 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Dual-Graph Regularized Moving Object Detection
Apr 25, 2022



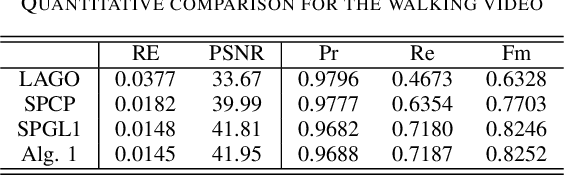
Moving object detection and its associated background-foreground separation have been widely used in a lot of applications, including computer vision, transportation and surveillance. Due to the presence of the static background, a video can be naturally decomposed into a low-rank background and a sparse foreground. Many regularization techniques, such as matrix nuclear norm, have been imposed on the background. In the meanwhile, sparsity or smoothness based regularizations, such as total variation and $\ell_1$, can be imposed on the foreground. Moreover, graph Laplacians are further imposed to capture the complicated geometry of background images. Recently, weighted regularization techniques including the weighted nuclear norm regularization have been proposed in the image processing community to promote adaptive sparsity while achieving efficient performance. In this paper, we propose a robust dual-graph regularized moving object detection model based on the weighted nuclear norm regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on body movement data sets have demonstrated the effectiveness of this method in separating moving objects from background, and the great potential in robotic applications.
Stepwise Feature Fusion: Local Guides Global
Mar 07, 2022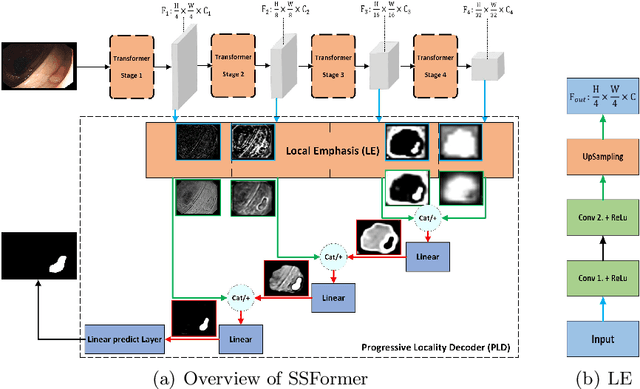
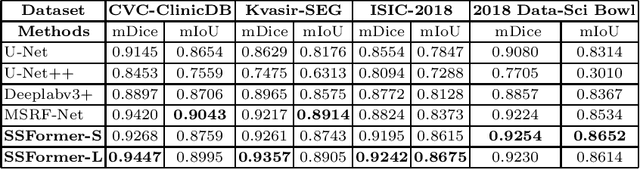
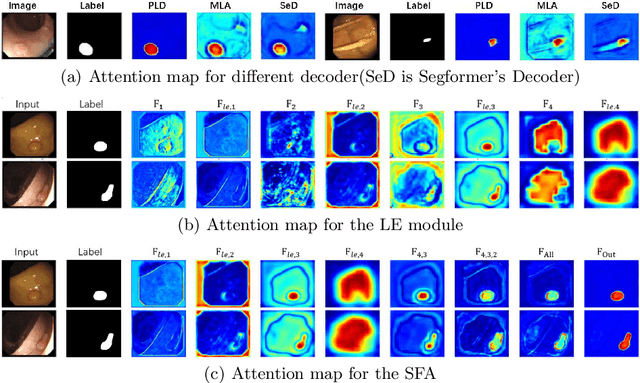
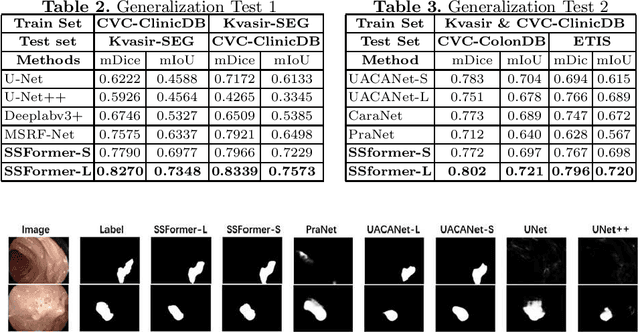
Colonoscopy, currently the most efficient and recognized colon polyp detection technology, is necessary for early screening and prevention of colorectal cancer. However, due to the varying size and complex morphological features of colonic polyps as well as the indistinct boundary between polyps and mucosa, accurate segmentation of polyps is still challenging. Deep learning has become popular for accurate polyp segmentation tasks with excellent results. However, due to the structure of polyps image and the varying shapes of polyps, it easy for existing deep learning models to overfitting the current dataset. As a result, the model may not process unseen colonoscopy data. To address this, we propose a new State-Of-The-Art model for medical image segmentation, the SSFormer, which uses a pyramid Transformer encoder to improve the generalization ability of models. Specifically, our proposed Progressive Locality Decoder can be adapted to the pyramid Transformer backbone to emphasize local features and restrict attention dispersion. The SSFormer achieves statet-of-the-art performance in both learning and generalization assessment.
LesionPaste: One-Shot Anomaly Detection for Medical Images
Mar 12, 2022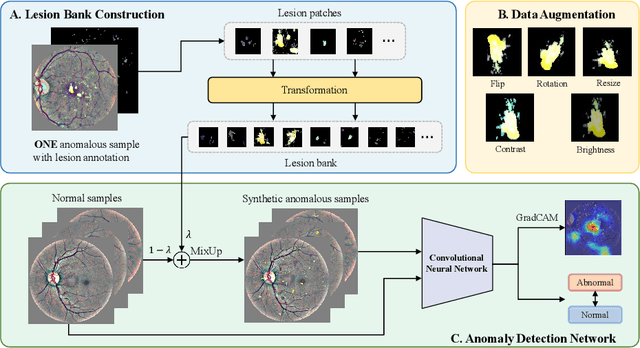
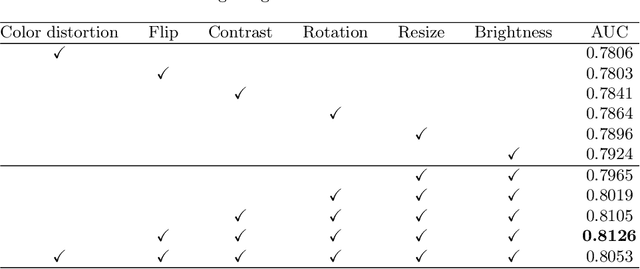
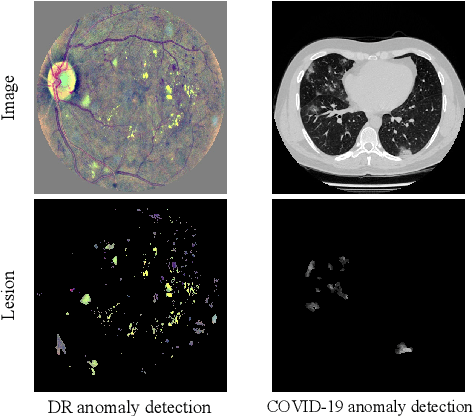
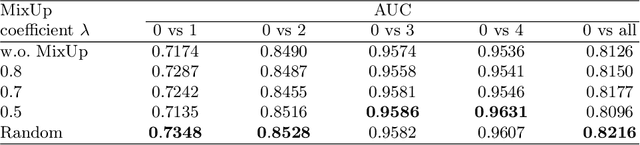
Due to the high cost of manually annotating medical images, especially for large-scale datasets, anomaly detection has been explored through training models with only normal data. Lacking prior knowledge of true anomalies is the main reason for the limited application of previous anomaly detection methods, especially in the medical image analysis realm. In this work, we propose a one-shot anomaly detection framework, namely LesionPaste, that utilizes true anomalies from a single annotated sample and synthesizes artificial anomalous samples for anomaly detection. First, a lesion bank is constructed by applying augmentation to randomly selected lesion patches. Then, MixUp is adopted to paste patches from the lesion bank at random positions in normal images to synthesize anomalous samples for training. Finally, a classification network is trained using the synthetic abnormal samples and the true normal data. Extensive experiments are conducted on two publicly-available medical image datasets with different types of abnormalities. On both datasets, our proposed LesionPaste largely outperforms several state-of-the-art unsupervised and semi-supervised anomaly detection methods, and is on a par with the fully-supervised counterpart. To note, LesionPaste is even better than the fully-supervised method in detecting early-stage diabetic retinopathy.
Differentiable Electron Microscopy Simulation: Methods and Applications for Visualization
May 08, 2022
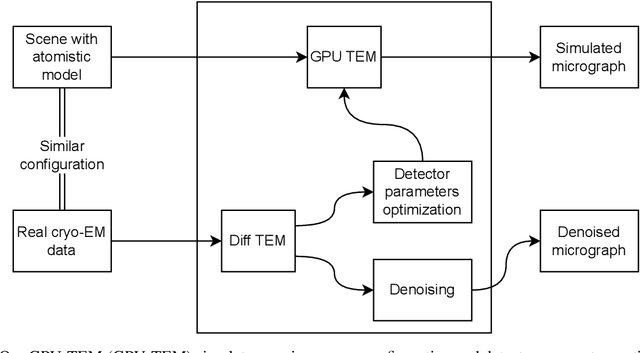
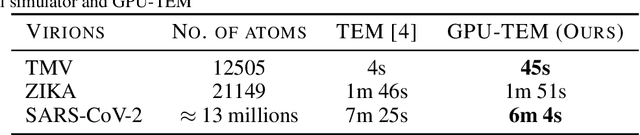
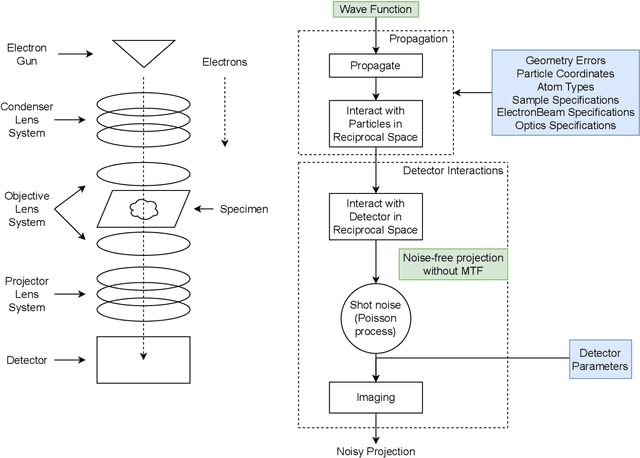
We propose a new microscopy simulation system that can depict atomistic models in a micrograph visual style, similar to results of physical electron microscopy imaging. This system is scalable, able to represent simulation of electron microscopy of tens of viral particles and synthesizes the image faster than previous methods. On top of that, the simulator is differentiable, both its deterministic as well as stochastic stages that form signal and noise representations in the micrograph. This notable property has the capability for solving inverse problems by means of optimization and thus allows for generation of microscopy simulations using the parameter settings estimated from real data. We demonstrate this learning capability through two applications: (1) estimating the parameters of the modulation transfer function defining the detector properties of the simulated and real micrographs, and (2) denoising the real data based on parameters trained from the simulated examples. While current simulators do not support any parameter estimation due to their forward design, we show that the results obtained using estimated parameters are very similar to the results of real micrographs. Additionally, we evaluate the denoising capabilities of our approach and show that the results showed an improvement over state-of-the-art methods. Denoised micrographs exhibit less noise in the tilt-series tomography reconstructions, ultimately reducing the visual dominance of noise in direct volume rendering of microscopy tomograms.
Investigating the Vision Transformer Model for Image Retrieval Tasks
Jan 11, 2021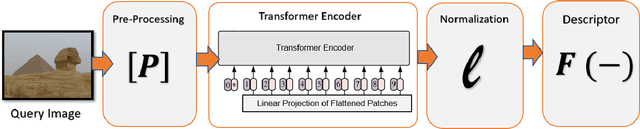
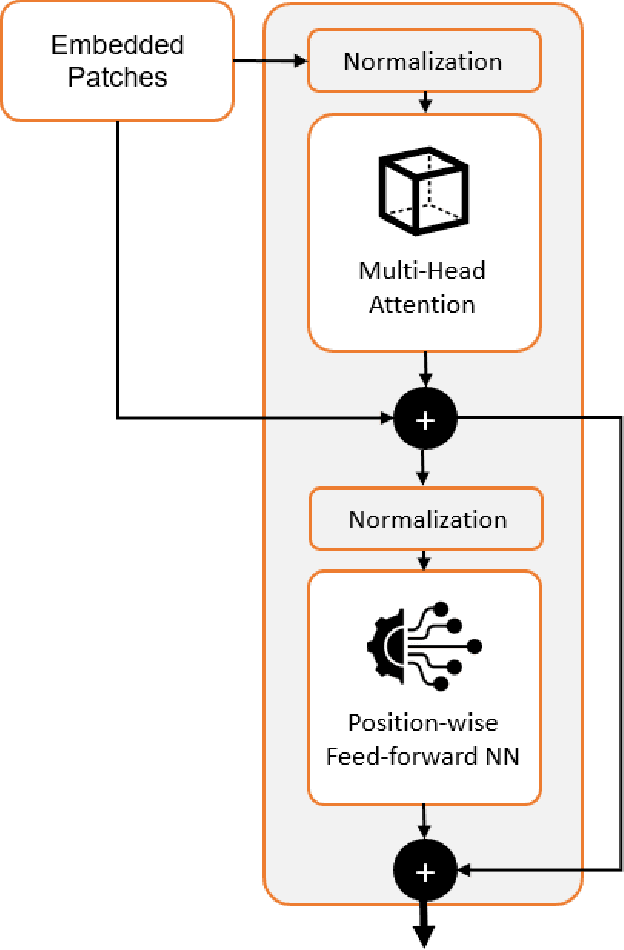
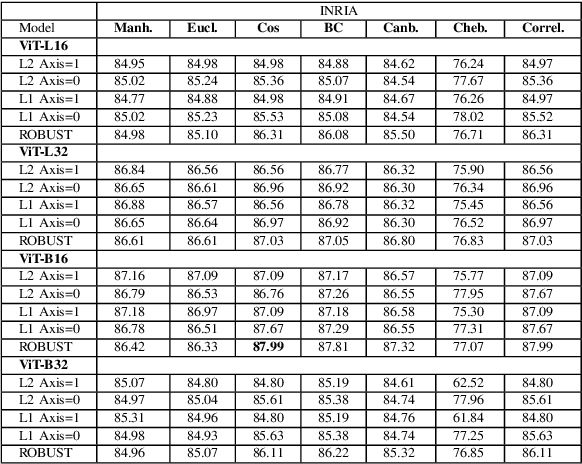
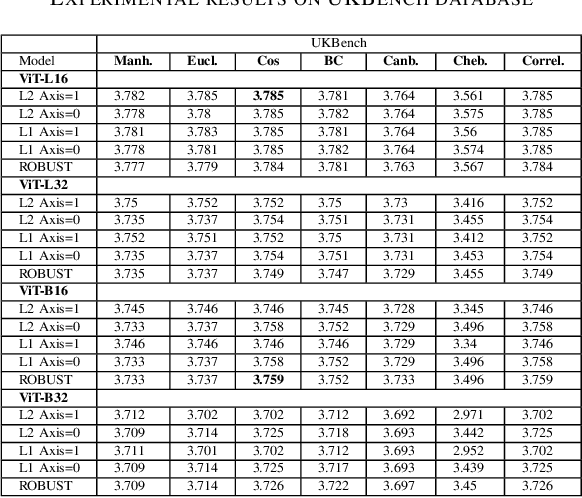
This paper introduces a plug-and-play descriptor that can be effectively adopted for image retrieval tasks without prior initialization or preparation. The description method utilizes the recently proposed Vision Transformer network while it does not require any training data to adjust parameters. In image retrieval tasks, the use of Handcrafted global and local descriptors has been very successfully replaced, over the last years, by the Convolutional Neural Networks (CNN)-based methods. However, the experimental evaluation conducted in this paper on several benchmarking datasets against 36 state-of-the-art descriptors from the literature demonstrates that a neural network that contains no convolutional layer, such as Vision Transformer, can shape a global descriptor and achieve competitive results. As fine-tuning is not required, the presented methodology's low complexity encourages adoption of the architecture as an image retrieval baseline model, replacing the traditional and well adopted CNN-based approaches and inaugurating a new era in image retrieval approaches.
Simplicial Attention Networks
Apr 20, 2022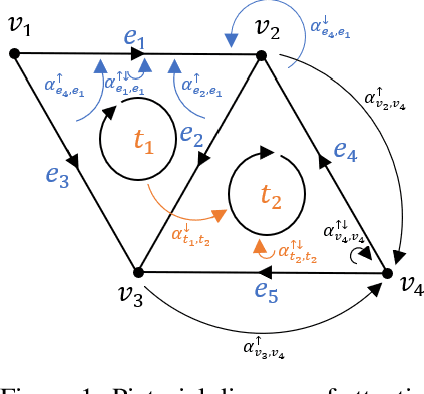
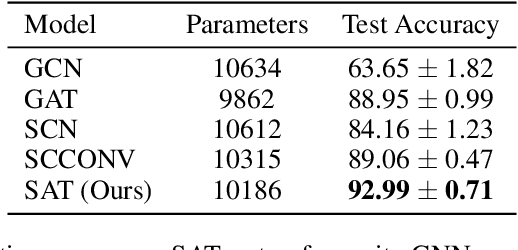

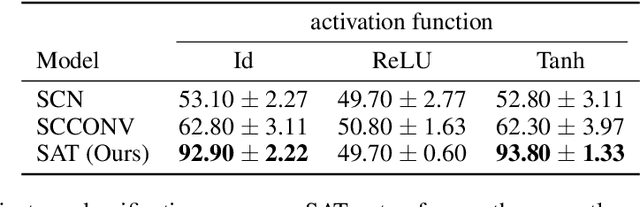
Graph representation learning methods have mostly been limited to the modelling of node-wise interactions. Recently, there has been an increased interest in understanding how higher-order structures can be utilised to further enhance the learning abilities of graph neural networks (GNNs) in combinatorial spaces. Simplicial Neural Networks (SNNs) naturally model these interactions by performing message passing on simplicial complexes, higher-dimensional generalisations of graphs. Nonetheless, the computations performed by most existent SNNs are strictly tied to the combinatorial structure of the complex. Leveraging the success of attention mechanisms in structured domains, we propose Simplicial Attention Networks (SAT), a new type of simplicial network that dynamically weighs the interactions between neighbouring simplicies and can readily adapt to novel structures. Additionally, we propose a signed attention mechanism that makes SAT orientation equivariant, a desirable property for models operating on (co)chain complexes. We demonstrate that SAT outperforms existent convolutional SNNs and GNNs in two image and trajectory classification tasks.
Generative Convolution Layer for Image Generation
Nov 30, 2021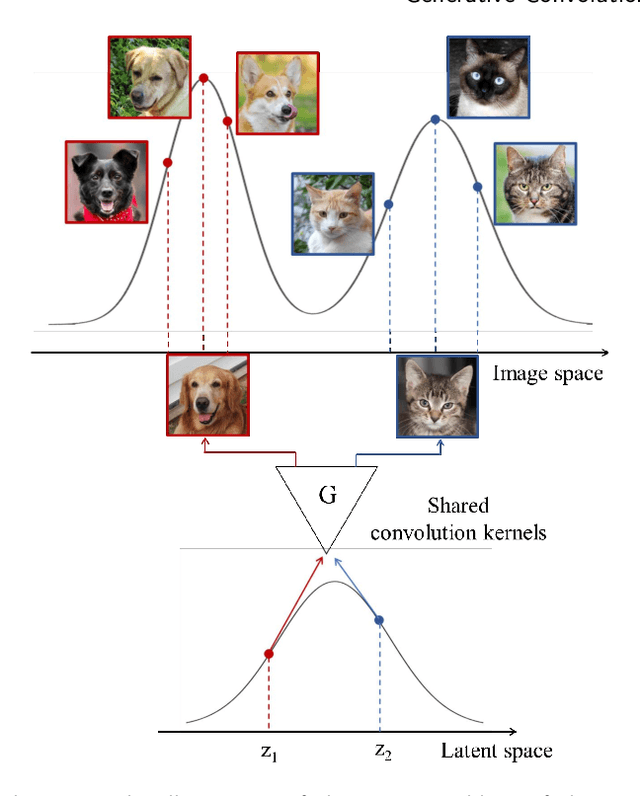
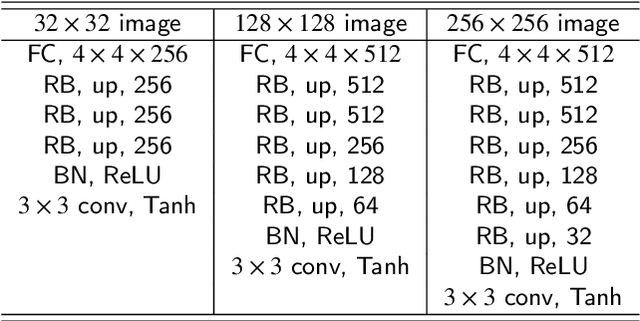
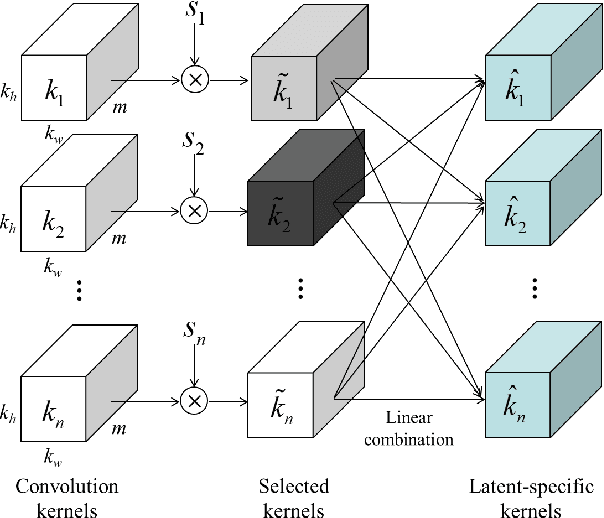
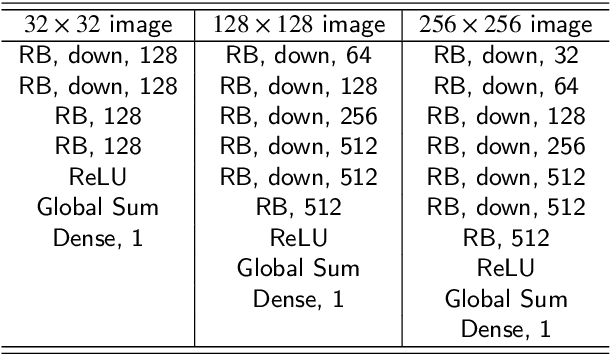
This paper introduces a novel convolution method, called generative convolution (GConv), which is simple yet effective for improving the generative adversarial network (GAN) performance. Unlike the standard convolution, GConv first selects useful kernels compatible with the given latent vector, and then linearly combines the selected kernels to make latent-specific kernels. Using the latent-specific kernels, the proposed method produces the latent-specific features which encourage the generator to produce high-quality images. This approach is simple but surprisingly effective. First, the GAN performance is significantly improved with a little additional hardware cost. Second, GConv can be employed to the existing state-of-the-art generators without modifying the network architecture. To reveal the superiority of GConv, this paper provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN-Church, CelebA, and tiny-ImageNet. Quantitative evaluations prove that GConv significantly boosts the performances of the unconditional and conditional GANs in terms of Inception score (IS) and Frechet inception distance (FID). For example, the proposed method improves both FID and IS scores on the tiny-ImageNet dataset from 35.13 to 29.76 and 20.23 to 22.64, respectively.
What to look at and where: Semantic and Spatial Refined Transformer for detecting human-object interactions
Apr 02, 2022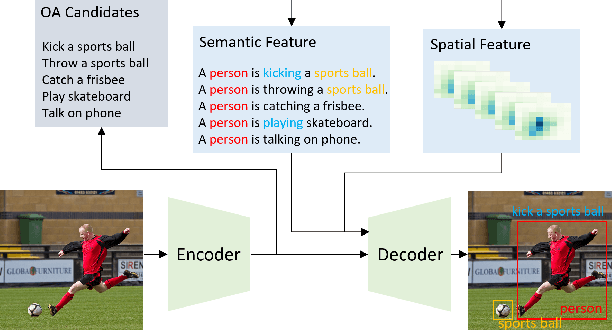
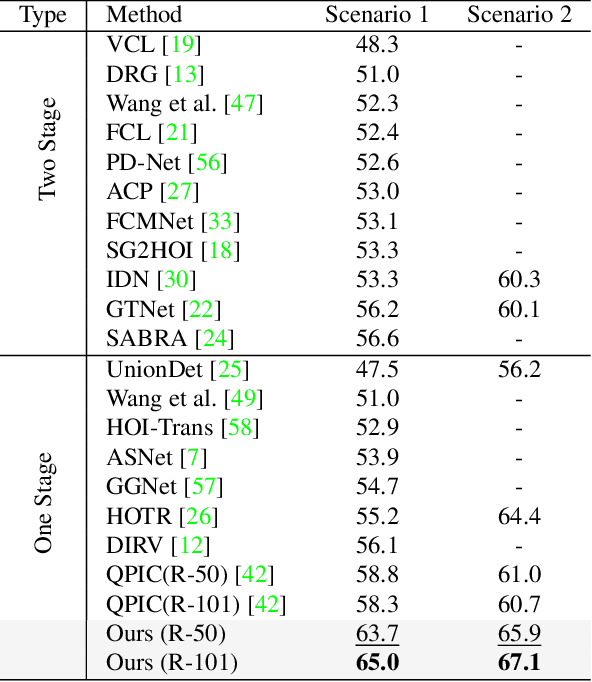
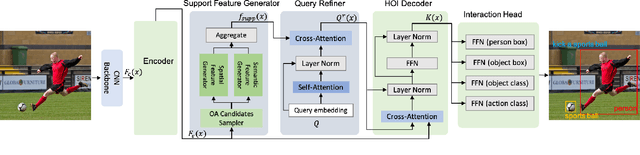
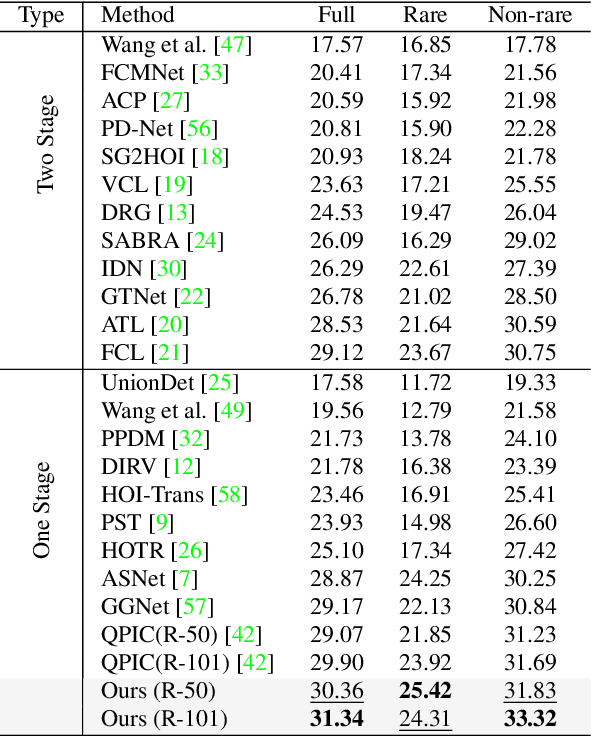
We propose a novel one-stage Transformer-based semantic and spatial refined transformer (SSRT) to solve the Human-Object Interaction detection task, which requires to localize humans and objects, and predicts their interactions. Differently from previous Transformer-based HOI approaches, which mostly focus at improving the design of the decoder outputs for the final detection, SSRT introduces two new modules to help select the most relevant object-action pairs within an image and refine the queries' representation using rich semantic and spatial features. These enhancements lead to state-of-the-art results on the two most popular HOI benchmarks: V-COCO and HICO-DET.
Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset
Apr 25, 2022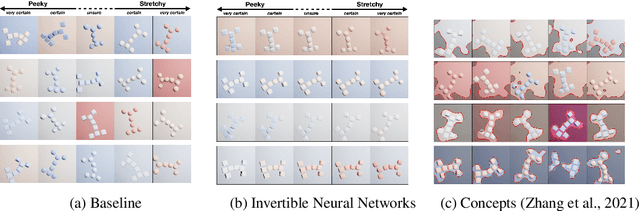
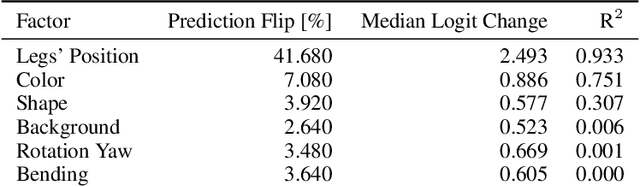


A variety of methods exist to explain image classification models. However, whether they provide any benefit to users over simply comparing various inputs and the model's respective predictions remains unclear. We conducted a user study (N=240) to test how such a baseline explanation technique performs against concept-based and counterfactual explanations. To this end, we contribute a synthetic dataset generator capable of biasing individual attributes and quantifying their relevance to the model. In a study, we assess if participants can identify the relevant set of attributes compared to the ground-truth. Our results show that the baseline outperformed concept-based explanations. Counterfactual explanations from an invertible neural network performed similarly as the baseline. Still, they allowed users to identify some attributes more accurately. Our results highlight the importance of measuring how well users can reason about biases of a model, rather than solely relying on technical evaluations or proxy tasks. We open-source our study and dataset so it can serve as a blue-print for future studies. For code see, https://github.com/berleon/do_users_benefit_from_interpretable_vision
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022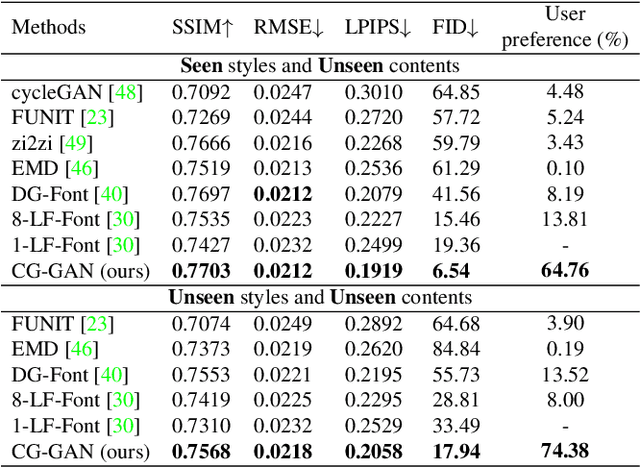
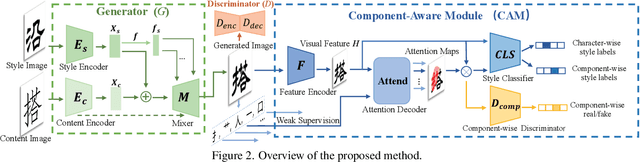


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.