 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Particle Image Velocimetry
Jan 28, 2021
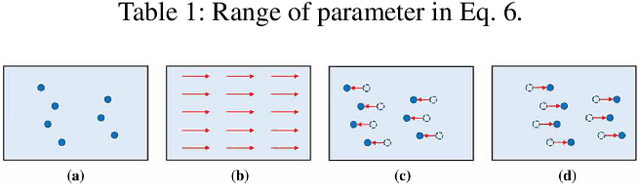

In the past decades, great progress has been made in the field of optical and particle-based measurement techniques for experimental analysis of fluid flows. Particle Image Velocimetry (PIV) technique is widely used to identify flow parameters from time-consecutive snapshots of particles injected into the fluid. The computation is performed as post-processing of the experimental data via proximity measure between particles in frames of reference. However, the post-processing step becomes problematic as the motility and density of the particles increases, since the data emerges in extreme rates and volumes. Moreover, existing algorithms for PIV either provide sparse estimations of the flow or require large computational time frame preventing from on-line use. The goal of this manuscript is therefore to develop an accurate on-line algorithm for estimation of the fine-grained velocity field from PIV data. As the data constitutes a pair of images, we employ computer vision methods to solve the problem. In this work, we introduce a convolutional neural network adapted to the problem, namely Volumetric Correspondence Network (VCN) which was recently proposed for the end-to-end optical flow estimation in computer vision. The network is thoroughly trained and tested on a dataset containing both synthetic and real flow data. Experimental results are analyzed and compared to that of conventional methods as well as other recently introduced methods based on neural networks. Our analysis indicates that the proposed approach provides improved efficiency also keeping accuracy on par with other state-of-the-art methods in the field. We also verify through a-posteriori tests that our newly constructed VCN schemes are reproducing well physically relevant statistics of velocity and velocity gradients.
A Quantitative Comparison between Shannon and Tsallis Havrda Charvat Entropies Applied to Cancer Outcome Prediction
Mar 22, 2022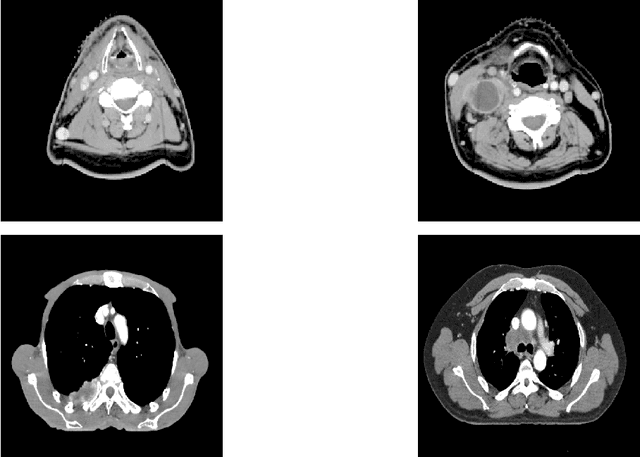
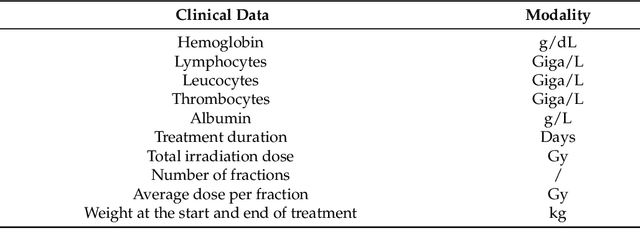
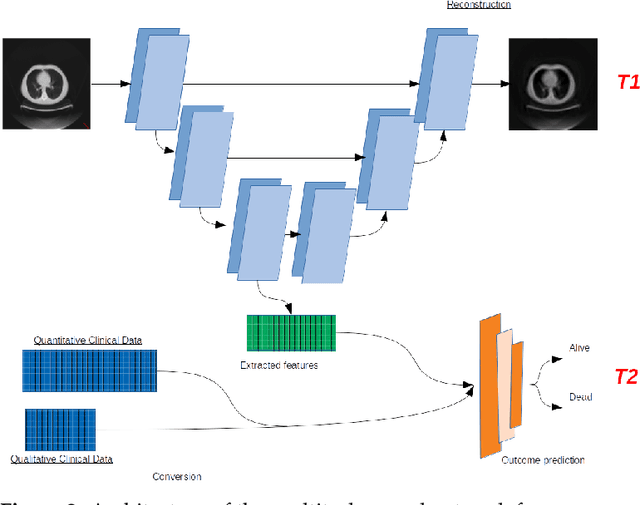

In this paper, we propose to quantitatively compare loss functions based on parameterized Tsallis-Havrda-Charvat entropy and classical Shannon entropy for the training of a deep network in the case of small datasets which are usually encountered in medical applications. Shannon cross-entropy is widely used as a loss function for most neural networks applied to the segmentation, classification and detection of images. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy. In this work, we compare these two entropies through a medical application for predicting recurrence in patients with head-neck and lung cancers after treatment. Based on both CT images and patient information, a multitask deep neural network is proposed to perform a recurrence prediction task using cross-entropy as a loss function and an image reconstruction task. Tsallis-Havrda-Charvat cross-entropy is a parameterized cross entropy with the parameter $\alpha$. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy for $\alpha$ = 1. The influence of this parameter on the final prediction results is studied. In this paper, the experiments are conducted on two datasets including in total 580 patients, of whom 434 suffered from head-neck cancers and 146 from lung cancers. The results show that Tsallis-Havrda-Charvat entropy can achieve better performance in terms of prediction accuracy with some values of $\alpha$.
* 11 pages, 3 figures
NeILF: Neural Incident Light Field for Physically-based Material Estimation
Mar 18, 2022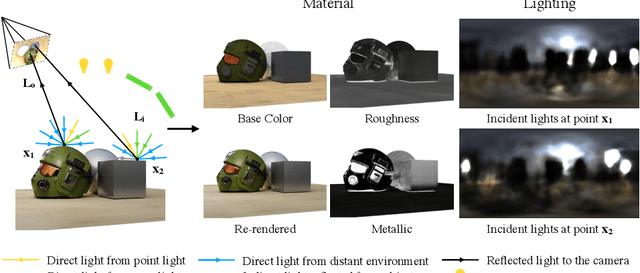
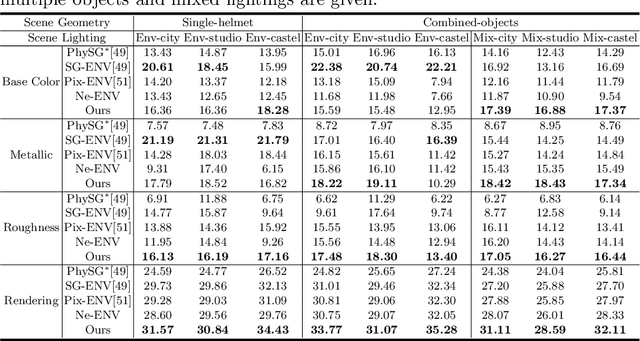
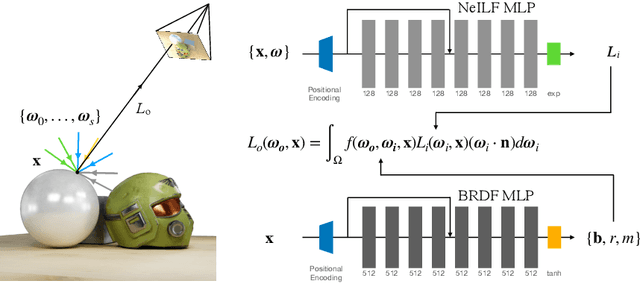

We present a differentiable rendering framework for material and lighting estimation from multi-view images and a reconstructed geometry. In the framework, we represent scene lightings as the Neural Incident Light Field (NeILF) and material properties as the surface BRDF modelled by multi-layer perceptrons. Compared with recent approaches that approximate scene lightings as the 2D environment map, NeILF is a fully 5D light field that is capable of modelling illuminations of any static scenes. In addition, occlusions and indirect lights can be handled naturally by the NeILF representation without requiring multiple bounces of ray tracing, making it possible to estimate material properties even for scenes with complex lightings and geometries. We also propose a smoothness regularization and a Lambertian assumption to reduce the material-lighting ambiguity during the optimization. Our method strictly follows the physically-based rendering equation, and jointly optimizes material and lighting through the differentiable rendering process. We have intensively evaluated the proposed method on our in-house synthetic dataset, the DTU MVS dataset, and real-world BlendedMVS scenes. Our method is able to outperform previous methods by a significant margin in terms of novel view rendering quality, setting a new state-of-the-art for image-based material and lighting estimation.
Visual Feature Encoding for GNNs on Road Networks
Mar 02, 2022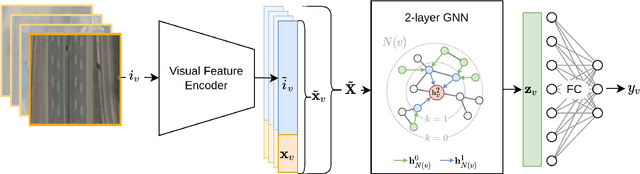
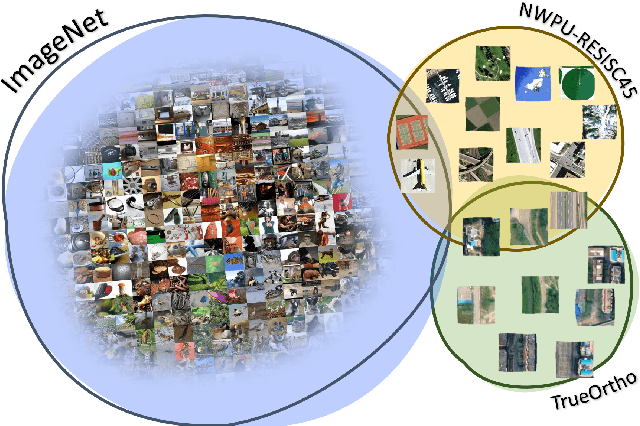
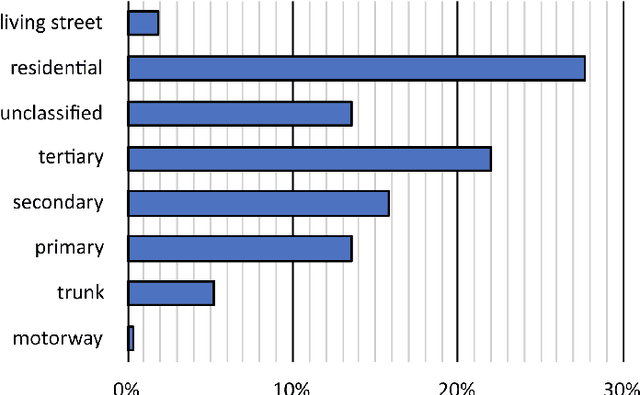
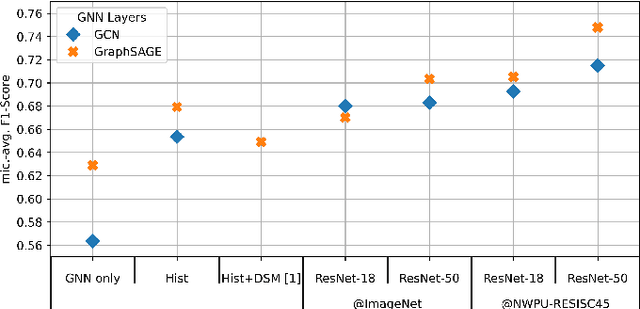
In this work, we present a novel approach to learning an encoding of visual features into graph neural networks with the application on road network data. We propose an architecture that combines state-of-the-art vision backbone networks with graph neural networks. More specifically, we perform a road type classification task on an Open Street Map road network through encoding of satellite imagery using various ResNet architectures. Our architecture further enables fine-tuning and a transfer-learning approach is evaluated by pretraining on the NWPU-RESISC45 image classification dataset for remote sensing and comparing them to purely ImageNet-pretrained ResNet models as visual feature encoders. The results show not only that the visual feature encoders are superior to low-level visual features, but also that the fine-tuning of the visual feature encoder to a general remote sensing dataset such as NWPU-RESISC45 can further improve the performance of a GNN on a machine learning task like road type classification.
Omnidirectional MediA Format (OMAF): Toolbox for Virtual Reality Services
Mar 02, 2022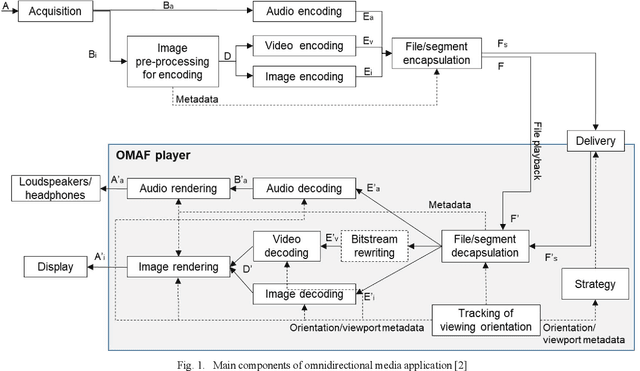
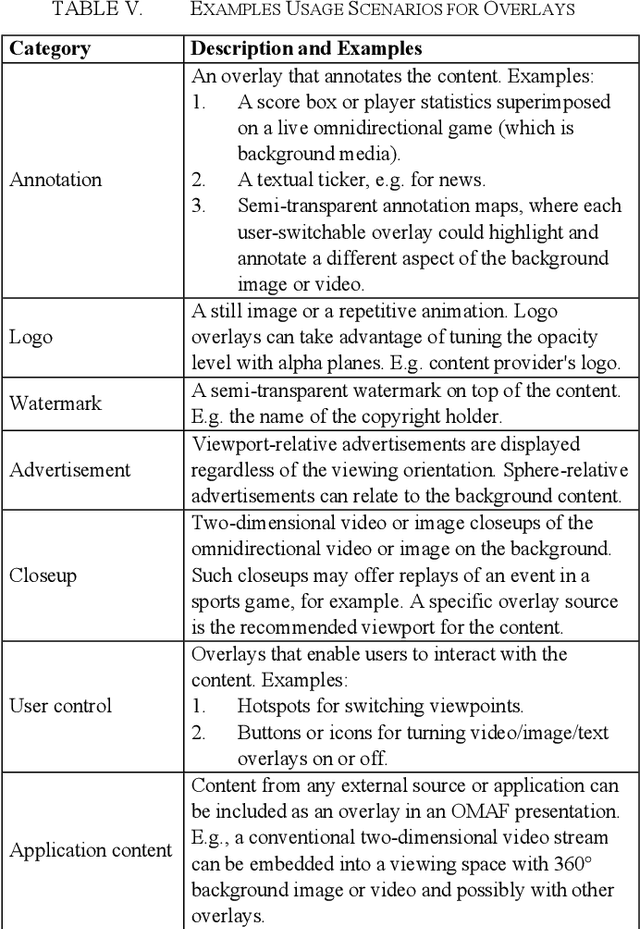
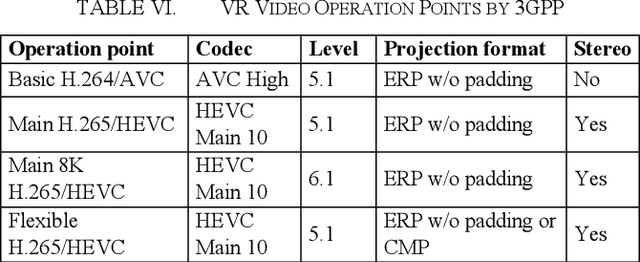
This paper provides an overview of the Omnidirectional Media Format (OMAF) standard, second edition, which has been recently finalized. OMAF specifies the media format for coding, storage, delivery, and rendering of omnidirectional media, including video, audio, images, and timed text. Additionally, OMAF supports multiple viewpoints corresponding to omnidirectional cameras and overlay images or video rendered over the omnidirectional background image or video. Many examples of usage scenarios for multiple viewpoints and overlays are described in the paper. OMAF provides a toolbox of features, which can be selectively used in virtual reality services. Consequently, the paper presents the interoperability points specified in the OMAF standard, which enable signaling which OMAF features are in use or required to be supported in implementations. Finally, the paper summarizes which OMAF interoperability points have been taken into use in virtual reality service specifications by the 3rd Generation Partnership Project (3GPP) and the Virtual Reality Industry Forum (VRIF).
* 7 pages, 1 figure. This document is the accepted version of the paper that has been published in 2021 IEEE Conference on Standards for Communications and Networking (CSCN)
Dynamic imaging using Motion-Compensated SmooThness Regularization on Manifolds (MoCo-SToRM)
Dec 06, 2021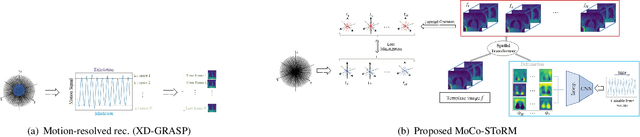
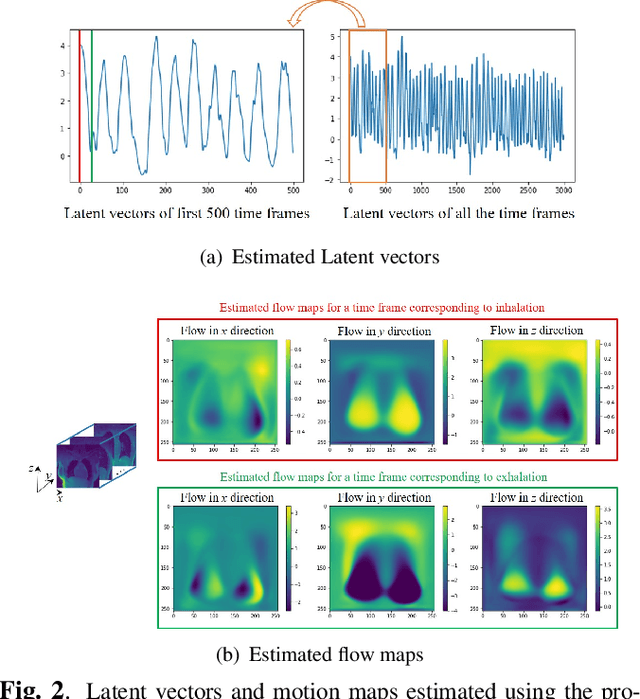
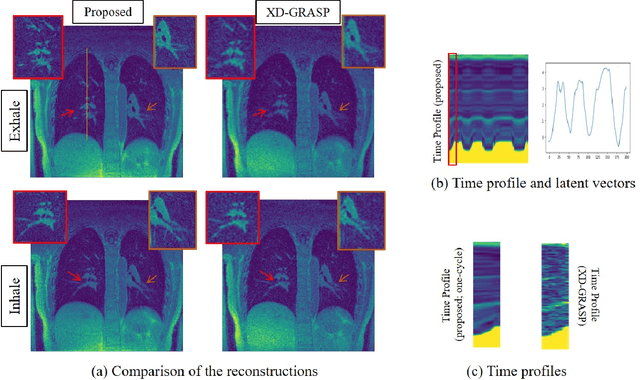
We introduce an unsupervised motion-compensated reconstruction scheme for high-resolution free-breathing pulmonary MRI. We model the image frames in the time series as the deformed version of the 3D template image volume. We assume the deformation maps to be points on a smooth manifold in high-dimensional space. Specifically, we model the deformation map at each time instant as the output of a CNN-based generator that has the same weight for all time-frames, driven by a low-dimensional latent vector. The time series of latent vectors account for the dynamics in the dataset, including respiratory motion and bulk motion. The template image volume, the parameters of the generator, and the latent vectors are learned directly from the k-t space data in an unsupervised fashion. Our experimental results show improved reconstructions compared to state-of-the-art methods, especially in the context of bulk motion during the scans.
Deep Translation Prior: Test-time Training for Photorealistic Style Transfer
Dec 12, 2021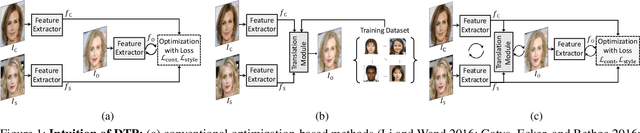
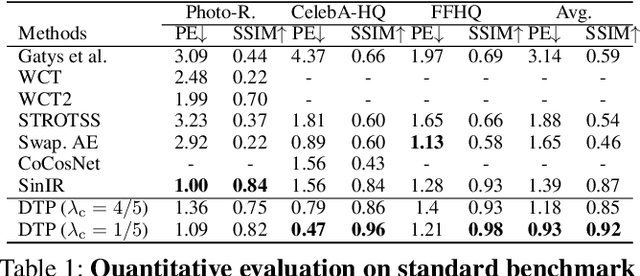
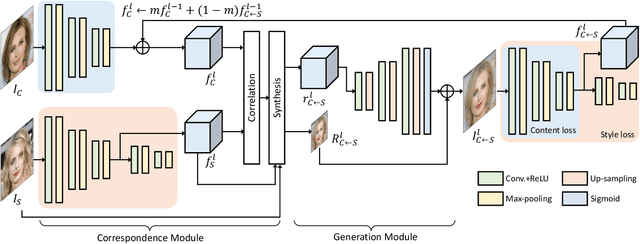
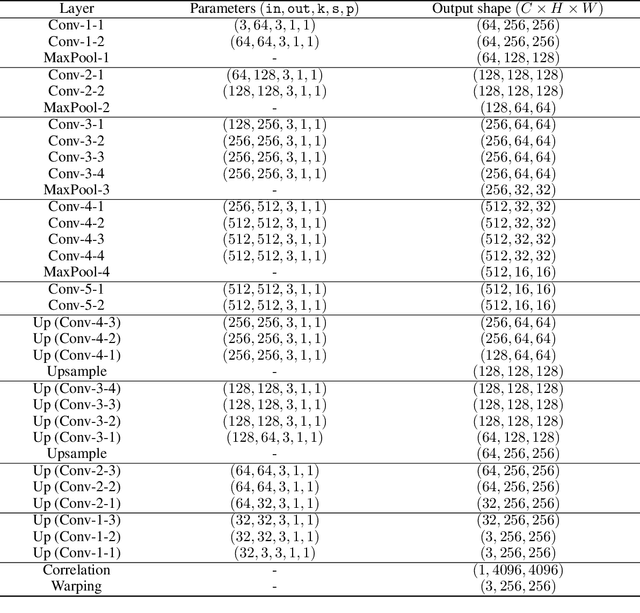
Recent techniques to solve photorealistic style transfer within deep convolutional neural networks (CNNs) generally require intensive training from large-scale datasets, thus having limited applicability and poor generalization ability to unseen images or styles. To overcome this, we propose a novel framework, dubbed Deep Translation Prior (DTP), to accomplish photorealistic style transfer through test-time training on given input image pair with untrained networks, which learns an image pair-specific translation prior and thus yields better performance and generalization. Tailored for such test-time training for style transfer, we present novel network architectures, with two sub-modules of correspondence and generation modules, and loss functions consisting of contrastive content, style, and cycle consistency losses. Our framework does not require offline training phase for style transfer, which has been one of the main challenges in existing methods, but the networks are to be solely learned during test-time. Experimental results prove that our framework has a better generalization ability to unseen image pairs and even outperforms the state-of-the-art methods.
Semantically Grounded Visual Embeddings for Zero-Shot Learning
Jan 03, 2022
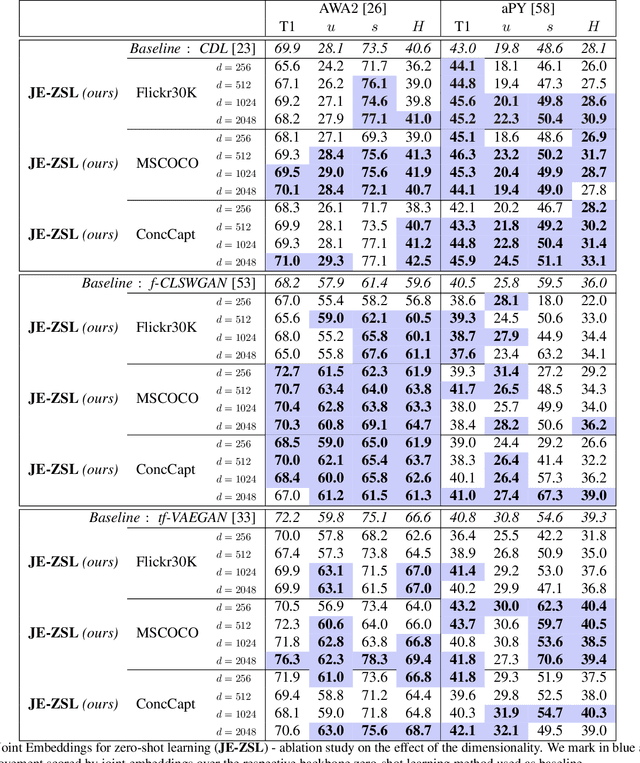
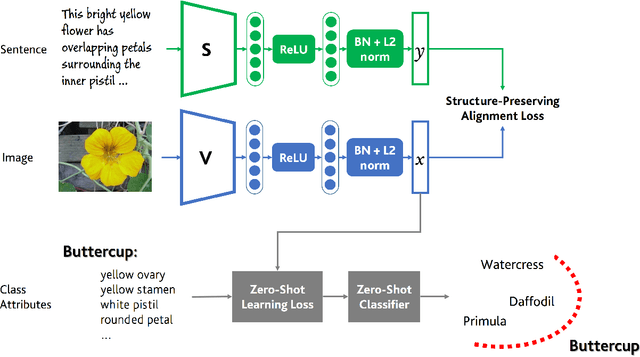
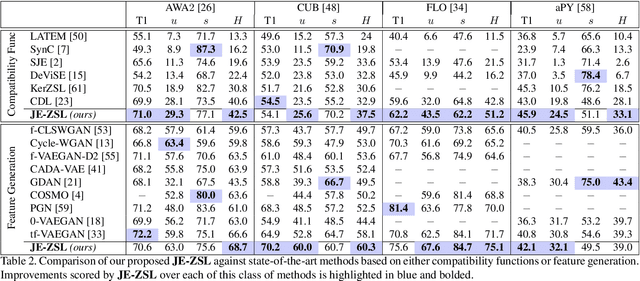
Zero-shot learning methods rely on fixed visual and semantic embeddings, extracted from independent vision and language models, both pre-trained for other large-scale tasks. This is a weakness of current zero-shot learning frameworks as such disjoint embeddings fail to adequately associate visual and textual information to their shared semantic content. Therefore, we propose to learn semantically grounded and enriched visual information by computing a joint image and text model with a two-stream network on a proxy task. To improve this alignment between image and textual representations, provided by attributes, we leverage ancillary captions to provide grounded semantic information. Our method, dubbed joint embeddings for zero-shot learning is evaluated on several benchmark datasets, improving the performance of existing state-of-the-art methods in both standard ($+1.6$\% on aPY, $+2.6\%$ on FLO) and generalized ($+2.1\%$ on AWA$2$, $+2.2\%$ on CUB) zero-shot recognition.
Essential Features: Reducing the Attack Surface of Adversarial Perturbations with Robust Content-Aware Image Preprocessing
Dec 03, 2020
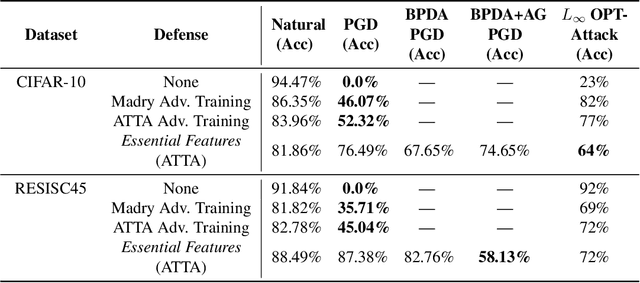
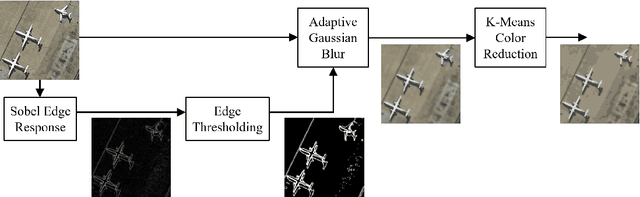
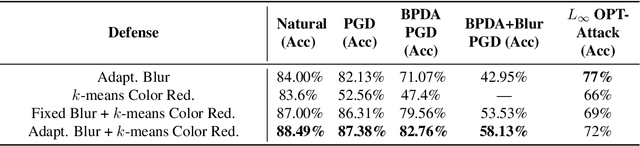
Adversaries are capable of adding perturbations to an image to fool machine learning models into incorrect predictions. One approach to defending against such perturbations is to apply image preprocessing functions to remove the effects of the perturbation. Existing approaches tend to be designed orthogonally to the content of the image and can be beaten by adaptive attacks. We propose a novel image preprocessing technique called Essential Features that transforms the image into a robust feature space that preserves the main content of the image while significantly reducing the effects of the perturbations. Specifically, an adaptive blurring strategy that preserves the main edge features of the original object along with a k-means color reduction approach is employed to simplify the image to its k most representative colors. This approach significantly limits the attack surface for adversaries by limiting the ability to adjust colors while preserving pertinent features of the original image. We additionally design several adaptive attacks and find that our approach remains more robust than previous baselines. On CIFAR-10 we achieve 64% robustness and 58.13% robustness on RESISC45, raising robustness by over 10% versus state-of-the-art adversarial training techniques against adaptive white-box and black-box attacks. The results suggest that strategies that retain essential features in images by adaptive processing of the content hold promise as a complement to adversarial training for boosting robustness against adversarial inputs.
Robust Contrastive Learning against Noisy Views
Jan 12, 2022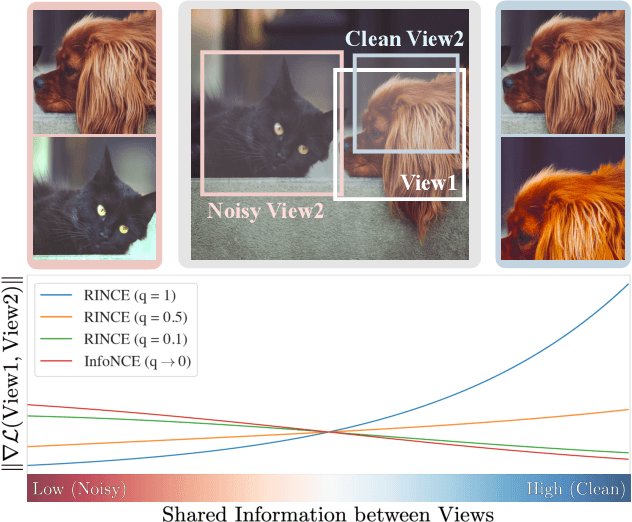
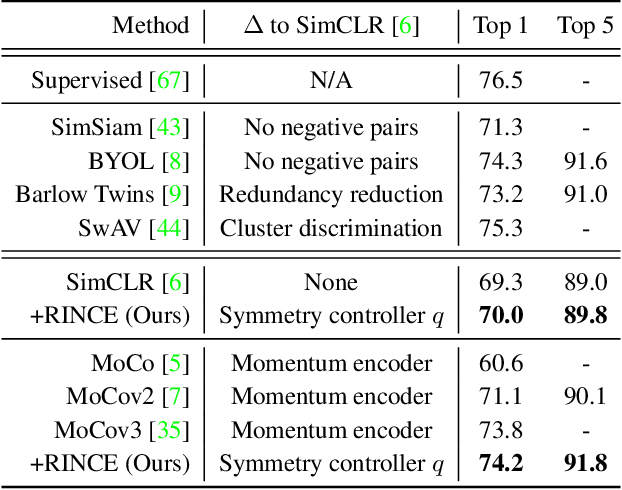

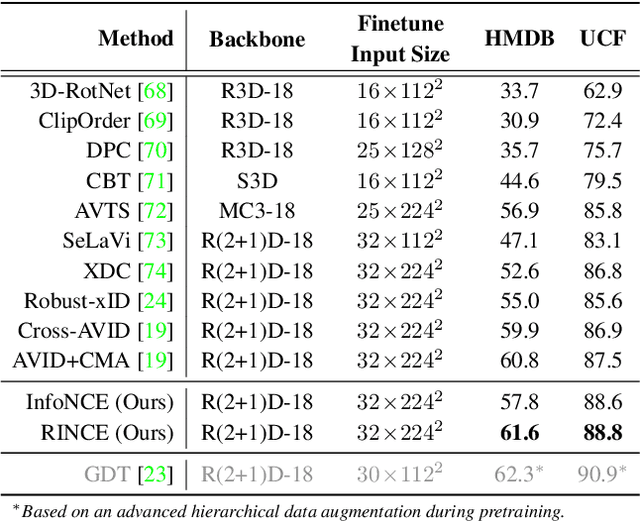
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.