 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots that learn to evaluate models of collective behavior
Apr 08, 2026Understanding and modeling animal behavior is essential for studying collective motion, decision-making, and bio-inspired robotics. Yet, evaluating the accuracy of behavioral models still often relies on offline comparisons to static trajectory statistics. Here we introduce a reinforcement-learning-based framework that uses a biomimetic robotic fish (RoboFish) to evaluate computational models of live fish behavior through closed-loop interaction. We trained policies in simulation using four distinct fish models-a simple constant-follow baseline, two rule-based models, and a biologically grounded convolutional neural network model-and transferred these policies to the real RoboFish setup, where they interacted with live fish. Policies were trained to guide a simulated fish to goal locations, enabling us to quantify how the response of real fish differs from the simulated fish's response. We evaluate the fish models by quantifying the sim-to-real gaps, defined as the Wasserstein distance between simulated and real distributions of behavioral metrics such as goal-reaching performance, inter-individual distances, wall interactions, and alignment. The neural network-based fish model exhibited the smallest gap across goal-reaching performance and most other metrics, indicating higher behavioral fidelity than conventional rule-based models under this benchmark. More importantly, this separation shows that the proposed evaluation can quantitatively distinguish candidate models under matched closed-loop conditions. Our work demonstrates how learning-based robotic experiments can uncover deficiencies in behavioral models and provides a general framework for evaluating animal behavior models through embodied interaction.
COMB: Common Open Modular robotic platform for Bees
Apr 04, 2026Experimental access to real honeybee colonies requires robotic systems capable of operating within limited spatial constraints, tolerating hive-specific fouling and environmental conditions, and supporting both sensing and localized actuation without frequent hardware redesign. This paper introduces COMB, a compact, open-source, modular mechatronic platform designed for in-hive experiments within standard observation-hive frames. The platform integrates a XY positioning stage, a Movable Access Window (MAW) for sealed tool access through the hive boundary, interchangeable payload modules, and an embedded control architecture that enables repeatable trajectory execution and signal generation. The platform's capabilities are demonstrated through three representative modules: a biomimetic dance-and-signaling payload, a close-range comb scanner, and an electromagnetic wing actuator for localized oscillatory stimulation. This paper details the hardware and software design of COMB, outlines its operational capabilities, and describes the supporting infrastructure for conducting real-world in-hive experiments. The platform is characterized in engineering terms through tracking waggle-trajectory executions, performing multi-image stitching for repeated comb mosaics, and conducting video-based spectral analysis of the wing actuator. These results position COMB as a reusable experimental robotics platform for controlled in-hive sensing and actuation, and as a compact, generalized successor to earlier task-specific honeybee robotic systems.
TABCF: Counterfactual Explanations for Tabular Data Using a Transformer-Based VAE
Oct 14, 2024In the field of Explainable AI (XAI), counterfactual (CF) explanations are one prominent method to interpret a black-box model by suggesting changes to the input that would alter a prediction. In real-world applications, the input is predominantly in tabular form and comprised of mixed data types and complex feature interdependencies. These unique data characteristics are difficult to model, and we empirically show that they lead to bias towards specific feature types when generating CFs. To overcome this issue, we introduce TABCF, a CF explanation method that leverages a transformer-based Variational Autoencoder (VAE) tailored for modeling tabular data. Our approach uses transformers to learn a continuous latent space and a novel Gumbel-Softmax detokenizer that enables precise categorical reconstruction while preserving end-to-end differentiability. Extensive quantitative evaluation on five financial datasets demonstrates that TABCF does not exhibit bias toward specific feature types, and outperforms existing methods in producing effective CFs that align with common CF desiderata.
WeiPer: OOD Detection using Weight Perturbations of Class Projections
May 28, 2024Recent advances in out-of-distribution (OOD) detection on image data show that pre-trained neural network classifiers can separate in-distribution (ID) from OOD data well, leveraging the class-discriminative ability of the model itself. Methods have been proposed that either use logit information directly or that process the model's penultimate layer activations. With "WeiPer", we introduce perturbations of the class projections in the final fully connected layer which creates a richer representation of the input. We show that this simple trick can improve the OOD detection performance of a variety of methods and additionally propose a distance-based method that leverages the properties of the augmented WeiPer space. We achieve state-of-the-art OOD detection results across multiple benchmarks of the OpenOOD framework, especially pronounced in difficult settings in which OOD samples are positioned close to the training set distribution. We support our findings with theoretical motivations and empirical observations, and run extensive ablations to provide insights into why WeiPer works.
Check News in One Click: NLP-Empowered Pro-Kremlin Propaganda Detection
Jan 28, 2024



Many European citizens become targets of the Kremlin propaganda campaigns, aiming to minimise public support for Ukraine, foster a climate of mistrust and disunity, and shape elections (Meister, 2022). To address this challenge, we developed ''Check News in 1 Click'', the first NLP-empowered pro-Kremlin propaganda detection application available in 7 languages, which provides the lay user with feedback on their news, and explains manipulative linguistic features and keywords. We conducted a user study, analysed user entries and models' behaviour paired with questionnaire answers, and investigated the advantages and disadvantages of the proposed interpretative solution.
PapagAI:Automated Feedback for Reflective Essays
Jul 10, 2023



Written reflective practice is a regular exercise pre-service teachers perform during their higher education. Usually, their lecturers are expected to provide individual feedback, which can be a challenging task to perform on a regular basis. In this paper, we present the first open-source automated feedback tool based on didactic theory and implemented as a hybrid AI system. We describe the components and discuss the advantages and disadvantages of our system compared to the state-of-art generative large language models. The main objective of our work is to enable better learning outcomes for students and to complement the teaching activities of lecturers.
Automated multilingual detection of Pro-Kremlin propaganda in newspapers and Telegram posts
Jan 25, 2023



The full-scale conflict between the Russian Federation and Ukraine generated an unprecedented amount of news articles and social media data reflecting opposing ideologies and narratives. These polarized campaigns have led to mutual accusations of misinformation and fake news, shaping an atmosphere of confusion and mistrust for readers worldwide. This study analyses how the media affected and mirrored public opinion during the first month of the war using news articles and Telegram news channels in Ukrainian, Russian, Romanian and English. We propose and compare two methods of multilingual automated pro-Kremlin propaganda identification, based on Transformers and linguistic features. We analyse the advantages and disadvantages of both methods, their adaptability to new genres and languages, and ethical considerations of their usage for content moderation. With this work, we aim to lay the foundation for further development of moderation tools tailored to the current conflict.
A Rigorous Study Of The Deep Taylor Decomposition
Nov 14, 2022Saliency methods attempt to explain deep neural networks by highlighting the most salient features of a sample. Some widely used methods are based on a theoretical framework called Deep Taylor Decomposition (DTD), which formalizes the recursive application of the Taylor Theorem to the network's layers. However, recent work has found these methods to be independent of the network's deeper layers and appear to respond only to lower-level image structure. Here, we investigate the DTD theory to better understand this perplexing behavior and found that the Deep Taylor Decomposition is equivalent to the basic gradient$\times$input method when the Taylor root points (an important parameter of the algorithm chosen by the user) are locally constant. If the root points are locally input-dependent, then one can justify any explanation. In this case, the theory is under-constrained. In an empirical evaluation, we find that DTD roots do not lie in the same linear regions as the input - contrary to a fundamental assumption of the Taylor theorem. The theoretical foundations of DTD were cited as a source of reliability for the explanations. However, our findings urge caution in making such claims.
DNNR: Differential Nearest Neighbors Regression
May 17, 2022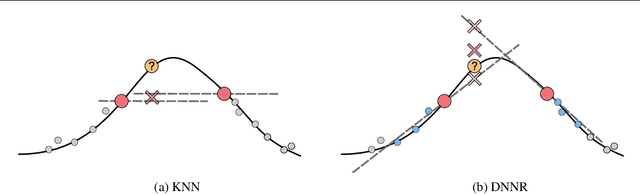



K-nearest neighbors (KNN) is one of the earliest and most established algorithms in machine learning. For regression tasks, KNN averages the targets within a neighborhood which poses a number of challenges: the neighborhood definition is crucial for the predictive performance as neighbors might be selected based on uninformative features, and averaging does not account for how the function changes locally. We propose a novel method called Differential Nearest Neighbors Regression (DNNR) that addresses both issues simultaneously: during training, DNNR estimates local gradients to scale the features; during inference, it performs an n-th order Taylor approximation using estimated gradients. In a large-scale evaluation on over 250 datasets, we find that DNNR performs comparably to state-of-the-art gradient boosting methods and MLPs while maintaining the simplicity and transparency of KNN. This allows us to derive theoretical error bounds and inspect failures. In times that call for transparency of ML models, DNNR provides a good balance between performance and interpretability.
Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset
Apr 25, 2022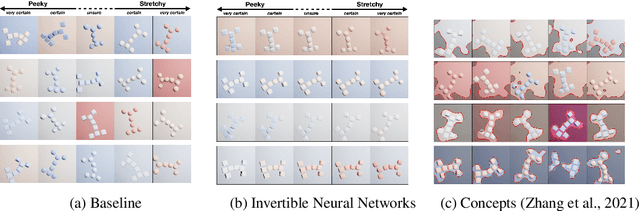


A variety of methods exist to explain image classification models. However, whether they provide any benefit to users over simply comparing various inputs and the model's respective predictions remains unclear. We conducted a user study (N=240) to test how such a baseline explanation technique performs against concept-based and counterfactual explanations. To this end, we contribute a synthetic dataset generator capable of biasing individual attributes and quantifying their relevance to the model. In a study, we assess if participants can identify the relevant set of attributes compared to the ground-truth. Our results show that the baseline outperformed concept-based explanations. Counterfactual explanations from an invertible neural network performed similarly as the baseline. Still, they allowed users to identify some attributes more accurately. Our results highlight the importance of measuring how well users can reason about biases of a model, rather than solely relying on technical evaluations or proxy tasks. We open-source our study and dataset so it can serve as a blue-print for future studies. For code see, https://github.com/berleon/do_users_benefit_from_interpretable_vision