 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoV: Chain-of-View Prompting for Spatial Reasoning
Jan 08, 2026Embodied question answering (EQA) in 3D environments often requires collecting context that is distributed across multiple viewpoints and partially occluded. However, most recent vision--language models (VLMs) are constrained to a fixed and finite set of input views, which limits their ability to acquire question-relevant context at inference time and hinders complex spatial reasoning. We propose Chain-of-View (CoV) prompting, a training-free, test-time reasoning framework that transforms a VLM into an active viewpoint reasoner through a coarse-to-fine exploration process. CoV first employs a View Selection agent to filter redundant frames and identify question-aligned anchor views. It then performs fine-grained view adjustment by interleaving iterative reasoning with discrete camera actions, obtaining new observations from the underlying 3D scene representation until sufficient context is gathered or a step budget is reached. We evaluate CoV on OpenEQA across four mainstream VLMs and obtain an average +11.56\% improvement in LLM-Match, with a maximum gain of +13.62\% on Qwen3-VL-Flash. CoV further exhibits test-time scaling: increasing the minimum action budget yields an additional +2.51\% average improvement, peaking at +3.73\% on Gemini-2.5-Flash. On ScanQA and SQA3D, CoV delivers strong performance (e.g., 116 CIDEr / 31.9 EM@1 on ScanQA and 51.1 EM@1 on SQA3D). Overall, these results suggest that question-aligned view selection coupled with open-view search is an effective, model-agnostic strategy for improving spatial reasoning in 3D EQA without additional training.
Robust Dual-Graph Regularized Moving Object Detection
Apr 25, 2022


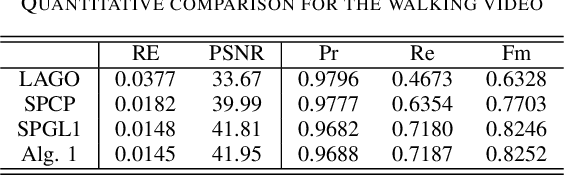
Moving object detection and its associated background-foreground separation have been widely used in a lot of applications, including computer vision, transportation and surveillance. Due to the presence of the static background, a video can be naturally decomposed into a low-rank background and a sparse foreground. Many regularization techniques, such as matrix nuclear norm, have been imposed on the background. In the meanwhile, sparsity or smoothness based regularizations, such as total variation and $\ell_1$, can be imposed on the foreground. Moreover, graph Laplacians are further imposed to capture the complicated geometry of background images. Recently, weighted regularization techniques including the weighted nuclear norm regularization have been proposed in the image processing community to promote adaptive sparsity while achieving efficient performance. In this paper, we propose a robust dual-graph regularized moving object detection model based on the weighted nuclear norm regularization, which is solved by the alternating direction method of multipliers (ADMM). Numerical experiments on body movement data sets have demonstrated the effectiveness of this method in separating moving objects from background, and the great potential in robotic applications.