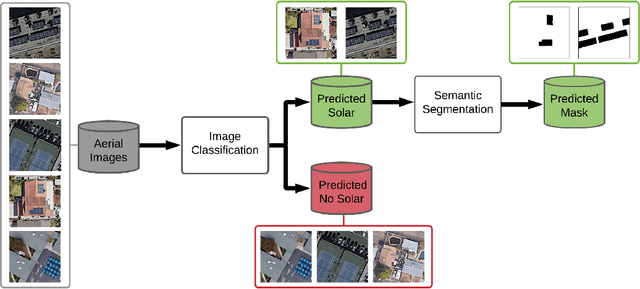
With the effects of global climate change impacting the world, collective efforts are needed to reduce greenhouse gas emissions. The energy sector is the single largest contributor to climate change and many efforts are focused on reducing dependence on carbon-emitting power plants and moving to renewable energy sources, such as solar power. A comprehensive database of the location of solar panels is important to assist analysts and policymakers in defining strategies for further expansion of solar energy. In this paper we focus on creating a world map of solar panels. We identify locations and total surface area of solar panels within a given geographic area. We use deep learning methods for automated detection of solar panel locations and their surface area using aerial imagery. The framework, which consists of a two-branch model using an image classifier in tandem with a semantic segmentation model, is trained on our created dataset of satellite images. Our work provides an efficient and scalable method for detecting solar panels, achieving an accuracy of 0.96 for classification and an IoU score of 0.82 for segmentation performance.
Temporal Feature Fusion with Sampling Pattern Optimization for Multi-echo Gradient Echo Acquisition and Image Reconstruction
Mar 10, 2021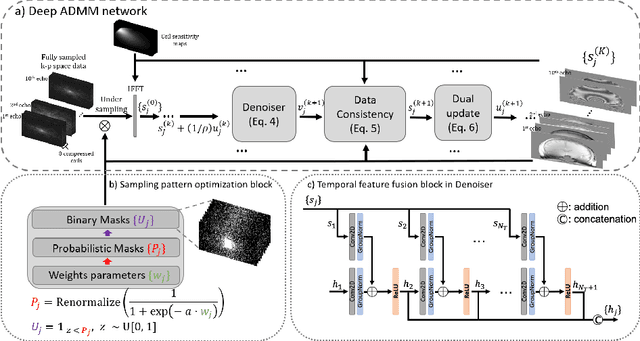
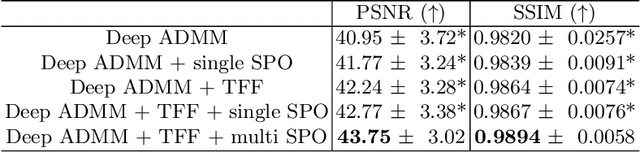
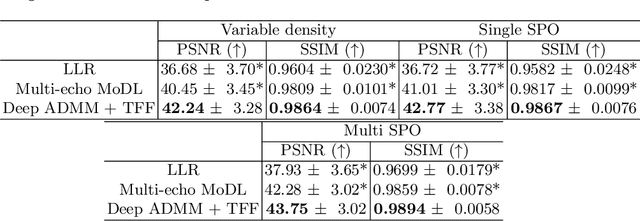
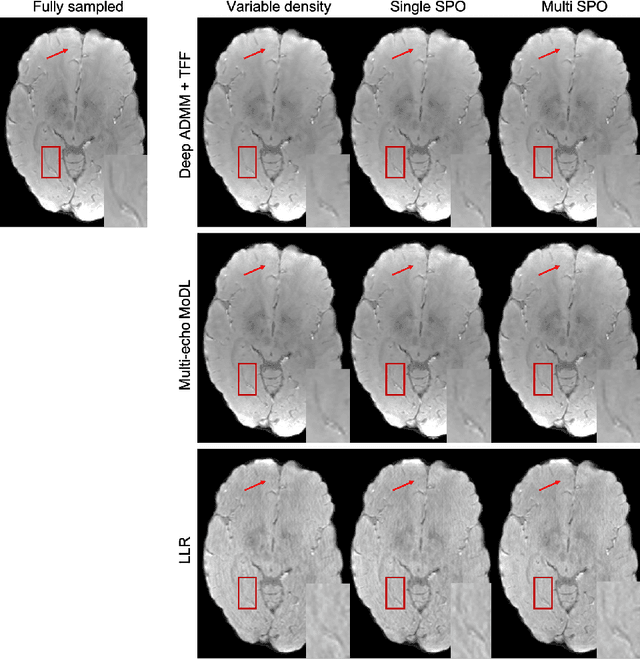
Quantitative imaging in MRI usually involves acquisition and reconstruction of a series of images at multi-echo time points, which possibly requires more scan time and specific reconstruction technique compared to conventional qualitative imaging. In this work, we focus on optimizing the acquisition and reconstruction process of multi-echo gradient echo pulse sequence for quantitative susceptibility mapping as one important quantitative imaging method in MRI. A multi-echo sampling pattern optimization block extended from LOUPE-ST is proposed to optimize the k-space sampling patterns along echoes. Besides, a recurrent temporal feature fusion block is proposed and inserted into a backbone deep ADMM network to capture the signal evolution along echo time during reconstruction. Experiments show that both blocks help improve multi-echo image reconstruction performance.
Generative Modeling with Optimal Transport Maps
Oct 06, 2021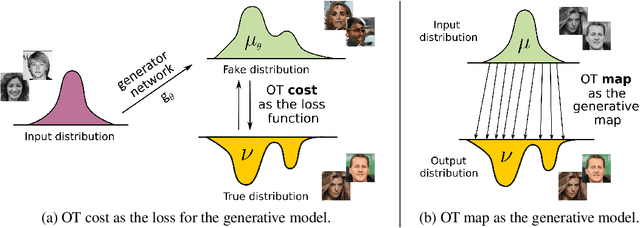

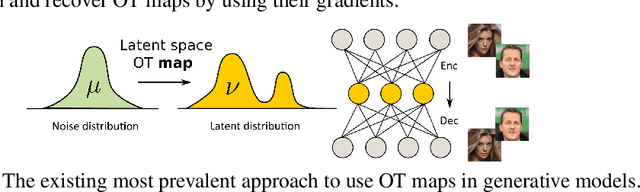

With the discovery of Wasserstein GANs, Optimal Transport (OT) has become a powerful tool for large-scale generative modeling tasks. In these tasks, OT cost is typically used as the loss for training GANs. In contrast to this approach, we show that the OT map itself can be used as a generative model, providing comparable performance. Previous analogous approaches consider OT maps as generative models only in the latent spaces due to their poor performance in the original high-dimensional ambient space. In contrast, we apply OT maps directly in the ambient space, e.g., a space of high-dimensional images. First, we derive a min-max optimization algorithm to efficiently compute OT maps for the quadratic cost (Wasserstein-2 distance). Next, we extend the approach to the case when the input and output distributions are located in the spaces of different dimensions and derive error bounds for the computed OT map. We evaluate the algorithm on image generation and unpaired image restoration tasks. In particular, we consider denoising, colorization, and inpainting, where the optimality of the restoration map is a desired attribute, since the output (restored) image is expected to be close to the input (degraded) one.
Combining Spiking Neural Network and Artificial Neural Network for Enhanced Image Classification
Feb 28, 2021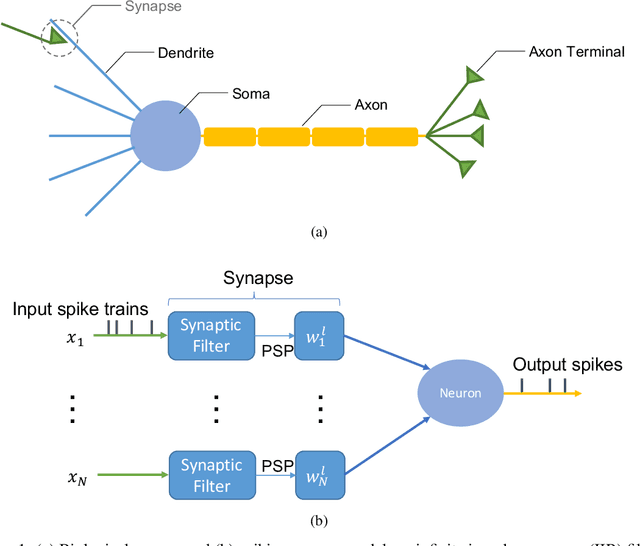
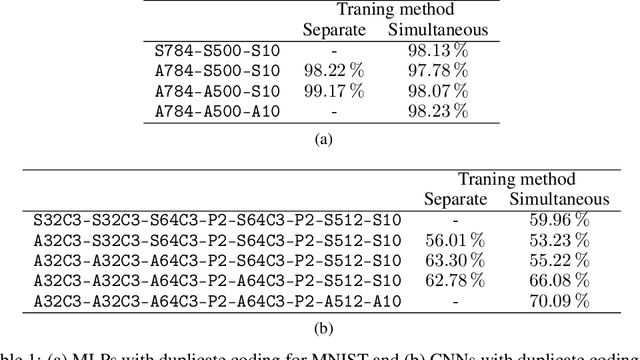
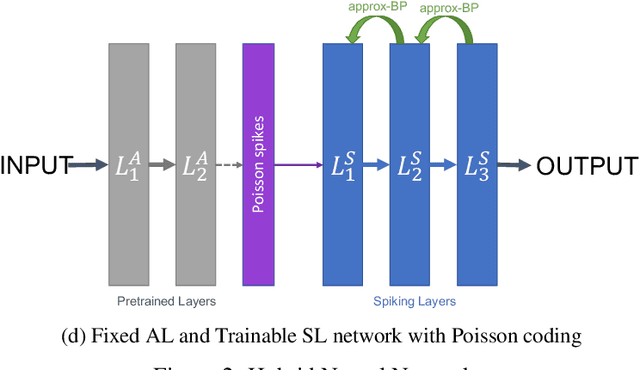

With the continued innovations of deep neural networks, spiking neural networks (SNNs) that more closely resemble biological brain synapses have attracted attention owing to their low power consumption.However, for continuous data values, they must employ a coding process to convert the values to spike trains.Thus, they have not yet exceeded the performance of artificial neural networks (ANNs), which handle such values directly.To this end, we combine an ANN and an SNN to build versatile hybrid neural networks (HNNs) that improve the concerned performance.To qualify this performance, MNIST and CIFAR-10 image datasets are used for various classification tasks in which the training and coding methods changes.In addition, we present simultaneous and separate methods to train the artificial and spiking layers, considering the coding methods of each.We find that increasing the number of artificial layers at the expense of spiking layers improves the HNN performance.For straightforward datasets such as MNIST, it is easy to achieve the same performance as ANNs by using duplicate coding and separate learning.However, for more complex tasks, the use of Gaussian coding and simultaneous learning is found to improve the accuracy of HNNs while utilizing a smaller number of artificial layers.
Search for temporal cell segmentation robustness in phase-contrast microscopy videos
Dec 16, 2021Studying cell morphology changes in time is critical to understanding cell migration mechanisms. In this work, we present a deep learning-based workflow to segment cancer cells embedded in 3D collagen matrices and imaged with phase-contrast microscopy. Our approach uses transfer learning and recurrent convolutional long-short term memory units to exploit the temporal information from the past and provide a consistent segmentation result. Lastly, we propose a geometrical-characterization approach to studying cancer cell morphology. Our approach provides stable results in time, and it is robust to the different weight initialization or training data sampling. We introduce a new annotated dataset for 2D cell segmentation and tracking, and an open-source implementation to replicate the experiments or adapt them to new image processing problems.
Optimal Estimation and Computational Limit of Low-rank Gaussian Mixtures
Jan 22, 2022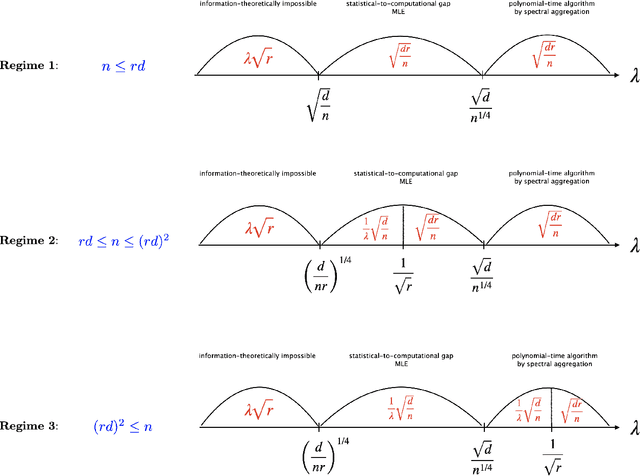
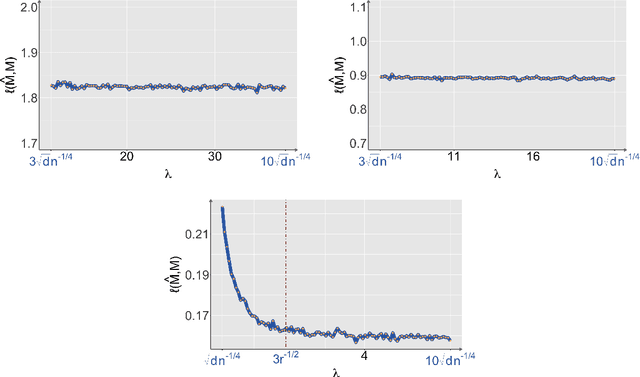
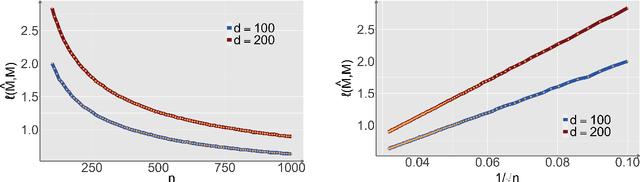
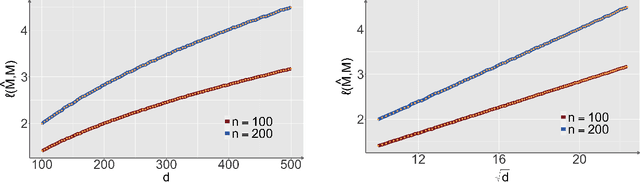
Structural matrix-variate observations routinely arise in diverse fields such as multi-layer network analysis and brain image clustering. While data of this type have been extensively investigated with fruitful outcomes being delivered, the fundamental questions like its statistical optimality and computational limit are largely under-explored. In this paper, we propose a low-rank Gaussian mixture model (LrMM) assuming each matrix-valued observation has a planted low-rank structure. Minimax lower bounds for estimating the underlying low-rank matrix are established allowing a whole range of sample sizes and signal strength. Under a minimal condition on signal strength, referred to as the information-theoretical limit or statistical limit, we prove the minimax optimality of a maximum likelihood estimator which, in general, is computationally infeasible. If the signal is stronger than a certain threshold, called the computational limit, we design a computationally fast estimator based on spectral aggregation and demonstrate its minimax optimality. Moreover, when the signal strength is smaller than the computational limit, we provide evidences based on the low-degree likelihood ratio framework to claim that no polynomial-time algorithm can consistently recover the underlying low-rank matrix. Our results reveal multiple phase transitions in the minimax error rates and the statistical-to-computational gap. Numerical experiments confirm our theoretical findings. We further showcase the merit of our spectral aggregation method on the worldwide food trading dataset.
Gated Texture CNN for Efficient and Configurable Image Denoising
Apr 20, 2020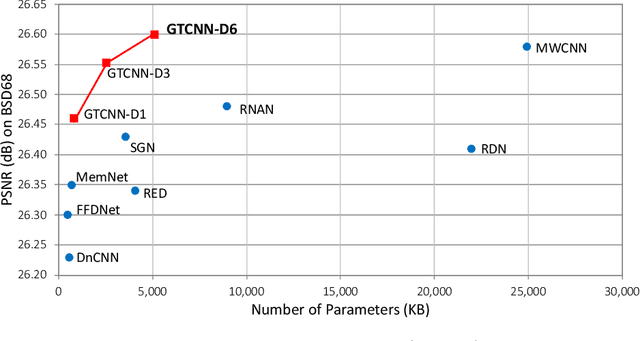
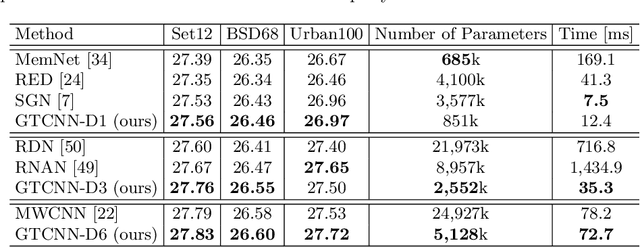
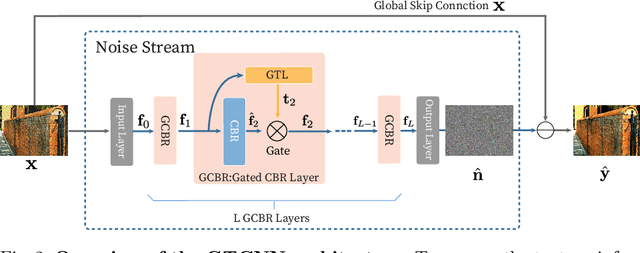
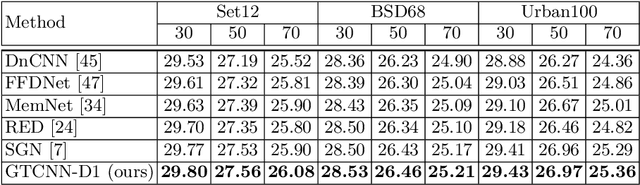
Convolutional neural network (CNN)-based image denoising methods typically estimate the noise component contained in a noisy input image and restore a clean image by subtracting the estimated noise from the input. However, previous denoising methods tend to remove high-frequency information (e.g., textures) from the input. It caused by intermediate feature maps of CNN contains texture information. A straightforward approach to this problem is stacking numerous layers, which leads to a high computational cost. To achieve high performance and computational efficiency, we propose a gated texture CNN (GTCNN), which is designed to carefully exclude the texture information from each intermediate feature map of the CNN by incorporating gating mechanisms. Our GTCNN achieves state-of-the-art performance with 4.8 times fewer parameters than previous state-of-the-art methods. Furthermore, the GTCNN allows us to interactively control the texture strength in the output image without any additional modules, training, or computational costs.
Graph Neural Networks for Cross-Camera Data Association
Jan 17, 2022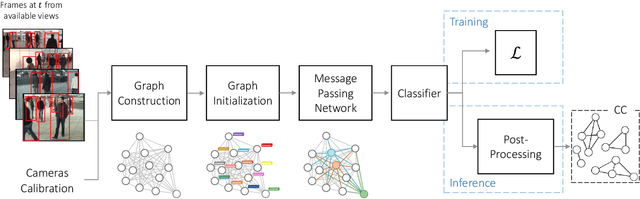
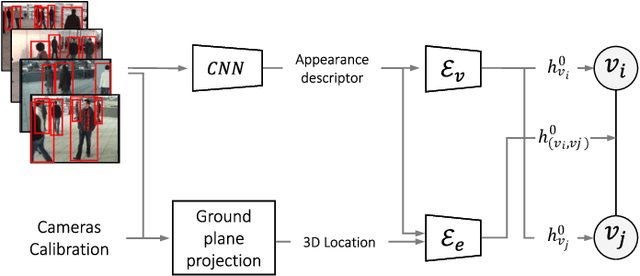
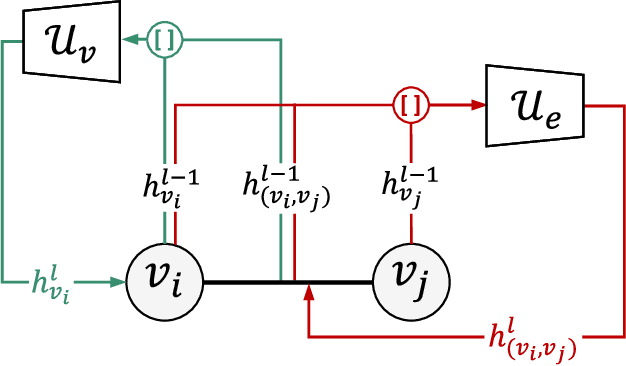
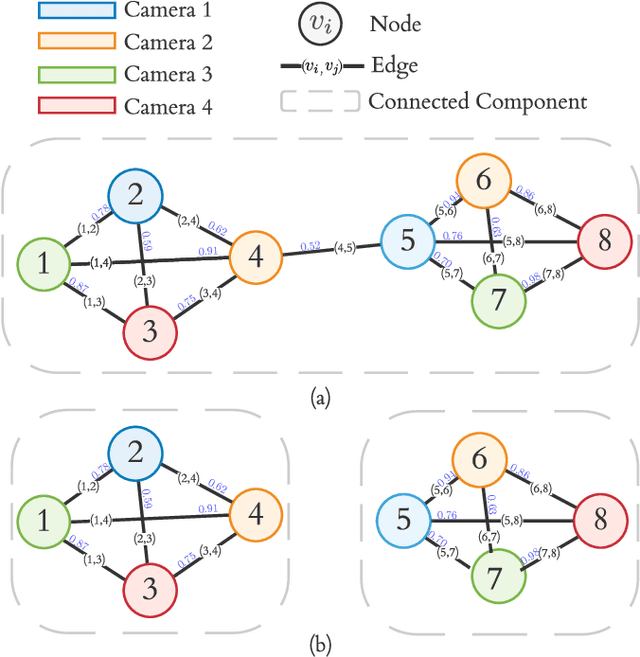
Cross-camera image data association is essential for many multi-camera computer vision tasks, such as multi-camera pedestrian detection, multi-camera multi-target tracking, 3D pose estimation, etc. This association task is typically stated as a bipartite graph matching problem and often solved by applying minimum-cost flow techniques, which may be computationally inefficient with large data. Furthermore, cameras are usually treated by pairs, obtaining local solutions, rather than finding a global solution at once. Other key issue is that of the affinity measurement: the widespread usage of non-learnable pre-defined distances, such as the Euclidean and Cosine ones. This paper proposes an efficient approach for cross-cameras data-association focused on a global solution, instead of processing cameras by pairs. To avoid the usage of fixed distances, we leverage the connectivity of Graph Neural Networks, previously unused in this scope, using a Message Passing Network to jointly learn features and similarity. We validate the proposal for pedestrian multi-view association, showing results over the EPFL multi-camera pedestrian dataset. Our approach considerably outperforms the literature data association techniques, without requiring to be trained in the same scenario in which it is tested. Our code is available at \url{http://www-vpu.eps.uam.es/publications/gnn_cca}.
MRI Recovery with A Self-calibrated Denoiser
Oct 18, 2021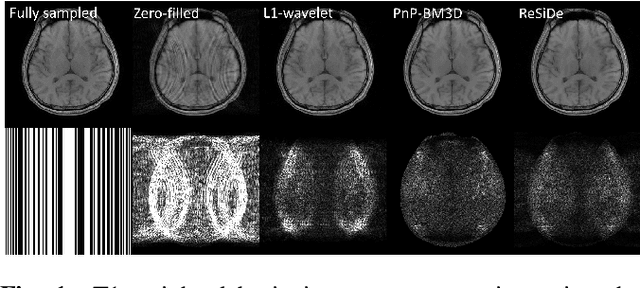
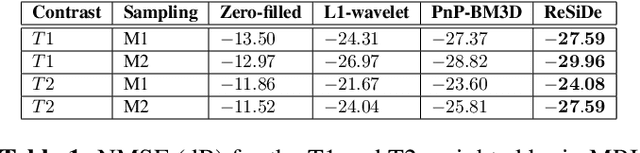
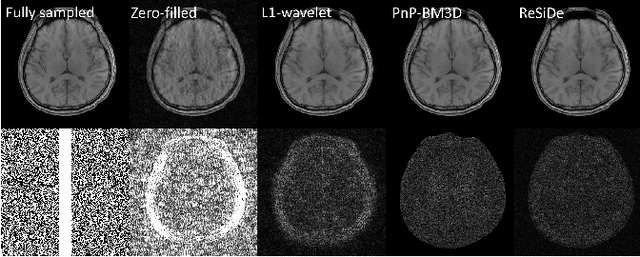
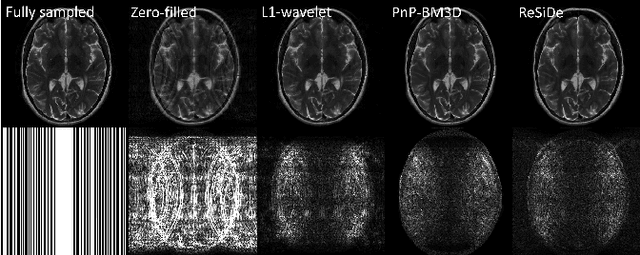
Plug-and-play (PnP) methods that employ application-specific denoisers have been proposed to solve inverse problems, including MRI reconstruction. However, training application-specific denoisers is not feasible for many applications due to the lack of training data. In this work, we propose a PnP-inspired recovery method that does not require data beyond the single, incomplete set of measurements. The proposed method, called recovery with a self-calibrated denoiser (ReSiDe), trains the denoiser from the patches of the image being recovered. The denoiser training and a call to the denoising subroutine are performed in each iteration of a PnP algorithm, leading to a progressive refinement of the reconstructed image. For validation, we compare ReSiDe with a compressed sensing-based method and a PnP method with BM3D denoising using single-coil MRI brain data.