 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Distracted Driver Detection via Vision Language Models with Double Decoupling
Jan 13, 2026Distracted driving is a major cause of traffic collisions, calling for robust and scalable detection methods. Vision-language models (VLMs) enable strong zero-shot image classification, but existing VLM-based distracted driver detectors often underperform in real-world conditions. We identify subject-specific appearance variations (e.g., clothing, age, and gender) as a key bottleneck: VLMs entangle these factors with behavior cues, leading to decisions driven by who the driver is rather than what the driver is doing. To address this, we propose a subject decoupling framework that extracts a driver appearance embedding and removes its influence from the image embedding prior to zero-shot classification, thereby emphasizing distraction-relevant evidence. We further orthogonalize text embeddings via metric projection onto Stiefel manifold to improve separability while staying close to the original semantics. Experiments demonstrate consistent gains over prior baselines, indicating the promise of our approach for practical road-safety applications.
Interpretable Image Quality Assessment via CLIP with Multiple Antonym-Prompt Pairs
Aug 24, 2023No reference image quality assessment (NR-IQA) is a task to estimate the perceptual quality of an image without its corresponding original image. It is even more difficult to perform this task in a zero-shot manner, i.e., without task-specific training. In this paper, we propose a new zero-shot and interpretable NRIQA method that exploits the ability of a pre-trained visionlanguage model to estimate the correlation between an image and a textual prompt. The proposed method employs a prompt pairing strategy and multiple antonym-prompt pairs corresponding to carefully selected descriptive features corresponding to the perceptual image quality. Thus, the proposed method is able to identify not only the perceptual quality evaluation of the image, but also the cause on which the quality evaluation is based. Experimental results show that the proposed method outperforms existing zero-shot NR-IQA methods in terms of accuracy and can evaluate the causes of perceptual quality degradation.
Gated Texture CNN for Efficient and Configurable Image Denoising
Apr 20, 2020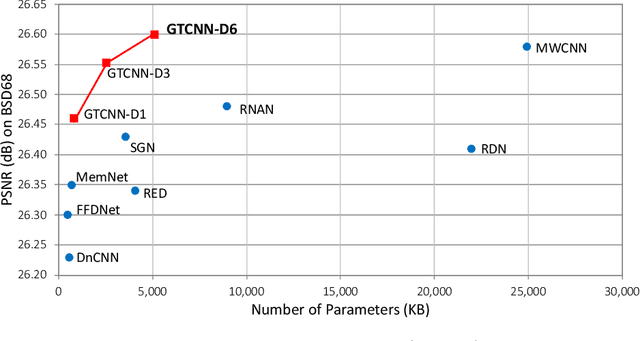
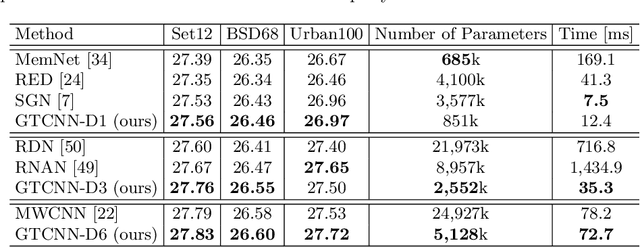
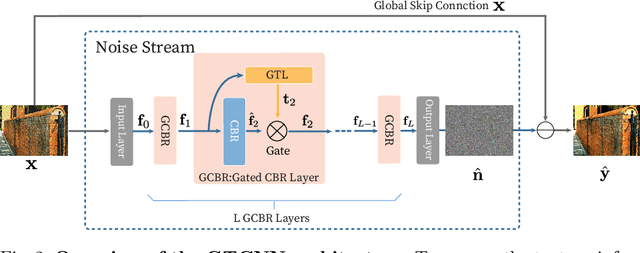
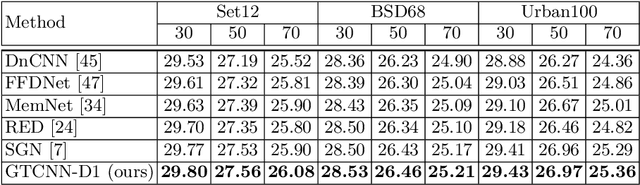
Convolutional neural network (CNN)-based image denoising methods typically estimate the noise component contained in a noisy input image and restore a clean image by subtracting the estimated noise from the input. However, previous denoising methods tend to remove high-frequency information (e.g., textures) from the input. It caused by intermediate feature maps of CNN contains texture information. A straightforward approach to this problem is stacking numerous layers, which leads to a high computational cost. To achieve high performance and computational efficiency, we propose a gated texture CNN (GTCNN), which is designed to carefully exclude the texture information from each intermediate feature map of the CNN by incorporating gating mechanisms. Our GTCNN achieves state-of-the-art performance with 4.8 times fewer parameters than previous state-of-the-art methods. Furthermore, the GTCNN allows us to interactively control the texture strength in the output image without any additional modules, training, or computational costs.