 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Online multi-resolution fusion of space-borne multispectral images
Apr 26, 2022
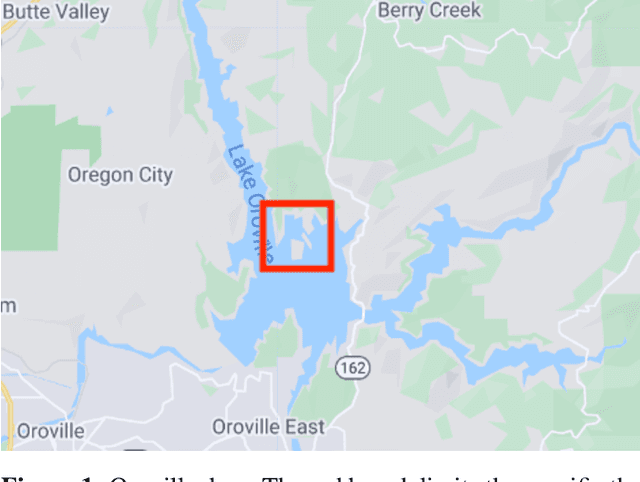
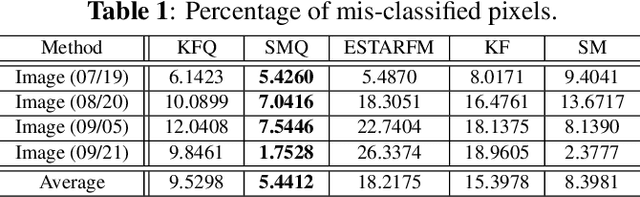
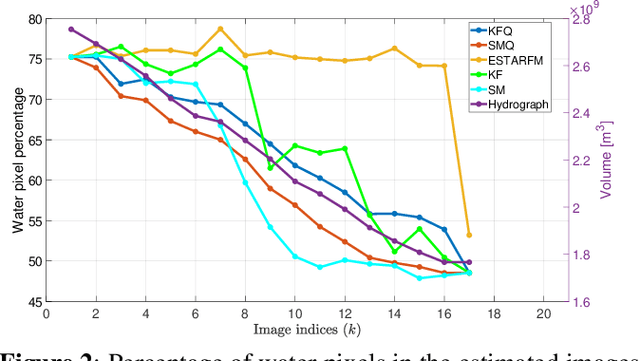
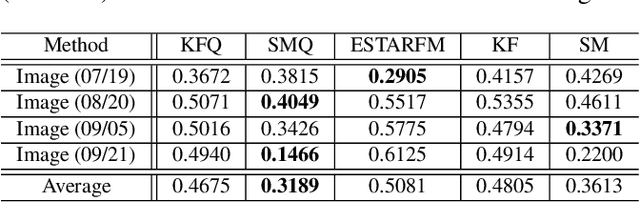
Satellite imaging has a central role in monitoring, detecting and estimating the intensity of key natural phenomena. One important feature of satellite images is the trade-off between spatial/spectral resolution and their revisiting time, a consequence of design and physical constraints imposed by satellite orbit among other technical limitations. In this paper, we focus on fusing multi-temporal, multi-spectral images where data acquired from different instruments with different spatial resolutions is used. We leverage the spatial relationship between images at multiple modalities to generate high-resolution image sequences at higher revisiting rates. To achieve this goal, we formulate the fusion method as a recursive state estimation problem and study its performance in filtering and smoothing contexts. The proposed strategy clearly outperforms competing methodologies, which is shown in the paper for real data acquired by the Landsat and MODIS instruments.
Wavelength-based Attributed Deep Neural Network for Underwater Image Restoration
Jun 15, 2021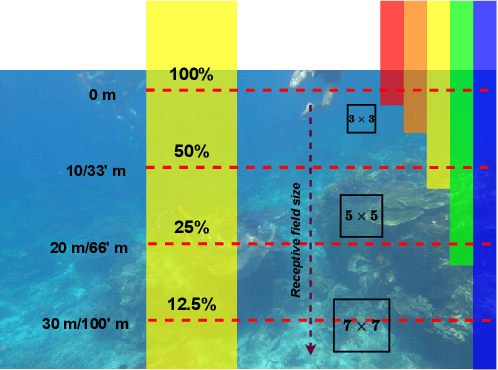



Underwater images, in general, suffer from low contrast and high color distortions due to the non-uniform attenuation of the light as it propagates through the water. In addition, the degree of attenuation varies with the wavelength resulting in the asymmetric traversing of colors. Despite the prolific works for underwater image restoration (UIR) using deep learning, the above asymmetricity has not been addressed in the respective network engineering. As the first novelty, this paper shows that attributing the right receptive field size (context) based on the traversing range of the color channel may lead to a substantial performance gain for the task of UIR. Further, it is important to suppress the irrelevant multi-contextual features and increase the representational power of the model. Therefore, as a second novelty, we have incorporated an attentive skip mechanism to adaptively refine the learned multi-contextual features. The proposed framework, called Deep WaveNet, is optimized using the traditional pixel-wise and feature-based cost functions. An extensive set of experiments have been carried out to show the efficacy of the proposed scheme over existing best-published literature on benchmark datasets. More importantly, we have demonstrated a comprehensive validation of enhanced images across various high-level vision tasks, e.g., underwater image semantic segmentation, and diver's 2D pose estimation. A sample video to exhibit our real-world performance is available at \url{https://www.youtube.com/watch?v=8qtuegBdfac}.
Skydiver: A Spiking Neural Network Accelerator Exploiting Spatio-Temporal Workload Balance
Mar 14, 2022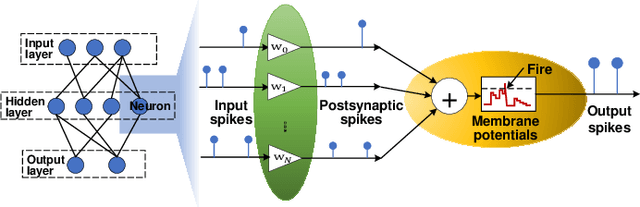
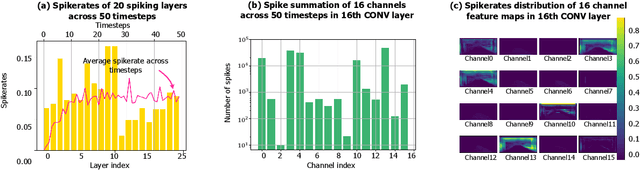
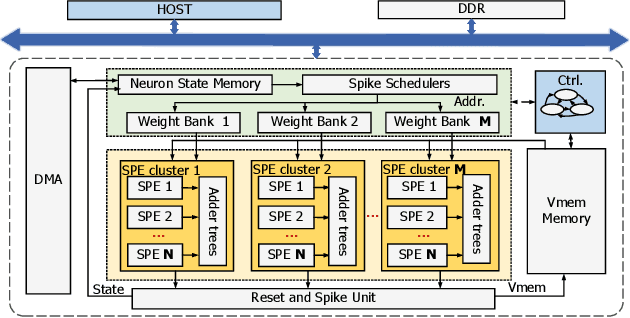
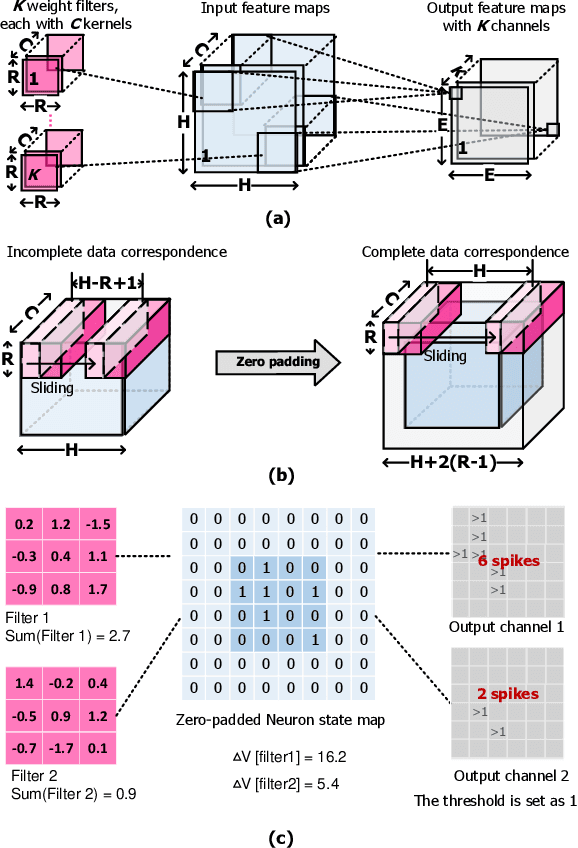
Spiking Neural Networks (SNNs) are developed as a promising alternative to Artificial Neural networks (ANNs) due to their more realistic brain-inspired computing models. SNNs have sparse neuron firing over time, i.e., spatio-temporal sparsity; thus, they are useful to enable energy-efficient hardware inference. However, exploiting spatio-temporal sparsity of SNNs in hardware leads to unpredictable and unbalanced workloads, degrading the energy efficiency. In this work, we propose an FPGA-based convolutional SNN accelerator called Skydiver that exploits spatio-temporal workload balance. We propose the Approximate Proportional Relation Construction (APRC) method that can predict the relative workload channel-wisely and a Channel-Balanced Workload Schedule (CBWS) method to increase the hardware workload balance ratio to over 90%. Skydiver was implemented on a Xilinx XC7Z045 FPGA and verified on image segmentation and MNIST classification tasks. Results show improved throughput by 1.4X and 1.2X for the two tasks. Skydiver achieved 22.6 KFPS throughput, and 42.4 uJ/Image prediction energy on the classification task with 98.5% accuracy.
CenterLoc3D: Monocular 3D Vehicle Localization Network for Roadside Surveillance Cameras
Apr 06, 2022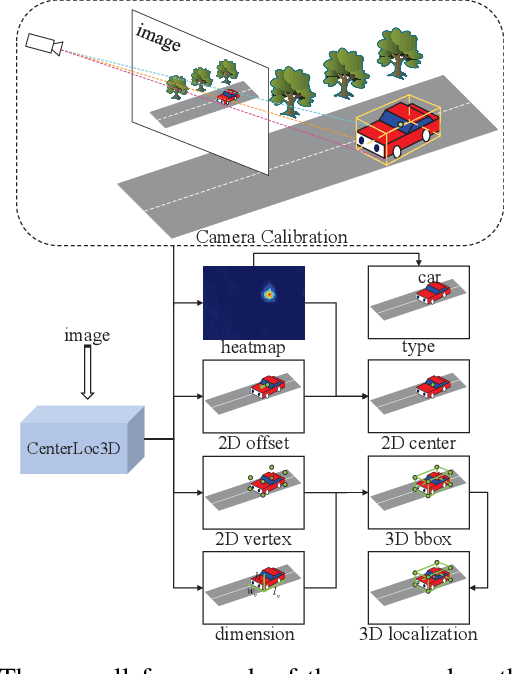
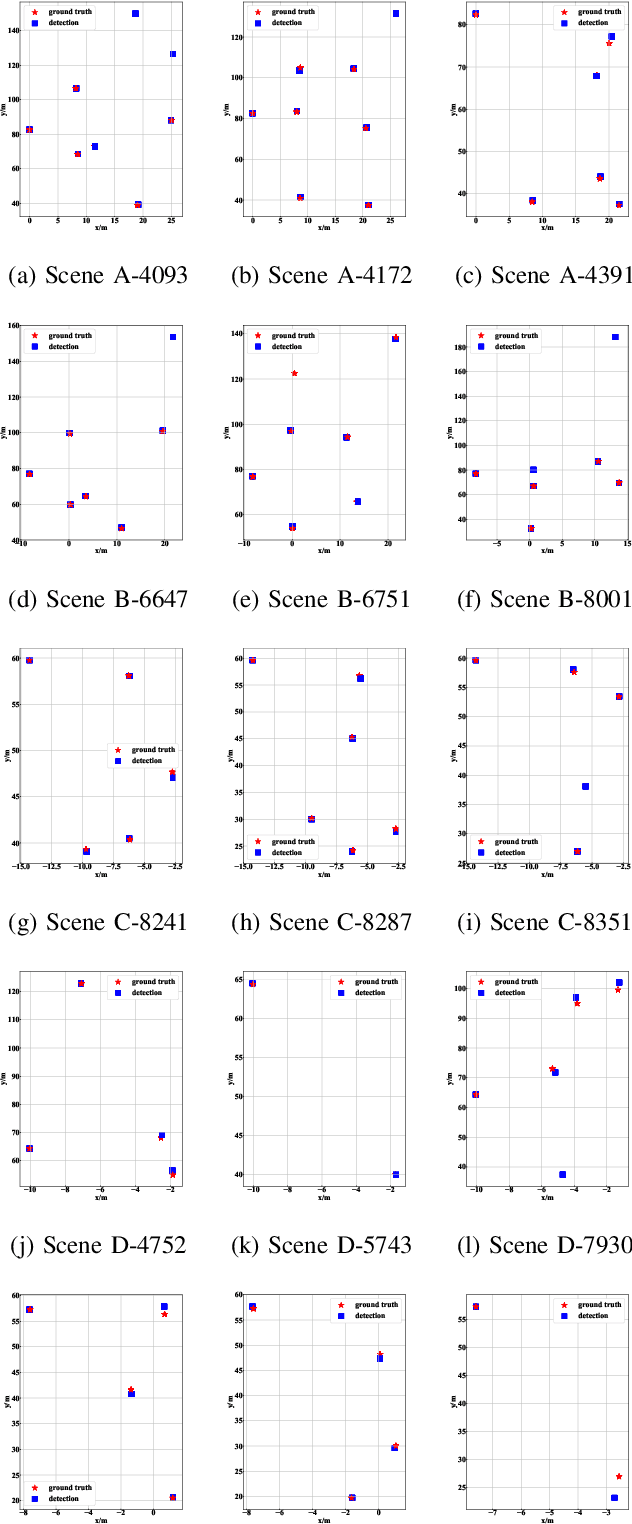
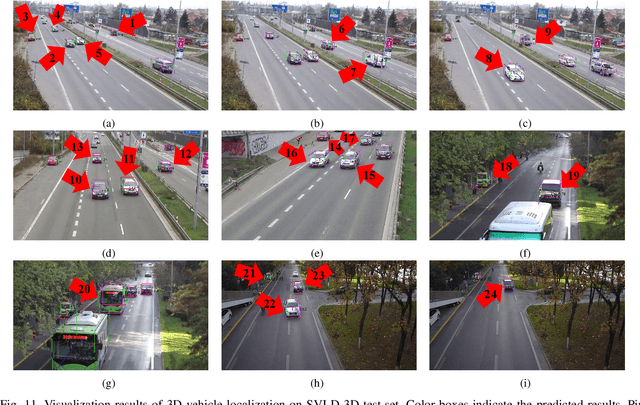
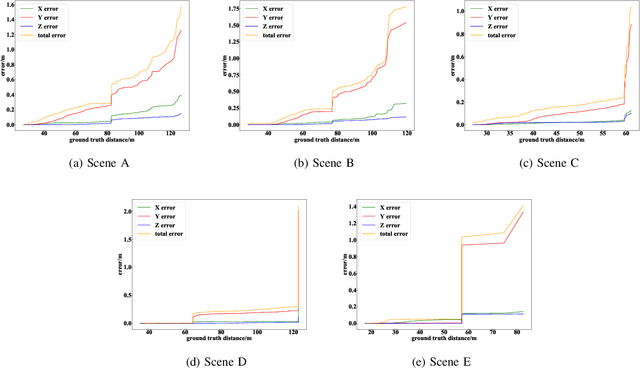
Monocular 3D vehicle localization is an important task in Intelligent Transportation System (ITS) and Cooperative Vehicle Infrastructure System (CVIS), which is usually achieved by monocular 3D vehicle detection. However, depth information cannot be obtained directly by monocular cameras due to the inherent imaging mechanism, resulting in more challenging monocular 3D tasks. Most of the current monocular 3D vehicle detection methods leverage 2D detectors and additional geometric modules, which reduces the efficiency. In this paper, we propose a 3D vehicle localization network CenterLoc3D for roadside monocular cameras, which directly predicts centroid and eight vertexes in image space, and the dimension of 3D bounding boxes without 2D detectors. To improve the precision of 3D vehicle localization, we propose a weighted-fusion module and a loss with spatial constraints embedded in CenterLoc3D. Firstly, the transformation matrix between 2D image space and 3D world space is solved by camera calibration. Secondly, vehicle type, centroid, eight vertexes, and the dimension of 3D vehicle bounding boxes are obtained by CenterLoc3D. Finally, centroid in 3D world space can be obtained by camera calibration and CenterLoc3D for 3D vehicle localization. To the best of our knowledge, this is the first application of 3D vehicle localization for roadside monocular cameras. Hence, we also propose a benchmark for this application including a dataset (SVLD-3D), an annotation tool (LabelImg-3D), and evaluation metrics. Through experimental validation, the proposed method achieves high accuracy and real-time performance.
Exploring Generative Adversarial Networks for Image-to-Image Translation in STEM Simulation
Oct 29, 2020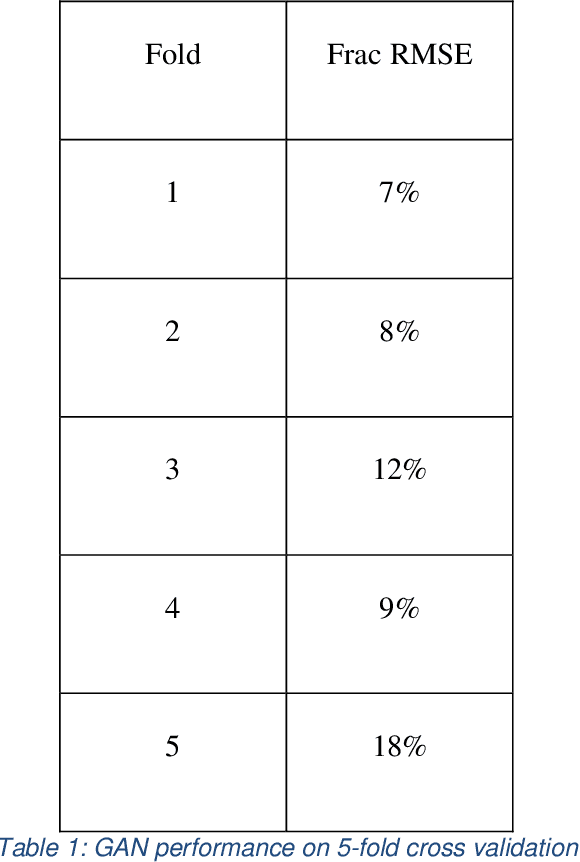
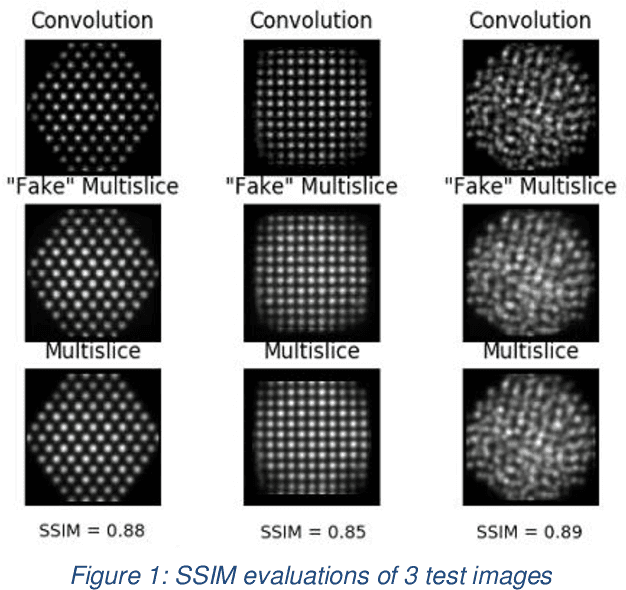

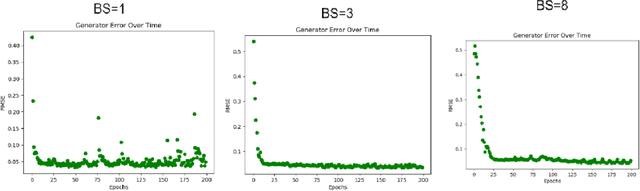
The use of accurate scanning transmission electron microscopy (STEM) image simulation methods require large computation times that can make their use infeasible for the simulation of many images. Other simulation methods based on linear imaging models, such as the convolution method, are much faster but are too inaccurate to be used in application. In this paper, we explore deep learning models that attempt to translate a STEM image produced by the convolution method to a prediction of the high accuracy multislice image. We then compare our results to those of regression methods. We find that using the deep learning model Generative Adversarial Network (GAN) provides us with the best results and performs at a similar accuracy level to previous regression models on the same dataset. Codes and data for this project can be found in this GitHub repository, https://github.com/uw-cmg/GAN-STEM-Conv2MultiSlice.
Boundary-aware Information Maximization for Self-supervised Medical Image Segmentation
Feb 04, 2022Unsupervised pre-training has been proven as an effective approach to boost various downstream tasks given limited labeled data. Among various methods, contrastive learning learns a discriminative representation by constructing positive and negative pairs. However, it is not trivial to build reasonable pairs for a segmentation task in an unsupervised way. In this work, we propose a novel unsupervised pre-training framework that avoids the drawback of contrastive learning. Our framework consists of two principles: unsupervised over-segmentation as a pre-train task using mutual information maximization and boundary-aware preserving learning. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
Backdooring Explainable Machine Learning
Apr 20, 2022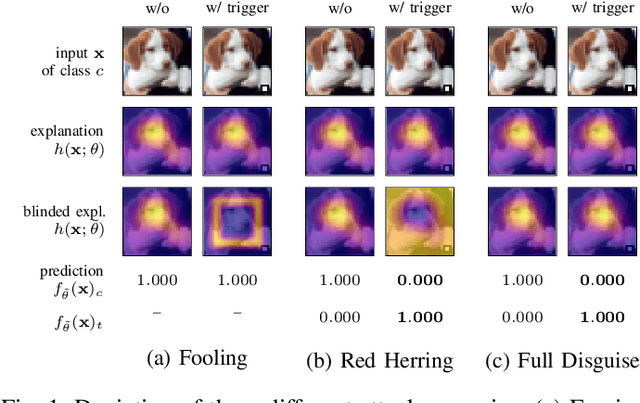
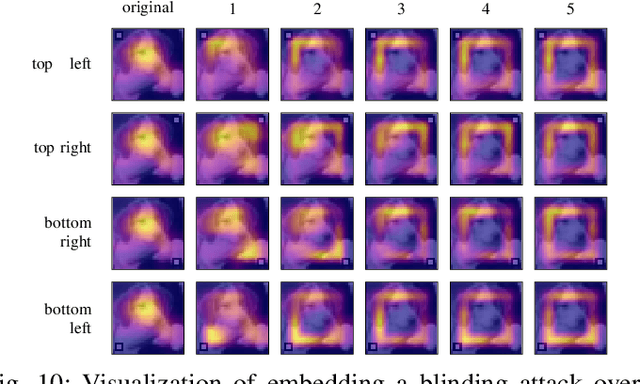
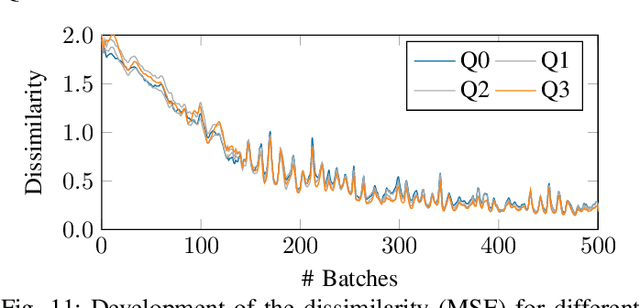
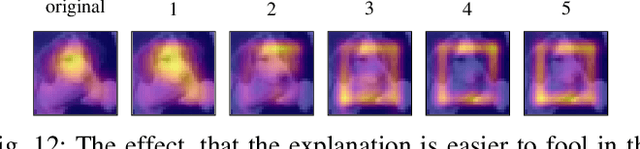
Explainable machine learning holds great potential for analyzing and understanding learning-based systems. These methods can, however, be manipulated to present unfaithful explanations, giving rise to powerful and stealthy adversaries. In this paper, we demonstrate blinding attacks that can fully disguise an ongoing attack against the machine learning model. Similar to neural backdoors, we modify the model's prediction upon trigger presence but simultaneously also fool the provided explanation. This enables an adversary to hide the presence of the trigger or point the explanation to entirely different portions of the input, throwing a red herring. We analyze different manifestations of such attacks for different explanation types in the image domain, before we resume to conduct a red-herring attack against malware classification.
Scale Normalized Image Pyramids with AutoFocus for Object Detection
Feb 10, 2021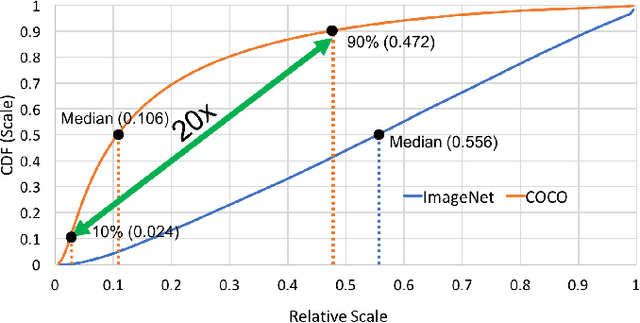

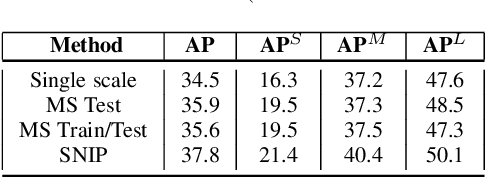
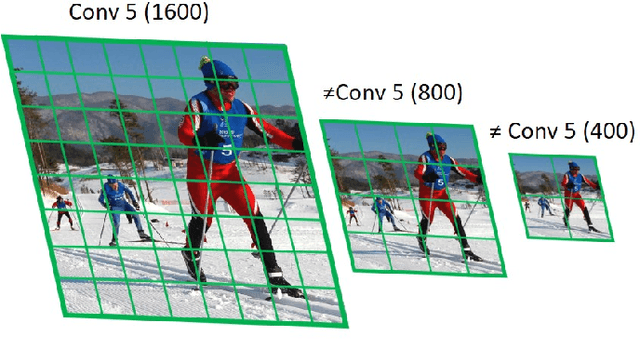
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.
HCSC: Hierarchical Contrastive Selective Coding
Feb 01, 2022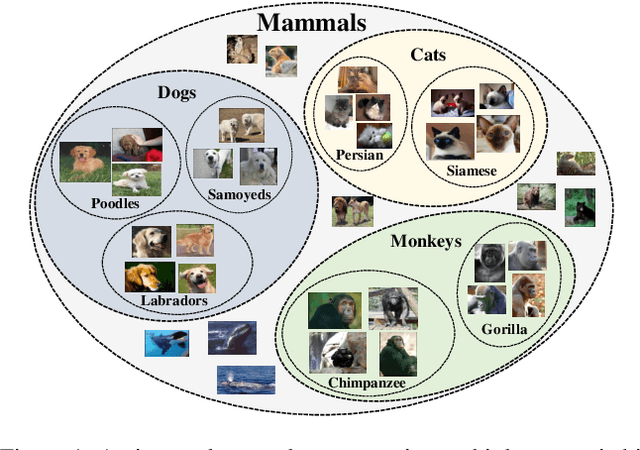
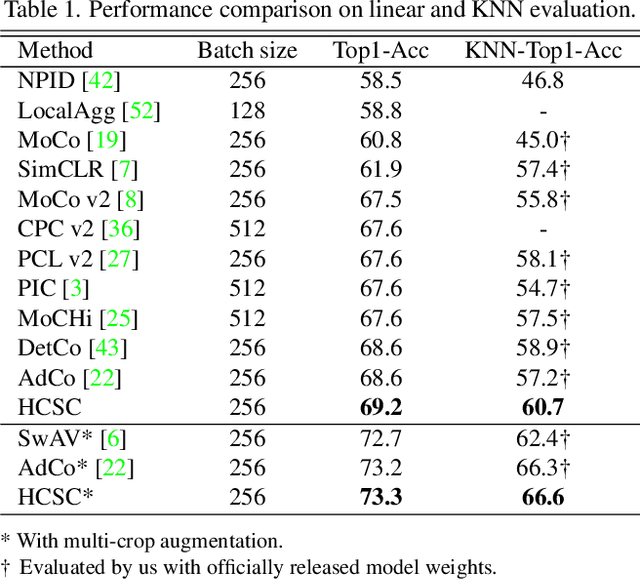
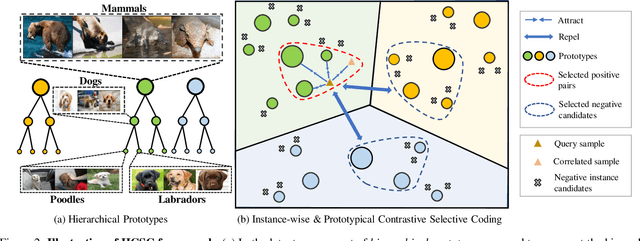
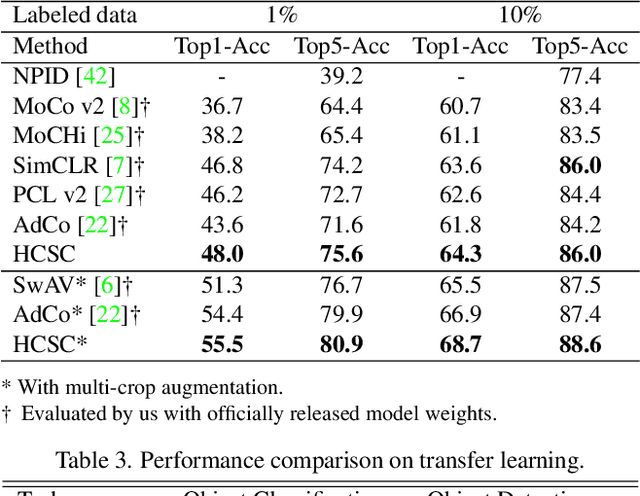
Hierarchical semantic structures naturally exist in an image dataset, in which several semantically relevant image clusters can be further integrated into a larger cluster with coarser-grained semantics. Capturing such structures with image representations can greatly benefit the semantic understanding on various downstream tasks. Existing contrastive representation learning methods lack such an important model capability. In addition, the negative pairs used in these methods are not guaranteed to be semantically distinct, which could further hamper the structural correctness of learned image representations. To tackle these limitations, we propose a novel contrastive learning framework called Hierarchical Contrastive Selective Coding (HCSC). In this framework, a set of hierarchical prototypes are constructed and also dynamically updated to represent the hierarchical semantic structures underlying the data in the latent space. To make image representations better fit such semantic structures, we employ and further improve conventional instance-wise and prototypical contrastive learning via an elaborate pair selection scheme. This scheme seeks to select more diverse positive pairs with similar semantics and more precise negative pairs with truly distinct semantics. On extensive downstream tasks, we verify the superior performance of HCSC over state-of-the-art contrastive methods, and the effectiveness of major model components is proved by plentiful analytical studies. Our source code and model weights are available at https://github.com/gyfastas/HCSC
On the semantics of big Earth observation data for land classification
Apr 23, 2022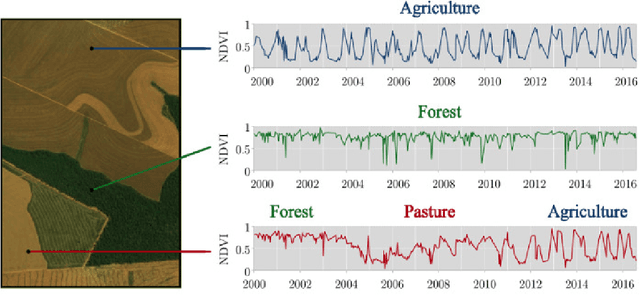
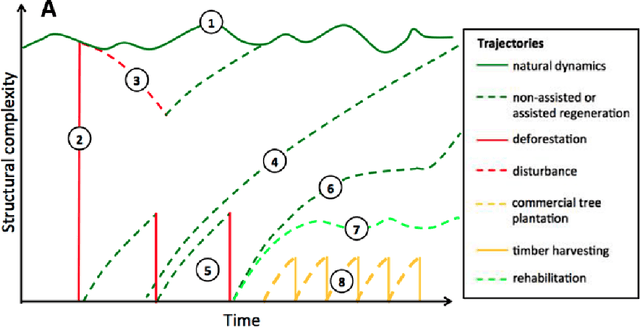
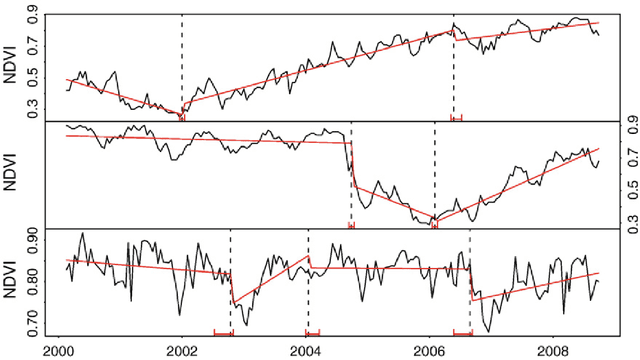
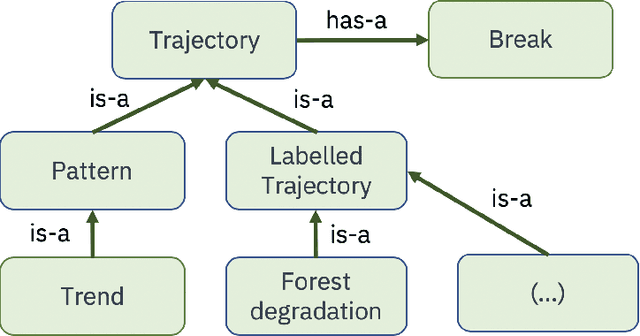
This paper discusses the challenges of using big Earth observation data for land classification. The approach taken is to consider pure data-driven methods to be insufficient to represent continuous change. We argue for sound theories when working with big data. After revising existing classification schemes such as FAO's Land Cover Classification System (LCCS), we conclude that LCCS and similar proposals cannot capture the complexity of landscape dynamics. We then investigate concepts that are being used for analyzing satellite image time series; we show these concepts to be instances of events. Therefore, for continuous monitoring of land change, event recognition needs to replace object identification as the prevailing paradigm. The paper concludes by showing how event semantics can improve data-driven methods to fulfil the potential of big data.