 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Thermal Image Super-Resolution Using Second-Order Channel Attention with Varying Receptive Fields
Jul 30, 2021
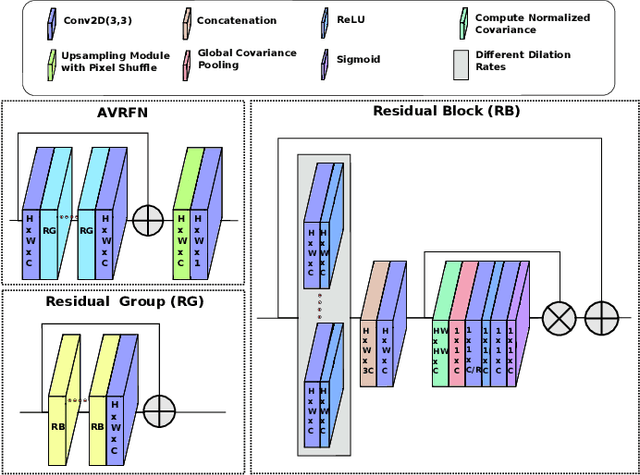
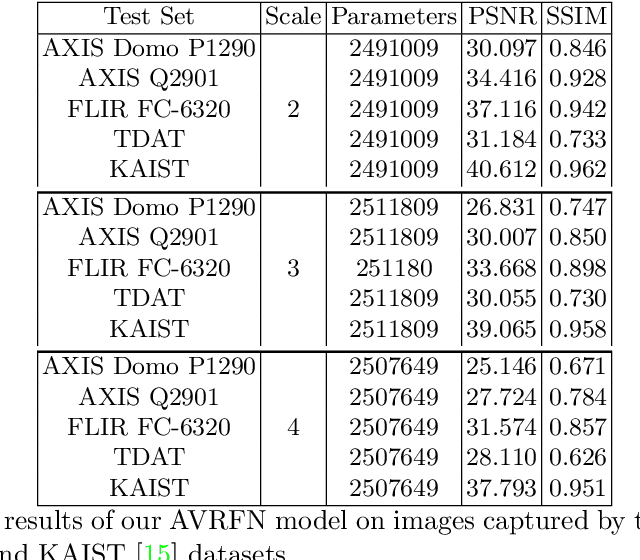
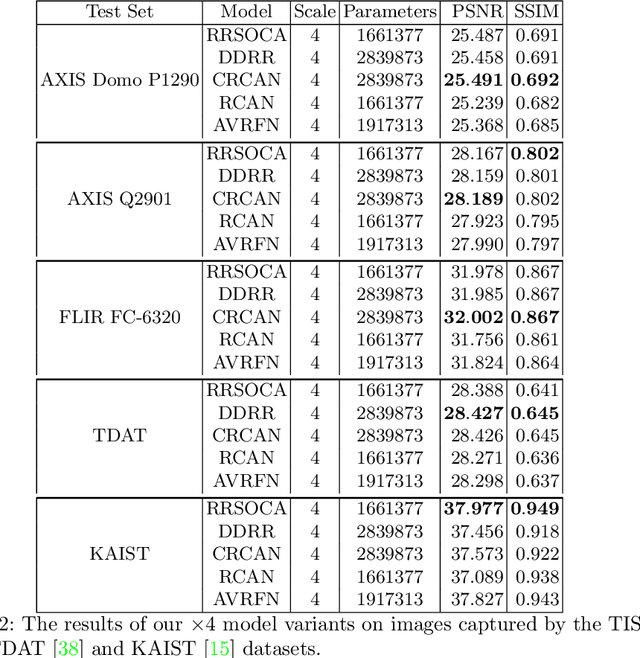

Thermal images model the long-infrared range of the electromagnetic spectrum and provide meaningful information even when there is no visible illumination. Yet, unlike imagery that represents radiation from the visible continuum, infrared images are inherently low-resolution due to hardware constraints. The restoration of thermal images is critical for applications that involve safety, search and rescue, and military operations. In this paper, we introduce a system to efficiently reconstruct thermal images. Specifically, we explore how to effectively attend to contrasting receptive fields (RFs) where increasing the RFs of a network can be computationally expensive. For this purpose, we introduce a deep attention to varying receptive fields network (AVRFN). We supply a gated convolutional layer with higher-order information extracted from disparate RFs, whereby an RF is parameterized by a dilation rate. In this way, the dilation rate can be tuned to use fewer parameters thus increasing the efficacy of AVRFN. Our experimental results show an improvement over the state of the art when compared against competing thermal image super-resolution methods.
Improving Unsupervised Image Clustering With Robust Learning
Dec 21, 2020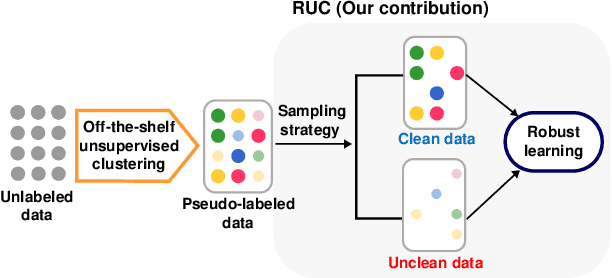
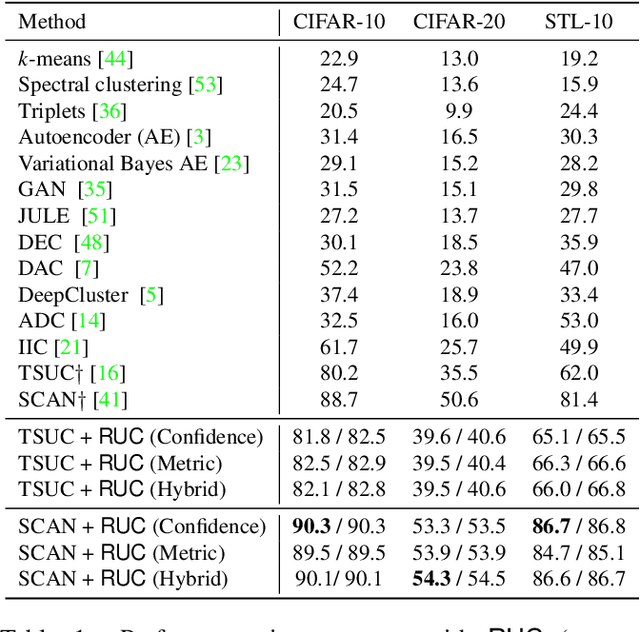
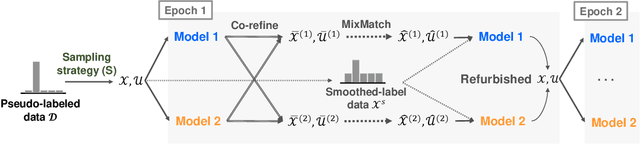

Unsupervised image clustering methods often introduce alternative objectives to indirectly train the model and are subject to faulty predictions and overconfident results. To overcome these challenges, the current research proposes an innovative model RUC that is inspired by robust learning. RUC's novelty is at utilizing pseudo-labels of existing image clustering models as a noisy dataset that may include misclassified samples. Its retraining process can revise misaligned knowledge and alleviate the overconfidence problem in predictions. This model's flexible structure makes it possible to be used as an add-on module to state-of-the-art clustering methods and helps them achieve better performance on multiple datasets. Extensive experiments show that the proposed model can adjust the model confidence with better calibration and gain additional robustness against adversarial noise.
ReconResNet: Regularised Residual Learning for MR Image Reconstruction of Undersampled Cartesian and Radial Data
Mar 16, 2021
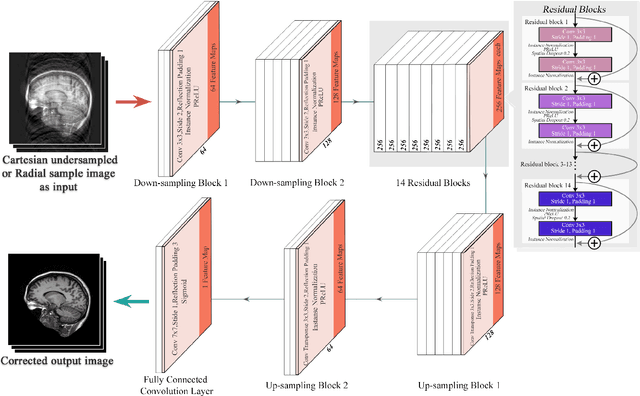
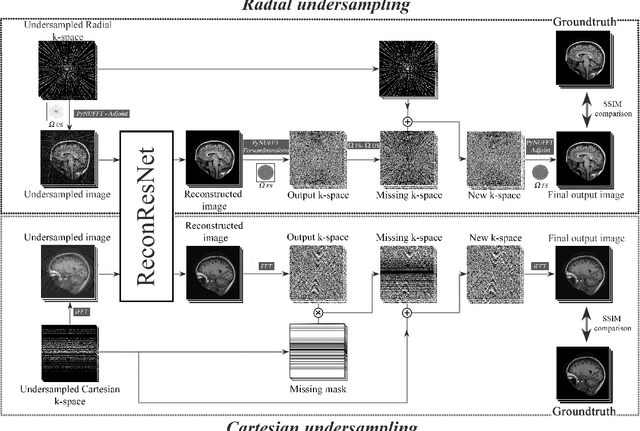
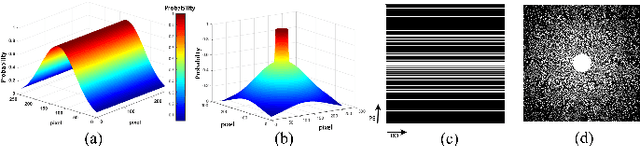
MRI is an inherently slow process, which leads to long scan time for high-resolution imaging. The speed of acquisition can be increased by ignoring parts of the data (undersampling). Consequently, this leads to the degradation of image quality, such as loss of resolution or introduction of image artefacts. This work aims to reconstruct highly undersampled Cartesian or radial MR acquisitions, with better resolution and with less to no artefact compared to conventional techniques like compressed sensing. In recent times, deep learning has emerged as a very important area of research and has shown immense potential in solving inverse problems, e.g. MR image reconstruction. In this paper, a deep learning based MR image reconstruction framework is proposed, which includes a modified regularised version of ResNet as the network backbone to remove artefacts from the undersampled image, followed by data consistency steps that fusions the network output with the data already available from undersampled k-space in order to further improve reconstruction quality. The performance of this framework for various undersampling patterns has also been tested, and it has been observed that the framework is robust to deal with various sampling patterns, even when mixed together while training, and results in very high quality reconstruction, in terms of high SSIM (highest being 0.990$\pm$0.006 for acceleration factor of 3.5), while being compared with the fully sampled reconstruction. It has been shown that the proposed framework can successfully reconstruct even for an acceleration factor of 20 for Cartesian (0.968$\pm$0.005) and 17 for radially (0.962$\pm$0.012) sampled data. Furthermore, it has been shown that the framework preserves brain pathology during reconstruction while being trained on healthy subjects.
MultiRes-NetVLAD: Augmenting Place Recognition Training with Low-Resolution Imagery
Feb 18, 2022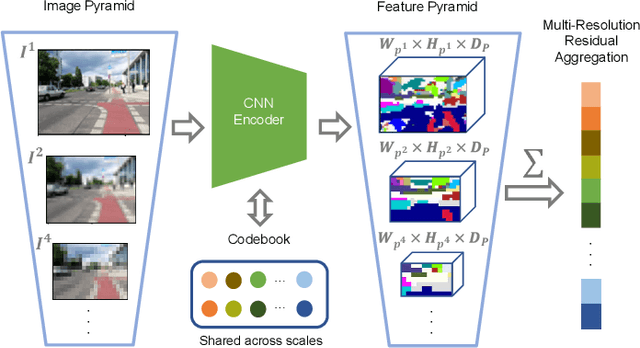
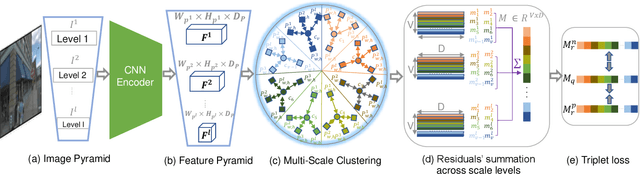
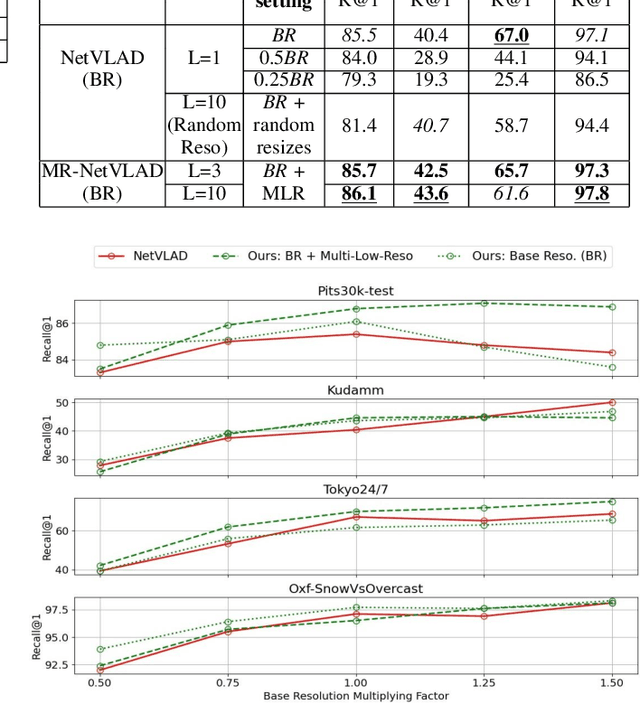

Visual Place Recognition (VPR) is a crucial component of 6-DoF localization, visual SLAM and structure-from-motion pipelines, tasked to generate an initial list of place match hypotheses by matching global place descriptors. However, commonly-used CNN-based methods either process multiple image resolutions after training or use a single resolution and limit multi-scale feature extraction to the last convolutional layer during training. In this paper, we augment NetVLAD representation learning with low-resolution image pyramid encoding which leads to richer place representations. The resultant multi-resolution feature pyramid can be conveniently aggregated through VLAD into a single compact representation, avoiding the need for concatenation or summation of multiple patches in recent multi-scale approaches. Furthermore, we show that the underlying learnt feature tensor can be combined with existing multi-scale approaches to improve their baseline performance. Evaluation on 15 viewpoint-varying and viewpoint-consistent benchmarking datasets confirm that the proposed MultiRes-NetVLAD leads to state-of-the-art Recall@N performance for global descriptor based retrieval, compared against 11 existing techniques. Source code is publicly available at https://github.com/Ahmedest61/MultiRes-NetVLAD.
* 12 pages, 6 Figures, Accepted for publication in IEEE RA-L 2022 and ICRA 2022, includes supplementary material
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
Jul 06, 2021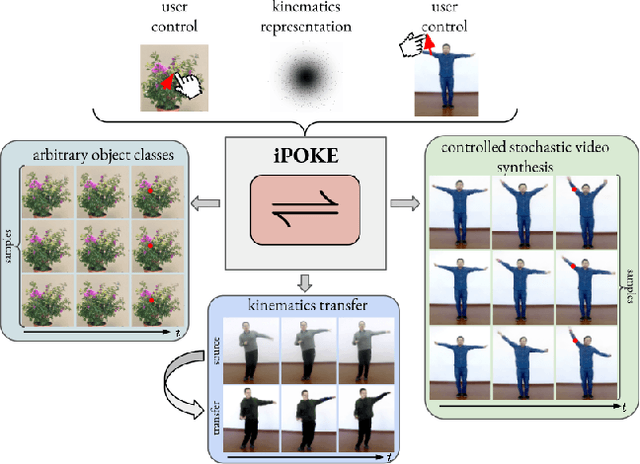
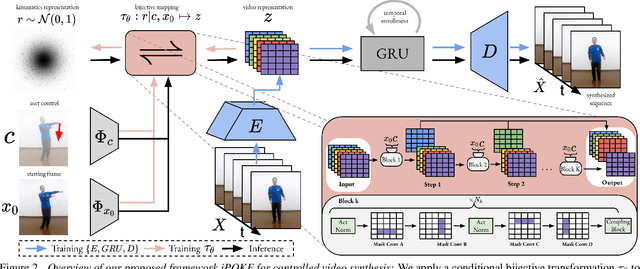

How would a static scene react to a local poke? What are the effects on other parts of an object if you could locally push it? There will be distinctive movement, despite evident variations caused by the stochastic nature of our world. These outcomes are governed by the characteristic kinematics of objects that dictate their overall motion caused by a local interaction. Conversely, the movement of an object provides crucial information about its underlying distinctive kinematics and the interdependencies between its parts. This two-way relation motivates learning a bijective mapping between object kinematics and plausible future image sequences. Therefore, we propose iPOKE - invertible Prediction of Object Kinematics - that, conditioned on an initial frame and a local poke, allows to sample object kinematics and establishes a one-to-one correspondence to the corresponding plausible videos, thereby providing a controlled stochastic video synthesis. In contrast to previous works, we do not generate arbitrary realistic videos, but provide efficient control of movements, while still capturing the stochastic nature of our environment and the diversity of plausible outcomes it entails. Moreover, our approach can transfer kinematics onto novel object instances and is not confined to particular object classes. Project page is available at https://bit.ly/3dJN4Lf
LDP-Net: An Unsupervised Pansharpening Network Based on Learnable Degradation Processes
Nov 24, 2021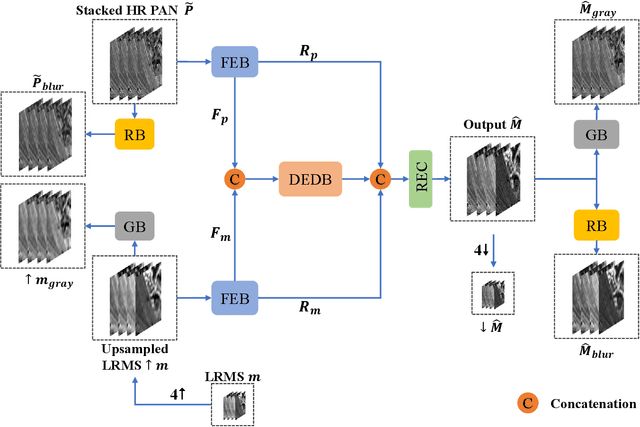
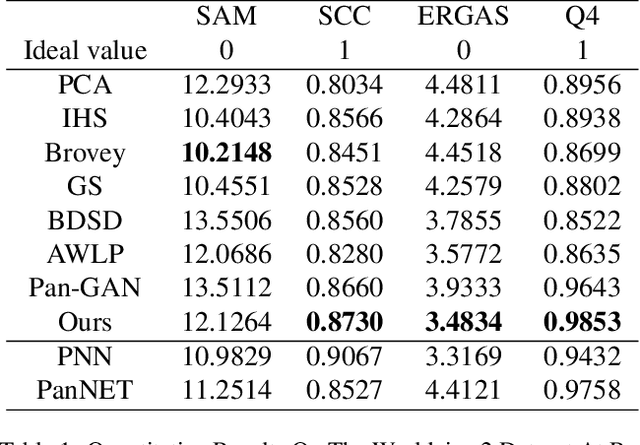
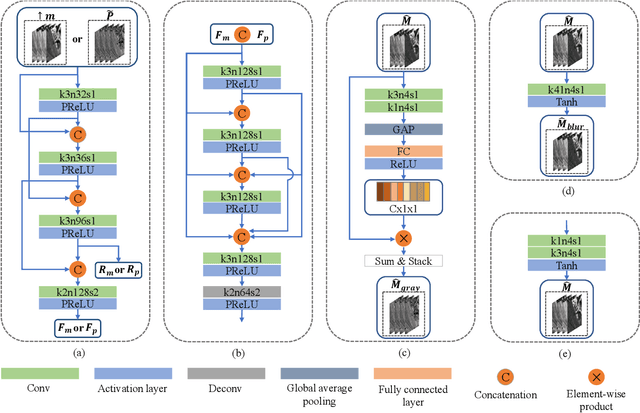
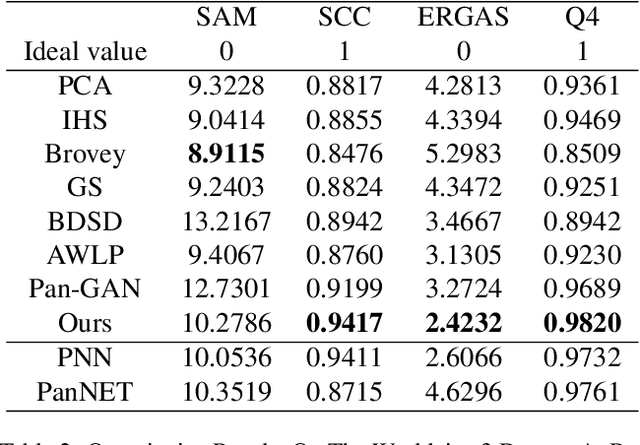
Pansharpening in remote sensing image aims at acquiring a high-resolution multispectral (HRMS) image directly by fusing a low-resolution multispectral (LRMS) image with a panchromatic (PAN) image. The main concern is how to effectively combine the rich spectral information of LRMS image with the abundant spatial information of PAN image. Recently, many methods based on deep learning have been proposed for the pansharpening task. However, these methods usually has two main drawbacks: 1) requiring HRMS for supervised learning; and 2) simply ignoring the latent relation between the MS and PAN image and fusing them directly. To solve these problems, we propose a novel unsupervised network based on learnable degradation processes, dubbed as LDP-Net. A reblurring block and a graying block are designed to learn the corresponding degradation processes, respectively. In addition, a novel hybrid loss function is proposed to constrain both spatial and spectral consistency between the pansharpened image and the PAN and LRMS images at different resolutions. Experiments on Worldview2 and Worldview3 images demonstrate that our proposed LDP-Net can fuse PAN and LRMS images effectively without the help of HRMS samples, achieving promising performance in terms of both qualitative visual effects and quantitative metrics.
Ghost projection. II. Beam shaping using realistic spatially-random masks
Feb 18, 2022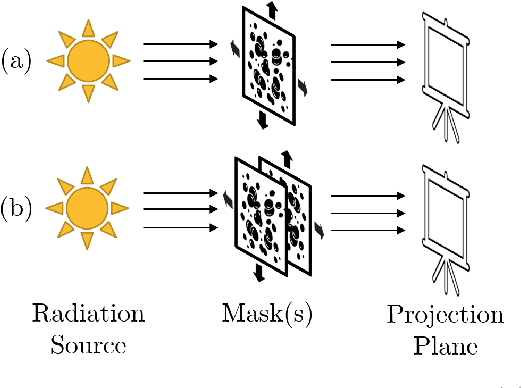
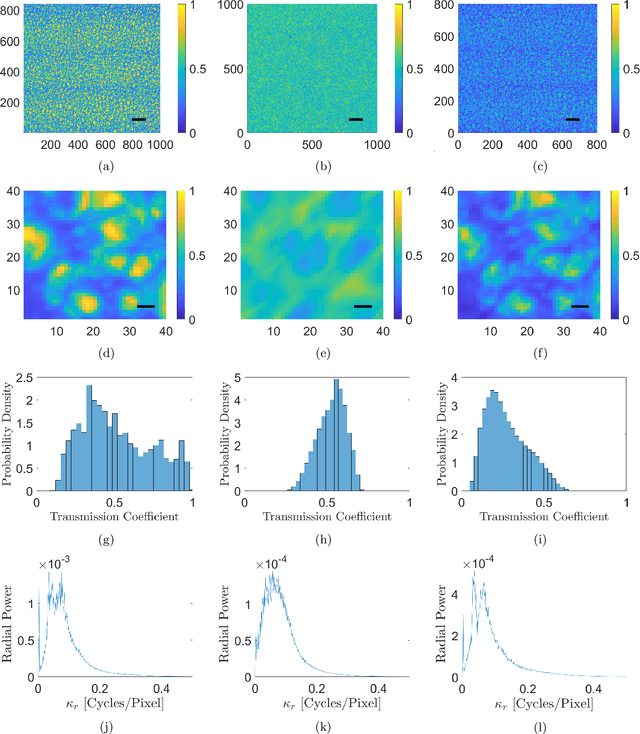
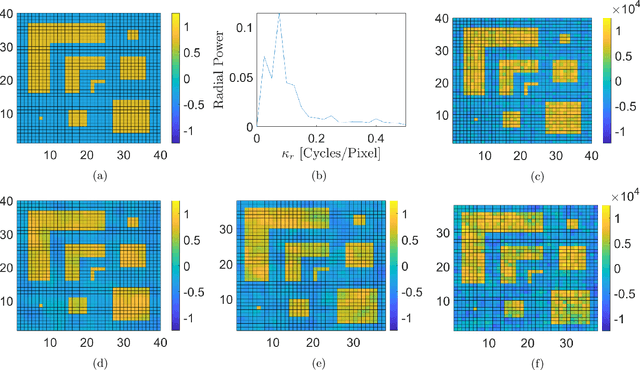
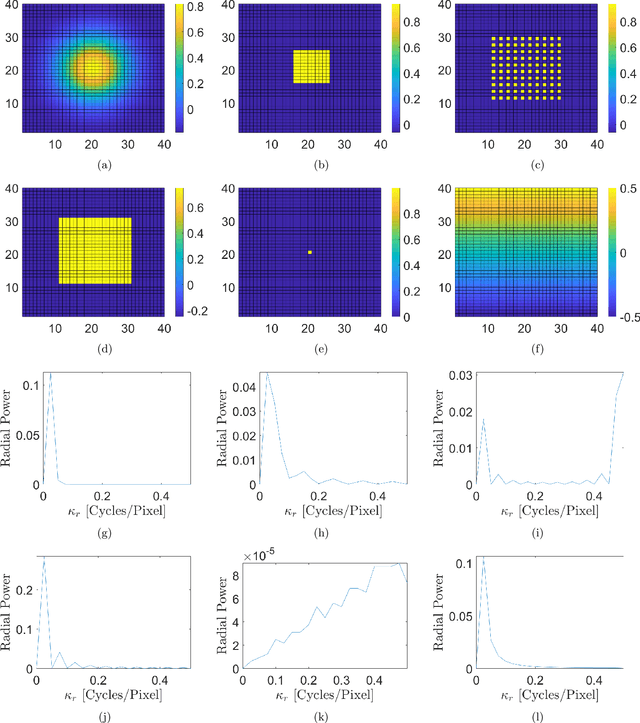
The spatial light modulator and optical data projector both rely on precisely configurable optical elements to shape a light beam. Here we explore an image-projection approach which does not require a configurable beam-shaping element. We term this approach {\em ghost projection} on account of its conceptual relation to computational ghost imaging. Instead of a configurable beam shaping element, the method transversely displaces a single illuminated mask, such as a spatially-random screen, to create specified distributions of radiant exposure. The method has potential applicability to image projection employing a variety of radiation and matter wave fields, such as hard x rays, neutrons, muons, atomic beams and molecular beams. Building on our previous theoretical and computational studies, we here seek to understand the effects, sensitivity, and tolerance of some key experimental limitations of the method. Focusing on the case of hard x rays, we employ experimentally acquired masks to numerically study the deleterious effects of photon shot noise, inaccuracies in random-mask exposure time, and inaccuracies in mask positioning, as well as adapting to spatially non-uniform illumination. Understanding the influence of these factors will assist in optimizing experimental design and work towards achieving ghost projection in practice.
Microdosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022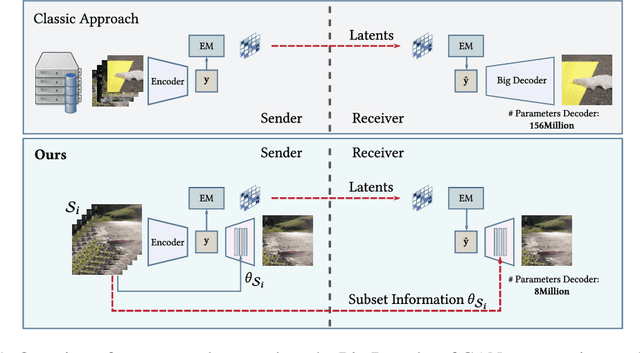
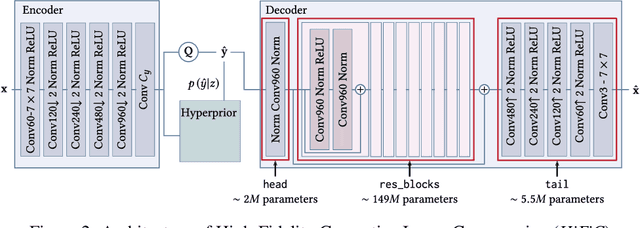
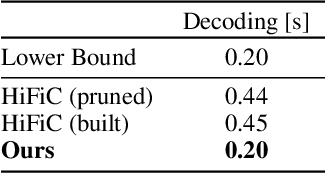

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Artificial Perceptual Learning: Image Categorization with Weak Supervision
Jun 02, 2021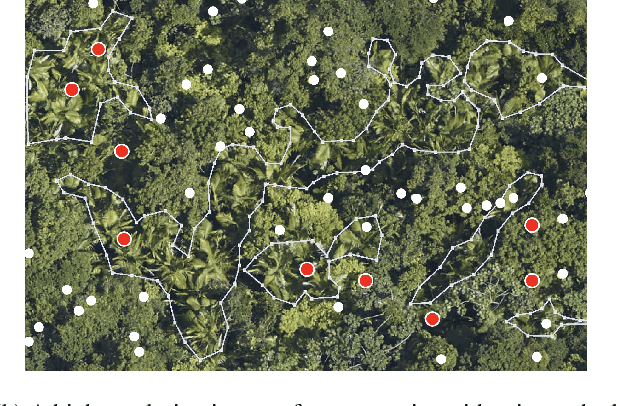
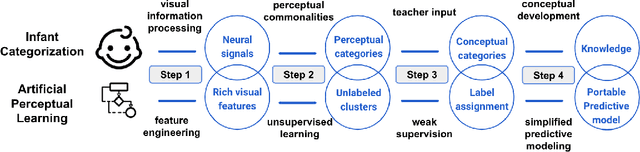

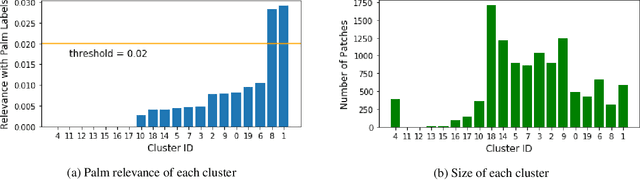
Machine learning has achieved much success on supervised learning tasks with large sets of well-annotated training samples. However, in many practical situations, such strong and high-quality supervision provided by training data is unavailable due to the expensive and labor-intensive labeling process. Automatically identifying and recognizing object categories in a large volume of unlabeled images with weak supervision remains an important, yet unsolved challenge in computer vision. In this paper, we propose a novel machine learning framework, artificial perceptual learning (APL), to tackle the problem of weakly supervised image categorization. The proposed APL framework is constructed using state-of-the-art machine learning algorithms as building blocks to mimic the cognitive development process known as infant categorization. We develop and illustrate the proposed framework by implementing a wide-field fine-grain ecological survey of tree species over an 8,000-hectare area of the El Yunque rainforest in Puerto Rico. It is based on unlabeled high-resolution aerial images of the tree canopy. Misplaced ground-based labels were available for less than 1% of these images, which serve as the only weak supervision for this learning framework. We validate the proposed framework using a small set of images with high quality human annotations and show that the proposed framework attains human-level cognitive economy.
Partially Does It: Towards Scene-Level FG-SBIR with Partial Input
Mar 28, 2022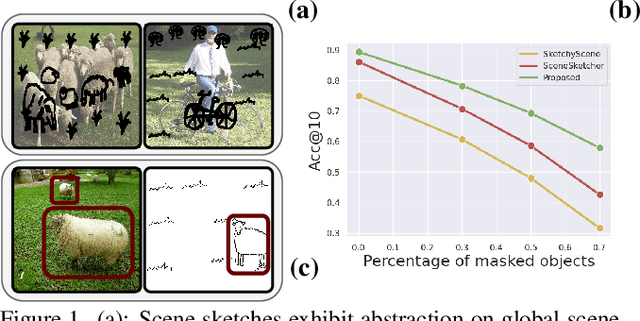
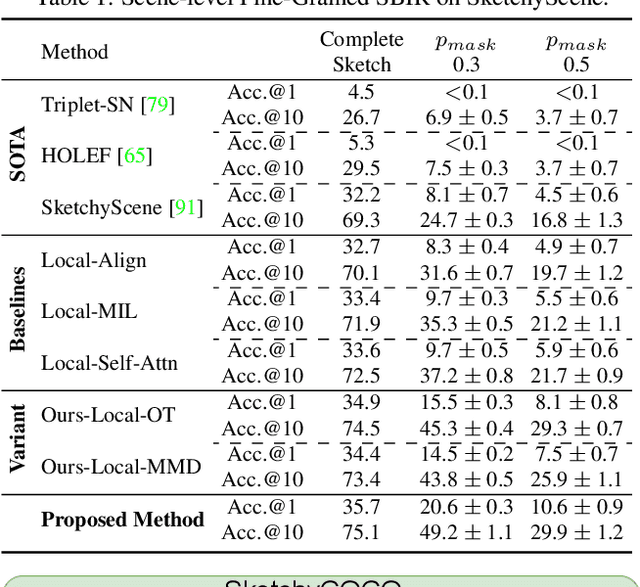
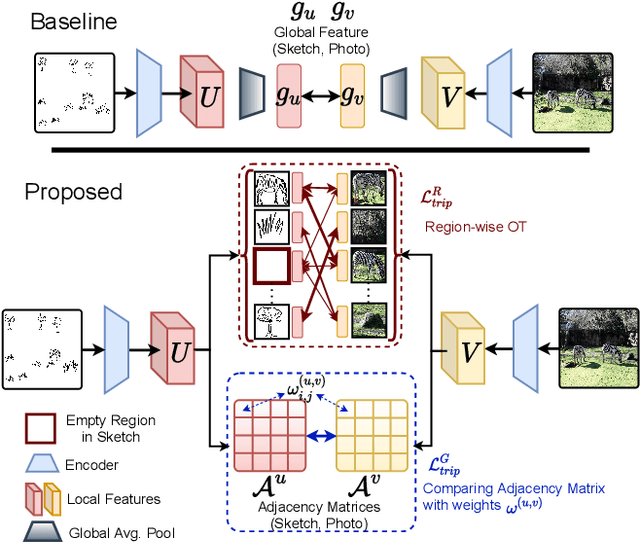
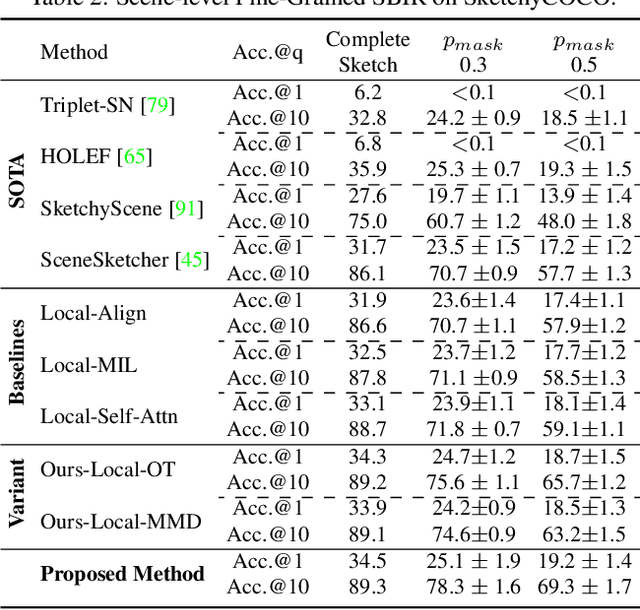
We scrutinise an important observation plaguing scene-level sketch research -- that a significant portion of scene sketches are "partial". A quick pilot study reveals: (i) a scene sketch does not necessarily contain all objects in the corresponding photo, due to the subjective holistic interpretation of scenes, (ii) there exists significant empty (white) regions as a result of object-level abstraction, and as a result, (iii) existing scene-level fine-grained sketch-based image retrieval methods collapse as scene sketches become more partial. To solve this "partial" problem, we advocate for a simple set-based approach using optimal transport (OT) to model cross-modal region associativity in a partially-aware fashion. Importantly, we improve upon OT to further account for holistic partialness by comparing intra-modal adjacency matrices. Our proposed method is not only robust to partial scene-sketches but also yields state-of-the-art performance on existing datasets.