 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle View Seafloor Recovery from Imaging Sonar via Differentiable Rendering
May 22, 2026Sonar is often the only modality suitable for high-resolution imaging underwater due to light attenuation and turbidity. Forward-looking imaging sonar provides measurements over range and horizontal angle but collapses vertical structure into a flat image, creating ambiguities that make 3D recovery challenging. A common use case for imaging sonar is underwater terrain mapping (bathymetry), yet current methods require many views, expensive multi-sensor setups, or significant training data, which limits use and adaptability to new environments. We present a training-free method that recovers bathymetry from a single sonar image in under 30 seconds via differentiable rendering, conditioned on a known seafloor tilt. To our knowledge, this is the first differentiable rendering approach for single-view height recovery in sonar. Our method implements differentiable sonar ray tracing and optimizes an explicit height field to reproduce the target image. On synthetic datasets, our approach outperforms a supervised CNN under distribution shift and remains close on rough terrain, while the CNN wins in-distribution. By modeling physically grounded priors of the sonar process, our method adapts across sensor configurations and environments without training data.
SAVeD: Learning to Denoise Low-SNR Video for Improved Downstream Performance
Mar 31, 2025Foundation models excel at vision tasks in natural images but fail in low signal-to-noise ratio (SNR) videos, such as underwater sonar, ultrasound, and microscopy. We introduce Spatiotemporal Augmentations and denoising in Video for Downstream Tasks (SAVeD), a self-supervised method that denoises low-SNR sensor videos and is trained using only the raw noisy data. By leveraging differences in foreground and background motion, SAVeD enhances object visibility using an encoder-decoder with a temporal bottleneck. Our approach improves classification, detection, tracking, and counting, outperforming state-of-the-art video denoising methods with lower resource requirements. Project page: https://suzanne-stathatos.github.io/SAVeD Code page: https://github.com/suzanne-stathatos/SAVeD
Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
May 20, 2022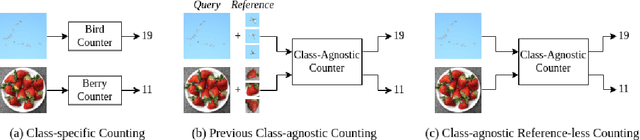
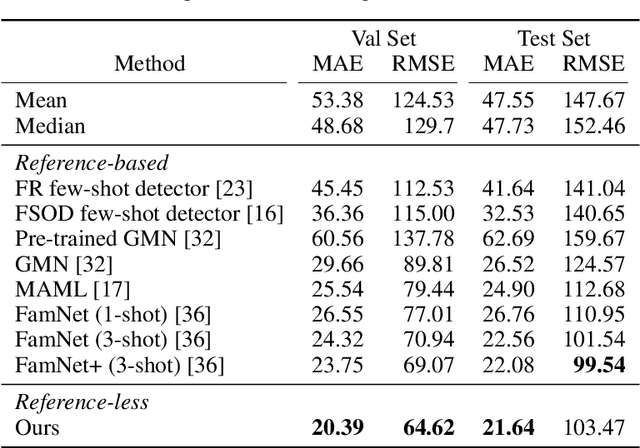
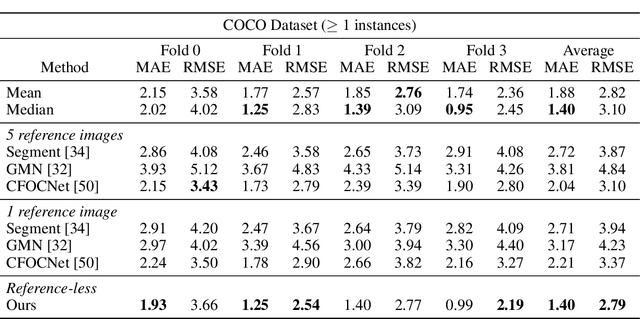

Object counting is a seemingly simple task with diverse real-world applications. Most counting methods focus on counting instances of specific, known classes. While there are class-agnostic counting methods that can generalise to unseen classes, these methods require reference images to define the type of object to be counted, as well as instance annotations during training. We identify that counting is, at its core, a repetition-recognition task and show that a general feature space, with global context, is sufficient to enumerate instances in an image without a prior on the object type present. Specifically, we demonstrate that self-supervised vision transformer features combined with a lightweight count regression head achieve competitive results when compared to other class-agnostic counting tasks without the need for point-level supervision or reference images. Our method thus facilitates counting on a constantly changing set composition. To the best of our knowledge, we are both the first reference-less class-agnostic counting method as well as the first weakly-supervised class-agnostic counting method.