 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
May 20, 2022
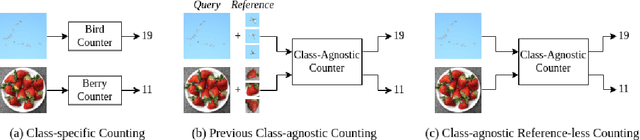
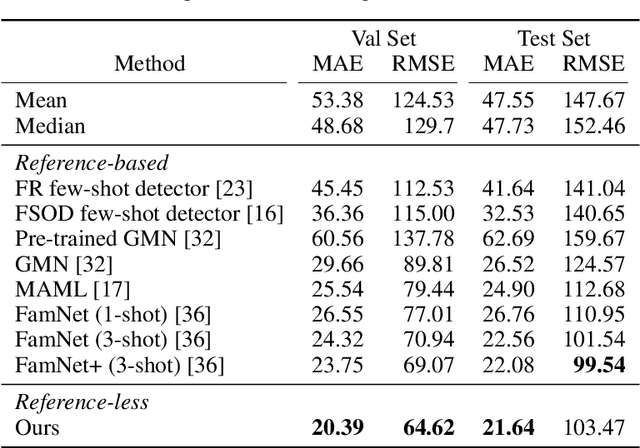
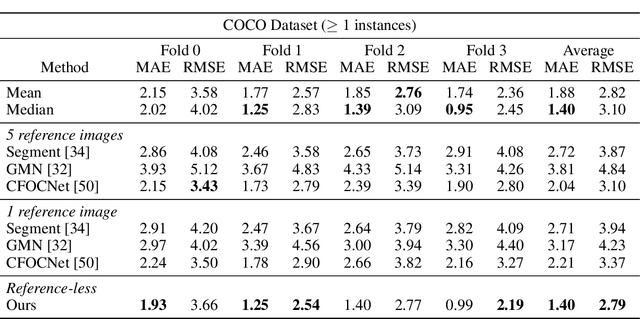

Object counting is a seemingly simple task with diverse real-world applications. Most counting methods focus on counting instances of specific, known classes. While there are class-agnostic counting methods that can generalise to unseen classes, these methods require reference images to define the type of object to be counted, as well as instance annotations during training. We identify that counting is, at its core, a repetition-recognition task and show that a general feature space, with global context, is sufficient to enumerate instances in an image without a prior on the object type present. Specifically, we demonstrate that self-supervised vision transformer features combined with a lightweight count regression head achieve competitive results when compared to other class-agnostic counting tasks without the need for point-level supervision or reference images. Our method thus facilitates counting on a constantly changing set composition. To the best of our knowledge, we are both the first reference-less class-agnostic counting method as well as the first weakly-supervised class-agnostic counting method.
Empirical Analysis of Image Caption Generation using Deep Learning
May 14, 2021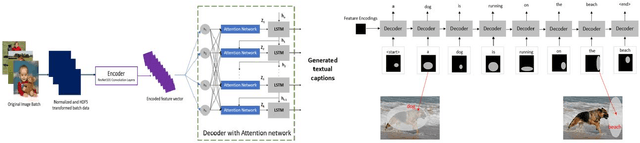
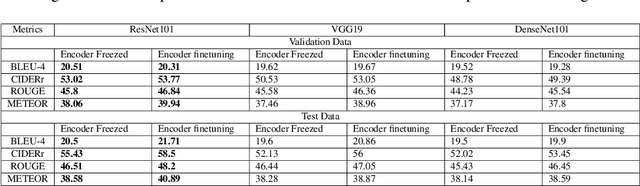

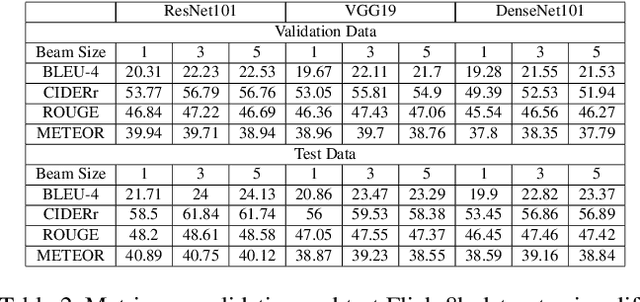
Automated image captioning is one of the applications of Deep Learning which involves fusion of work done in computer vision and natural language processing, and it is typically performed using Encoder-Decoder architectures. In this project, we have implemented and experimented with various flavors of multi-modal image captioning networks where ResNet101, DenseNet121 and VGG19 based CNN Encoders and Attention based LSTM Decoders were explored. We have studied the effect of beam size and the use of pretrained word embeddings and compared them to baseline CNN encoder and RNN decoder architecture. The goal is to analyze the performance of each approach using various evaluation metrics including BLEU, CIDEr, ROUGE and METEOR. We have also explored model explainability using Visual Attention Maps (VAM) to highlight parts of the images which has maximum contribution for predicting each word of the generated caption.
The Missing Invariance Principle Found -- the Reciprocal Twin of Invariant Risk Minimization
May 29, 2022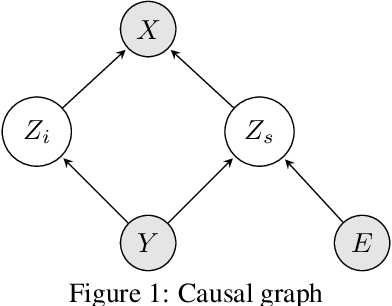
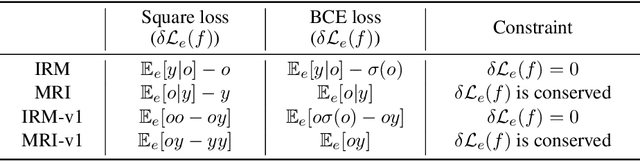
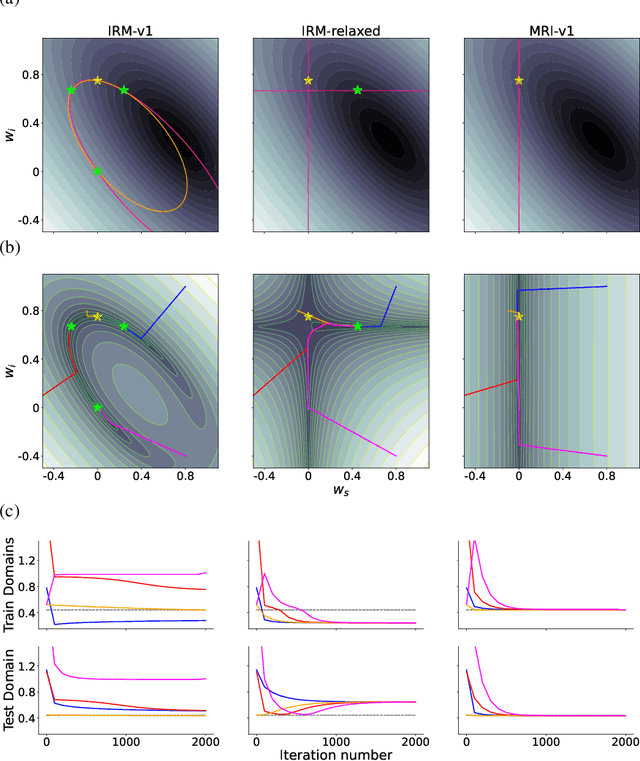

Machine learning models often generalize poorly to out-of-distribution (OOD) data as a result of relying on features that are spuriously correlated with the label during training. Recently, the technique of Invariant Risk Minimization (IRM) was proposed to learn predictors that only use invariant features by conserving the feature-conditioned class expectation $\mathbb{E}_e[y|f(x)]$ across environments. However, more recent studies have demonstrated that IRM can fail in various task settings. Here, we identify a fundamental flaw of IRM formulation that causes the failure. We then introduce a complementary notion of invariance, MRI, that is based on conserving the class-conditioned feature expectation $\mathbb{E}_e[f(x)|y]$ across environments, that corrects for the flaw in IRM. Further, we introduce a simplified, practical version of the MRI formulation called as MRI-v1. We note that this constraint is convex which confers it with an advantage over the practical version of IRM, IRM-v1, which imposes non-convex constraints. We prove that in a general linear problem setting, MRI-v1 can guarantee invariant predictors given sufficient environments. We also empirically demonstrate that MRI strongly out-performs IRM and consistently achieves near-optimal OOD generalization in image-based nonlinear problems.
Enhanced Modality Transition for Image Captioning
Feb 23, 2021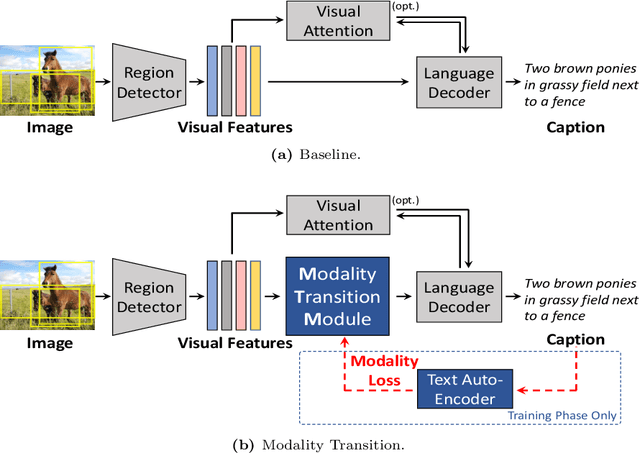
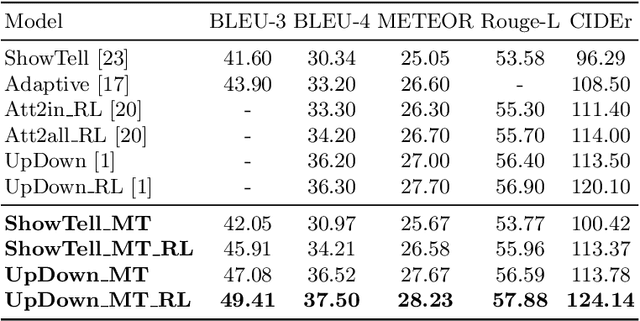
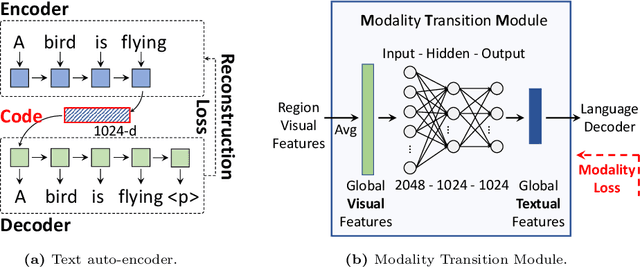
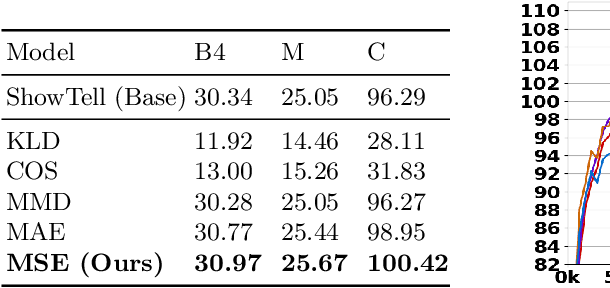
Image captioning model is a cross-modality knowledge discovery task, which targets at automatically describing an image with an informative and coherent sentence. To generate the captions, the previous encoder-decoder frameworks directly forward the visual vectors to the recurrent language model, forcing the recurrent units to generate a sentence based on the visual features. Although these sentences are generally readable, they still suffer from the lack of details and highlights, due to the fact that the substantial gap between the image and text modalities is not sufficiently addressed. In this work, we explicitly build a Modality Transition Module (MTM) to transfer visual features into semantic representations before forwarding them to the language model. During the training phase, the modality transition network is optimised by the proposed modality loss, which compares the generated preliminary textual encodings with the target sentence vectors from a pre-trained text auto-encoder. In this way, the visual vectors are transited into the textual subspace for more contextual and precise language generation. The novel MTM can be incorporated into most of the existing methods. Extensive experiments have been conducted on the MS-COCO dataset demonstrating the effectiveness of the proposed framework, improving the performance by 3.4% comparing to the state-of-the-arts.
High-resolution Face Swapping via Latent Semantics Disentanglement
Mar 30, 2022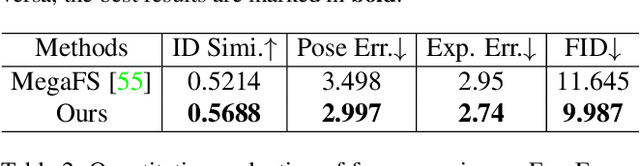
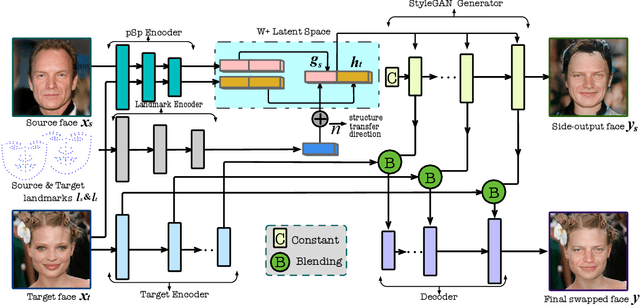
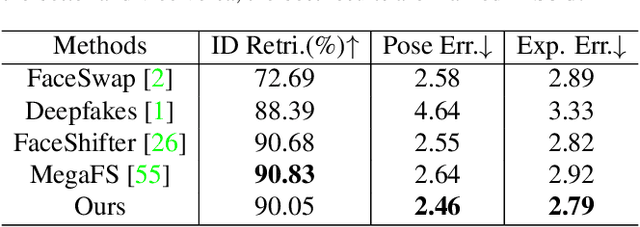

We present a novel high-resolution face swapping method using the inherent prior knowledge of a pre-trained GAN model. Although previous research can leverage generative priors to produce high-resolution results, their quality can suffer from the entangled semantics of the latent space. We explicitly disentangle the latent semantics by utilizing the progressive nature of the generator, deriving structure attributes from the shallow layers and appearance attributes from the deeper ones. Identity and pose information within the structure attributes are further separated by introducing a landmark-driven structure transfer latent direction. The disentangled latent code produces rich generative features that incorporate feature blending to produce a plausible swapping result. We further extend our method to video face swapping by enforcing two spatio-temporal constraints on the latent space and the image space. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art image/video face swapping methods in terms of hallucination quality and consistency. Code can be found at: https://github.com/cnnlstm/FSLSD_HiRes.
Finding an Unsupervised Image Segmenter in Each of Your Deep Generative Models
May 17, 2021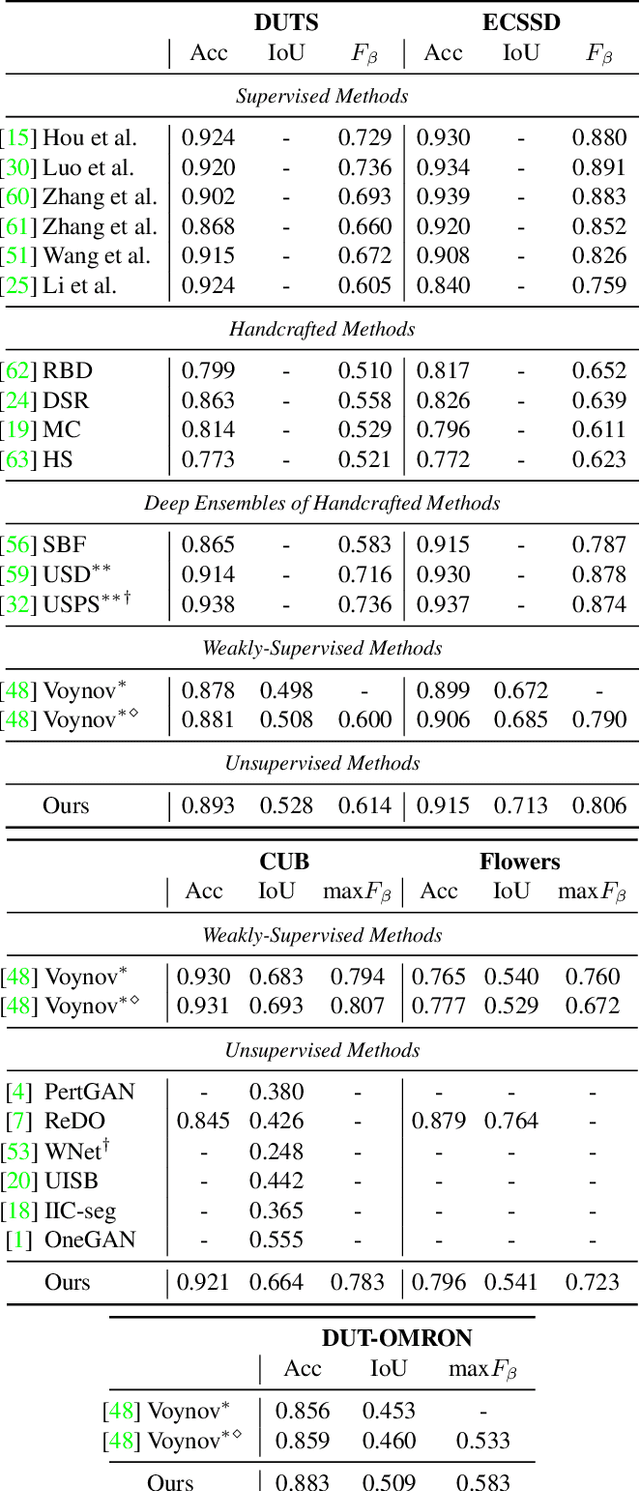
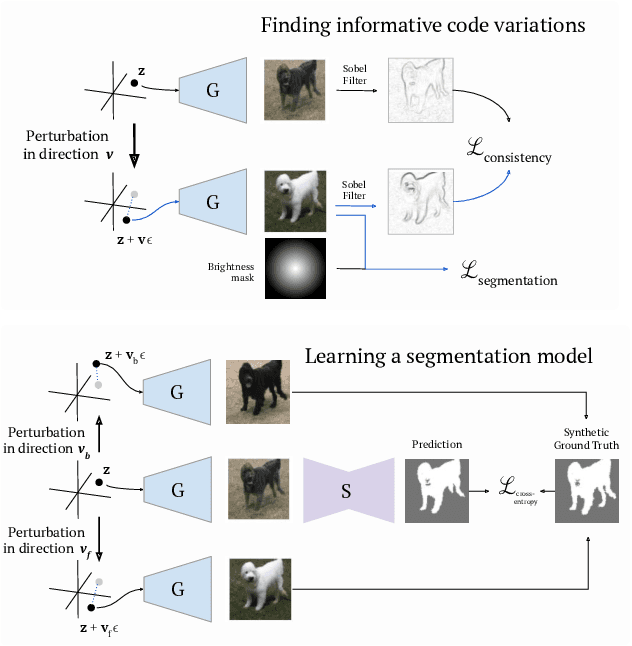

Recent research has shown that numerous human-interpretable directions exist in the latent space of GANs. In this paper, we develop an automatic procedure for finding directions that lead to foreground-background image separation, and we use these directions to train an image segmentation model without human supervision. Our method is generator-agnostic, producing strong segmentation results with a wide range of different GAN architectures. Furthermore, by leveraging GANs pretrained on large datasets such as ImageNet, we are able to segment images from a range of domains without further training or finetuning. Evaluating our method on image segmentation benchmarks, we compare favorably to prior work while using neither human supervision nor access to the training data. Broadly, our results demonstrate that automatically extracting foreground-background structure from pretrained deep generative models can serve as a remarkably effective substitute for human supervision.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
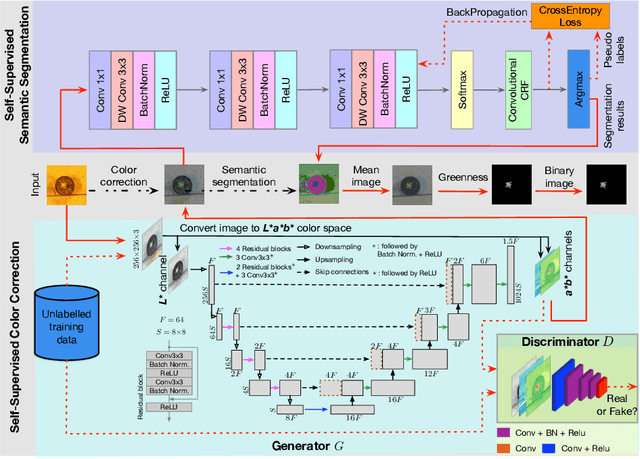

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
What do we learn? Debunking the Myth of Unsupervised Outlier Detection
Jun 08, 2022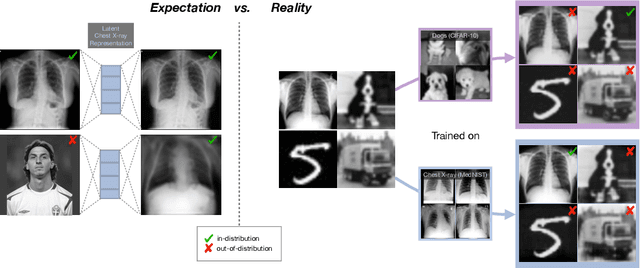
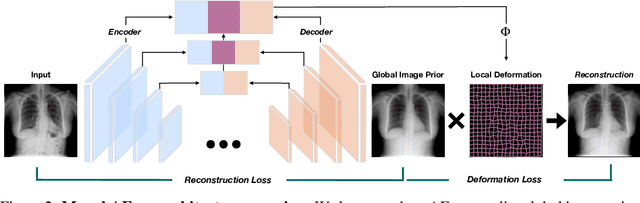
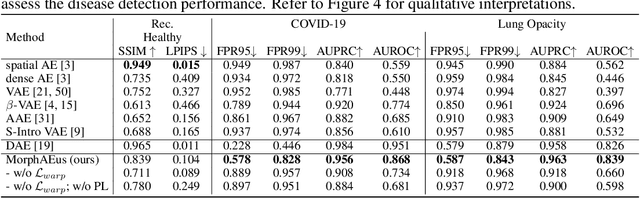
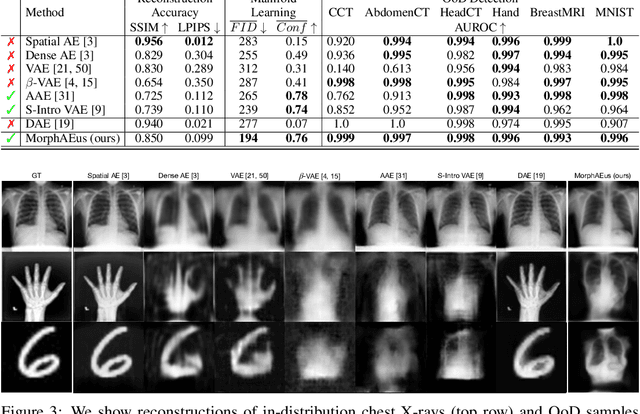
Even though auto-encoders (AEs) have the desirable property of learning compact representations without labels and have been widely applied to out-of-distribution (OoD) detection, they are generally still poorly understood and are used incorrectly in detecting outliers where the normal and abnormal distributions are strongly overlapping. In general, the learned manifold is assumed to contain key information that is only important for describing samples within the training distribution, and that the reconstruction of outliers leads to high residual errors. However, recent work suggests that AEs are likely to be even better at reconstructing some types of OoD samples. In this work, we challenge this assumption and investigate what auto-encoders actually learn when they are posed to solve two different tasks. First, we propose two metrics based on the Fr\'echet inception distance (FID) and confidence scores of a trained classifier to assess whether AEs can learn the training distribution and reliably recognize samples from other domains. Second, we investigate whether AEs are able to synthesize normal images from samples with abnormal regions, on a more challenging lung pathology detection task. We have found that state-of-the-art (SOTA) AEs are either unable to constrain the latent manifold and allow reconstruction of abnormal patterns, or they are failing to accurately restore the inputs from their latent distribution, resulting in blurred or misaligned reconstructions. We propose novel deformable auto-encoders (MorphAEus) to learn perceptually aware global image priors and locally adapt their morphometry based on estimated dense deformation fields. We demonstrate superior performance over unsupervised methods in detecting OoD and pathology.
User-Guided Personalized Image Aesthetic Assessment based on Deep Reinforcement Learning
Jun 14, 2021
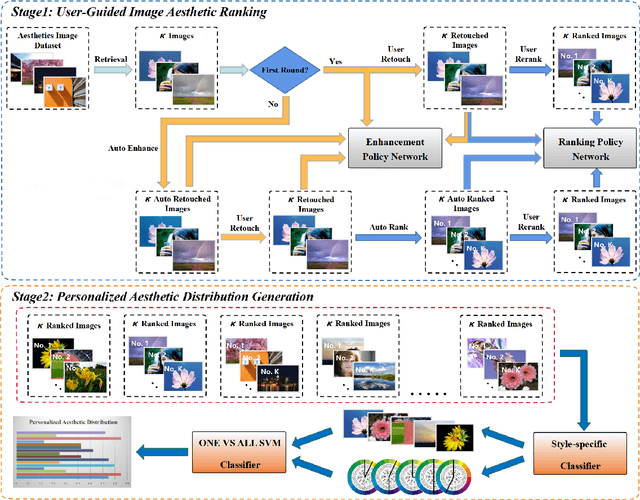
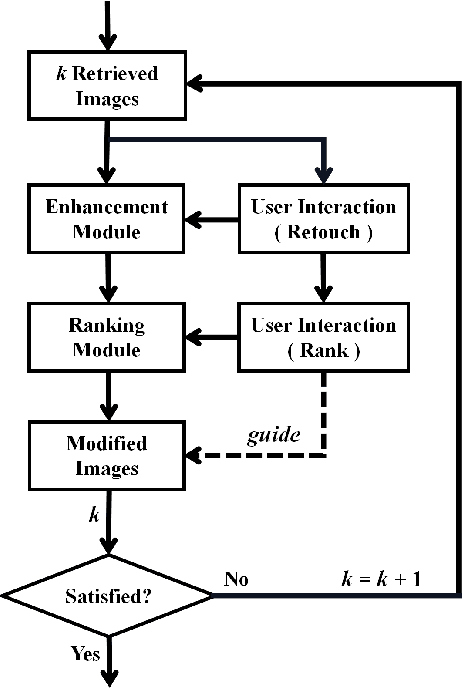
Personalized image aesthetic assessment (PIAA) has recently become a hot topic due to its usefulness in a wide variety of applications such as photography, film and television, e-commerce, fashion design and so on. This task is more seriously affected by subjective factors and samples provided by users. In order to acquire precise personalized aesthetic distribution by small amount of samples, we propose a novel user-guided personalized image aesthetic assessment framework. This framework leverages user interactions to retouch and rank images for aesthetic assessment based on deep reinforcement learning (DRL), and generates personalized aesthetic distribution that is more in line with the aesthetic preferences of different users. It mainly consists of two stages. In the first stage, personalized aesthetic ranking is generated by interactive image enhancement and manual ranking, meanwhile two policy networks will be trained. The images will be pushed to the user for manual retouching and simultaneously to the enhancement policy network. The enhancement network utilizes the manual retouching results as the optimization goals of DRL. After that, the ranking process performs the similar operations like the retouching mentioned before. These two networks will be trained iteratively and alternatively to help to complete the final personalized aesthetic assessment automatically. In the second stage, these modified images are labeled with aesthetic attributes by one style-specific classifier, and then the personalized aesthetic distribution is generated based on the multiple aesthetic attributes of these images, which conforms to the aesthetic preference of users better.
Top-down inference in an early visual cortex inspired hierarchical Variational Autoencoder
Jun 01, 2022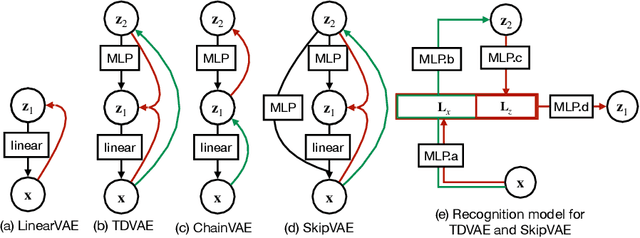

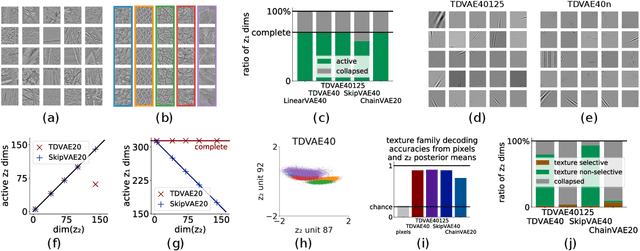
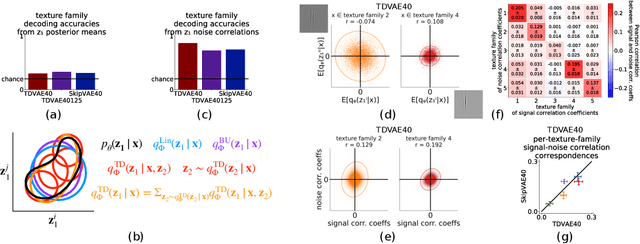
Interpreting computations in the visual cortex as learning and inference in a generative model of the environment has received wide support both in neuroscience and cognitive science. However, hierarchical computations, a hallmark of visual cortical processing, has remained impervious for generative models because of a lack of adequate tools to address it. Here we capitalize on advances in Variational Autoencoders (VAEs) to investigate the early visual cortex with sparse coding hierarchical VAEs trained on natural images. We design alternative architectures that vary both in terms of the generative and the recognition components of the two latent-layer VAE. We show that representations similar to the one found in the primary and secondary visual cortices naturally emerge under mild inductive biases. Importantly, a nonlinear representation for texture-like patterns is a stable property of the high-level latent space resistant to the specific architecture of the VAE, reminiscent of the secondary visual cortex. We show that a neuroscience-inspired choice of the recognition model, which features a top-down processing component is critical for two signatures of computations with generative models: learning higher order moments of the posterior beyond the mean and image inpainting. Patterns in higher order response statistics provide inspirations for neuroscience to interpret response correlations and for machine learning to evaluate the learned representations through more detailed characterization of the posterior.