 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analytical Interpretation of Latent Codes in InfoGAN with SAR Images
May 26, 2022
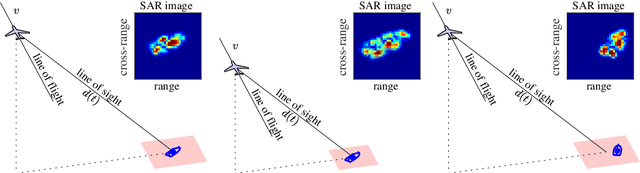
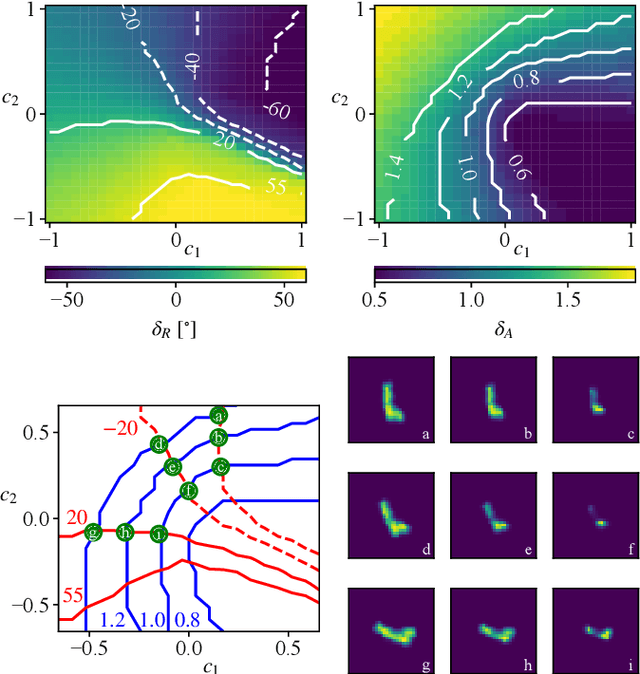
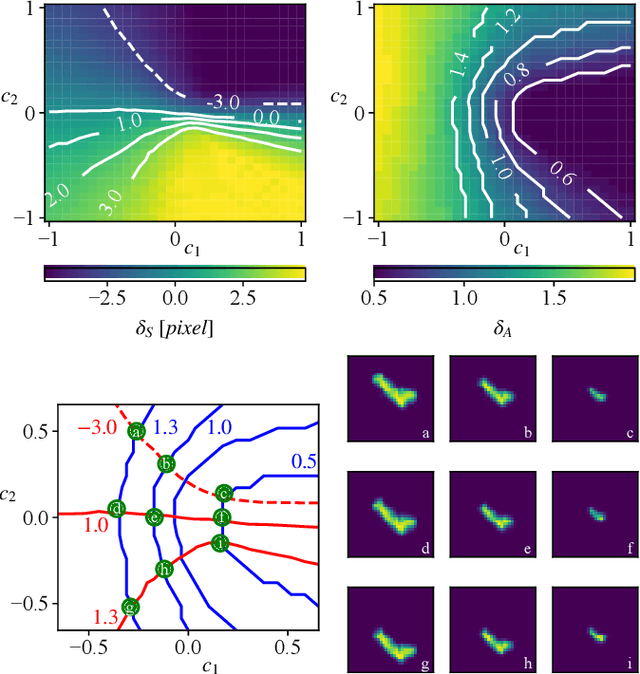
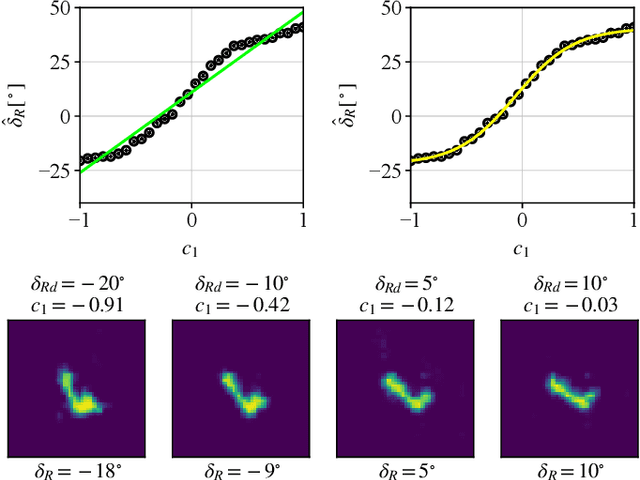
Generative Adversarial Networks (GANs) can synthesize abundant photo-realistic synthetic aperture radar (SAR) images. Some recent GANs (e.g., InfoGAN), are even able to edit specific properties of the synthesized images by introducing latent codes. It is crucial for SAR image synthesis since the targets in real SAR images are with different properties due to the imaging mechanism. Despite the success of InfoGAN in manipulating properties, there still lacks a clear explanation of how these latent codes affect synthesized properties, thus editing specific properties usually relies on empirical trials, unreliable and time-consuming. In this paper, we show that latent codes are disentangled to affect the properties of SAR images in a non-linear manner. By introducing some property estimators for latent codes, we are able to provide a completely analytical nonlinear model to decompose the entangled causality between latent codes and different properties. The qualitative and quantitative experimental results further reveal that the properties can be calculated by latent codes, inversely, the satisfying latent codes can be estimated given desired properties. In this case, properties can be manipulated by latent codes as we expect.
Learning from Multiple Expert Annotators for Enhancing Anomaly Detection in Medical Image Analysis
Mar 20, 2022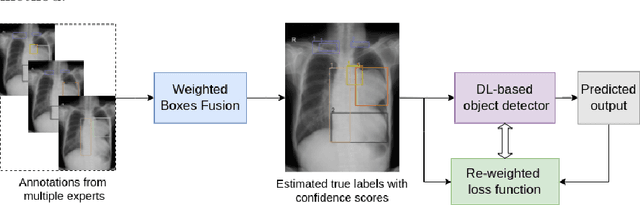
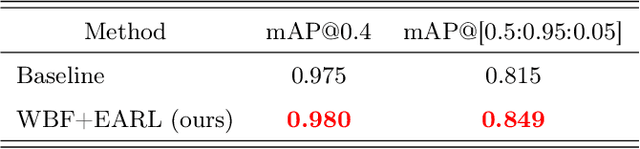
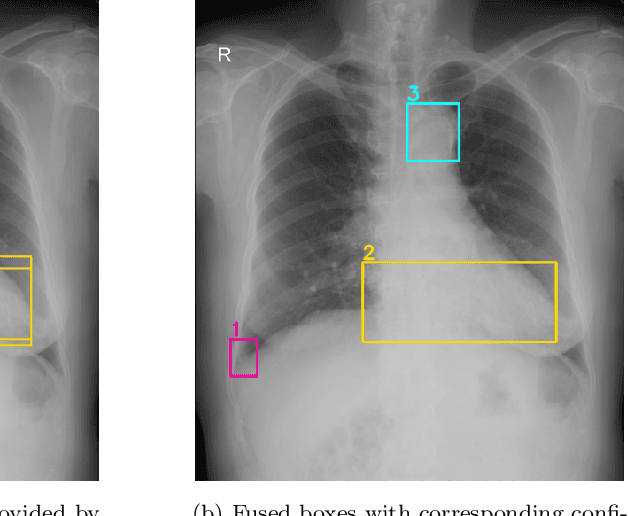
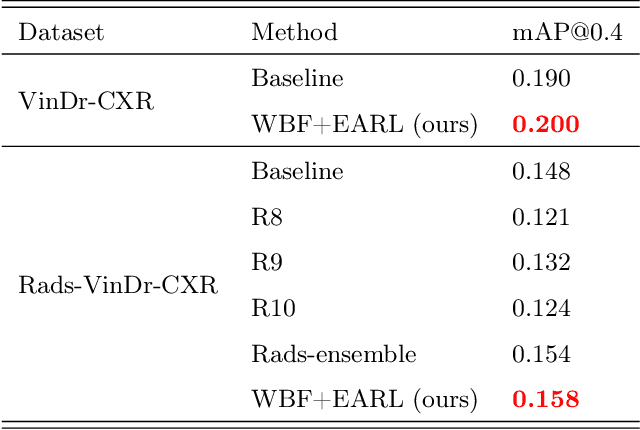
Building an accurate computer-aided diagnosis system based on data-driven approaches requires a large amount of high-quality labeled data. In medical imaging analysis, multiple expert annotators often produce subjective estimates about "ground truth labels" during the annotation process, depending on their expertise and experience. As a result, the labeled data may contain a variety of human biases with a high rate of disagreement among annotators, which significantly affect the performance of supervised machine learning algorithms. To tackle this challenge, we propose a simple yet effective approach to combine annotations from multiple radiology experts for training a deep learning-based detector that aims to detect abnormalities on medical scans. The proposed method first estimates the ground truth annotations and confidence scores of training examples. The estimated annotations and their scores are then used to train a deep learning detector with a re-weighted loss function to localize abnormal findings. We conduct an extensive experimental evaluation of the proposed approach on both simulated and real-world medical imaging datasets. The experimental results show that our approach significantly outperforms baseline approaches that do not consider the disagreements among annotators, including methods in which all of the noisy annotations are treated equally as ground truth and the ensemble of different models trained on different label sets provided separately by annotators.
CA-UDA: Class-Aware Unsupervised Domain Adaptation with Optimal Assignment and Pseudo-Label Refinement
May 30, 2022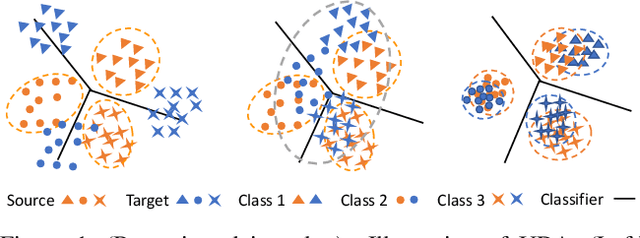
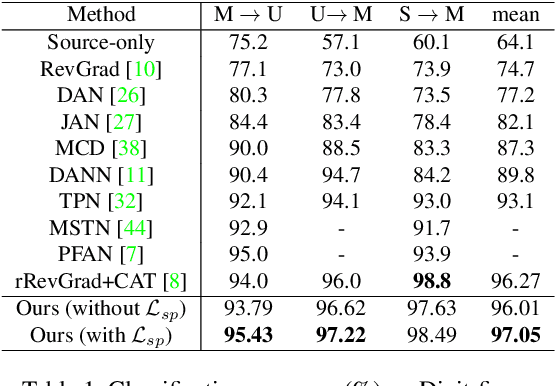
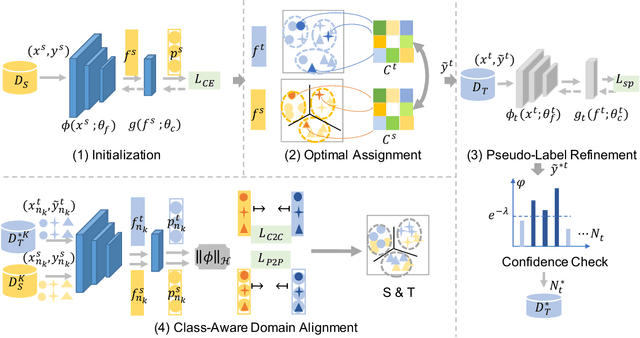
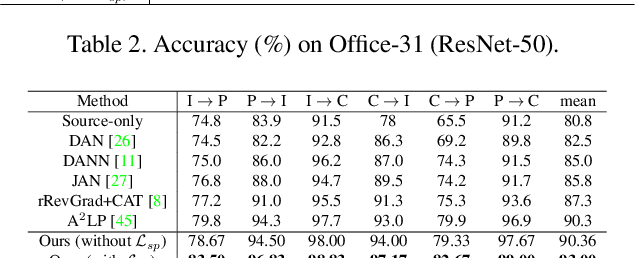
Recent works on unsupervised domain adaptation (UDA) focus on the selection of good pseudo-labels as surrogates for the missing labels in the target data. However, source domain bias that deteriorates the pseudo-labels can still exist since the shared network of the source and target domains are typically used for the pseudo-label selections. The suboptimal feature space source-to-target domain alignment can also result in unsatisfactory performance. In this paper, we propose CA-UDA to improve the quality of the pseudo-labels and UDA results with optimal assignment, a pseudo-label refinement strategy and class-aware domain alignment. We use an auxiliary network to mitigate the source domain bias for pseudo-label refinement. Our intuition is that the underlying semantics in the target domain can be fully exploited to help refine the pseudo-labels that are inferred from the source features under domain shift. Furthermore, our optimal assignment can optimally align features in the source-to-target domains and our class-aware domain alignment can simultaneously close the domain gap while preserving the classification decision boundaries. Extensive experiments on several benchmark datasets show that our method can achieve state-of-the-art performance in the image classification task.
A Deep Learning based No-reference Quality Assessment Model for UGC Videos
Apr 29, 2022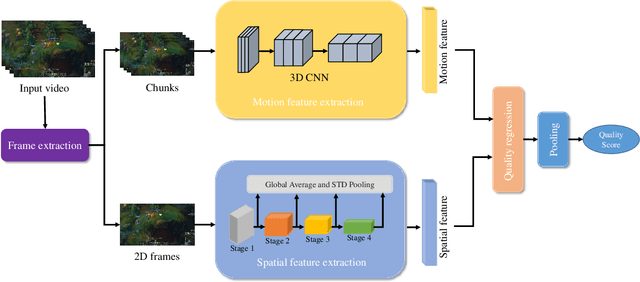

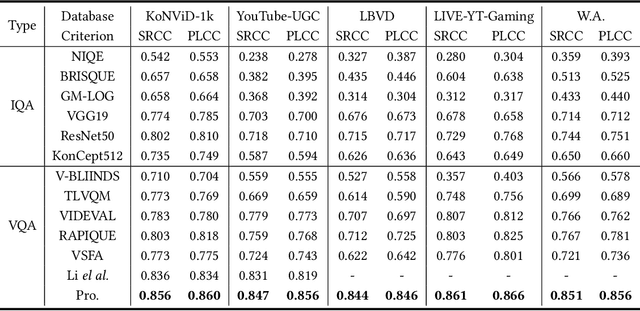
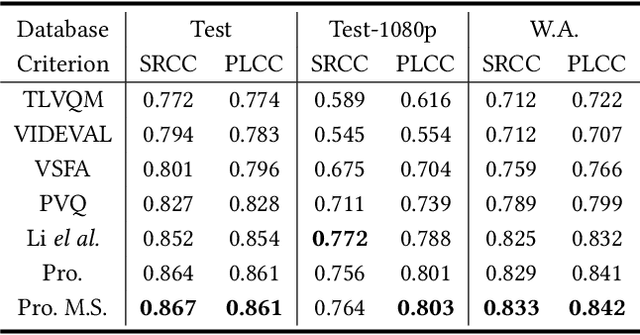
Quality assessment for User Generated Content (UGC) videos plays an important role in ensuring the viewing experience of end-users. Previous UGC video quality assessment (VQA) studies either use the image recognition model or the image quality assessment (IQA) models to extract frame-level features of UGC videos for quality regression, which are regarded as the sub-optimal solutions because of the domain shifts between these tasks and the UGC VQA task. In this paper, we propose a very simple but effective UGC VQA model, which tries to address this problem by training an end-to-end spatial feature extraction network to directly learn the quality-aware spatial feature representation from raw pixels of the video frames. We also extract the motion features to measure the temporal-related distortions that the spatial features cannot model. The proposed model utilizes very sparse frames to extract spatial features and dense frames (i.e. the video chunk) with a very low spatial resolution to extract motion features, which thereby has low computational complexity. With the better quality-aware features, we only use the simple multilayer perception layer (MLP) network to regress them into the chunk-level quality scores, and then the temporal average pooling strategy is adopted to obtain the video-level quality score. We further introduce a multi-scale quality fusion strategy to solve the problem of VQA across different spatial resolutions, where the multi-scale weights are obtained from the contrast sensitivity function of the human visual system. The experimental results show that the proposed model achieves the best performance on five popular UGC VQA databases, which demonstrates the effectiveness of the proposed model. The code will be publicly available.
Unraveling Attention via Convex Duality: Analysis and Interpretations of Vision Transformers
May 17, 2022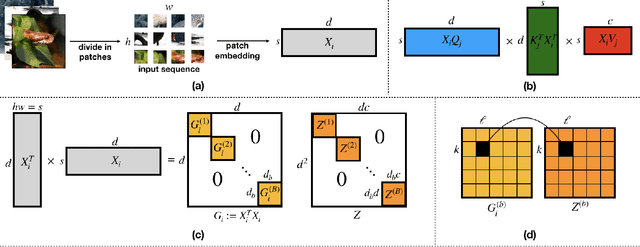
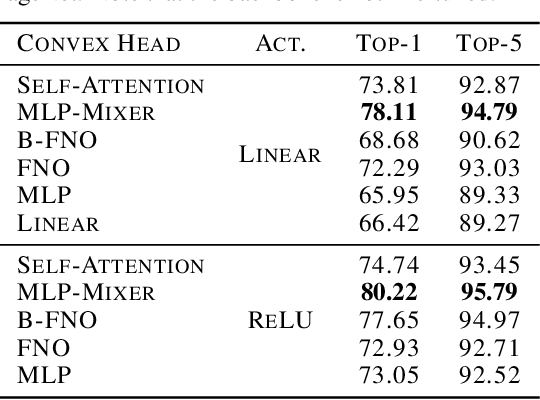
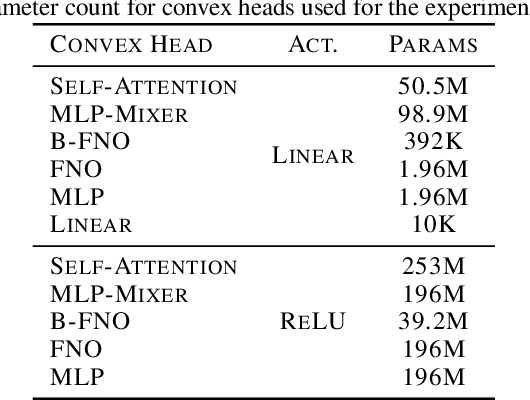
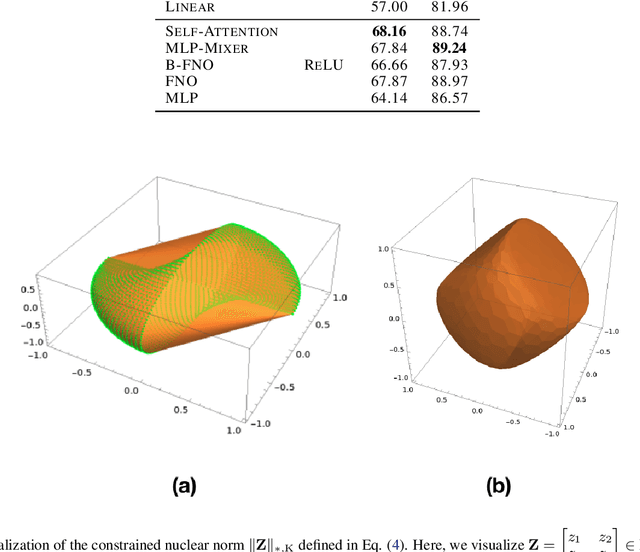
Vision transformers using self-attention or its proposed alternatives have demonstrated promising results in many image related tasks. However, the underpinning inductive bias of attention is not well understood. To address this issue, this paper analyzes attention through the lens of convex duality. For the non-linear dot-product self-attention, and alternative mechanisms such as MLP-mixer and Fourier Neural Operator (FNO), we derive equivalent finite-dimensional convex problems that are interpretable and solvable to global optimality. The convex programs lead to {\it block nuclear-norm regularization} that promotes low rank in the latent feature and token dimensions. In particular, we show how self-attention networks implicitly clusters the tokens, based on their latent similarity. We conduct experiments for transferring a pre-trained transformer backbone for CIFAR-100 classification by fine-tuning a variety of convex attention heads. The results indicate the merits of the bias induced by attention compared with the existing MLP or linear heads.
Self-Organized Variational Autoencoders (Self-VAE) for Learned Image Compression
May 28, 2021
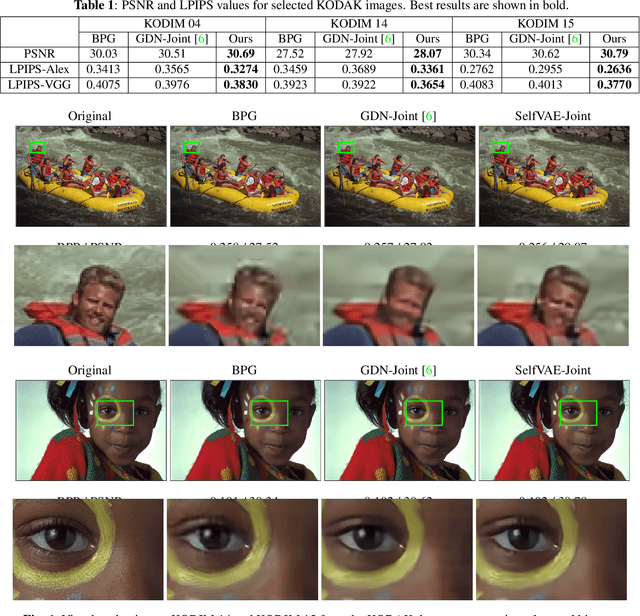
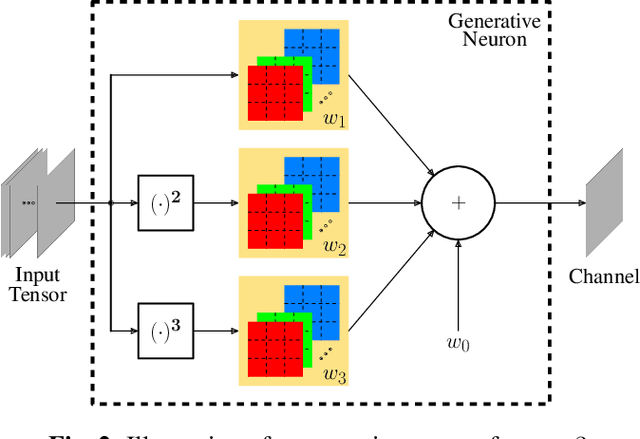
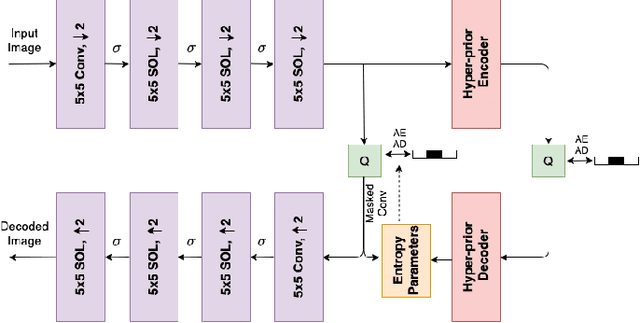
In end-to-end optimized learned image compression, it is standard practice to use a convolutional variational autoencoder with generalized divisive normalization (GDN) to transform images into a latent space. Recently, Operational Neural Networks (ONNs) that learn the best non-linearity from a set of alternatives, and their self-organized variants, Self-ONNs, that approximate any non-linearity via Taylor series have been proposed to address the limitations of convolutional layers and a fixed nonlinear activation. In this paper, we propose to replace the convolutional and GDN layers in the variational autoencoder with self-organized operational layers, and propose a novel self-organized variational autoencoder (Self-VAE) architecture that benefits from stronger non-linearity. The experimental results demonstrate that the proposed Self-VAE yields improvements in both rate-distortion performance and perceptual image quality.
MVP: Multimodality-guided Visual Pre-training
Mar 10, 2022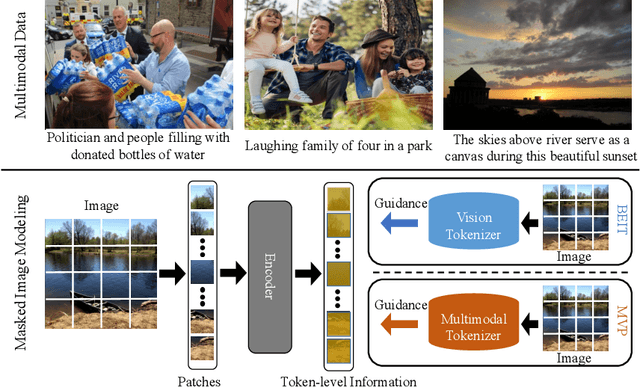
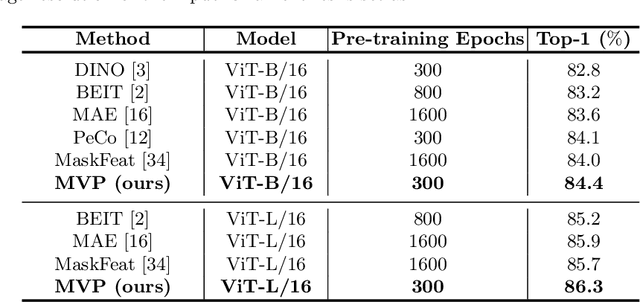
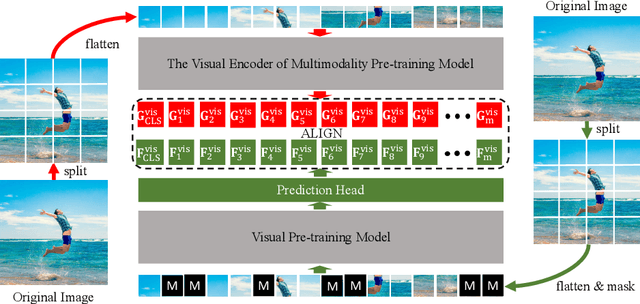
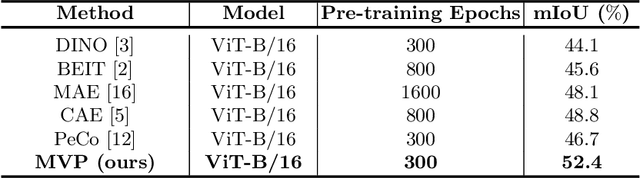
Recently, masked image modeling (MIM) has become a promising direction for visual pre-training. In the context of vision transformers, MIM learns effective visual representation by aligning the token-level features with a pre-defined space (e.g., BEIT used a d-VAE trained on a large image corpus as the tokenizer). In this paper, we go one step further by introducing guidance from other modalities and validating that such additional knowledge leads to impressive gains for visual pre-training. The proposed approach is named Multimodality-guided Visual Pre-training (MVP), in which we replace the tokenizer with the vision branch of CLIP, a vision-language model pre-trained on 400 million image-text pairs. We demonstrate the effectiveness of MVP by performing standard experiments, i.e., pre-training the ViT models on ImageNet and fine-tuning them on a series of downstream visual recognition tasks. In particular, pre-training ViT-Base/16 for 300 epochs, MVP reports a 52.4% mIoU on ADE20K, surpassing BEIT (the baseline and previous state-of-the-art) with an impressive margin of 6.8%.
Augmentation-induced Consistency Regularization for Classification
May 26, 2022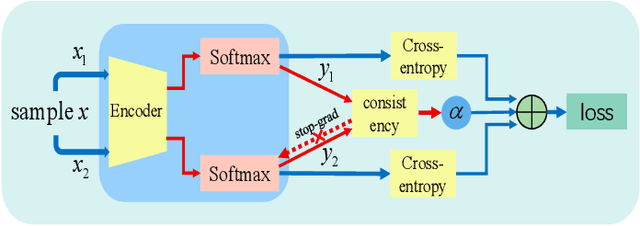
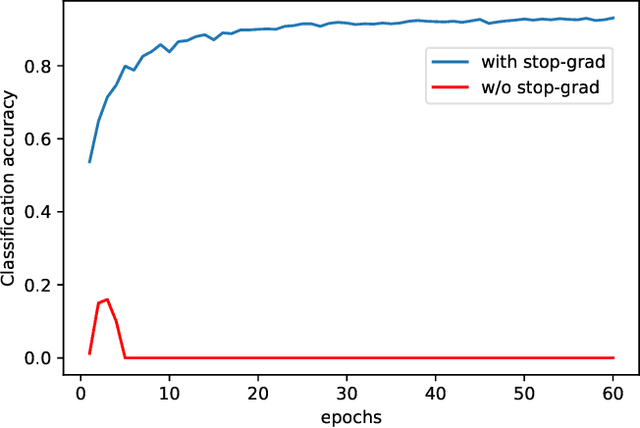
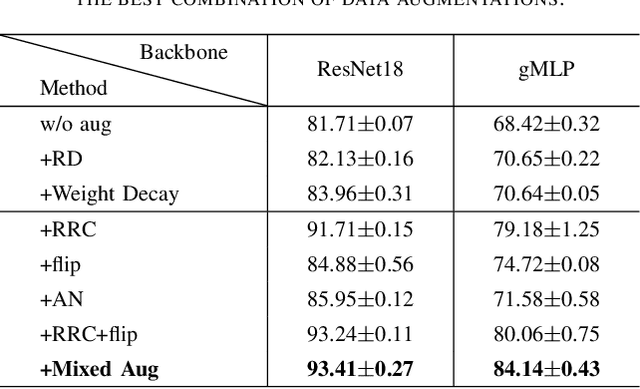
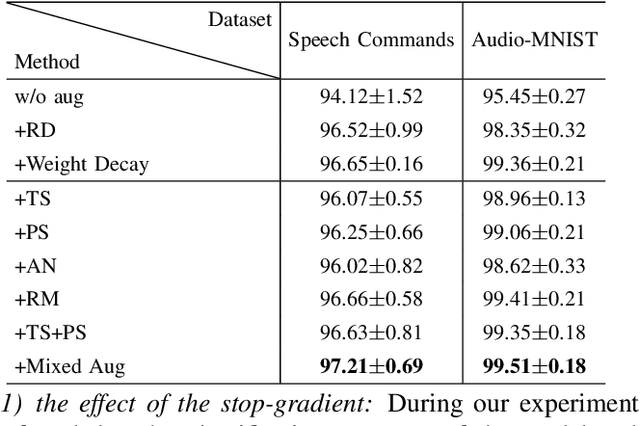
Deep neural networks have become popular in many supervised learning tasks, but they may suffer from overfitting when the training dataset is limited. To mitigate this, many researchers use data augmentation, which is a widely used and effective method for increasing the variety of datasets. However, the randomness introduced by data augmentation causes inevitable inconsistency between training and inference, which leads to poor improvement. In this paper, we propose a consistency regularization framework based on data augmentation, called CR-Aug, which forces the output distributions of different sub models generated by data augmentation to be consistent with each other. Specifically, CR-Aug evaluates the discrepancy between the output distributions of two augmented versions of each sample, and it utilizes a stop-gradient operation to minimize the consistency loss. We implement CR-Aug to image and audio classification tasks and conduct extensive experiments to verify its effectiveness in improving the generalization ability of classifiers. Our CR-Aug framework is ready-to-use, it can be easily adapted to many state-of-the-art network architectures. Our empirical results show that CR-Aug outperforms baseline methods by a significant margin.
Photographic Visualization of Weather Forecasts with Generative Adversarial Networks
Mar 29, 2022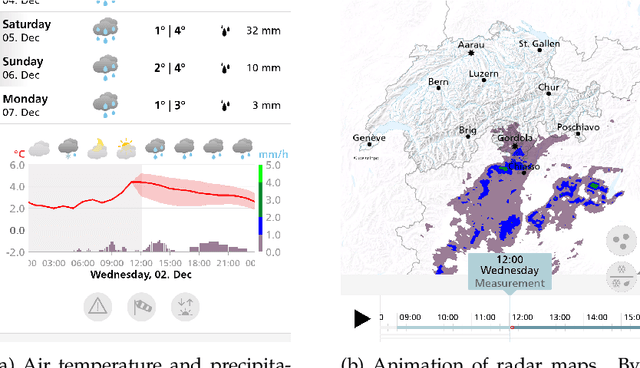
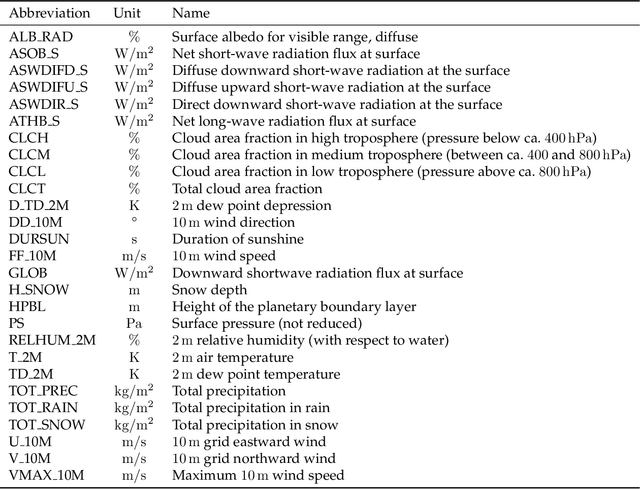


Outdoor webcam images are an information-dense yet accessible visualization of past and present weather conditions, and are consulted by meteorologists and the general public alike. Weather forecasts, however, are still communicated as text, pictograms or charts. We therefore introduce a novel method that uses photographic images to also visualize future weather conditions. This is challenging, because photographic visualizations of weather forecasts should look real, be free of obvious artifacts, and should match the predicted weather conditions. The transition from observation to forecast should be seamless, and there should be visual continuity between images for consecutive lead times. We use conditional Generative Adversarial Networks to synthesize such visualizations. The generator network, conditioned on the analysis and the forecasting state of the numerical weather prediction (NWP) model, transforms the present camera image into the future. The discriminator network judges whether a given image is the real image of the future, or whether it has been synthesized. Training the two networks against each other results in a visualization method that scores well on all four evaluation criteria. We present results for three camera sites across Switzerland that differ in climatology and terrain. We show that users find it challenging to distinguish real from generated images, performing not much better than if they guessed randomly. The generated images match the atmospheric, ground and illumination conditions of the COSMO-1 NWP model forecast in at least 89 % of the examined cases. Nowcasting sequences of generated images achieve a seamless transition from observation to forecast and attain visual continuity.
Blind microscopy image denoising with a deep residual and multiscale encoder/decoder network
May 01, 2021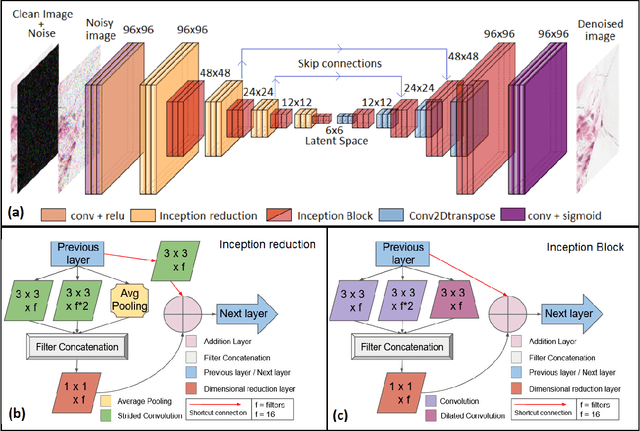
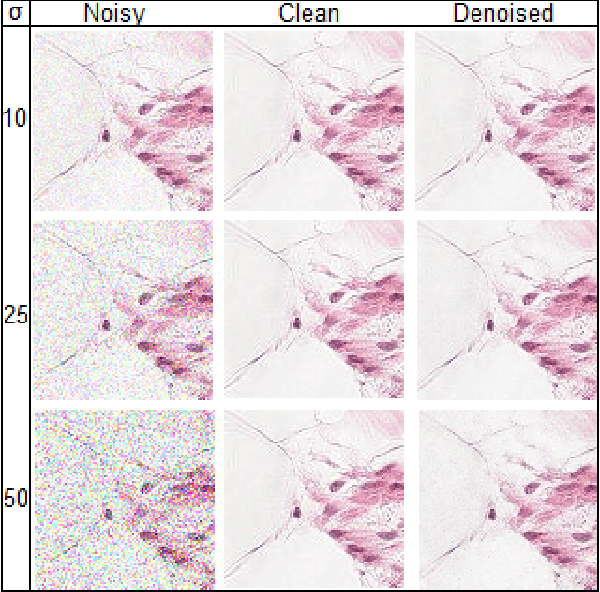
In computer-aided diagnosis (CAD) focused on microscopy, denoising improves the quality of image analysis. In general, the accuracy of this process may depend both on the experience of the microscopist and on the equipment sensitivity and specificity. A medical image could be corrupted by both intrinsic noise, due to the device limitations, and, by extrinsic signal perturbations during image acquisition. Nowadays, CAD deep learning applications pre-process images with image denoising models to reinforce learning and prediction. In this work, an innovative and lightweight deep multiscale convolutional encoder-decoder neural network is proposed. Specifically, the encoder uses deterministic mapping to map features into a hidden representation. Then, the latent representation is rebuilt to generate the reconstructed denoised image. Residual learning strategies are used to improve and accelerate the training process using skip connections in bridging across convolutional and deconvolutional layers. The proposed model reaches on average 38.38 of PSNR and 0.98 of SSIM on a test set of 57458 images overcoming state-of-the-art models in the same application domain