 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ActionFormer: Localizing Moments of Actions with Transformers
Feb 16, 2022
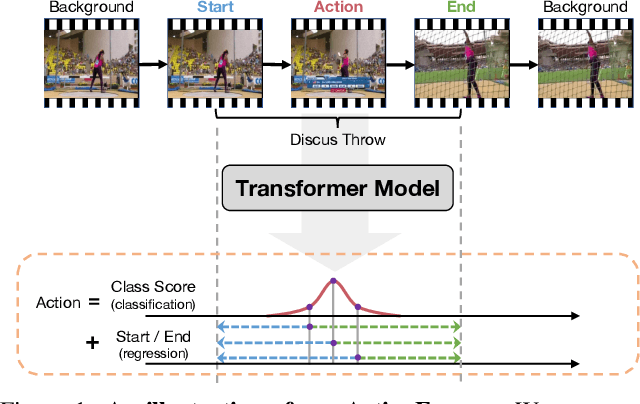
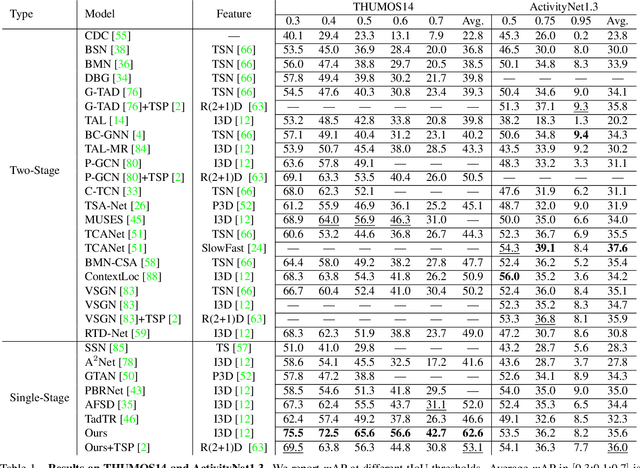
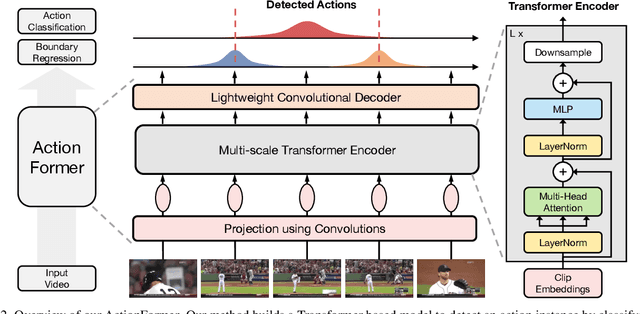
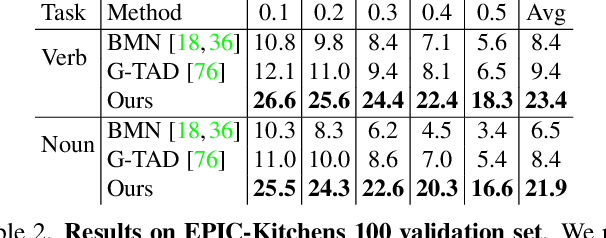
Self-attention based Transformer models have demonstrated impressive results for image classification and object detection, and more recently for video understanding. Inspired by this success, we investigate the application of Transformer networks for temporal action localization in videos. To this end, we present ActionFormer -- a simple yet powerful model to identify actions in time and recognize their categories in a single shot, without using action proposals or relying on pre-defined anchor windows. ActionFormer combines a multiscale feature representation with local self-attention, and uses a light-weighted decoder to classify every moment in time and estimate the corresponding action boundaries. We show that this orchestrated design results in major improvements upon prior works. Without bells and whistles, ActionFormer achieves 65.6% mAP at tIoU=0.5 on THUMOS14, outperforming the best prior model by 8.7 absolute percentage points and crossing the 60% mAP for the first time. Further, ActionFormer demonstrates strong results on ActivityNet 1.3 (36.0% average mAP) and the more recent EPIC-Kitchens 100 (+13.5% average mAP over prior works). Our code is available at http://github.com/happyharrycn/actionformer_release
The interpretation of endobronchial ultrasound image using 3D convolutional neural network for differentiating malignant and benign mediastinal lesions
Aug 02, 2021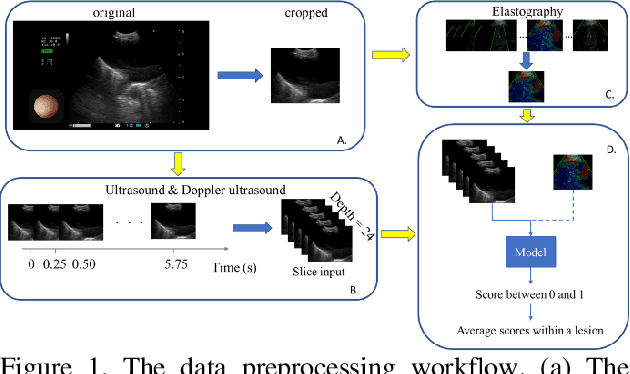
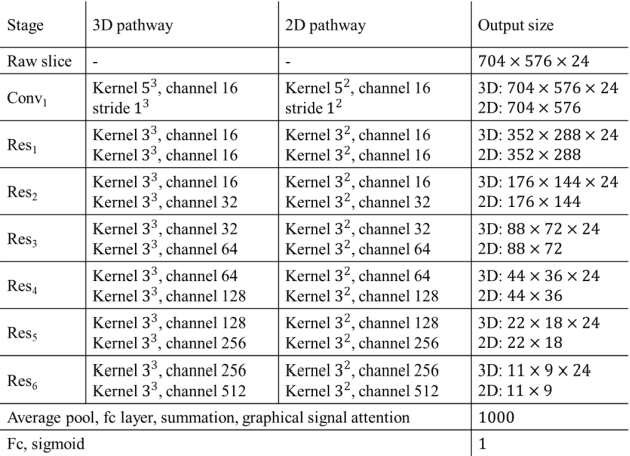
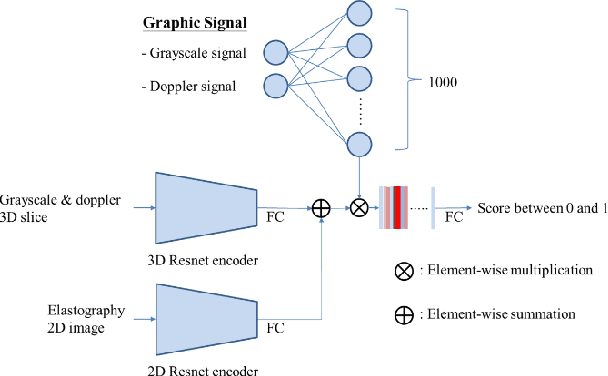
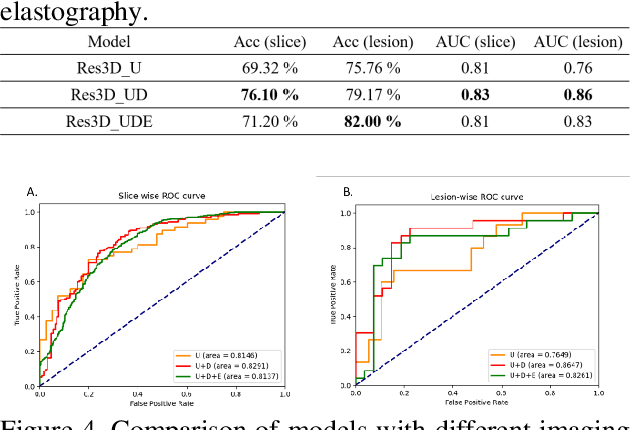
The purpose of this study is to differentiate malignant and benign mediastinal lesions by using the three-dimensional convolutional neural network through the endobronchial ultrasound (EBUS) image. Compared with previous study, our proposed model is robust to noise and able to fuse various imaging features and spatiotemporal features of EBUS videos. Endobronchial ultrasound-guided transbronchial needle aspiration (EBUS-TBNA) is a diagnostic tool for intrathoracic lymph nodes. Physician can observe the characteristics of the lesion using grayscale mode, doppler mode, and elastography during the procedure. To process the EBUS data in the form of a video and appropriately integrate the features of multiple imaging modes, we used a time-series three-dimensional convolutional neural network (3D CNN) to learn the spatiotemporal features and design a variety of architectures to fuse each imaging mode. Our model (Res3D_UDE) took grayscale mode, Doppler mode, and elastography as training data and achieved an accuracy of 82.00% and area under the curve (AUC) of 0.83 on the validation set. Compared with previous study, we directly used videos recorded during procedure as training and validation data, without additional manual selection, which might be easier for clinical application. In addition, model designed with 3D CNN can also effectively learn spatiotemporal features and improve accuracy. In the future, our model may be used to guide physicians to quickly and correctly find the target lesions for slice sampling during the inspection process, reduce the number of slices of benign lesions, and shorten the inspection time.
Robust Region Feature Synthesizer for Zero-Shot Object Detection
Jan 01, 2022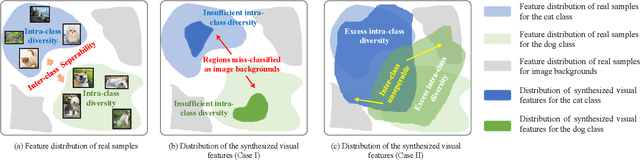
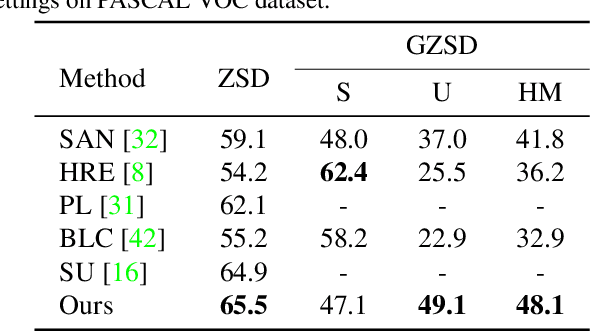
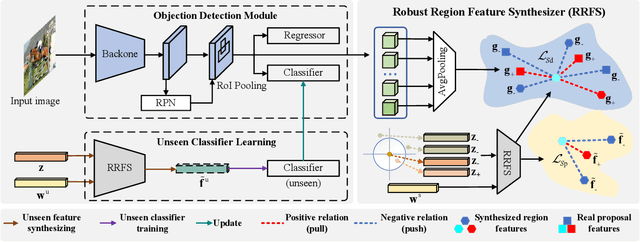
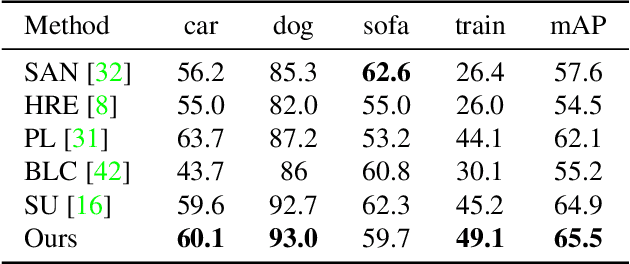
Zero-shot object detection aims at incorporating class semantic vectors to realize the detection of (both seen and) unseen classes given an unconstrained test image. In this study, we reveal the core challenges in this research area: how to synthesize robust region features (for unseen objects) that are as intra-class diverse and inter-class separable as the real samples, so that strong unseen object detectors can be trained upon them. To address these challenges, we build a novel zero-shot object detection framework that contains an Intra-class Semantic Diverging component and an Inter-class Structure Preserving component. The former is used to realize the one-to-more mapping to obtain diverse visual features from each class semantic vector, preventing miss-classifying the real unseen objects as image backgrounds. While the latter is used to avoid the synthesized features too scattered to mix up the inter-class and foreground-background relationship. To demonstrate the effectiveness of the proposed approach, comprehensive experiments on PASCAL VOC, COCO, and DIOR datasets are conducted. Notably, our approach achieves the new state-of-the-art performance on PASCAL VOC and COCO and it is the first study to carry out zero-shot object detection in remote sensing imagery.
Uncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021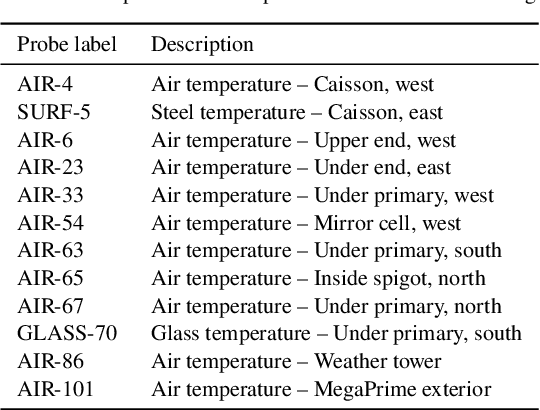
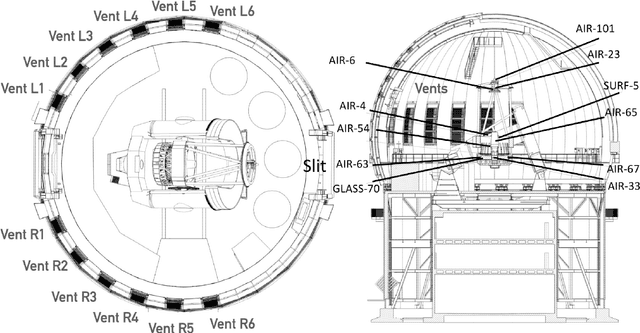
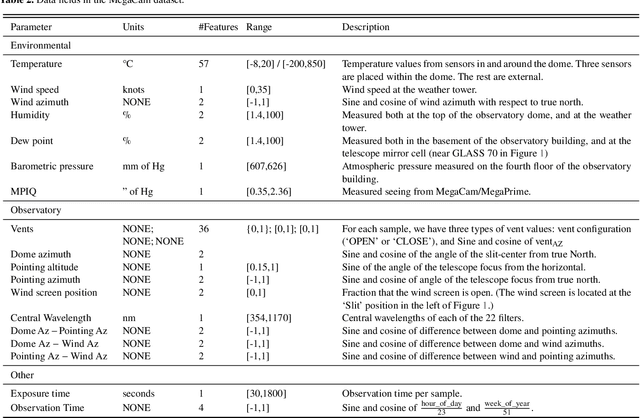
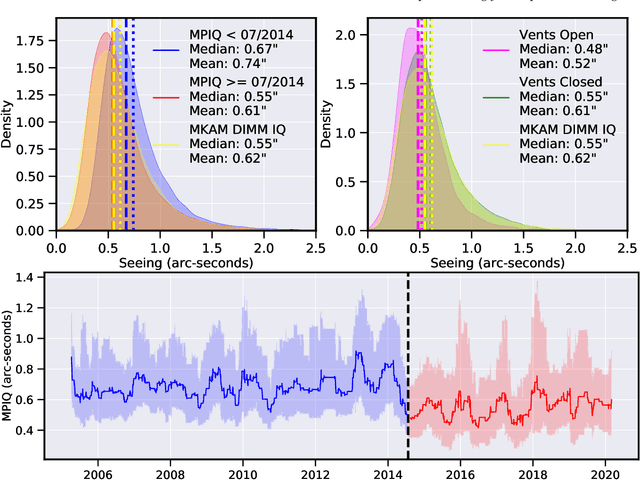
We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
Weightless Neural Networks for Efficient Edge Inference
Mar 03, 2022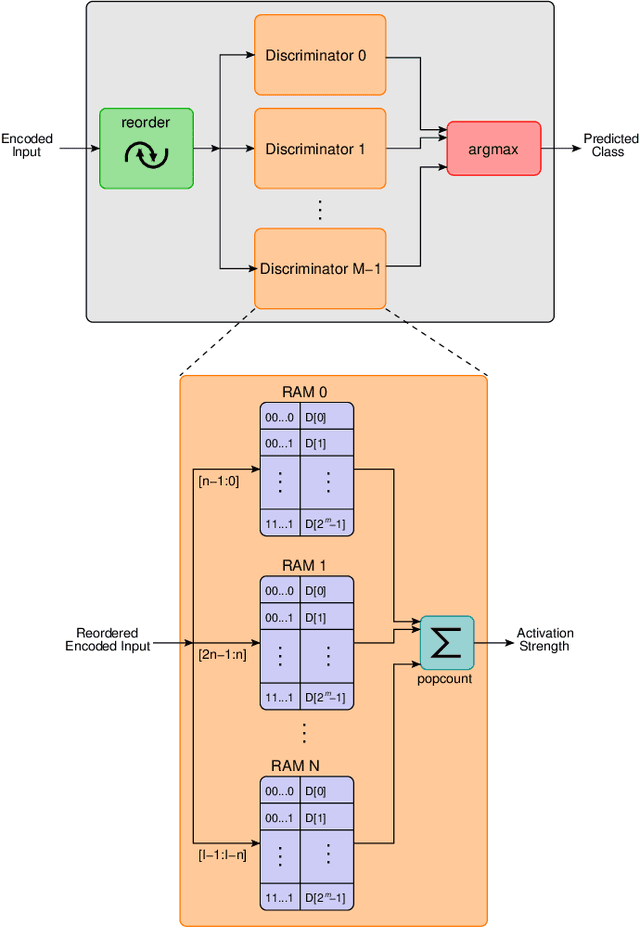
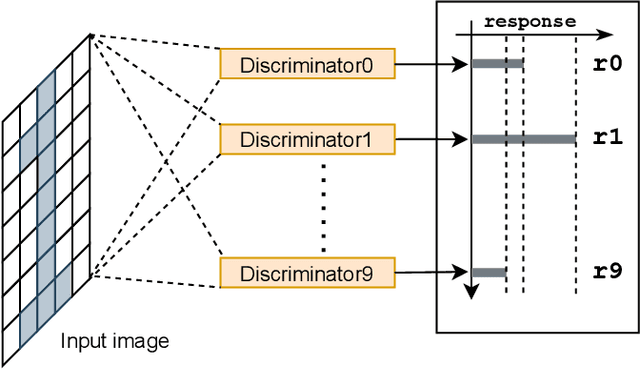
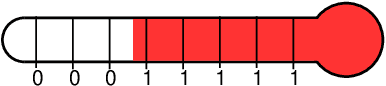
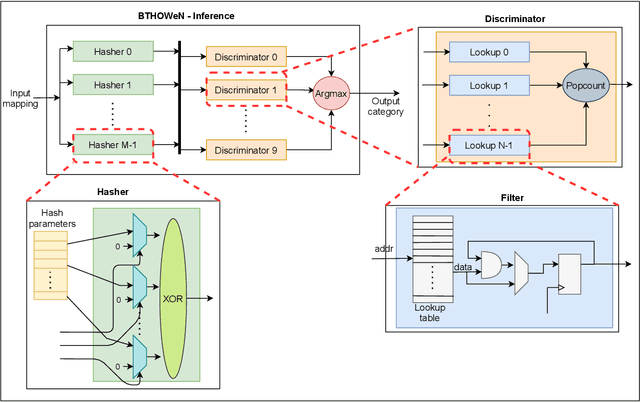
Weightless Neural Networks (WNNs) are a class of machine learning model which use table lookups to perform inference. This is in contrast with Deep Neural Networks (DNNs), which use multiply-accumulate operations. State-of-the-art WNN architectures have a fraction of the implementation cost of DNNs, but still lag behind them on accuracy for common image recognition tasks. Additionally, many existing WNN architectures suffer from high memory requirements. In this paper, we propose a novel WNN architecture, BTHOWeN, with key algorithmic and architectural improvements over prior work, namely counting Bloom filters, hardware-friendly hashing, and Gaussian-based nonlinear thermometer encodings to improve model accuracy and reduce area and energy consumption. BTHOWeN targets the large and growing edge computing sector by providing superior latency and energy efficiency to comparable quantized DNNs. Compared to state-of-the-art WNNs across nine classification datasets, BTHOWeN on average reduces error by more than than 40% and model size by more than 50%. We then demonstrate the viability of the BTHOWeN architecture by presenting an FPGA-based accelerator, and compare its latency and resource usage against similarly accurate quantized DNN accelerators, including Multi-Layer Perceptron (MLP) and convolutional models. The proposed BTHOWeN models consume almost 80% less energy than the MLP models, with nearly 85% reduction in latency. In our quest for efficient ML on the edge, WNNs are clearly deserving of additional attention.
G-Mixup: Graph Data Augmentation for Graph Classification
Feb 16, 2022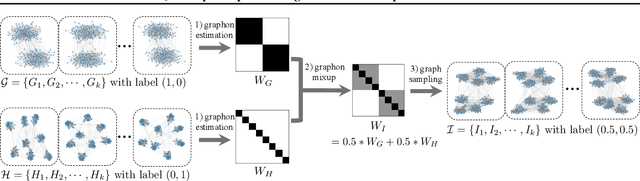

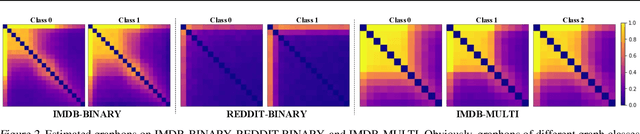
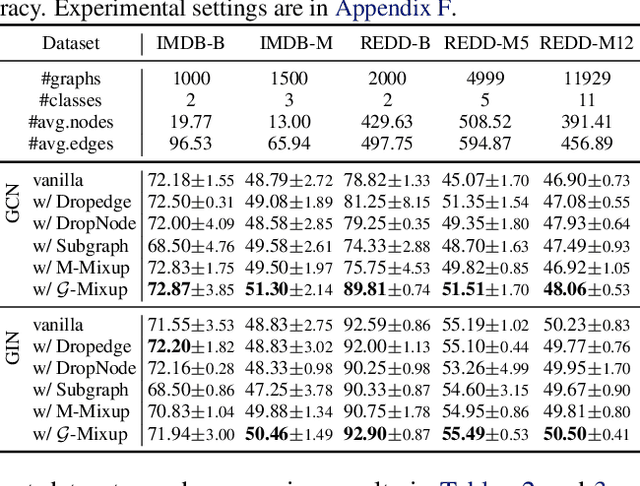
This work develops \emph{mixup for graph data}. Mixup has shown superiority in improving the generalization and robustness of neural networks by interpolating features and labels between two random samples. Traditionally, Mixup can work on regular, grid-like, and Euclidean data such as image or tabular data. However, it is challenging to directly adopt Mixup to augment graph data because different graphs typically: 1) have different numbers of nodes; 2) are not readily aligned; and 3) have unique typologies in non-Euclidean space. To this end, we propose $\mathcal{G}$-Mixup to augment graphs for graph classification by interpolating the generator (i.e., graphon) of different classes of graphs. Specifically, we first use graphs within the same class to estimate a graphon. Then, instead of directly manipulating graphs, we interpolate graphons of different classes in the Euclidean space to get mixed graphons, where the synthetic graphs are generated through sampling based on the mixed graphons. Extensive experiments show that $\mathcal{G}$-Mixup substantially improves the generalization and robustness of GNNs.
An Efficient Video Streaming Architecture with QoS Control for Virtual Desktop Infrastructure in Cloud Computing
Mar 11, 2022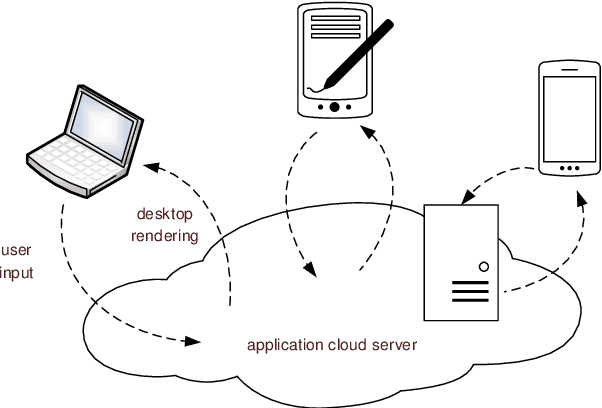

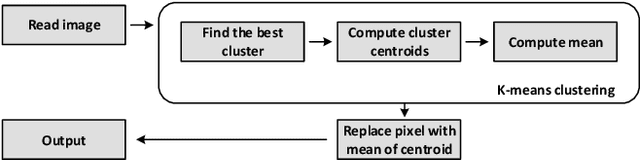
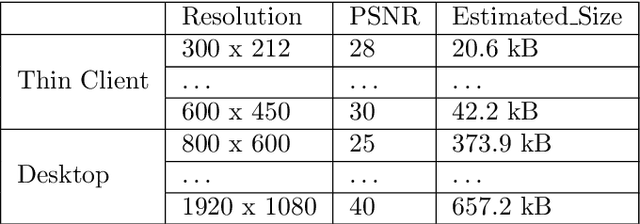
In virtual desktop infrastructure (VDI) environments, the remote display protocol has a big responsibility to transmit video data from a data center-hosted desktop to the endpoint. The protocol must ensure a high level of client perceived end-to-end quality of service (QoS) under heavy work load conditions. Each remote display protocol works differently depending on the network and which applications are being delivered. In healthcare applications, doctors and nurses can use mobile devices directly to monitor patients. Moreover, the ability to implement tasks requiring high consumption of CPU and other resources is applicable to a variety of applications including research and cloud gaming. Such computer games and complex processes will run on powerful cloud servers and the screen contents will be transmitted to the client. TO enable such applications, remote display technology requires further enhancements to meet more stringent requirements on bandwidth and QoS, an to allow realtime operation. In this paper, we present an architecture including flexible QoS control to improve the user quality of experience (QoE). The QoS control is developed based on linear regression modeling using historical network data. Additionally, the architecture includes a novel compression algorithm of 2D images, designed to guarantee the best image quality and to reduce video delay; this algorithm is based on k-means clustering and can satisfy the requirements of realtime onboard processing. Through simulations with a real work dataset collected by the MIT Computer Science and Artificial Lab, we present experimental as well as explain the performance of the QoS system.
Boosting Image Super-Resolution Via Fusion of Complementary Information Captured by Multi-Modal Sensors
Dec 07, 2020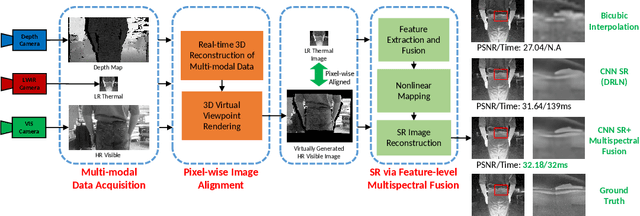

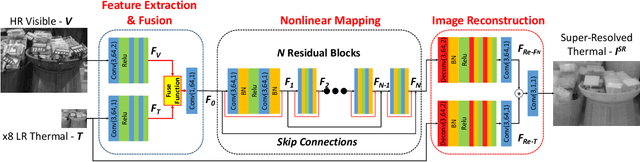
Image Super-Resolution (SR) provides a promising technique to enhance the image quality of low-resolution optical sensors, facilitating better-performing target detection and autonomous navigation in a wide range of robotics applications. It is noted that the state-of-the-art SR methods are typically trained and tested using single-channel inputs, neglecting the fact that the cost of capturing high-resolution images in different spectral domains varies significantly. In this paper, we attempt to leverage complementary information from a low-cost channel (visible/depth) to boost image quality of an expensive channel (thermal) using fewer parameters. To this end, we first present an effective method to virtually generate pixel-wise aligned visible and thermal images based on real-time 3D reconstruction of multi-modal data captured at various viewpoints. Then, we design a feature-level multispectral fusion residual network model to perform high-accuracy SR of thermal images by adaptively integrating co-occurrence features presented in multispectral images. Experimental results demonstrate that this new approach can effectively alleviate the ill-posed inverse problem of image SR by taking into account complementary information from an additional low-cost channel, significantly outperforming state-of-the-art SR approaches in terms of both accuracy and efficiency.
BIGPrior: Towards Decoupling Learned Prior Hallucination and Data Fidelity in Image Restoration
Nov 03, 2020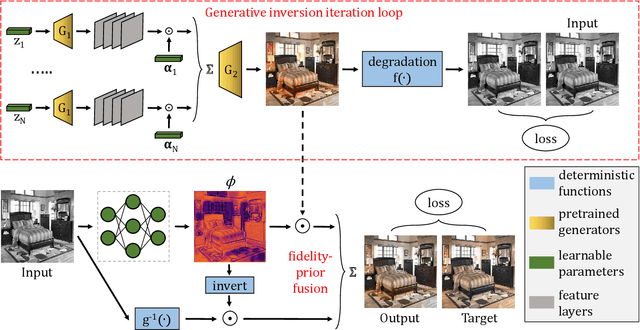



Image restoration encompasses fundamental image processing tasks that have been addressed with different algorithms and deep learning methods. Classical restoration algorithms leverage a variety of priors, either implicitly or explicitly. Their priors are hand-designed and their corresponding weights are heuristically assigned. Thus, deep learning methods often produce superior restoration quality. Deep networks are, however, capable of strong and hardly-predictable hallucinations. Networks jointly and implicitly learn to be faithful to the observed data while learning an image prior, and the separation of original and hallucinated data downstream is then not possible. This limits their wide-spread adoption in restoration applications. Furthermore, it is often the hallucinated part that is victim to degradation-model overfitting. We present an approach with decoupled network-prior hallucination and data fidelity. We refer to our framework as the Bayesian Integration of a Generative Prior (BIGPrior). Our BIGPrior method is rooted in a Bayesian restoration framework, and tightly connected to classical restoration methods. In fact, our approach can be viewed as a generalization of a large family of classical restoration algorithms. We leverage a recent network inversion method to extract image prior information from a generative network. We show on image colorization, inpainting, and denoising that our framework consistently improves the prior results through good integration of data fidelity. Our method, though partly reliant on the quality of the generative network inversion, is competitive with state-of-the-art supervised and task-specific restoration methods. It also provides an additional metric that sets forth the degree of prior reliance per pixel. Indeed, the per pixel contributions of the decoupled data fidelity and prior terms are readily available in our proposed framework.
Benchmarking Representation Learning for Natural World Image Collections
Mar 30, 2021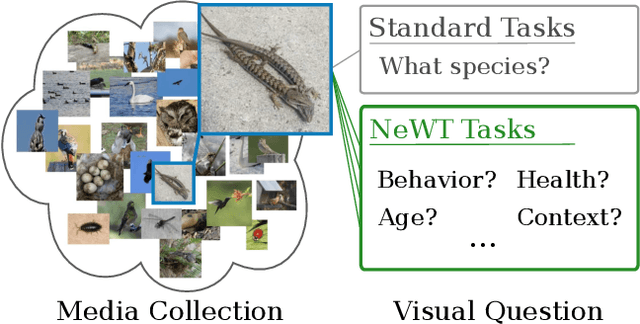

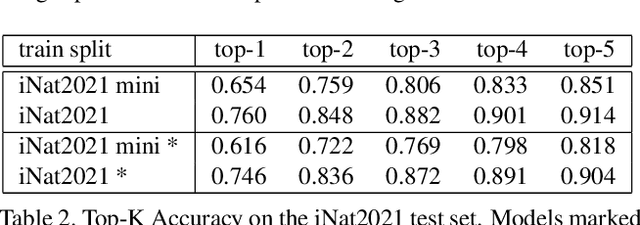

Recent progress in self-supervised learning has resulted in models that are capable of extracting rich representations from image collections without requiring any explicit label supervision. However, to date the vast majority of these approaches have restricted themselves to training on standard benchmark datasets such as ImageNet. We argue that fine-grained visual categorization problems, such as plant and animal species classification, provide an informative testbed for self-supervised learning. In order to facilitate progress in this area we present two new natural world visual classification datasets, iNat2021 and NeWT. The former consists of 2.7M images from 10k different species uploaded by users of the citizen science application iNaturalist. We designed the latter, NeWT, in collaboration with domain experts with the aim of benchmarking the performance of representation learning algorithms on a suite of challenging natural world binary classification tasks that go beyond standard species classification. These two new datasets allow us to explore questions related to large-scale representation and transfer learning in the context of fine-grained categories. We provide a comprehensive analysis of feature extractors trained with and without supervision on ImageNet and iNat2021, shedding light on the strengths and weaknesses of different learned features across a diverse set of tasks. We find that features produced by standard supervised methods still outperform those produced by self-supervised approaches such as SimCLR. However, improved self-supervised learning methods are constantly being released and the iNat2021 and NeWT datasets are a valuable resource for tracking their progress.