 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangled Latent Energy-Based Style Translation: An Image-Level Structural MRI Harmonization Framework
Feb 10, 2024
Brain magnetic resonance imaging (MRI) has been extensively employed across clinical and research fields, but often exhibits sensitivity to site effects arising from nonbiological variations such as differences in field strength and scanner vendors. Numerous retrospective MRI harmonization techniques have demonstrated encouraging outcomes in reducing the site effects at image level. However, existing methods generally suffer from high computational requirements and limited generalizability, restricting their applicability to unseen MRIs. In this paper, we design a novel disentangled latent energy-based style translation (DLEST) framework for unpaired image-level MRI harmonization, consisting of (1) site-invariant image generation (SIG), (2) site-specific style translation (SST), and (3) site-specific MRI synthesis (SMS). Specifically, the SIG employs a latent autoencoder to encode MRIs into a low-dimensional latent space and reconstruct MRIs from latent codes. The SST utilizes an energy-based model to comprehend the global latent distribution of a target domain and translate source latent codes toward the target domain, while SMS enables MRI synthesis with a target-specific style. By disentangling image generation and style translation in latent space, the DLEST can achieve efficient style translation. Our model was trained on T1-weighted MRIs from a public dataset (with 3,984 subjects across 58 acquisition sites/settings) and validated on an independent dataset (with 9 traveling subjects scanned in 11 sites/settings) in 4 tasks: (1) histogram and clustering comparison, (2) site classification, (3) brain tissue segmentation, and (4) site-specific MRI synthesis. Qualitative and quantitative results demonstrate the superiority of our method over several state-of-the-arts.
A Survey on Domain Generalization for Medical Image Analysis
Feb 13, 2024Medical Image Analysis (MedIA) has emerged as a crucial tool in computer-aided diagnosis systems, particularly with the advancement of deep learning (DL) in recent years. However, well-trained deep models often experience significant performance degradation when deployed in different medical sites, modalities, and sequences, known as a domain shift issue. In light of this, Domain Generalization (DG) for MedIA aims to address the domain shift challenge by generalizing effectively and performing robustly across unknown data distributions. This paper presents the a comprehensive review of substantial developments in this area. First, we provide a formal definition of domain shift and domain generalization in medical field, and discuss several related settings. Subsequently, we summarize the recent methods from three viewpoints: data manipulation level, feature representation level, and model training level, and present some algorithms in detail for each viewpoints. Furthermore, we introduce the commonly used datasets. Finally, we summarize existing literature and present some potential research topics for the future. For this survey, we also created a GitHub project by collecting the supporting resources, at the link: https://github.com/Ziwei-Niu/DG_for_MedIA
CommVQA: Situating Visual Question Answering in Communicative Contexts
Feb 22, 2024Current visual question answering (VQA) models tend to be trained and evaluated on image-question pairs in isolation. However, the questions people ask are dependent on their informational needs and prior knowledge about the image content. To evaluate how situating images within naturalistic contexts shapes visual questions, we introduce CommVQA, a VQA dataset consisting of images, image descriptions, real-world communicative scenarios where the image might appear (e.g., a travel website), and follow-up questions and answers conditioned on the scenario. We show that CommVQA poses a challenge for current models. Providing contextual information to VQA models improves performance broadly, highlighting the relevance of situating systems within a communicative scenario.
ArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Feb 27, 2024In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.
Graph Convolutional Neural Networks for Automated Echocardiography View Recognition: A Holistic Approach
Mar 01, 2024To facilitate diagnosis on cardiac ultrasound (US), clinical practice has established several standard views of the heart, which serve as reference points for diagnostic measurements and define viewports from which images are acquired. Automatic view recognition involves grouping those images into classes of standard views. Although deep learning techniques have been successful in achieving this, they still struggle with fully verifying the suitability of an image for specific measurements due to factors like the correct location, pose, and potential occlusions of cardiac structures. Our approach goes beyond view classification and incorporates a 3D mesh reconstruction of the heart that enables several more downstream tasks, like segmentation and pose estimation. In this work, we explore learning 3D heart meshes via graph convolutions, using similar techniques to learn 3D meshes in natural images, such as human pose estimation. As the availability of fully annotated 3D images is limited, we generate synthetic US images from 3D meshes by training an adversarial denoising diffusion model. Experiments were conducted on synthetic and clinical cases for view recognition and structure detection. The approach yielded good performance on synthetic images and, despite being exclusively trained on synthetic data, it already showed potential when applied to clinical images. With this proof-of-concept, we aim to demonstrate the benefits of graphs to improve cardiac view recognition that can ultimately lead to better efficiency in cardiac diagnosis.
Trustworthy Self-Attention: Enabling the Network to Focus Only on the Most Relevant References
Mar 01, 2024
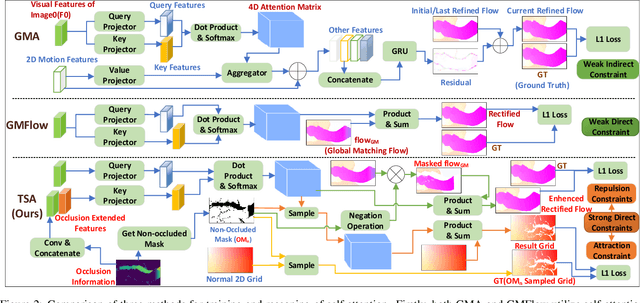
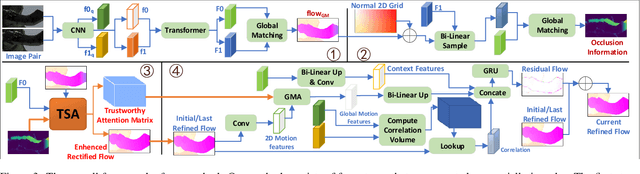
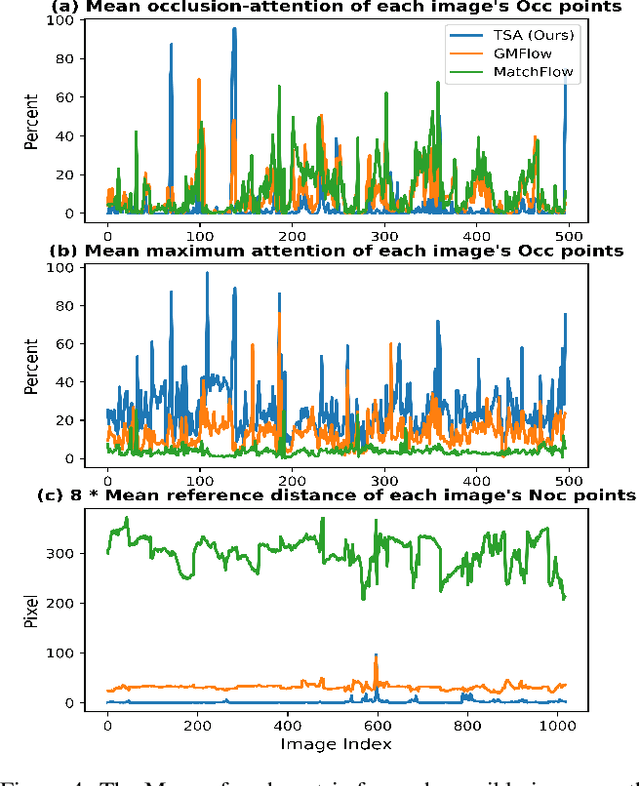
The prediction of optical flow for occluded points is still a difficult problem that has not yet been solved. Recent methods use self-attention to find relevant non-occluded points as references for estimating the optical flow of occluded points based on the assumption of self-similarity. However, they rely on visual features of a single image and weak constraints, which are not sufficient to constrain the trained network to focus on erroneous and weakly relevant reference points. We make full use of online occlusion recognition information to construct occlusion extended visual features and two strong constraints, allowing the network to learn to focus only on the most relevant references without requiring occlusion ground truth to participate in the training of the network. Our method adds very few network parameters to the original framework, making it very lightweight. Extensive experiments show that our model has the greatest cross-dataset generalization. Our method achieves much greater error reduction, 18.6%, 16.2%, and 20.1% for all points, non-occluded points, and occluded points respectively from the state-of-the-art GMA-base method, MATCHFlow(GMA), on Sintel Albedo pass. Furthermore, our model achieves state-of-the-art performance on the Sintel bench-marks, ranking \#1 among all published methods on Sintel clean pass. The code will be open-source.
HyperSDFusion: Bridging Hierarchical Structures in Language and Geometry for Enhanced 3D Text2Shape Generation
Mar 01, 2024

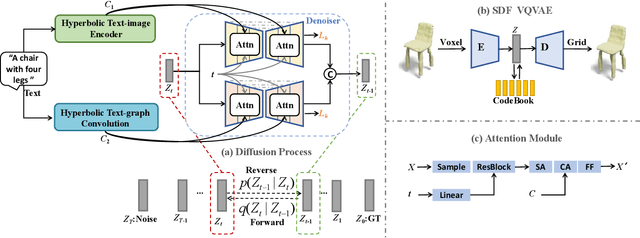
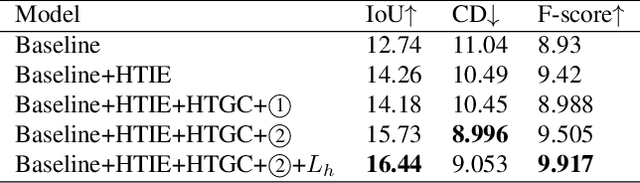
3D shape generation from text is a fundamental task in 3D representation learning. The text-shape pairs exhibit a hierarchical structure, where a general text like "chair" covers all 3D shapes of the chair, while more detailed prompts refer to more specific shapes. Furthermore, both text and 3D shapes are inherently hierarchical structures. However, existing Text2Shape methods, such as SDFusion, do not exploit that. In this work, we propose HyperSDFusion, a dual-branch diffusion model that generates 3D shapes from a given text. Since hyperbolic space is suitable for handling hierarchical data, we propose to learn the hierarchical representations of text and 3D shapes in hyperbolic space. First, we introduce a hyperbolic text-image encoder to learn the sequential and multi-modal hierarchical features of text in hyperbolic space. In addition, we design a hyperbolic text-graph convolution module to learn the hierarchical features of text in hyperbolic space. In order to fully utilize these text features, we introduce a dual-branch structure to embed text features in 3D feature space. At last, to endow the generated 3D shapes with a hierarchical structure, we devise a hyperbolic hierarchical loss. Our method is the first to explore the hyperbolic hierarchical representation for text-to-shape generation. Experimental results on the existing text-to-shape paired dataset, Text2Shape, achieved state-of-the-art results.
Fine-tuning CLIP Text Encoders with Two-step Paraphrasing
Feb 23, 2024Contrastive language-image pre-training (CLIP) models have demonstrated considerable success across various vision-language tasks, such as text-to-image retrieval, where the model is required to effectively process natural language input to produce an accurate visual output. However, current models still face limitations in dealing with linguistic variations in input queries, such as paraphrases, making it challenging to handle a broad range of user queries in real-world applications. In this study, we introduce a straightforward fine-tuning approach to enhance the representations of CLIP models for paraphrases. Our approach involves a two-step paraphrase generation process, where we automatically create two categories of paraphrases from web-scale image captions by leveraging large language models. Subsequently, we fine-tune the CLIP text encoder using these generated paraphrases while freezing the image encoder. Our resulting model, which we call ParaCLIP, exhibits significant improvements over baseline CLIP models across various tasks, including paraphrased retrieval (with rank similarity scores improved by up to 2.0% and 5.6%), Visual Genome Relation and Attribution, as well as seven semantic textual similarity tasks.
On normalization-equivariance properties of supervised and unsupervised denoising methods: a survey
Feb 23, 2024Image denoising is probably the oldest and still one of the most active research topic in image processing. Many methodological concepts have been introduced in the past decades and have improved performances significantly in recent years, especially with the emergence of convolutional neural networks and supervised deep learning. In this paper, we propose a survey of guided tour of supervised and unsupervised learning methods for image denoising, classifying the main principles elaborated during this evolution, with a particular concern given to recent developments in supervised learning. It is conceived as a tutorial organizing in a comprehensive framework current approaches. We give insights on the rationales and limitations of the most performant methods in the literature, and we highlight the common features between many of them. Finally, we focus on on the normalization equivariance properties that is surprisingly not guaranteed with most of supervised methods. It is of paramount importance that intensity shifting or scaling applied to the input image results in a corresponding change in the denoiser output.
BEBLID: Boosted efficient binary local image descriptor
Feb 07, 2024Efficient matching of local image features is a fundamental task in many computer vision applications. However, the real-time performance of top matching algorithms is compromised in computationally limited devices, such as mobile phones or drones, due to the simplicity of their hardware and their finite energy supply. In this paper we introduce BEBLID, an efficient learned binary image descriptor. It improves our previous real-valued descriptor, BELID, making it both more efficient for matching and more accurate. To this end we use AdaBoost with an improved weak-learner training scheme that produces better local descriptions. Further, we binarize our descriptor by forcing all weak-learners to have the same weight in the strong learner combination and train it in an unbalanced data set to address the asymmetries arising in matching and retrieval tasks. In our experiments BEBLID achieves an accuracy close to SIFT and better computational efficiency than ORB, the fastest algorithm in the literature.