 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Warwick Image Forensics Dataset for Device Fingerprinting In Multimedia Forensics
May 07, 2020
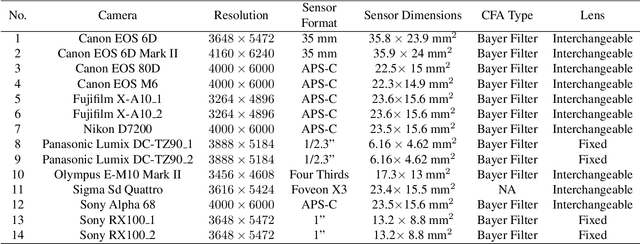

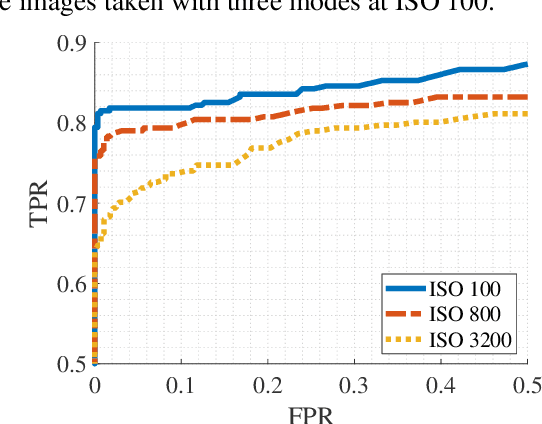
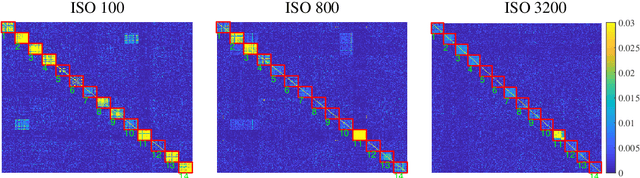
Device fingerprints like sensor pattern noise (SPN) are widely used for provenance analysis and image authentication. Over the past few years, the rapid advancement in digital photography has greatly reshaped the pipeline of image capturing process on consumer-level mobile devices. The flexibility of camera parameter settings and the emergence of multi-frame photography algorithms, especially high dynamic range (HDR) imaging, bring new challenges to device fingerprinting. The subsequent study on these topics requires a new purposefully built image dataset. In this paper, we present the Warwick Image Forensics Dataset, an image dataset of more than 58,600 images captured using 14 digital cameras with various exposure settings. Special attention to the exposure settings allows the images to be adopted by different multi-frame computational photography algorithms and for subsequent device fingerprinting. The dataset is released as an open-source, free for use for the digital forensic community.
Semi-supervised Identification and Mapping of Surface Water Extent using Street-level Monitoring Videos
Jan 31, 2022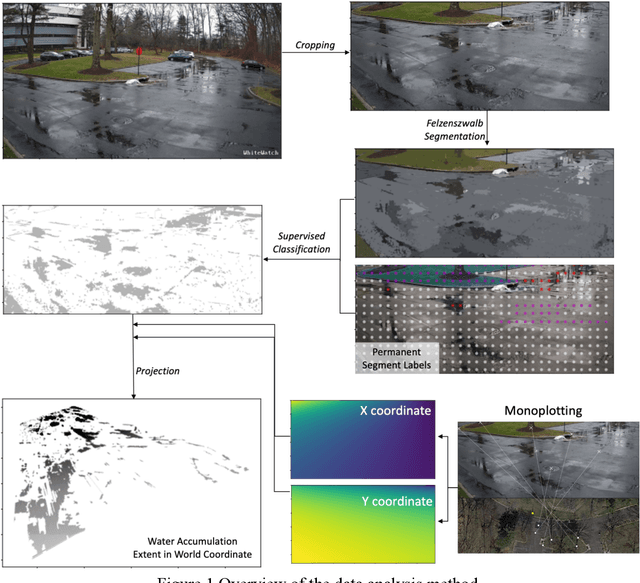



Urban flooding is becoming a common and devastating hazard to cause life loss and economic damage. Monitoring and understanding urban flooding in the local scale is a challenging task due to the complicated urban landscape, intricate hydraulic process, and the lack of high-quality and resolution data. The emerging smart city technology such as monitoring cameras provides an unprecedented opportunity to address the data issue. However, estimating the water accumulation on the land surface based on the monitoring footage is unreliable using the traditional segmentation technique because the boundary of the water accumulation, under the influence of varying weather, background, and illumination, is usually too fuzzy to identify, and the oblique angle and image distortion in the video monitoring data prevents georeferencing and object-based measurements. This paper presents a novel semi-supervised segmentation scheme for surface water extent recognition from the footage of an oblique monitoring camera. The semi-supervised segmentation algorithm was found suitable to determine the water boundary and the monoplotting method was successfully applied to georeference the pixels of the monitoring video for the virtual quantification of the local drainage process. The correlation and mechanism-based analysis demonstrates the value of the proposed method in advancing the understanding of local drainage hydraulics. The workflow and created methods in this study has a great potential to study other street-level and earth surface processes.
Deep Learning-Based Detail Map Estimation for MultiSpectral Image Fusion in Remote Sensing
Feb 07, 2021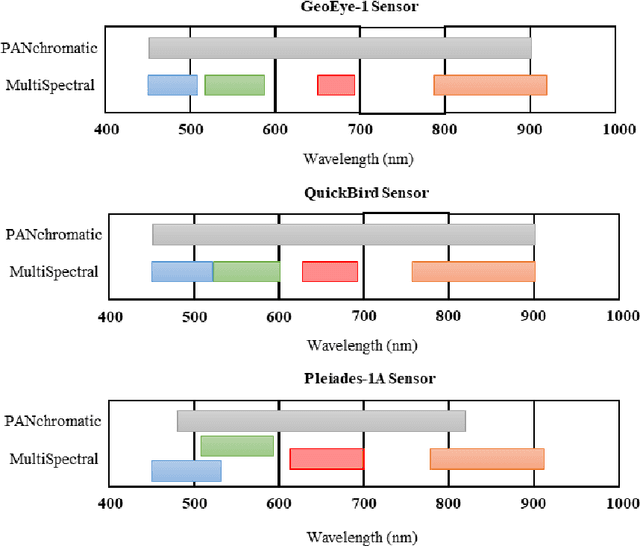
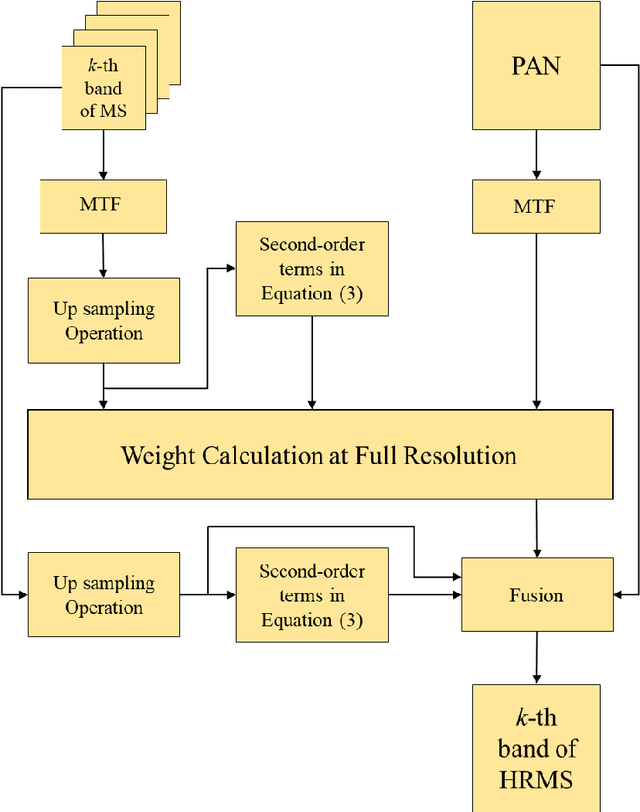
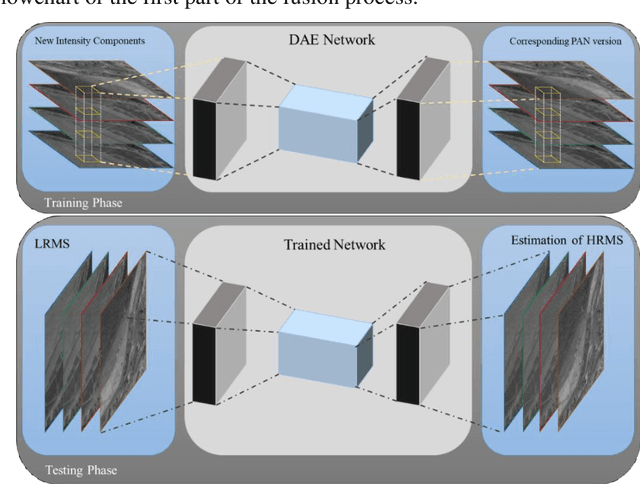

This paper presents a deep learning-based estimation of the intensity component of MultiSpectral bands by considering joint multiplication of the neighbouring spectral bands. This estimation is conducted as part of the component substitution approach for fusion of PANchromatic and MultiSpectral images in remote sensing. After computing the band dependent intensity components, a deep neural network is trained to learn the nonlinear relationship between a PAN image and its nonlinear intensity components. Low Resolution MultiSpectral bands are then fed into the trained network to obtain an estimate of High Resolution MultiSpectral bands. Experiments conducted on three datasets show that the developed deep learning-based estimation approach provides improved performance compared to the existing methods based on three objective metrics.
A hypothesis-driven method based on machine learning for neuroimaging data analysis
Feb 09, 2022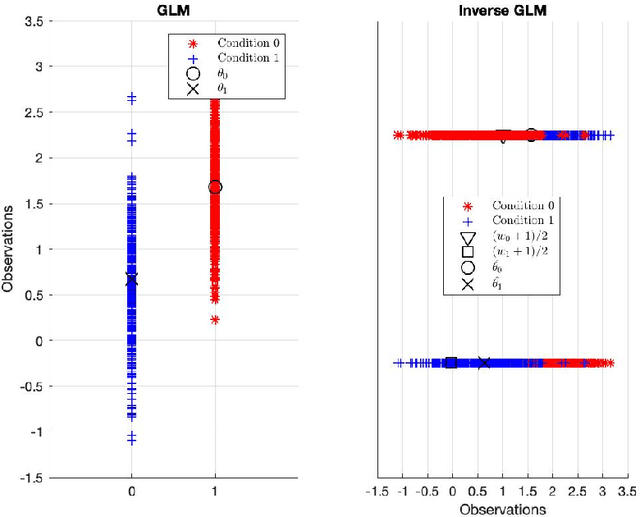

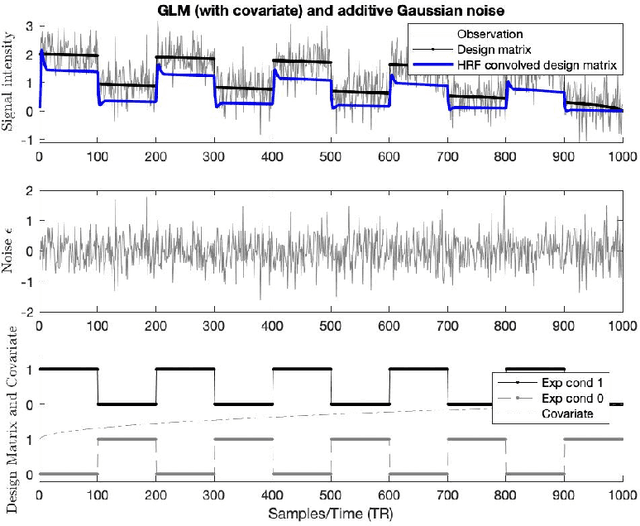
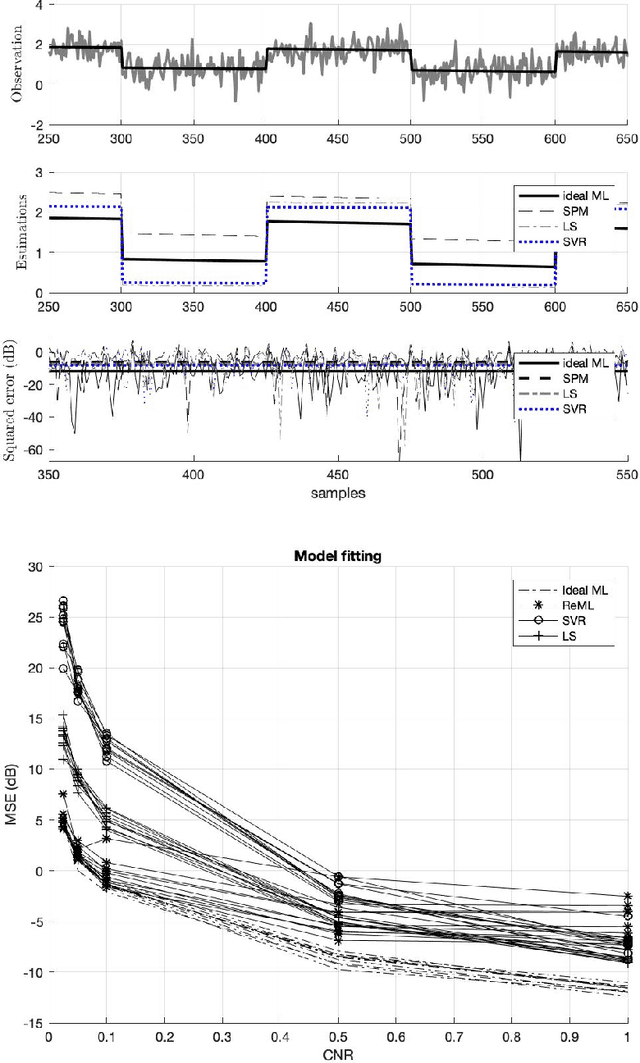
There remains an open question about the usefulness and the interpretation of Machine learning (MLE) approaches for discrimination of spatial patterns of brain images between samples or activation states. In the last few decades, these approaches have limited their operation to feature extraction and linear classification tasks for between-group inference. In this context, statistical inference is assessed by randomly permuting image labels or by the use of random effect models that consider between-subject variability. These multivariate MLE-based statistical pipelines, whilst potentially more effective for detecting activations than hypotheses-driven methods, have lost their mathematical elegance, ease of interpretation, and spatial localization of the ubiquitous General linear Model (GLM). Recently, the estimation of the conventional GLM has been demonstrated to be connected to an univariate classification task when the design matrix is expressed as a binary indicator matrix. In this paper we explore the complete connection between the univariate GLM and MLE \emph{regressions}. To this purpose we derive a refined statistical test with the GLM based on the parameters obtained by a linear Support Vector Regression (SVR) in the \emph{inverse} problem (SVR-iGLM). Subsequently, random field theory (RFT) is employed for assessing statistical significance following a conventional GLM benchmark. Experimental results demonstrate how parameter estimations derived from each model (mainly GLM and SVR) result in different experimental design estimates that are significantly related to the predefined functional task. Moreover, using real data from a multisite initiative the proposed MLE-based inference demonstrates statistical power and the control of false positives, outperforming the regular GLM.
Finding Directions in GAN's Latent Space for Neural Face Reenactment
Jan 31, 2022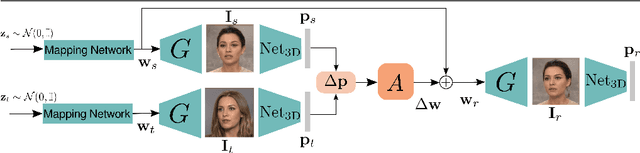
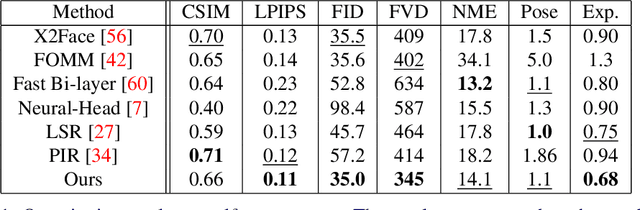
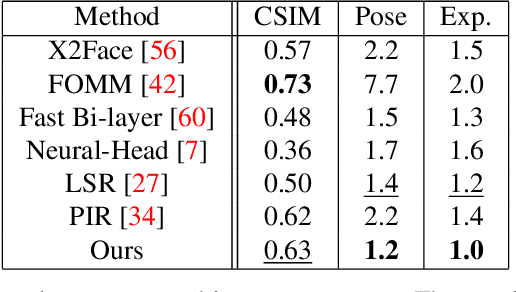

This paper is on face/head reenactment where the goal is to transfer the facial pose (3D head orientation and expression) of a target face to a source face. Previous methods focus on learning embedding networks for identity and pose disentanglement which proves to be a rather hard task, degrading the quality of the generated images. We take a different approach, bypassing the training of such networks, by using (fine-tuned) pre-trained GANs which have been shown capable of producing high-quality facial images. Because GANs are characterized by weak controllability, the core of our approach is a method to discover which directions in latent GAN space are responsible for controlling facial pose and expression variations. We present a simple pipeline to learn such directions with the aid of a 3D shape model which, by construction, already captures disentangled directions for facial pose, identity and expression. Moreover, we show that by embedding real images in the GAN latent space, our method can be successfully used for the reenactment of real-world faces. Our method features several favorable properties including using a single source image (one-shot) and enabling cross-person reenactment. Our qualitative and quantitative results show that our approach often produces reenacted faces of significantly higher quality than those produced by state-of-the-art methods for the standard benchmarks of VoxCeleb1 & 2.
Text-Free Image-to-Speech Synthesis Using Learned Segmental Units
Dec 31, 2020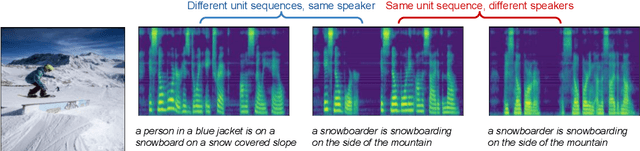
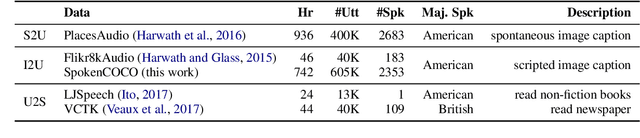
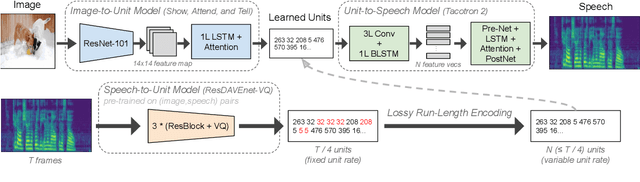
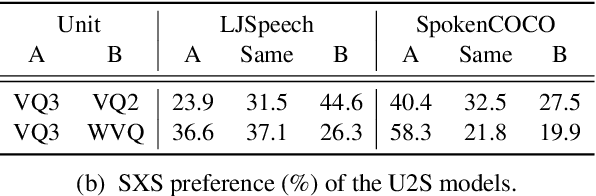
In this paper we present the first model for directly synthesizing fluent, natural-sounding spoken audio captions for images that does not require natural language text as an intermediate representation or source of supervision. Instead, we connect the image captioning module and the speech synthesis module with a set of discrete, sub-word speech units that are discovered with a self-supervised visual grounding task. We conduct experiments on the Flickr8k spoken caption dataset in addition to a novel corpus of spoken audio captions collected for the popular MSCOCO dataset, demonstrating that our generated captions also capture diverse visual semantics of the images they describe. We investigate several different intermediate speech representations, and empirically find that the representation must satisfy several important properties to serve as drop-in replacements for text.
Unsupervised Learning of Image Segmentation Based on Differentiable Feature Clustering
Jul 20, 2020



The usage of convolutional neural networks (CNNs) for unsupervised image segmentation was investigated in this study. In the proposed approach, label prediction and network parameter learning are alternately iterated to meet the following criteria: (a) pixels of similar features should be assigned the same label, (b) spatially continuous pixels should be assigned the same label, and (c) the number of unique labels should be large. Although these criteria are incompatible, the proposed approach minimizes the combination of similarity loss and spatial continuity loss to find a plausible solution of label assignment that balances the aforementioned criteria well. The contributions of this study are four-fold. First, we propose a novel end-to-end network of unsupervised image segmentation that consists of normalization and an argmax function for differentiable clustering. Second, we introduce a spatial continuity loss function that mitigates the limitations of fixed segment boundaries possessed by previous work. Third, we present an extension of the proposed method for segmentation with scribbles as user input, which showed better accuracy than existing methods while maintaining efficiency. Finally, we introduce another extension of the proposed method: unseen image segmentation by using networks pre-trained with a few reference images without re-training the networks. The effectiveness of the proposed approach was examined on several benchmark datasets of image segmentation.
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Mar 16, 2021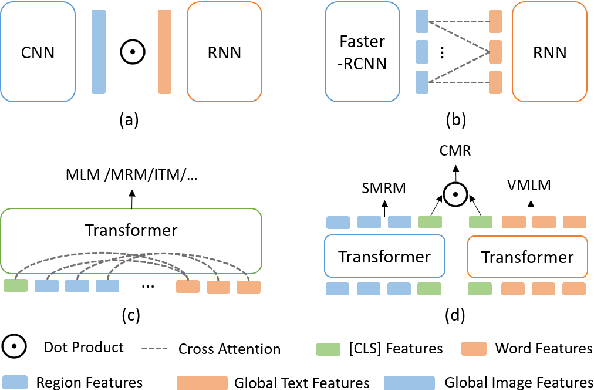
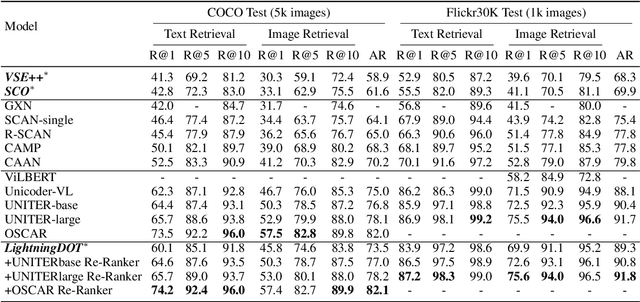
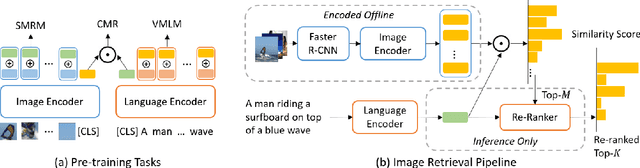

Multimodal pre-training has propelled great advancement in vision-and-language research. These large-scale pre-trained models, although successful, fatefully suffer from slow inference speed due to enormous computation cost mainly from cross-modal attention in Transformer architecture. When applied to real-life applications, such latency and computation demand severely deter the practical use of pre-trained models. In this paper, we study Image-text retrieval (ITR), the most mature scenario of V+L application, which has been widely studied even prior to the emergence of recent pre-trained models. We propose a simple yet highly effective approach, LightningDOT that accelerates the inference time of ITR by thousands of times, without sacrificing accuracy. LightningDOT removes the time-consuming cross-modal attention by pre-training on three novel learning objectives, extracting feature indexes offline, and employing instant dot-product matching with further re-ranking, which significantly speeds up retrieval process. In fact, LightningDOT achieves new state of the art across multiple ITR benchmarks such as Flickr30k, COCO and Multi30K, outperforming existing pre-trained models that consume 1000x magnitude of computational hours. Code and pre-training checkpoints are available at https://github.com/intersun/LightningDOT.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 29, 2020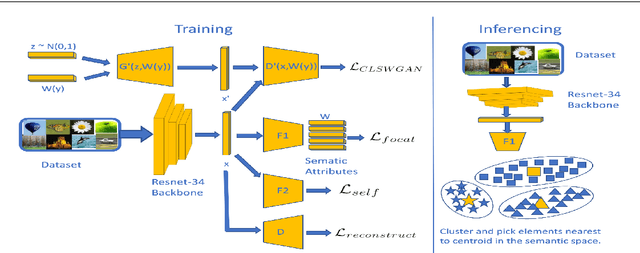
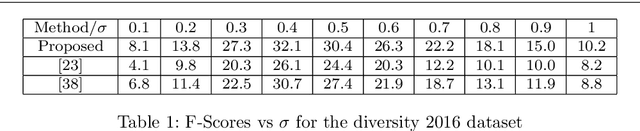
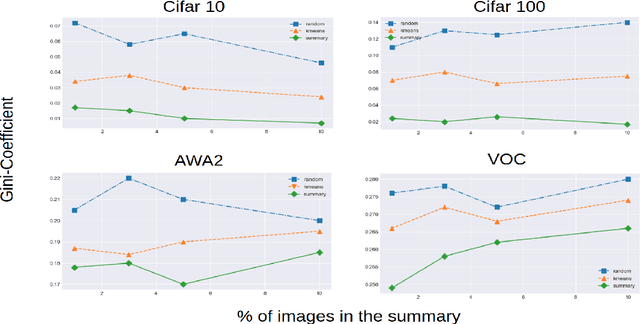
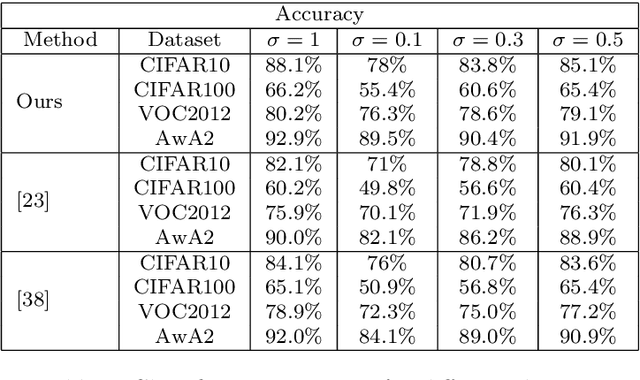
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
Can Un-trained Neural Networks Compete with Trained Neural Networks at Image Reconstruction?
Jul 06, 2020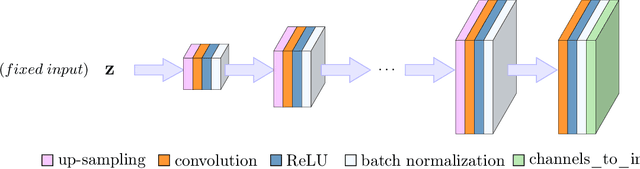
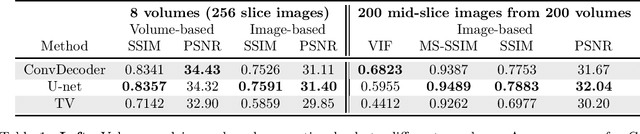

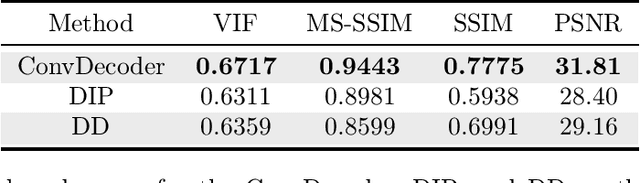
Convolutional Neural Networks (CNNs) are highly effective for image reconstruction problems. Typically, CNNs are trained on large amounts of training images. Recently, however, un-trained neural networks such as the Deep Image Prior and Deep Decoder have achieved excellent image reconstruction performance for standard image reconstruction problems such as image denoising and image inpainting, without using any training data. This success raises the question whether un-trained neural networks can compete with trained ones for practical imaging tasks. To address this question, we consider accelerated magnetic resonance imaging (MRI), an important medical imaging problem, which has received significant attention from the deep-learning community, and for which a dedicated training set exists. We study and optimize un-trained architectures, and as a result, propose a variation of the architectures of the deep image prior and deep decoder. We show that the resulting convolutional decoder out-performs other un-trained methods and---most importantly---achieves on-par performance with a standard trained baseline, the U-net, on the FastMRI dataset, a new dataset for benchmarking deep learning based reconstruction methods. Besides achieving on-par reconstruction performance relative to trained methods, we demonstrate that a key advantage over trained methods is robustness to out-of-distribution examples.