 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Complementary-aware Multi-process Fusion for Visual Place Recognition
Dec 09, 2021
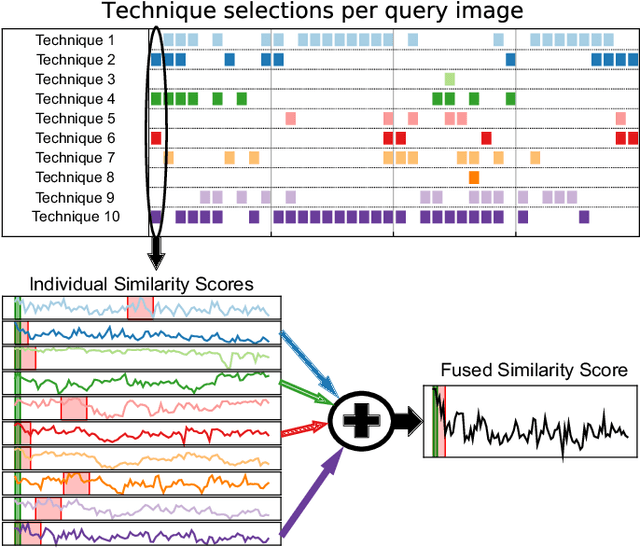
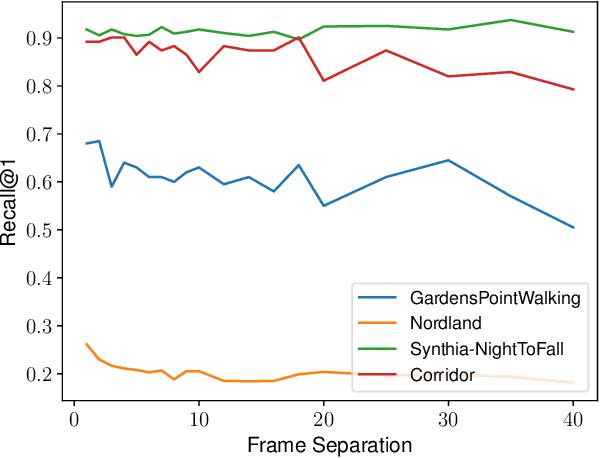
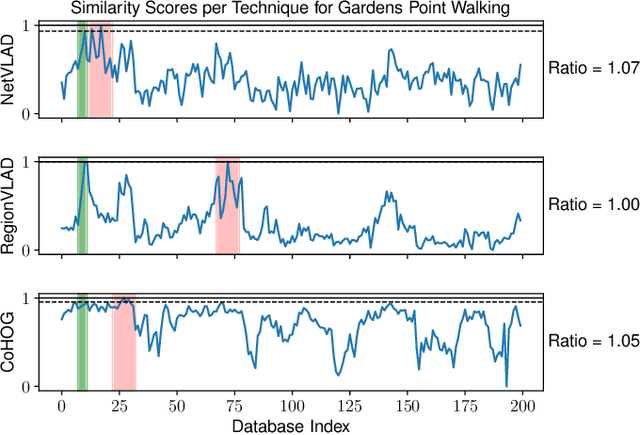
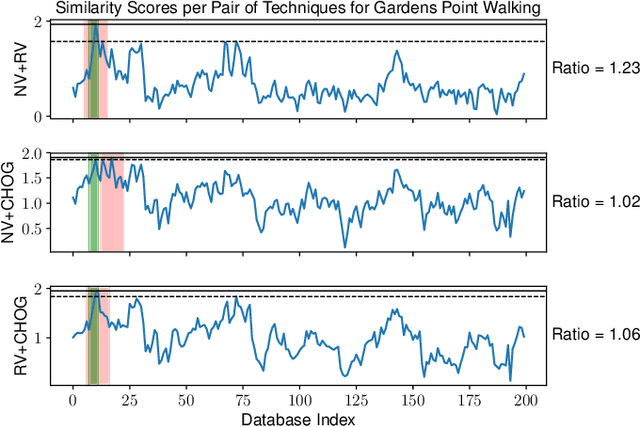
A recent approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques simultaneously. However, selecting the optimal set of techniques to use in a specific deployment environment a-priori is a difficult and unresolved challenge. Further, to the best of our knowledge, no method exists which can select a set of techniques on a frame-by-frame basis in response to image-to-image variations. In this work, we propose an unsupervised algorithm that finds the most robust set of VPR techniques to use in the current deployment environment, on a frame-by-frame basis. The selection of techniques is determined by an analysis of the similarity scores between the current query image and the collection of database images and does not require ground-truth information. We demonstrate our approach on a wide variety of datasets and VPR techniques and show that the proposed dynamic multi-process fusion (Dyn-MPF) has superior VPR performance compared to a variety of challenging competitive methods, some of which are given an unfair advantage through access to the ground-truth information.
A Deep Learning Approach for the Detection of COVID-19 from Chest X-Ray Images using Convolutional Neural Networks
Jan 24, 2022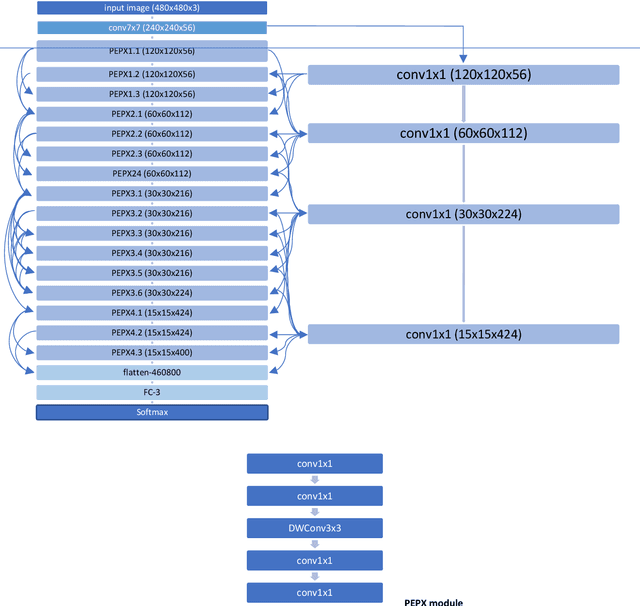
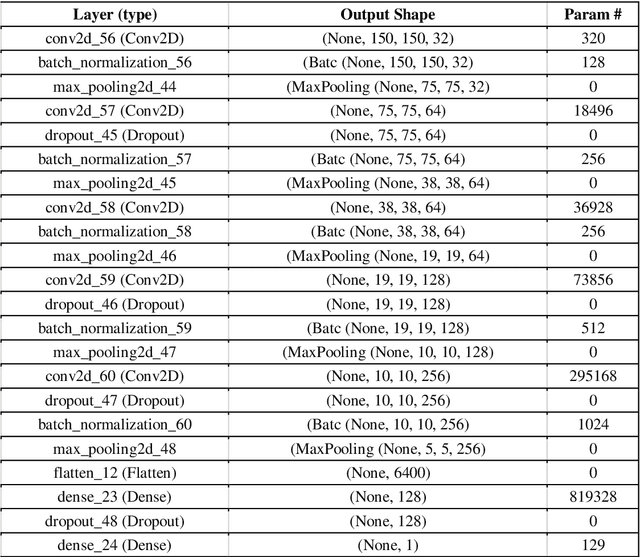
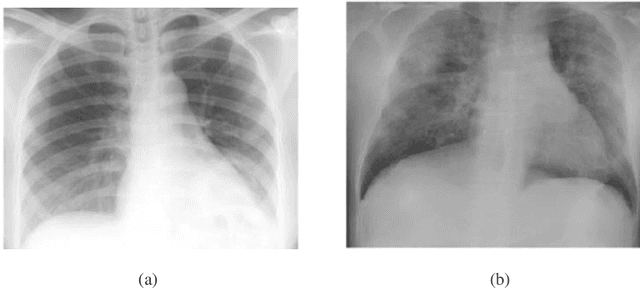
The COVID-19 (coronavirus) is an ongoing pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The virus was first identified in mid-December 2019 in the Hubei province of Wuhan, China and by now has spread throughout the planet with more than 75.5 million confirmed cases and more than 1.67 million deaths. With limited number of COVID-19 test kits available in medical facilities, it is important to develop and implement an automatic detection system as an alternative diagnosis option for COVID-19 detection that can used on a commercial scale. Chest X-ray is the first imaging technique that plays an important role in the diagnosis of COVID-19 disease. Computer vision and deep learning techniques can help in determining COVID-19 virus with Chest X-ray Images. Due to the high availability of large-scale annotated image datasets, great success has been achieved using convolutional neural network for image analysis and classification. In this research, we have proposed a deep convolutional neural network trained on five open access datasets with binary output: Normal and Covid. The performance of the model is compared with four pre-trained convolutional neural network-based models (COVID-Net, ResNet18, ResNet and MobileNet-V2) and it has been seen that the proposed model provides better accuracy on the validation set as compared to the other four pre-trained models. This research work provides promising results which can be further improvise and implement on a commercial scale.
Augmentation based unsupervised domain adaptation
Feb 23, 2022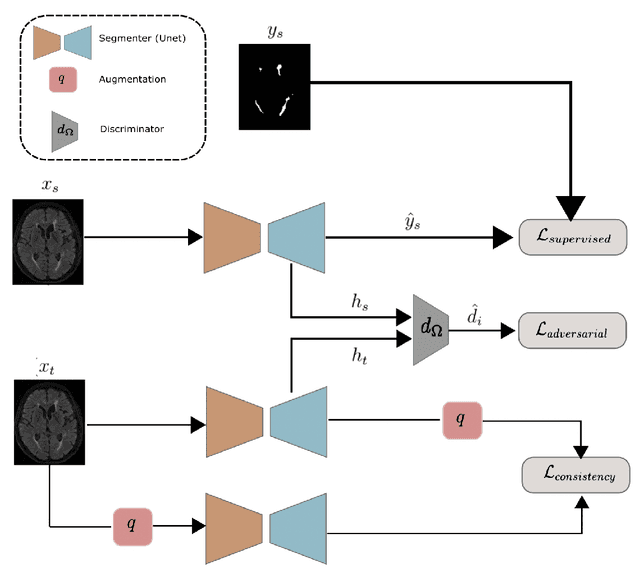

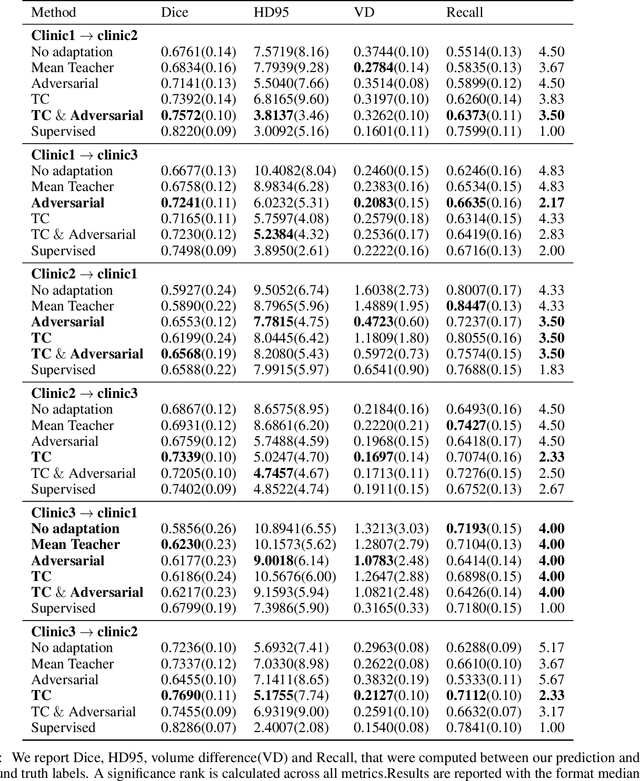
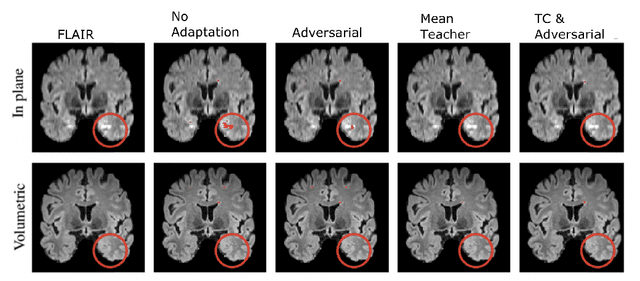
The insertion of deep learning in medical image analysis had lead to the development of state-of-the art strategies in several applications such a disease classification, as well as abnormality detection and segmentation. However, even the most advanced methods require a huge and diverse amount of data to generalize. Because in realistic clinical scenarios, data acquisition and annotation is expensive, deep learning models trained on small and unrepresentative data tend to outperform when deployed in data that differs from the one used for training (e.g data from different scanners). In this work, we proposed a domain adaptation methodology to alleviate this problem in segmentation models. Our approach takes advantage of the properties of adversarial domain adaptation and consistency training to achieve more robust adaptation. Using two datasets with white matter hyperintensities (WMH) annotations, we demonstrated that the proposed method improves model generalization even in corner cases where individual strategies tend to fail.
Implementation of Convolutional Neural Network Architecture on 3D Multiparametric Magnetic Resonance Imaging for Prostate Cancer Diagnosis
Dec 29, 2021
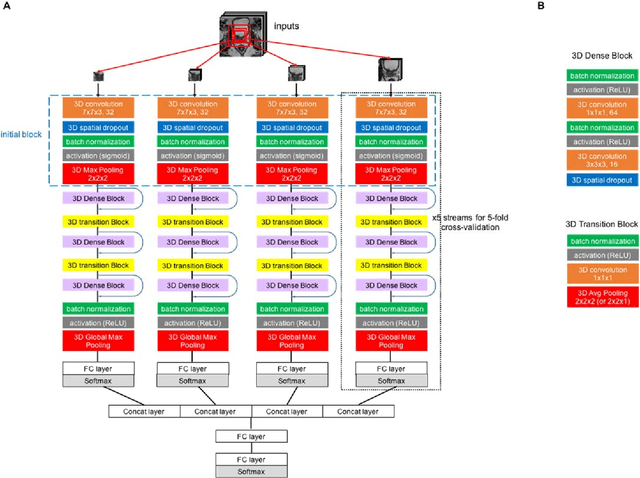
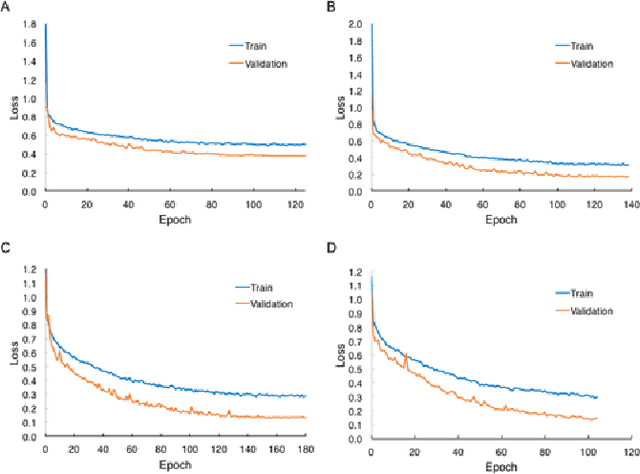
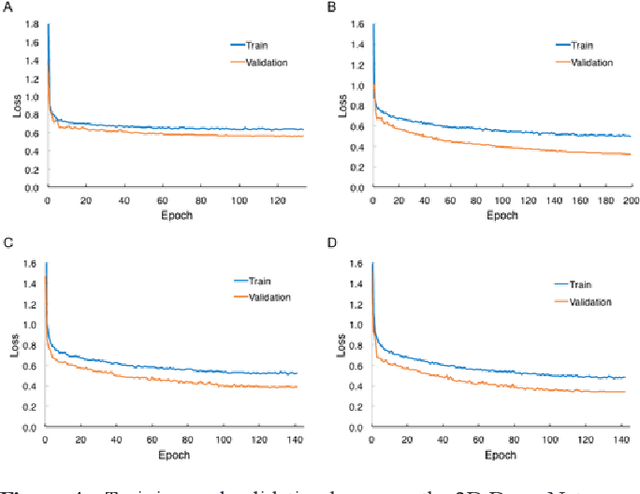
Prostate cancer is one of the most common causes of cancer deaths in men. There is a growing demand for noninvasively and accurately diagnostic methods that facilitate the current standard prostate cancer risk assessment in clinical practice. Still, developing computer-aided classification tools in prostate cancer diagnostics from multiparametric magnetic resonance images continues to be a challenge. In this work, we propose a novel deep learning approach for automatic classification of prostate lesions in the corresponding magnetic resonance images by constructing a two-stage multimodal multi-stream convolutional neural network (CNN)-based architecture framework. Without implementing sophisticated image preprocessing steps or third-party software, our framework achieved the classification performance with the area under a Receiver Operating Characteristic (ROC) curve value of 0.87. The result outperformed most of the submitted methods and shared the highest value reported by the PROSTATEx Challenge organizer. Our proposed CNN-based framework reflects the potential of assisting medical image interpretation in prostate cancer and reducing unnecessary biopsies.
Shallow Transits -- Deep Learning II: Identify Individual Exoplanetary Transits in Red Noise using Deep Learning
Mar 15, 2022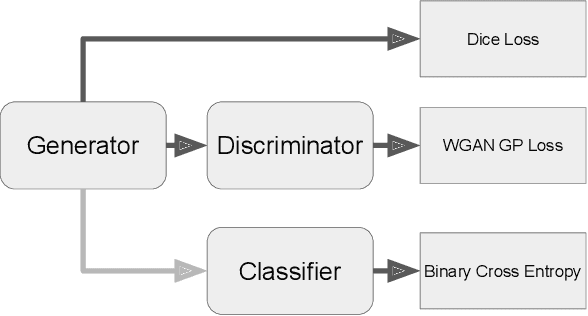

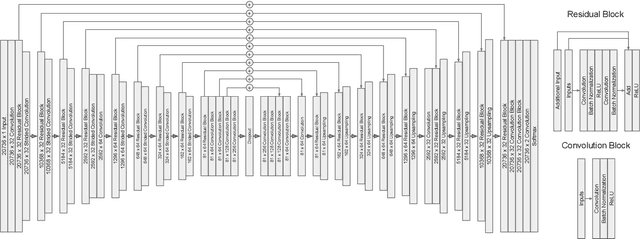
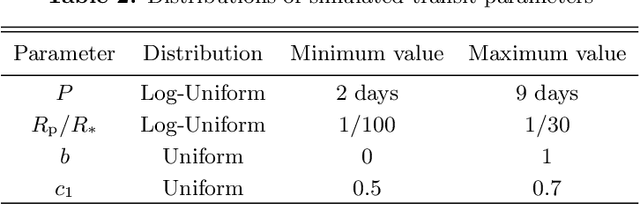
In a previous paper, we have introduced a deep learning neural network that should be able to detect the existence of very shallow periodic planetary transits in the presence of red noise. The network in that feasibility study would not provide any further details about the detected transits. The current paper completes this missing part. We present a neural network that tags samples that were obtained during transits. This is essentially similar to the task of identifying the semantic context of each pixel in an image -- an important task in computer vision, called `semantic segmentation', which is often performed by deep neural networks. The neural network we present makes use of novel deep learning concepts such as U-Nets, Generative Adversarial Networks (GAN), and adversarial loss. The resulting segmentation should allow further studies of the light curves which are tagged as containing transits. This approach towards the detection and study of very shallow transits is bound to play a significant role in future space-based transit surveys such as PLATO, which are specifically aimed to detect those extremely difficult cases of long-period shallow transits. Our segmentation network also adds to the growing toolbox of deep learning approaches which are being increasingly used in the study of exoplanets, but so far mainly for vetting transits, rather than their initial detection.
Image Captioning as an Assistive Technology: Lessons Learned from VizWiz 2020 Challenge
Dec 21, 2020
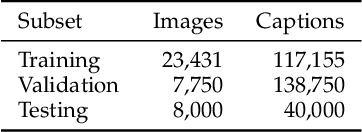
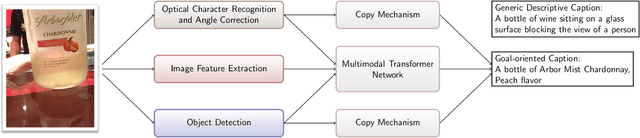
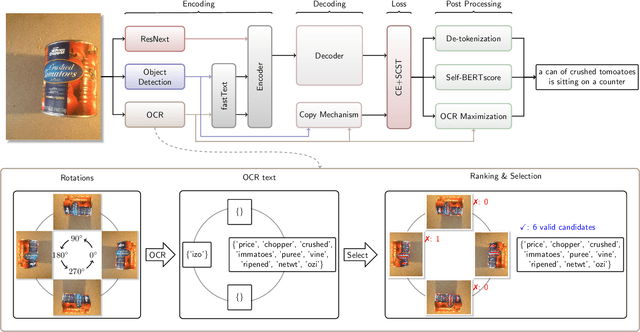
Image captioning has recently demonstrated impressive progress largely owing to the introduction of neural network algorithms trained on curated dataset like MS-COCO. Often work in this field is motivated by the promise of deployment of captioning systems in practical applications. However, the scarcity of data and contexts in many competition datasets renders the utility of systems trained on these datasets limited as an assistive technology in real-world settings, such as helping visually impaired people navigate and accomplish everyday tasks. This gap motivated the introduction of the novel VizWiz dataset, which consists of images taken by the visually impaired and captions that have useful, task-oriented information. In an attempt to help the machine learning computer vision field realize its promise of producing technologies that have positive social impact, the curators of the VizWiz dataset host several competitions, including one for image captioning. This work details the theory and engineering from our winning submission to the 2020 captioning competition. Our work provides a step towards improved assistive image captioning systems.
Unsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation
Mar 18, 2020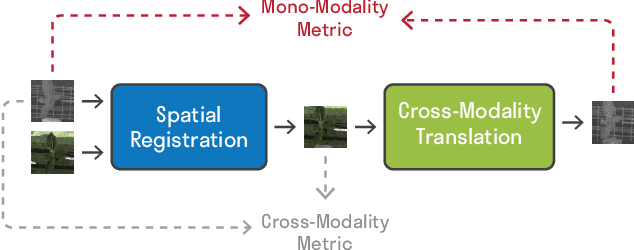
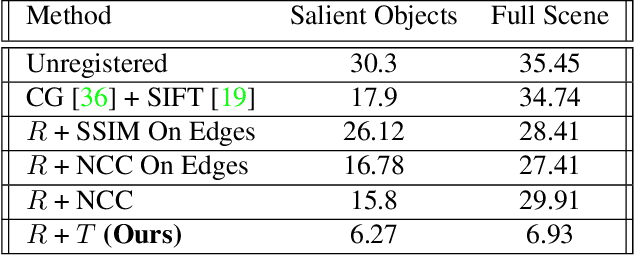
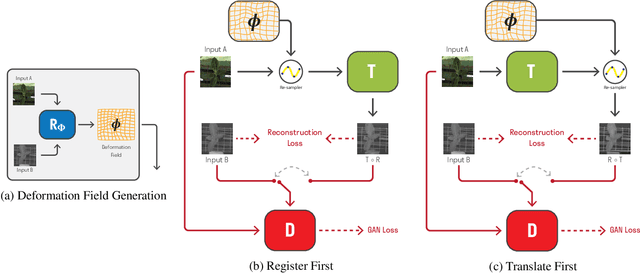
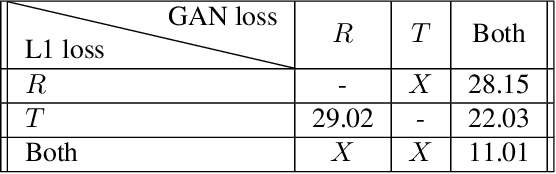
Many applications, such as autonomous driving, heavily rely on multi-modal data where spatial alignment between the modalities is required. Most multi-modal registration methods struggle computing the spatial correspondence between the images using prevalent cross-modality similarity measures. In this work, we bypass the difficulties of developing cross-modality similarity measures, by training an image-to-image translation network on the two input modalities. This learned translation allows training the registration network using simple and reliable mono-modality metrics. We perform multi-modal registration using two networks - a spatial transformation network and a translation network. We show that by encouraging our translation network to be geometry preserving, we manage to train an accurate spatial transformation network. Compared to state-of-the-art multi-modal methods our presented method is unsupervised, requiring no pairs of aligned modalities for training, and can be adapted to any pair of modalities. We evaluate our method quantitatively and qualitatively on commercial datasets, showing that it performs well on several modalities and achieves accurate alignment.
Associative Adversarial Learning Based on Selective Attack
Jan 04, 2022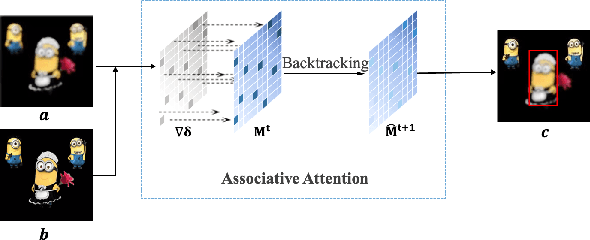
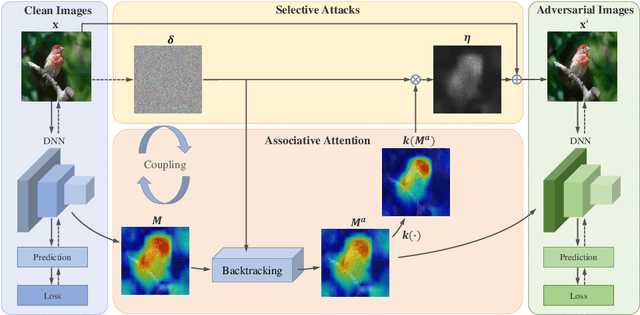
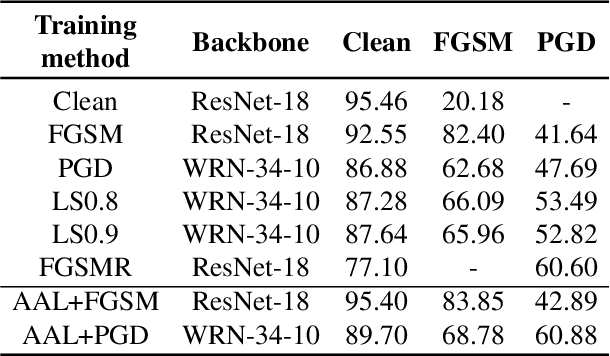
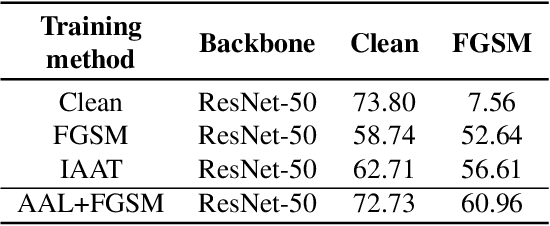
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Deep Image Prior for Sparse-sampling Photoacoustic Microscopy
Oct 15, 2020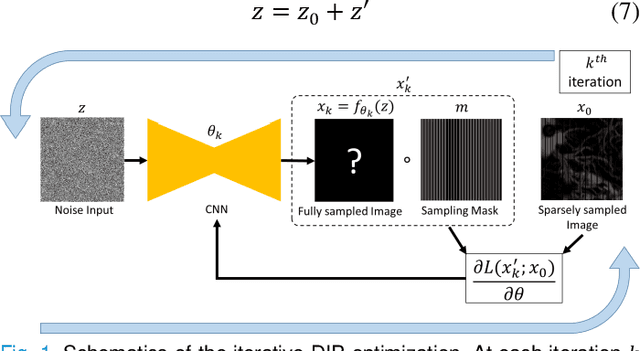
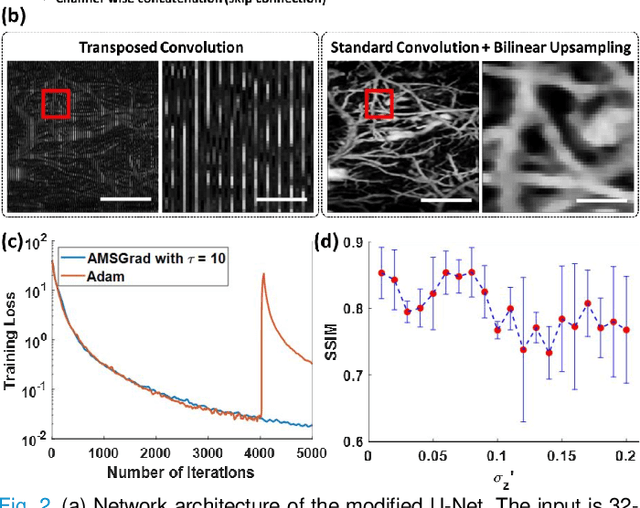
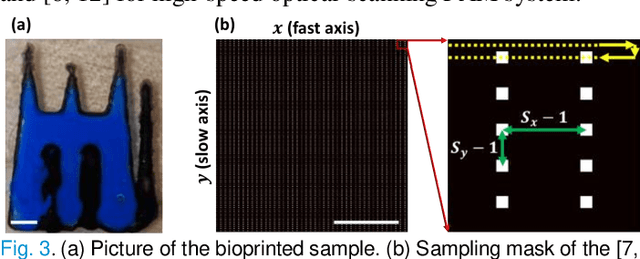
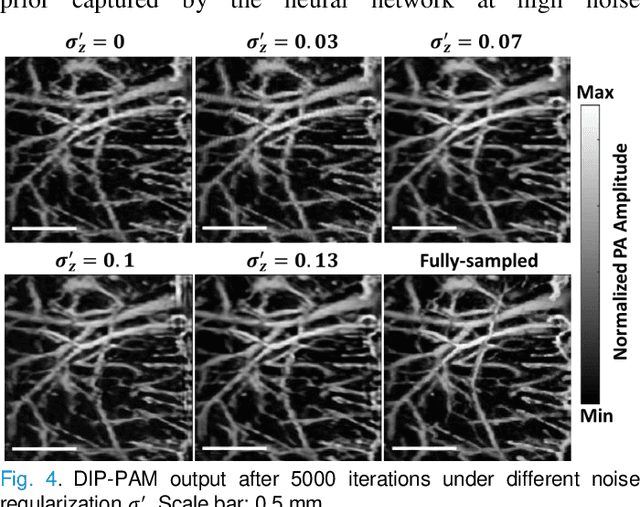
Photoacoustic microscopy (PAM) is an emerging method for imaging both structural and functional information without the need for exogenous contrast agents. However, state-of-the-art PAM faces a tradeoff between imaging speed and spatial sampling density within the same field-of-view (FOV). Limited by the pulsed laser's repetition rate, the imaging speed is inversely proportional to the total number of effective pixels. To cover the same FOV in a shorter amount of time with the same PAM hardware, there is currently no other option than to decrease spatial sampling density (i.e., sparse sampling). Deep learning methods have recently been used to improve sparsely sampled PAM images; however, these methods often require time-consuming pre-training and a large training dataset that has fully sampled, co-registered ground truth. In this paper, we propose using a method known as "deep image prior" to improve the image quality of sparsely sampled PAM images. The network does not need prior learning or fully sampled ground truth, making its implementation more flexible and much quicker. Our results show promising improvement in PA vasculature images with as few as 2% of the effective pixels. Our deep image prior approach produces results that outperform interpolation methods and can be readily translated to other high-speed, sparse-sampling imaging modalities.
Cross-Region Building Counting in Satellite Imagery using Counting Consistency
Oct 26, 2021
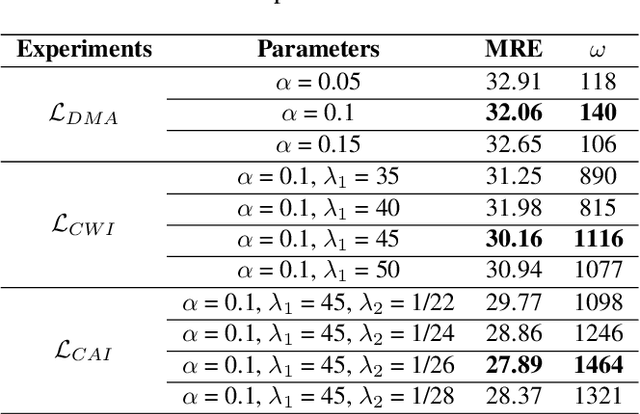
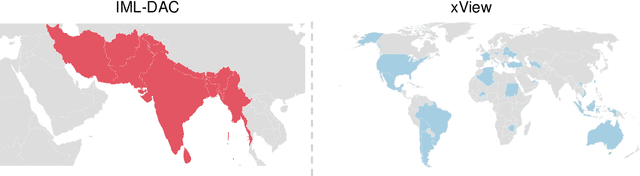
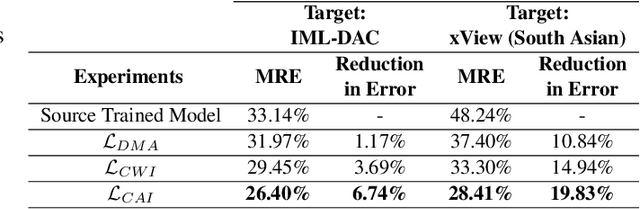
Estimating the number of buildings in any geographical region is a vital component of urban analysis, disaster management, and public policy decision. Deep learning methods for building localization and counting in satellite imagery, can serve as a viable and cheap alternative. However, these algorithms suffer performance degradation when applied to the regions on which they have not been trained. Current large datasets mostly cover the developed regions and collecting such datasets for every region is a costly, time-consuming, and difficult endeavor. In this paper, we propose an unsupervised domain adaptation method for counting buildings where we use a labeled source domain (developed regions) and adapt the trained model on an unlabeled target domain (developing regions). We initially align distribution maps across domains by aligning the output space distribution through adversarial loss. We then exploit counting consistency constraints, within-image count consistency, and across-image count consistency, to decrease the domain shift. Within-image consistency enforces that building count in the whole image should be greater than or equal to count in any of its sub-image. Across-image consistency constraint enforces that if an image contains considerably more buildings than the other image, then their sub-images shall also have the same order. These two constraints encourage the behavior to be consistent across and within the images, regardless of the scale. To evaluate the performance of our proposed approach, we collected and annotated a large-scale dataset consisting of challenging South Asian regions having higher building densities and irregular structures as compared to existing datasets. We perform extensive experiments to verify the efficacy of our approach and report improvements of approximately 7% to 20% over the competitive baseline methods.