 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Dec 28, 2019
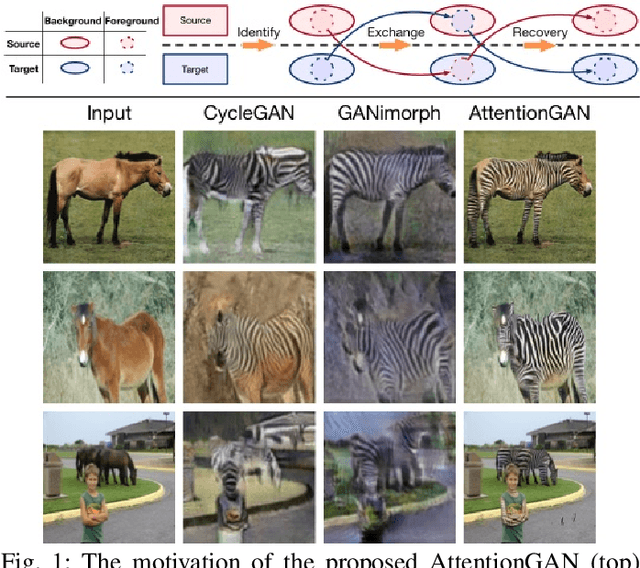



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.
Learning Texture Transformer Network for Image Super-Resolution
Jun 22, 2020
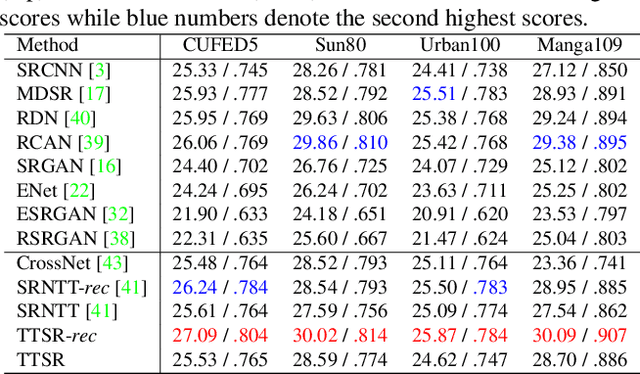
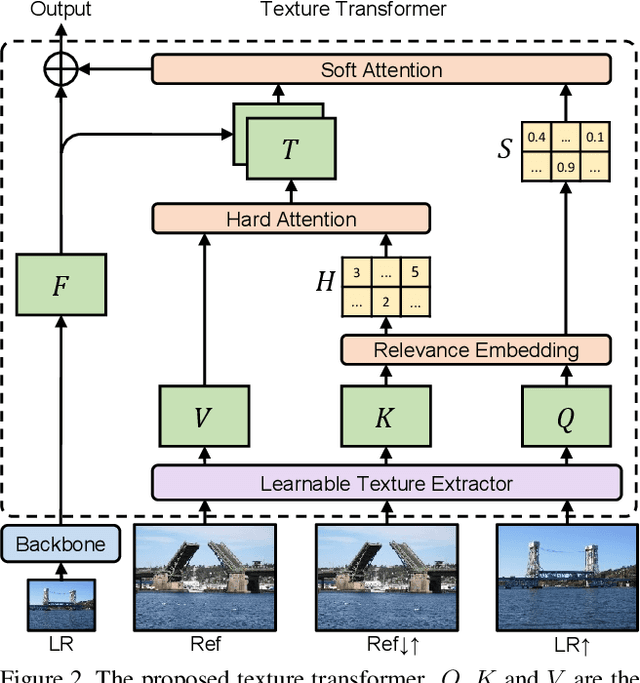
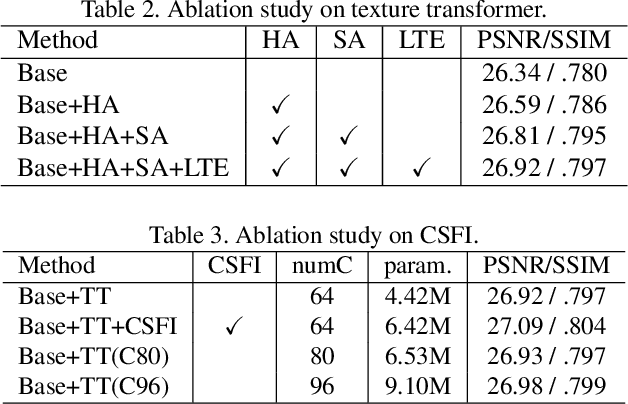
We study on image super-resolution (SR), which aims to recover realistic textures from a low-resolution (LR) image. Recent progress has been made by taking high-resolution images as references (Ref), so that relevant textures can be transferred to LR images. However, existing SR approaches neglect to use attention mechanisms to transfer high-resolution (HR) textures from Ref images, which limits these approaches in challenging cases. In this paper, we propose a novel Texture Transformer Network for Image Super-Resolution (TTSR), in which the LR and Ref images are formulated as queries and keys in a transformer, respectively. TTSR consists of four closely-related modules optimized for image generation tasks, including a learnable texture extractor by DNN, a relevance embedding module, a hard-attention module for texture transfer, and a soft-attention module for texture synthesis. Such a design encourages joint feature learning across LR and Ref images, in which deep feature correspondences can be discovered by attention, and thus accurate texture features can be transferred. The proposed texture transformer can be further stacked in a cross-scale way, which enables texture recovery from different levels (e.g., from 1x to 4x magnification). Extensive experiments show that TTSR achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations.
Deep Decoding of $\ell_\infty$-coded Light Field Images
Jan 24, 2022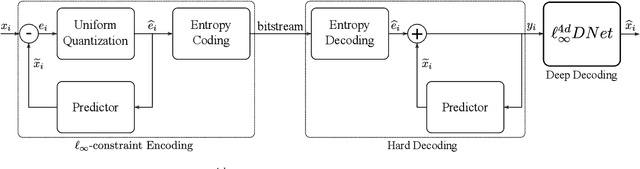
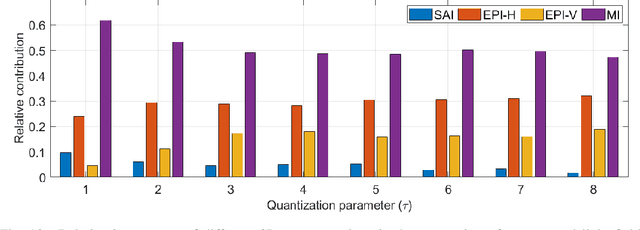
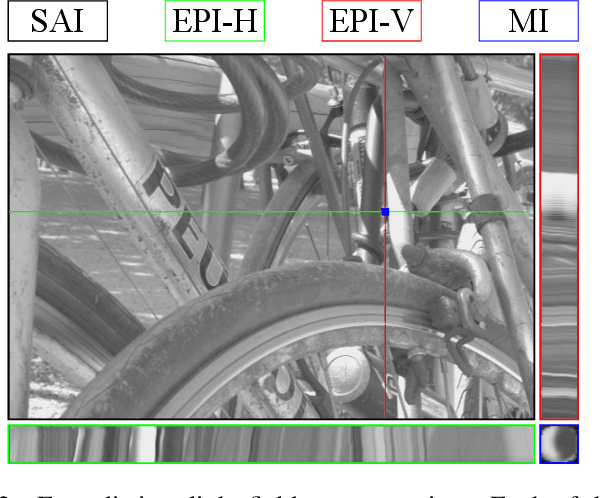
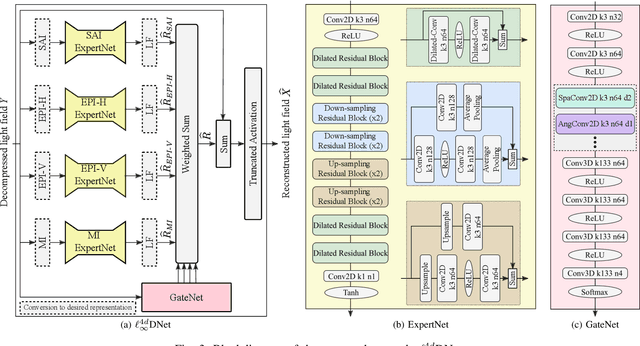
To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than $100\times$ greater amount of information than conventional images. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for inexpensive light field cameras. In this work, we propose a novel $\ell_\infty$-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder. Targeting high-fidelity reconstruction, the CNN decoder capitalizes on the $\ell_\infty$-constraint and light field properties to remove the compression artifacts and achieves significantly better performance than existing state-of-the-art $\ell_2$-based light field compression methods.
Panoptic Segmentation Meets Remote Sensing
Nov 23, 2021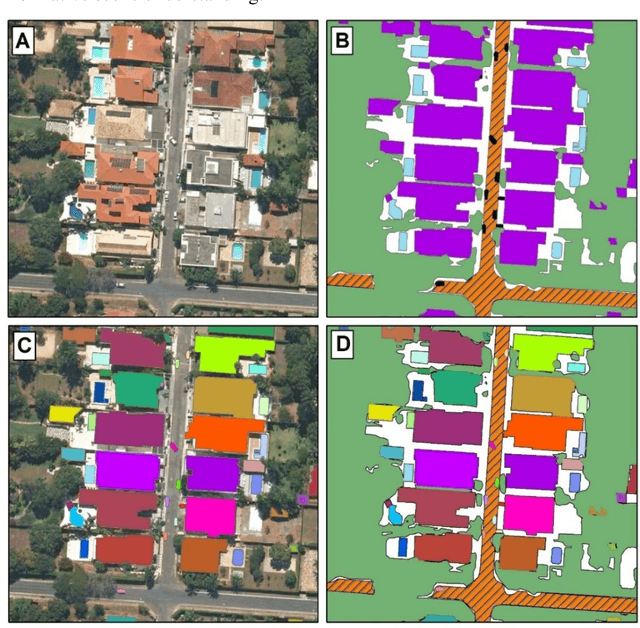
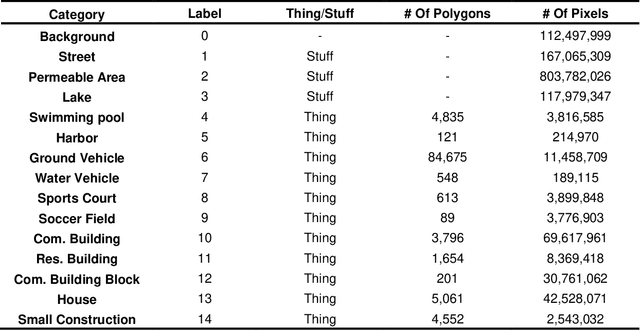
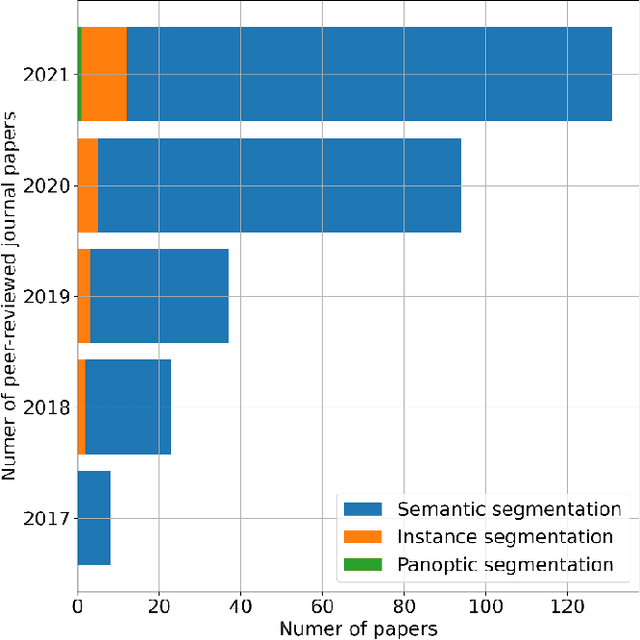

Panoptic segmentation combines instance and semantic predictions, allowing the detection of "things" and "stuff" simultaneously. Effectively approaching panoptic segmentation in remotely sensed data can be auspicious in many challenging problems since it allows continuous mapping and specific target counting. Several difficulties have prevented the growth of this task in remote sensing: (a) most algorithms are designed for traditional images, (b) image labelling must encompass "things" and "stuff" classes, and (c) the annotation format is complex. Thus, aiming to solve and increase the operability of panoptic segmentation in remote sensing, this study has five objectives: (1) create a novel data preparation pipeline for panoptic segmentation, (2) propose an annotation conversion software to generate panoptic annotations; (3) propose a novel dataset on urban areas, (4) modify the Detectron2 for the task, and (5) evaluate difficulties of this task in the urban setting. We used an aerial image with a 0,24-meter spatial resolution considering 14 classes. Our pipeline considers three image inputs, and the proposed software uses point shapefiles for creating samples in the COCO format. Our study generated 3,400 samples with 512x512 pixel dimensions. We used the Panoptic-FPN with two backbones (ResNet-50 and ResNet-101), and the model evaluation considered semantic instance and panoptic metrics. We obtained 93.9, 47.7, and 64.9 for the mean IoU, box AP, and PQ. Our study presents the first effective pipeline for panoptic segmentation and an extensive database for other researchers to use and deal with other data or related problems requiring a thorough scene understanding.
IceNet for Interactive Contrast Enhancement
Sep 13, 2021

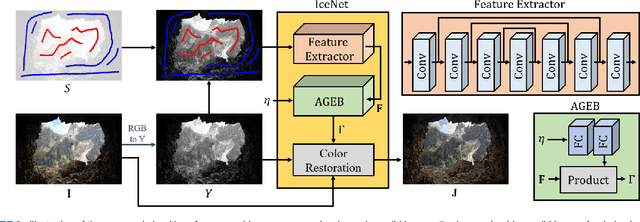

A CNN-based interactive contrast enhancement algorithm, called IceNet, is proposed in this work, which enables a user to adjust image contrast easily according to his or her preference. Specifically, a user provides a parameter for controlling the global brightness and two types of scribbles to darken or brighten local regions in an image. Then, given these annotations, IceNet estimates a gamma map for the pixel-wise gamma correction. Finally, through color restoration, an enhanced image is obtained. The user may provide annotations iteratively to obtain a satisfactory image. IceNet is also capable of producing a personalized enhanced image automatically, which can serve as a basis for further adjustment if so desired. Moreover, to train IceNet effectively and reliably, we propose three differentiable losses. Extensive experiments show that IceNet can provide users with satisfactorily enhanced images.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Jan 24, 2022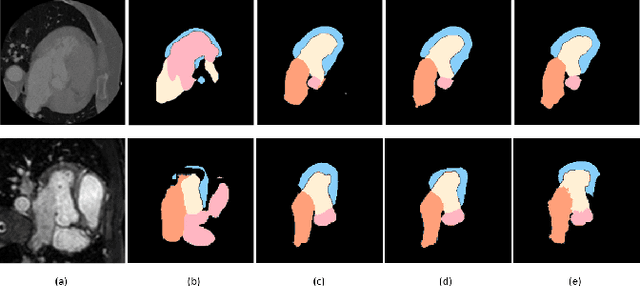
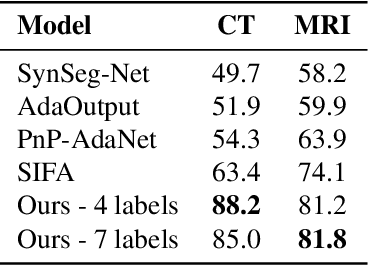


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
Multiscale Generative Models: Improving Performance of a Generative Model Using Feedback from Other Dependent Generative Models
Jan 24, 2022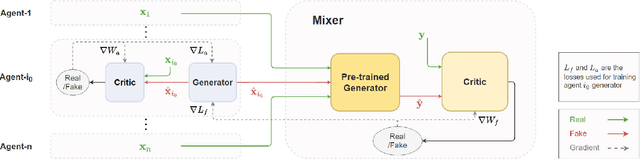


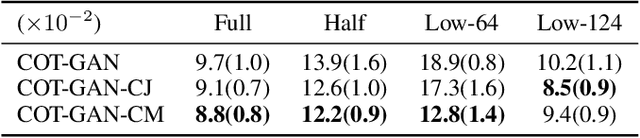
Realistic fine-grained multi-agent simulation of real-world complex systems is crucial for many downstream tasks such as reinforcement learning. Recent work has used generative models (GANs in particular) for providing high-fidelity simulation of real-world systems. However, such generative models are often monolithic and miss out on modeling the interaction in multi-agent systems. In this work, we take a first step towards building multiple interacting generative models (GANs) that reflects the interaction in real world. We build and analyze a hierarchical set-up where a higher-level GAN is conditioned on the output of multiple lower-level GANs. We present a technique of using feedback from the higher-level GAN to improve performance of lower-level GANs. We mathematically characterize the conditions under which our technique is impactful, including understanding the transfer learning nature of our set-up. We present three distinct experiments on synthetic data, time series data, and image domain, revealing the wide applicability of our technique.
Multi-relation Message Passing for Multi-label Text Classification
Feb 10, 2022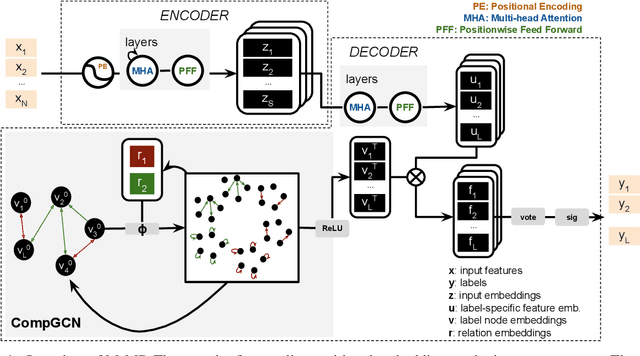

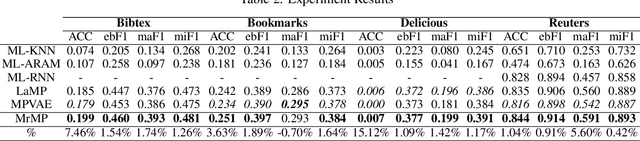
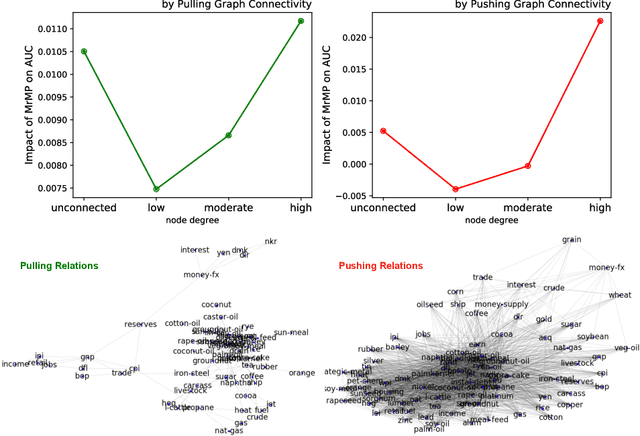
A well-known challenge associated with the multi-label classification problem is modelling dependencies between labels. Most attempts at modelling label dependencies focus on co-occurrences, ignoring the valuable information that can be extracted by detecting label subsets that rarely occur together. For example, consider customer product reviews; a product probably would not simultaneously be tagged by both "recommended" (i.e., reviewer is happy and recommends the product) and "urgent" (i.e., the review suggests immediate action to remedy an unsatisfactory experience). Aside from the consideration of positive and negative dependencies, the direction of a relationship should also be considered. For a multi-label image classification problem, the "ship" and "sea" labels have an obvious dependency, but the presence of the former implies the latter much more strongly than the other way around. These examples motivate the modelling of multiple types of bi-directional relationships between labels. In this paper, we propose a novel method, entitled Multi-relation Message Passing (MrMP), for the multi-label classification problem. Experiments on benchmark multi-label text classification datasets show that the MrMP module yields similar or superior performance compared to state-of-the-art methods. The approach imposes only minor additional computational and memory overheads.
Semi-automated Virtual Unfolded View Generation Method of Stomach from CT Volumes
Jan 14, 2022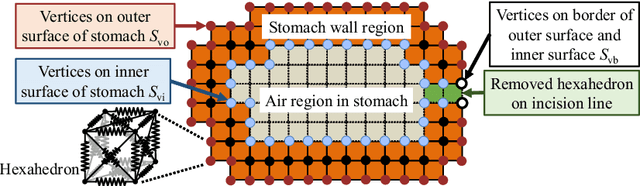
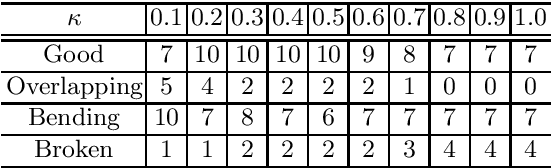
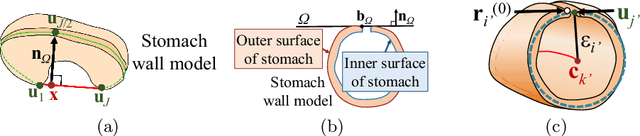
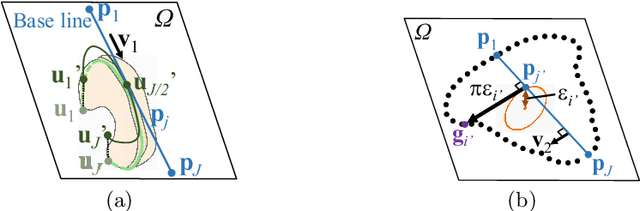
CT image-based diagnosis of the stomach is developed as a new way of diagnostic method. A virtual unfolded (VU) view is suitable for displaying its wall. In this paper, we propose a semi-automated method for generating VU views of the stomach. Our method requires minimum manual operations. The determination of the unfolding forces and the termination of the unfolding process are automated. The unfolded shape of the stomach is estimated based on its radius. The unfolding forces are determined so that the stomach wall is deformed to the expected shape. The iterative deformation process is terminated if the difference of the shapes between the deformed shape and expected shape is small. Our experiments using 67 CT volumes showed that our proposed method can generate good VU views for 76.1% cases.
* Accepted paper as a poster presentation at MICCAI 2013 (International Conference on Medical Image Computing and Computer-Assisted Intervention), Nagoya, Japan
Guidestar-free image-guided wavefront-shaping
Jul 08, 2020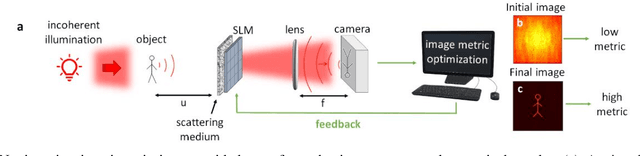
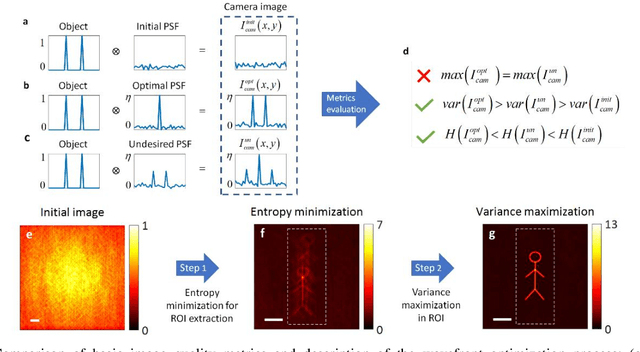
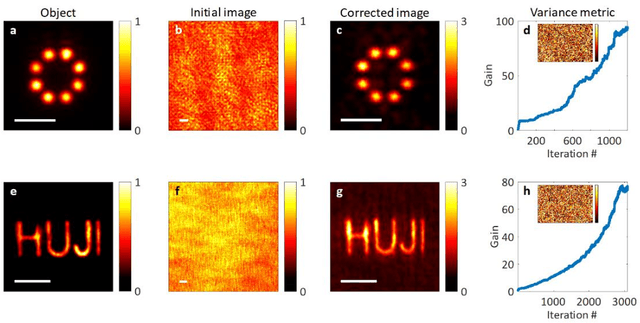
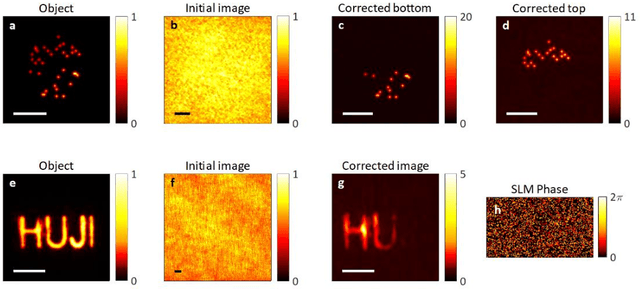
Optical imaging through scattering media is a fundamental challenge in many applications. Recently, substantial breakthroughs such as imaging through biological tissues and looking around corners have been obtained by the use of wavefront-shaping approaches. However, these require an implanted guide-star for determining the wavefront correction, controlled coherent illumination, and most often raster scanning of the shaped focus. Alternative novel computational approaches that exploit speckle correlations, avoid guide-stars and wavefront control but are limited to small two-dimensional objects contained within the memory-effect correlations range. Here, we present a new concept, image-guided wavefront-shaping, allowing non-invasive, guidestar-free, widefield, incoherent imaging through highly scattering layers, without illumination control. Most importantly, the wavefront-correction is found even for objects that are larger than the memory-effect range, by blindly optimizing image-quality metrics. We demonstrate imaging of extended objects through highly-scattering layers and multi-core fibers, paving the way for non-invasive imaging in various applications, from microscopy to endoscopy.