 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MoCap-less Quantitative Evaluation of Ego-Pose Estimation Without Ground Truth Measurements
Feb 01, 2022

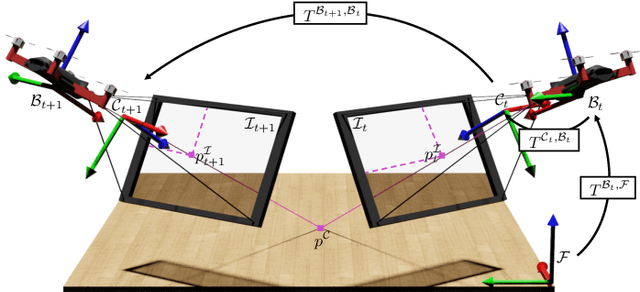

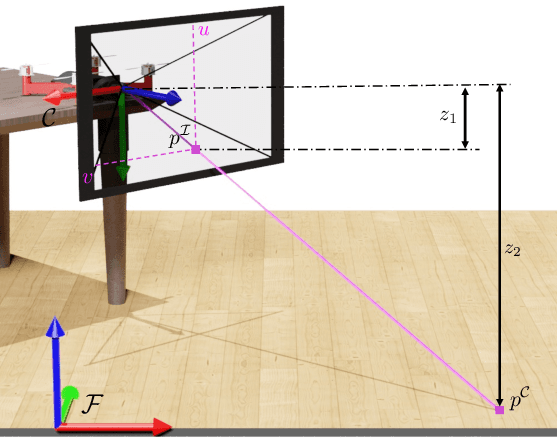
The emergence of data-driven approaches for control and planning in robotics have highlighted the need for developing experimental robotic platforms for data collection. However, their implementation is often complex and expensive, in particular for flying and terrestrial robots where the precise estimation of the position requires motion capture devices (MoCap) or Lidar. In order to simplify the use of a robotic platform dedicated to research on a wide range of indoor and outdoor environments, we present a data validation tool for ego-pose estimation that does not require any equipment other than the on-board camera. The method and tool allow a rapid, visual and quantitative evaluation of the quality of ego-pose sensors and are sensitive to different sources of flaws in the acquisition chain, ranging from desynchronization of the sensor flows to misevaluation of the geometric parameters of the robotic platform. Using computer vision, the information from the sensors is used to calculate the motion of a semantic scene point through its projection to the 2D image space of the on-board camera. The deviations of these keypoints from references created with a semi-automatic tool allow rapid and simple quality assessment of the data collected on the platform. To demonstrate the performance of our method, we evaluate it on two challenging standard UAV datasets as well as one dataset taken from a terrestrial robot.
HMIC: Hierarchical Medical Image Classification, A Deep Learning Approach
Jun 23, 2020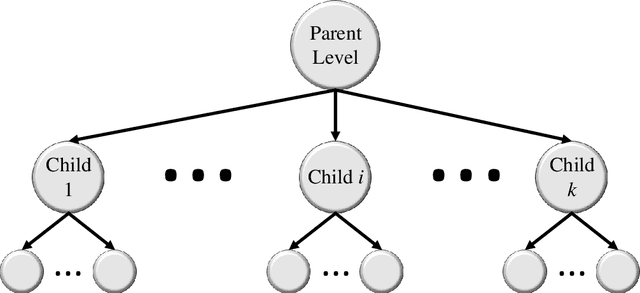
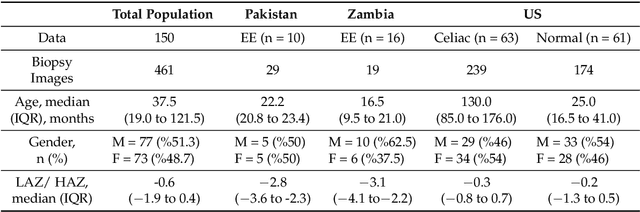
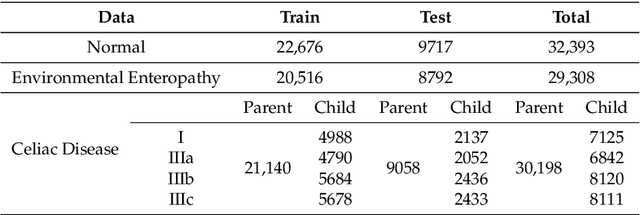
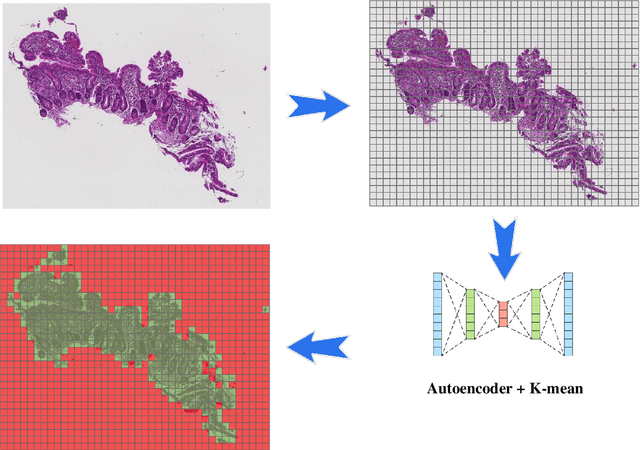
Image classification is central to the big data revolution in medicine. Improved information processing methods for diagnosis and classification of digital medical images have shown to be successful via deep learning approaches. As this field is explored, there are limitations to the performance of traditional supervised classifiers. This paper outlines an approach that is different from the current medical image classification tasks that view the issue as multi-class classification. We performed a hierarchical classification using our Hierarchical Medical Image classification (HMIC) approach. HMIC uses stacks of deep learning models to give particular comprehension at each level of the clinical picture hierarchy. For testing our performance, we use biopsy of the small bowel images that contain three categories in the parent level (Celiac Disease, Environmental Enteropathy, and histologically normal controls). For the child level, Celiac Disease Severity is classified into 4 classes (I, IIIa, IIIb, and IIIC).
Learning and Crafting for the Wide Multiple Baseline Stereo
Dec 22, 2021
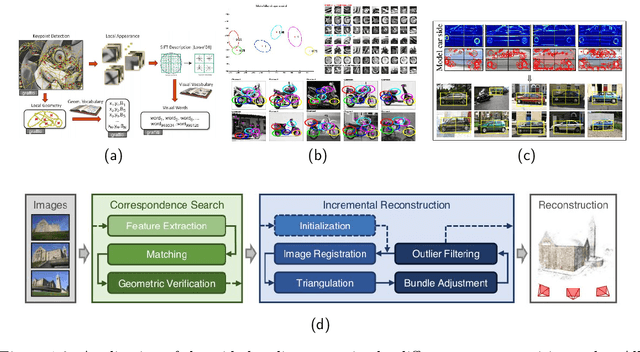
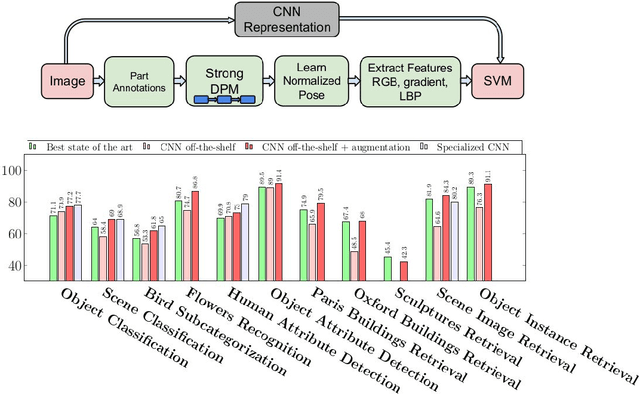
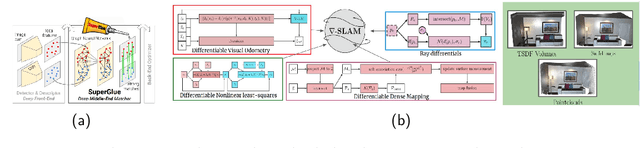
This thesis introduces the wide multiple baseline stereo (WxBS) problem. WxBS, a generalization of the standard wide baseline stereo problem, considers the matching of images that simultaneously differ in more than one image acquisition factor such as viewpoint, illumination, sensor type, or where object appearance changes significantly, e.g., over time. A new dataset with the ground truth, evaluation metric and baselines has been introduced. The thesis presents the following improvements of the WxBS pipeline. (i) A loss function, called HardNeg, for learning a local image descriptor that relies on hard negative mining within a mini-batch and on the maximization of the distance between the closest positive and the closest negative patches. (ii) The descriptor trained with the HardNeg loss, called HardNet, is compact and shows state-of-the-art performance in standard matching, patch verification and retrieval benchmarks. (iii) A method for learning the affine shape, orientation, and potentially other parameters related to geometric and appearance properties of local features. (iv) A tentative correspondences generation strategy which generalizes the standard first to second closest distance ratio is presented. The selection strategy, which shows performance superior to the standard method, is applicable to either hard-engineered descriptors like SIFT, LIOP, and MROGH or deeply learned like HardNet. (v) A feedback loop is introduced for the two-view matching problem, resulting in MODS -- matching with on-demand view synthesis -- algorithm. MODS is an algorithm that handles a viewing angle difference even larger than the previous state-of-the-art ASIFT algorithm, without a significant increase of computational cost over "standard" wide and narrow baseline approaches. Last, but not least, a comprehensive benchmark for local features and robust estimation algorithms is introduced.
iDECODe: In-distribution Equivariance for Conformal Out-of-distribution Detection
Jan 07, 2022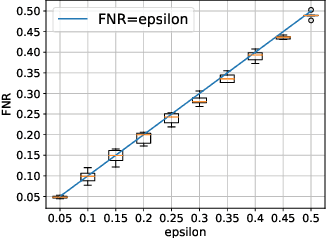
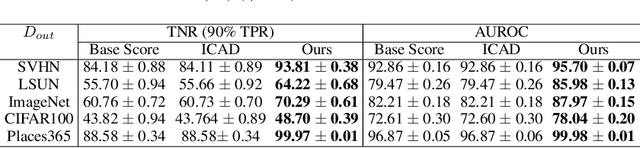

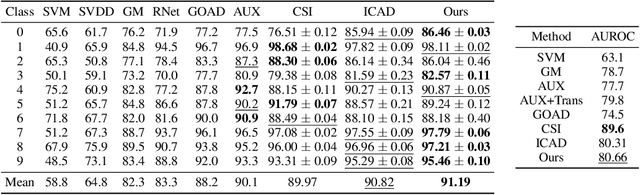
Machine learning methods such as deep neural networks (DNNs), despite their success across different domains, are known to often generate incorrect predictions with high confidence on inputs outside their training distribution. The deployment of DNNs in safety-critical domains requires detection of out-of-distribution (OOD) data so that DNNs can abstain from making predictions on those. A number of methods have been recently developed for OOD detection, but there is still room for improvement. We propose the new method iDECODe, leveraging in-distribution equivariance for conformal OOD detection. It relies on a novel base non-conformity measure and a new aggregation method, used in the inductive conformal anomaly detection framework, thereby guaranteeing a bounded false detection rate. We demonstrate the efficacy of iDECODe by experiments on image and audio datasets, obtaining state-of-the-art results. We also show that iDECODe can detect adversarial examples.
Learning RAW-to-sRGB Mappings with Inaccurately Aligned Supervision
Aug 18, 2021
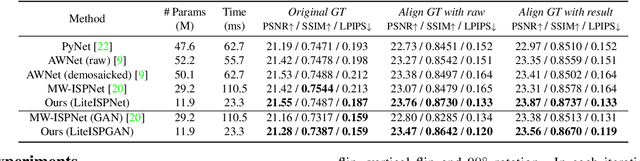
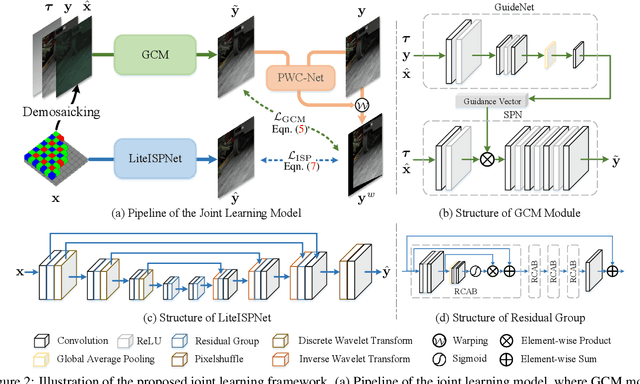
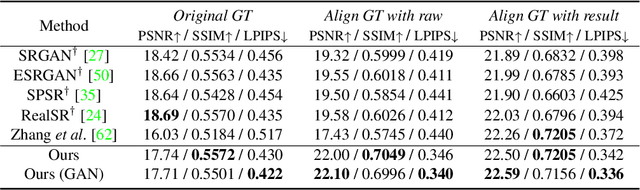
Learning RAW-to-sRGB mapping has drawn increasing attention in recent years, wherein an input raw image is trained to imitate the target sRGB image captured by another camera. However, the severe color inconsistency makes it very challenging to generate well-aligned training pairs of input raw and target sRGB images. While learning with inaccurately aligned supervision is prone to causing pixel shift and producing blurry results. In this paper, we circumvent such issue by presenting a joint learning model for image alignment and RAW-to-sRGB mapping. To diminish the effect of color inconsistency in image alignment, we introduce to use a global color mapping (GCM) module to generate an initial sRGB image given the input raw image, which can keep the spatial location of the pixels unchanged, and the target sRGB image is utilized to guide GCM for converting the color towards it. Then a pre-trained optical flow estimation network (e.g., PWC-Net) is deployed to warp the target sRGB image to align with the GCM output. To alleviate the effect of inaccurately aligned supervision, the warped target sRGB image is leveraged to learn RAW-to-sRGB mapping. When training is done, the GCM module and optical flow network can be detached, thereby bringing no extra computation cost for inference. Experiments show that our method performs favorably against state-of-the-arts on ZRR and SR-RAW datasets. With our joint learning model, a light-weight backbone can achieve better quantitative and qualitative performance on ZRR dataset. Codes are available at https://github.com/cszhilu1998/RAW-to-sRGB.
CAN3D: Fast 3D Medical Image Segmentation via Compact Context Aggregation
Sep 22, 2021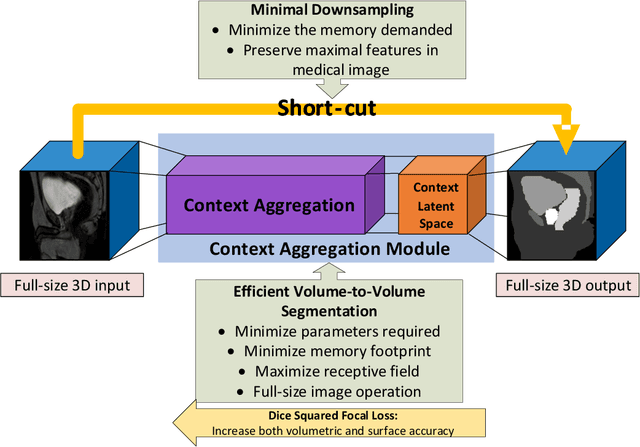

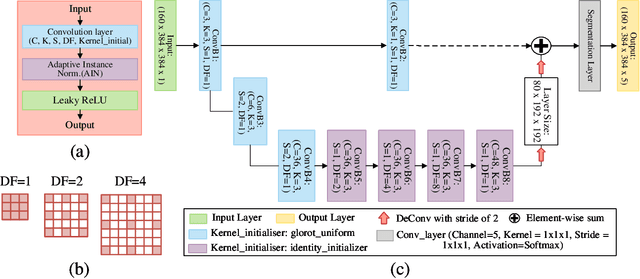
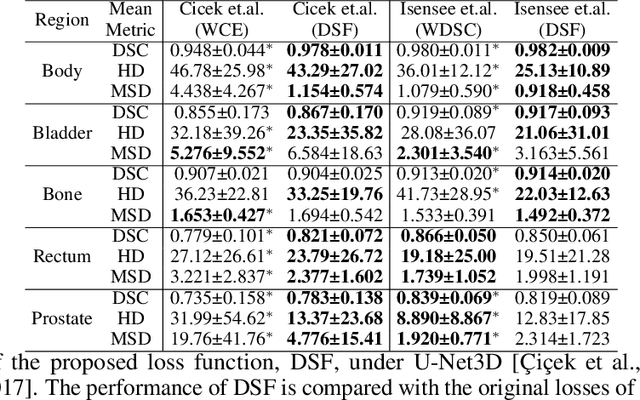
Direct automatic segmentation of objects from 3D medical imaging, such as magnetic resonance (MR) imaging, is challenging as it often involves accurately identifying a number of individual objects with complex geometries within a large volume under investigation. To address these challenges, most deep learning approaches typically enhance their learning capability by substantially increasing the complexity or the number of trainable parameters within their models. Consequently, these models generally require long inference time on standard workstations operating clinical MR systems and are restricted to high-performance computing hardware due to their large memory requirement. Further, to fit 3D dataset through these large models using limited computer memory, trade-off techniques such as patch-wise training are often used which sacrifice the fine-scale geometric information from input images which could be clinically significant for diagnostic purposes. To address these challenges, we present a compact convolutional neural network with a shallow memory footprint to efficiently reduce the number of model parameters required for state-of-art performance. This is critical for practical employment as most clinical environments only have low-end hardware with limited computing power and memory. The proposed network can maintain data integrity by directly processing large full-size 3D input volumes with no patches required and significantly reduces the computational time required for both training and inference. We also propose a novel loss function with extra shape constraint to improve the accuracy for imbalanced classes in 3D MR images.
Persistent Homology for Breast Tumor Classification using Mammogram Scans
Jan 07, 2022
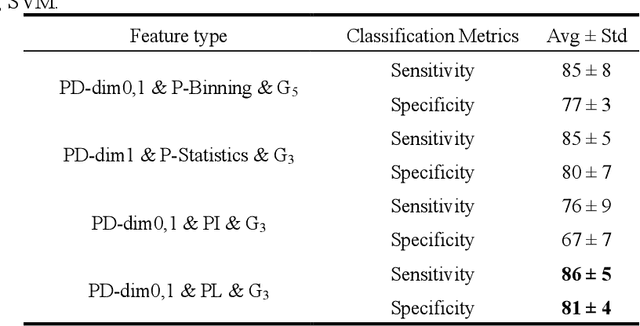

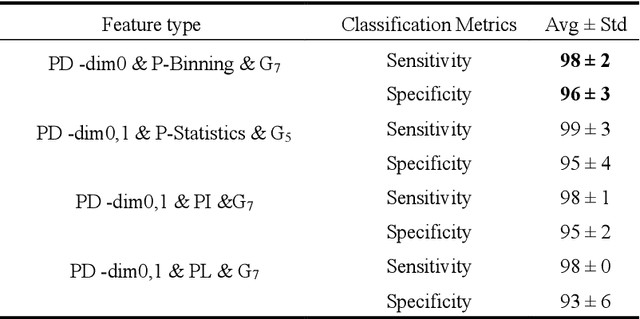
An Important tool in the field topological data analysis is known as persistent Homology (PH) which is used to encode abstract representation of the homology of data at different resolutions in the form of persistence diagram (PD). In this work we build more than one PD representation of a single image based on a landmark selection method, known as local binary patterns, that encode different types of local textures from images. We employed different PD vectorizations using persistence landscapes, persistence images, persistence binning (Betti Curve) and statistics. We tested the effectiveness of proposed landmark based PH on two publicly available breast abnormality detection datasets using mammogram scans. Sensitivity of landmark based PH obtained is over 90% in both datasets for the detection of abnormal breast scans. Finally, experimental results give new insights on using different types of PD vectorizations which help in utilising PH in conjunction with machine learning classifiers.
Automatically Searching for U-Net Image Translator Architecture
Feb 26, 2020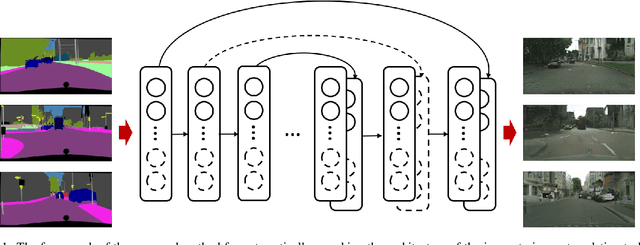
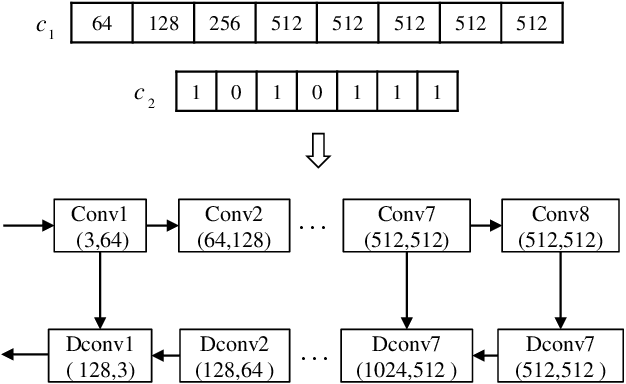


Image translators have been successfully applied to many important low level image processing tasks. However, classical network architecture of image translator like U-Net, is borrowed from other vision tasks like biomedical image segmentation. This straightforward adaptation may not be optimal and could cause redundancy in the network structure. In this paper, we propose an automatic architecture searching method for image translator. By utilizing evolutionary algorithm, we investigate a more efficient network architecture which costs less computation resources and achieves better performance than the original one. Extensive qualitative and quantitative experiments are conducted to demonstrate the effectiveness of the proposed method. Moreover, we transplant the searched network architecture to other datasets which are not involved in the architecture searching procedure. Efficiency of the searched architecture on these datasets further demonstrates the generalization of the method.
Exploring Overcomplete Representations for Single Image Deraining using CNNs
Oct 20, 2020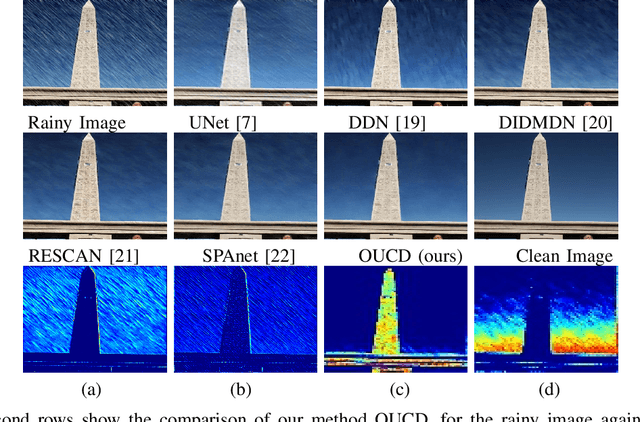


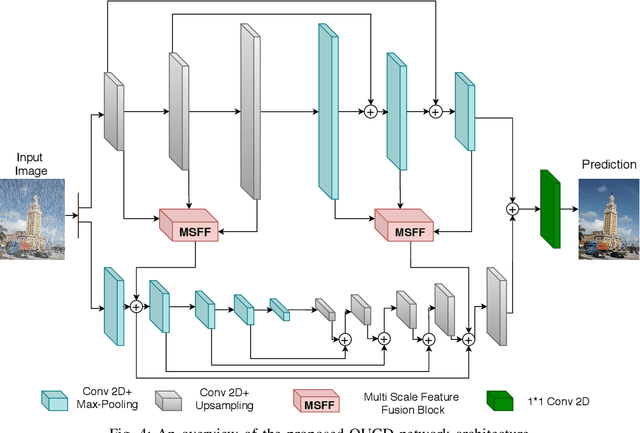
Removal of rain streaks from a single image is an extremely challenging problem since the rainy images often contain rain streaks of different size, shape, direction and density. Most recent methods for deraining use a deep network following a generic "encoder-decoder" architecture which captures low-level features across the initial layers and high-level features in the deeper layers. For the task of deraining, the rain streaks which are to be removed are relatively small and focusing much on global features is not an efficient way to solve the problem. To this end, we propose using an overcomplete convolutional network architecture which gives special attention in learning local structures by restraining the receptive field of filters. We combine it with U-Net so that it does not lose out on the global structures as well while focusing more on low-level features, to compute the derained image. The proposed network called, Over-and-Under Complete Deraining Network (OUCD), consists of two branches: overcomplete branch which is confined to small receptive field size in order to focus on the local structures and an undercomplete branch that has larger receptive fields to primarily focus on global structures. Extensive experiments on synthetic and real datasets demonstrate that the proposed method achieves significant improvements over the recent state-of-the-art methods.
Image to Language Understanding: Captioning approach
Feb 21, 2020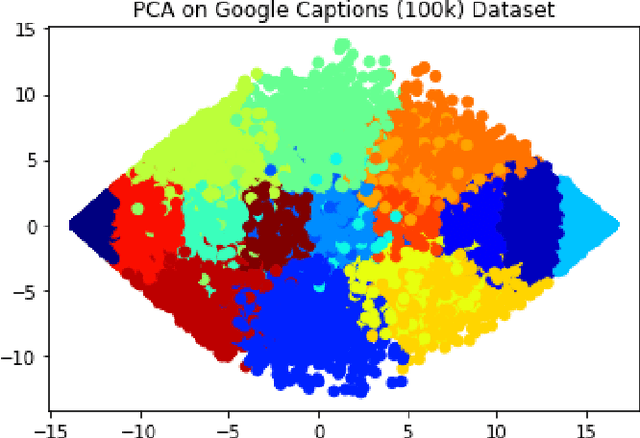
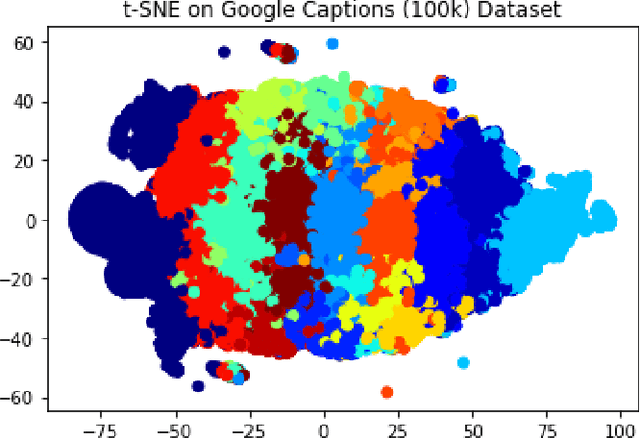
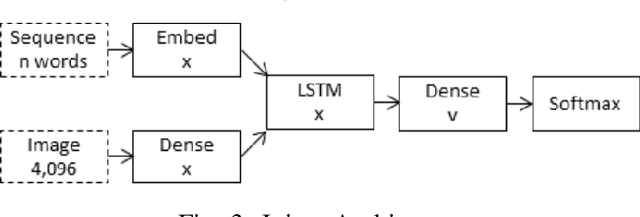
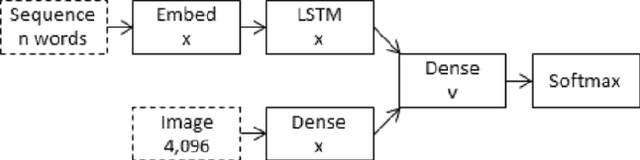
Extracting context from visual representations is of utmost importance in the advancement of Computer Science. Representation of such a format in Natural Language has a huge variety of applications such as helping the visually impaired etc. Such an approach is a combination of Computer Vision and Natural Language techniques which is a hard problem to solve. This project aims to compare different approaches for solving the image captioning problem. In specific, the focus was on comparing two different types of models: Encoder-Decoder approach and a Multi-model approach. In the encoder-decoder approach, inject and merge architectures were compared against a multi-modal image captioning approach based primarily on object detection. These approaches have been compared on the basis on state of the art sentence comparison metrics such as BLEU, GLEU, Meteor, and Rouge on a subset of the Google Conceptual captions dataset which contains 100k images. On the basis of this comparison, we observed that the best model was the Inception injected encoder model. This best approach has been deployed as a web-based system. On uploading an image, such a system will output the best caption associated with the image.