 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Consistency driven Sequential Transformers Attention Model for Partially Observable Scenes
Apr 01, 2022
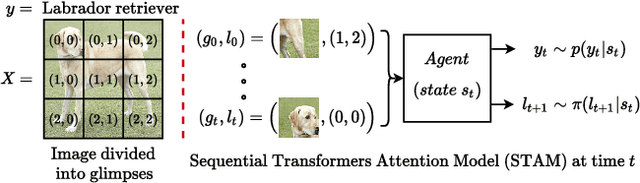
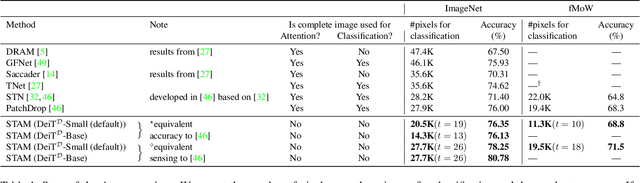
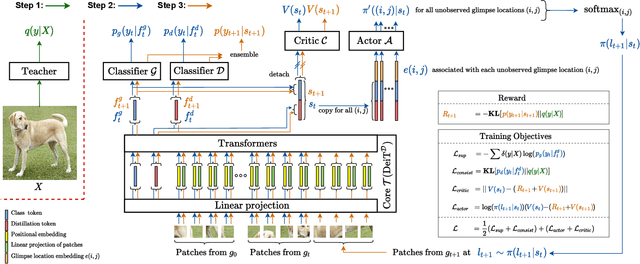
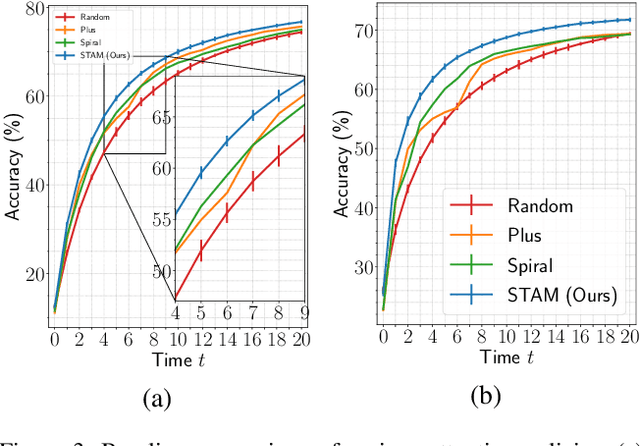
Most hard attention models initially observe a complete scene to locate and sense informative glimpses, and predict class-label of a scene based on glimpses. However, in many applications (e.g., aerial imaging), observing an entire scene is not always feasible due to the limited time and resources available for acquisition. In this paper, we develop a Sequential Transformers Attention Model (STAM) that only partially observes a complete image and predicts informative glimpse locations solely based on past glimpses. We design our agent using DeiT-distilled and train it with a one-step actor-critic algorithm. Furthermore, to improve classification performance, we introduce a novel training objective, which enforces consistency between the class distribution predicted by a teacher model from a complete image and the class distribution predicted by our agent using glimpses. When the agent senses only 4% of the total image area, the inclusion of the proposed consistency loss in our training objective yields 3% and 8% higher accuracy on ImageNet and fMoW datasets, respectively. Moreover, our agent outperforms previous state-of-the-art by observing nearly 27% and 42% fewer pixels in glimpses on ImageNet and fMoW.
Transductive image segmentation: Self-training and effect of uncertainty estimation
Jul 19, 2021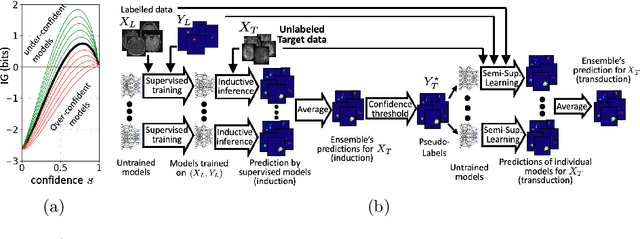

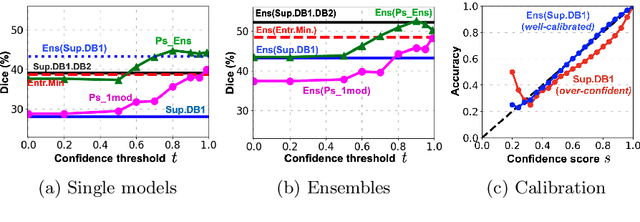
Semi-supervised learning (SSL) uses unlabeled data during training to learn better models. Previous studies on SSL for medical image segmentation focused mostly on improving model generalization to unseen data. In some applications, however, our primary interest is not generalization but to obtain optimal predictions on a specific unlabeled database that is fully available during model development. Examples include population studies for extracting imaging phenotypes. This work investigates an often overlooked aspect of SSL, transduction. It focuses on the quality of predictions made on the unlabeled data of interest when they are included for optimization during training, rather than improving generalization. We focus on the self-training framework and explore its potential for transduction. We analyze it through the lens of Information Gain and reveal that learning benefits from the use of calibrated or under-confident models. Our extensive experiments on a large MRI database for multi-class segmentation of traumatic brain lesions shows promising results when comparing transductive with inductive predictions. We believe this study will inspire further research on transductive learning, a well-suited paradigm for medical image analysis.
A Dense Siamese U-Net trained with Edge Enhanced 3D IOU Loss for Image Co-segmentation
Aug 17, 2021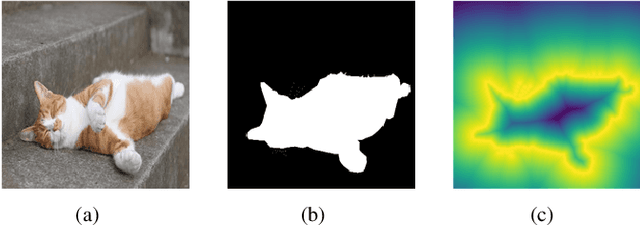
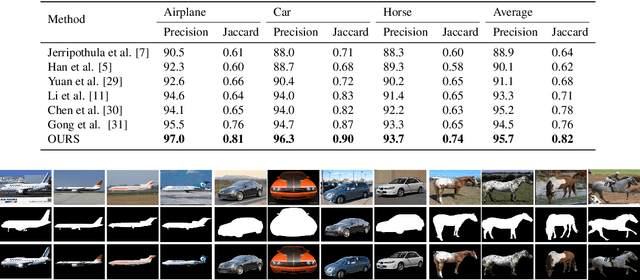
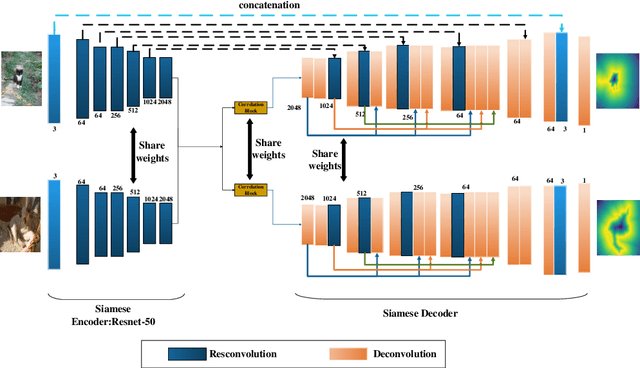
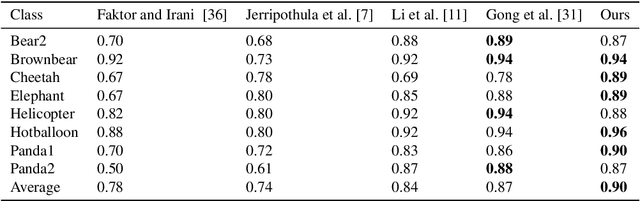
Image co-segmentation has attracted a lot of attentions in computer vision community. In this paper, we propose a new approach to image co-segmentation through introducing the dense connections into the decoder path of Siamese U-net and presenting a new edge enhanced 3D IOU loss measured over distance maps. Considering the rigorous mapping between the signed normalized distance map (SNDM) and the binary segmentation mask, we estimate the SNDMs directly from original images and use them to determine the segmentation results. We apply the Siamese U-net for solving this problem and improve its effectiveness by densely connecting each layer with subsequent layers in the decoder path. Furthermore, a new learning loss is designed to measure the 3D intersection over union (IOU) between the generated SNDMs and the labeled SNDMs. The experimental results on commonly used datasets for image co-segmentation demonstrate the effectiveness of our presented dense structure and edge enhanced 3D IOU loss of SNDM. To our best knowledge, they lead to the state-of-the-art performance on the Internet and iCoseg datasets.
Analysis of Diffractive Neural Networks for Seeing Through Random Diffusers
May 01, 2022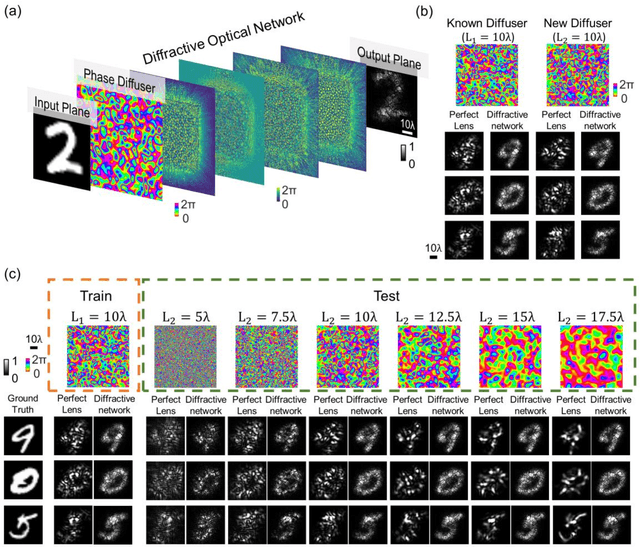
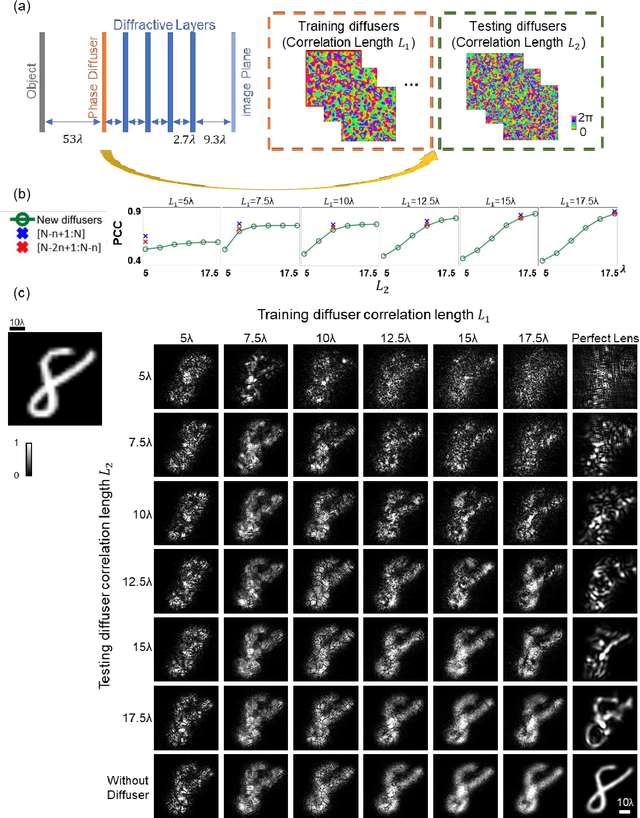
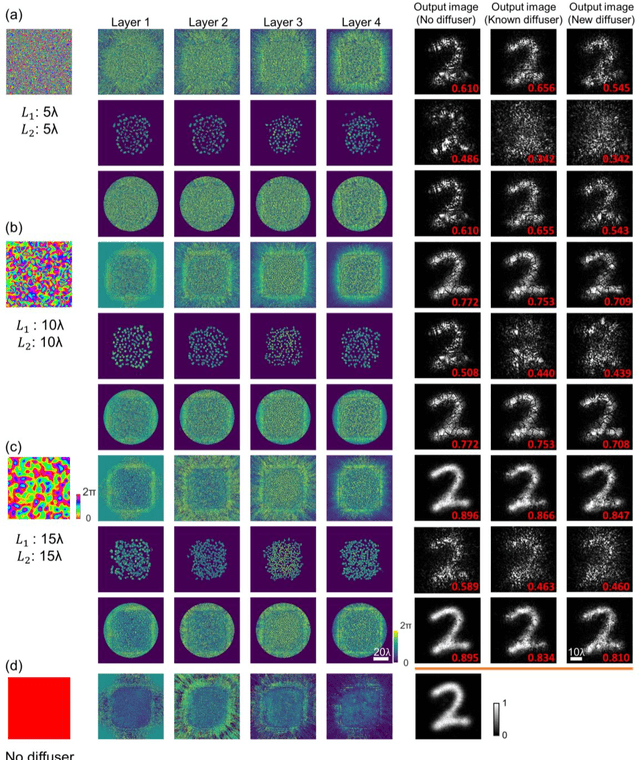
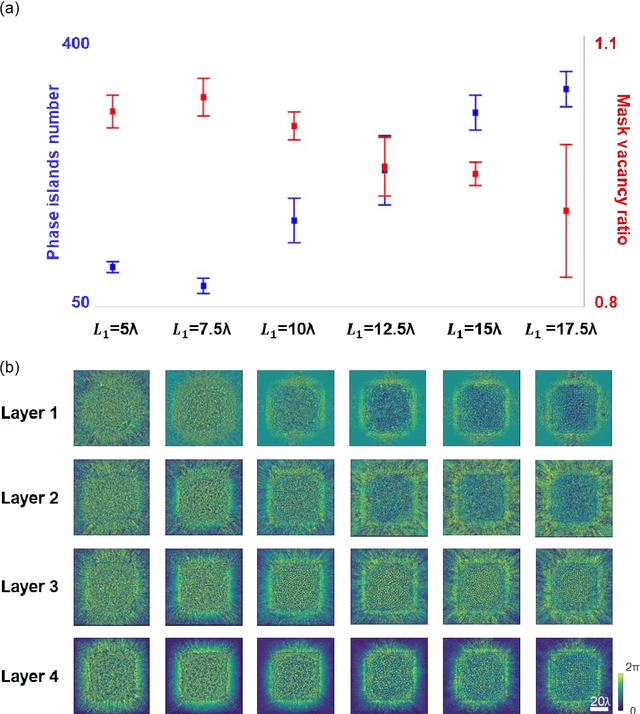
Imaging through diffusive media is a challenging problem, where the existing solutions heavily rely on digital computers to reconstruct distorted images. We provide a detailed analysis of a computer-free, all-optical imaging method for seeing through random, unknown phase diffusers using diffractive neural networks, covering different deep learning-based training strategies. By analyzing various diffractive networks designed to image through random diffusers with different correlation lengths, a trade-off between the image reconstruction fidelity and distortion reduction capability of the diffractive network was observed. During its training, random diffusers with a range of correlation lengths were used to improve the diffractive network's generalization performance. Increasing the number of random diffusers used in each epoch reduced the overfitting of the diffractive network's imaging performance to known diffusers. We also demonstrated that the use of additional diffractive layers improved the generalization capability to see through new, random diffusers. Finally, we introduced deliberate misalignments in training to 'vaccinate' the network against random layer-to-layer shifts that might arise due to the imperfect assembly of the diffractive networks. These analyses provide a comprehensive guide in designing diffractive networks to see through random diffusers, which might profoundly impact many fields, such as biomedical imaging, atmospheric physics, and autonomous driving.
Semi-parametric Makeup Transfer via Semantic-aware Correspondence
Mar 04, 2022
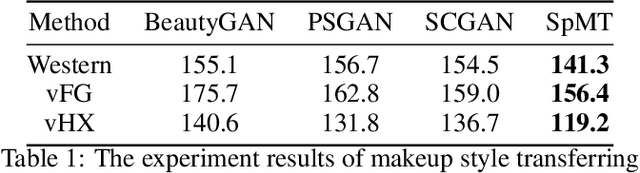
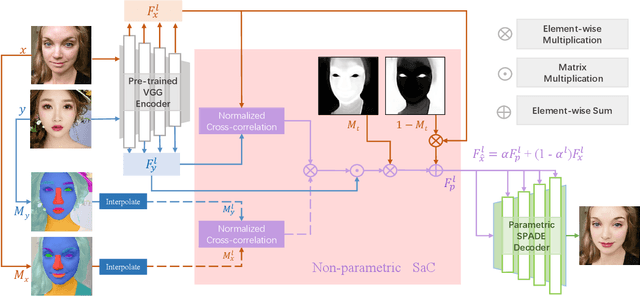
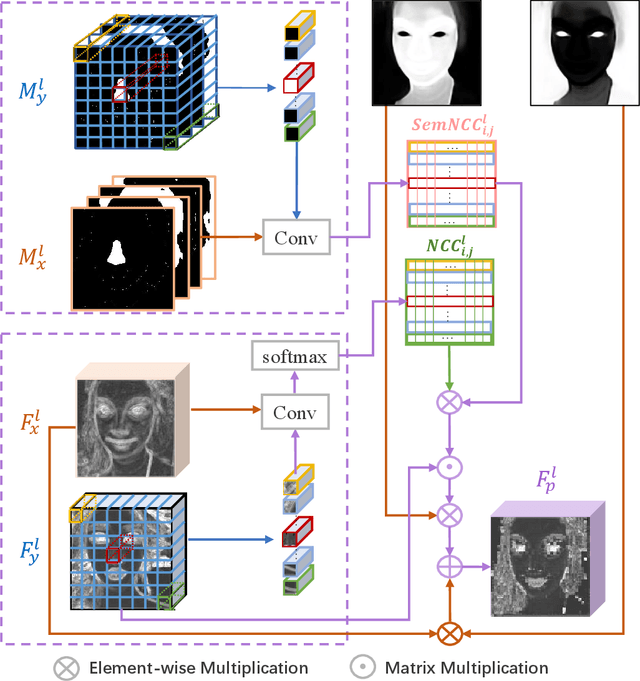
The large discrepancy between the source non-makeup image and the reference makeup image is one of the key challenges in makeup transfer. Conventional approaches for makeup transfer either learn disentangled representation or perform pixel-wise correspondence in a parametric way between two images. We argue that non-parametric techniques have a high potential for addressing the pose, expression, and occlusion discrepancies. To this end, this paper proposes a \textbf{S}emi-\textbf{p}arametric \textbf{M}akeup \textbf{T}ransfer (SpMT) method, which combines the reciprocal strengths of non-parametric and parametric mechanisms. The non-parametric component is a novel \textbf{S}emantic-\textbf{a}ware \textbf{C}orrespondence (SaC) module that explicitly reconstructs content representation with makeup representation under the strong constraint of component semantics. The reconstructed representation is desired to preserve the spatial and identity information of the source image while "wearing" the makeup of the reference image. The output image is synthesized via a parametric decoder that draws on the reconstructed representation. Extensive experiments demonstrate the superiority of our method in terms of visual quality, robustness, and flexibility. Code and pre-trained model are available at \url{https://github.com/AnonymScholar/SpMT.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022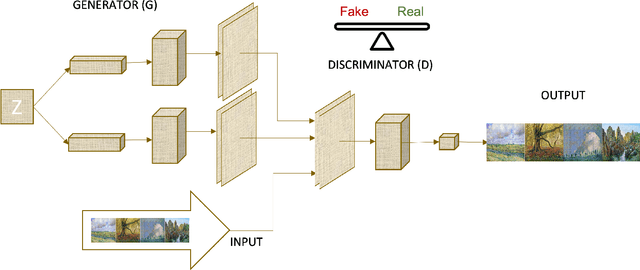


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
Weakly Supervised Volumetric Image Segmentation with Deformed Templates
Jun 07, 2021



There are many approaches that use weak-supervision to train networks to segment 2D images. By contrast, existing 3D approaches rely on full-supervision of a subset of 2D slices of the 3D image volume. In this paper, we propose an approach that is truly weakly-supervised in the sense that we only need to provide a sparse set of 3D point on the surface of target objects, an easy task that can be quickly done. We use the 3D points to deform a 3D template so that it roughly matches the target object outlines and we introduce an architecture that exploits the supervision provided by coarse template to train a network to find accurate boundaries. We evaluate the performance of our approach on Computed Tomography (CT), Magnetic Resonance Imagery (MRI) and Electron Microscopy (EM) image datasets. We will show that it outperforms a more traditional approach to weak-supervision in 3D at a reduced supervision cost.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 28, 2021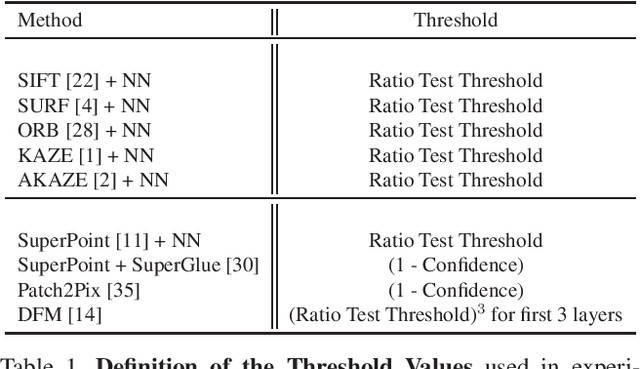
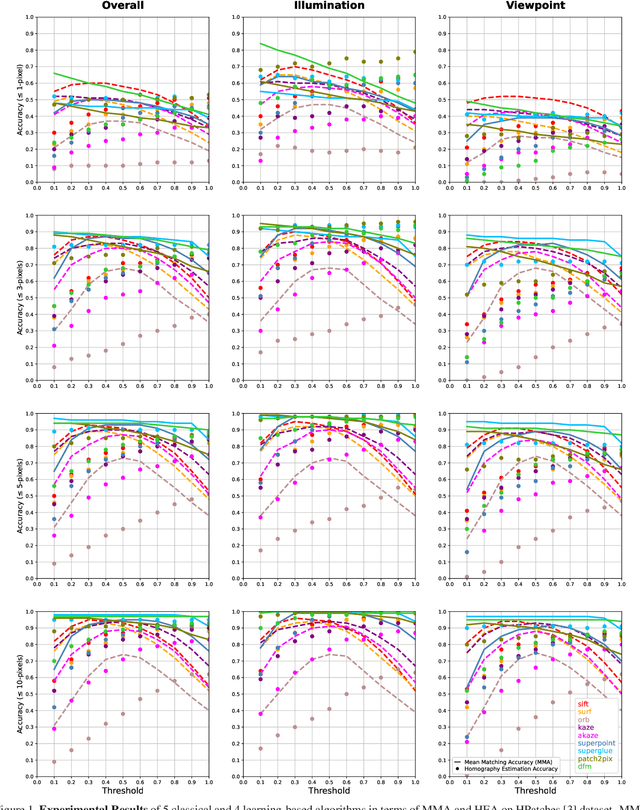
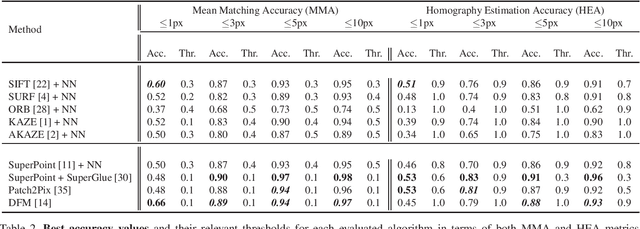
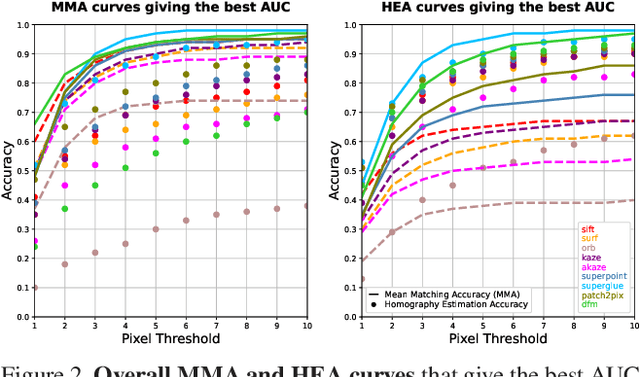
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.
Exemplar Free Class Agnostic Counting
May 27, 2022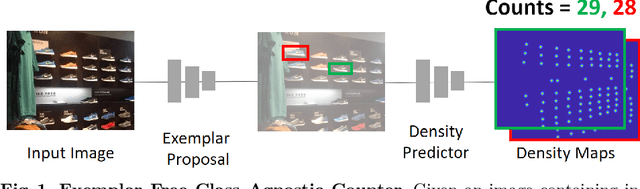
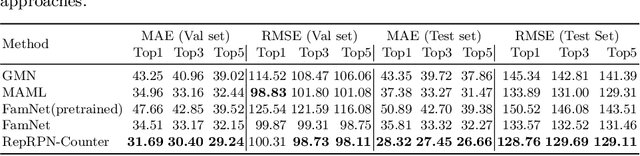
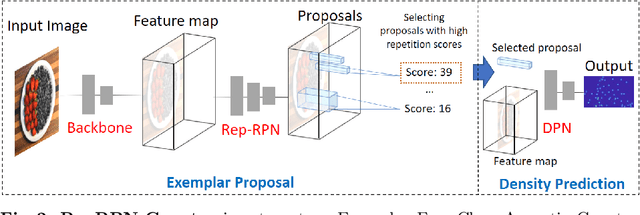
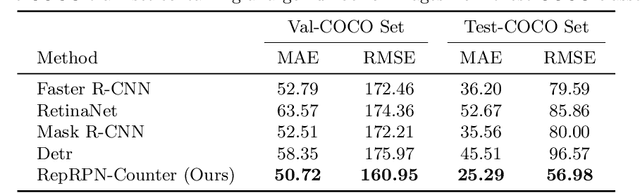
We tackle the task of Class Agnostic Counting, which aims to count objects in a novel object category at test time without any access to labeled training data for that category. All previous class agnostic counting methods cannot work in a fully automated setting, and require computationally expensive test time adaptation. To address these challenges, we propose a visual counter which operates in a fully automated setting and does not require any test time adaptation. Our proposed approach first identifies exemplars from repeating objects in an image, and then counts the repeating objects. We propose a novel region proposal network for identifying the exemplars. After identifying the exemplars, we obtain the corresponding count by using a density estimation based Visual Counter. We evaluate our proposed approach on FSC-147 dataset, and show that it achieves superior performance compared to the existing approaches.
Comparison of convolutional neural networks for cloudy optical images reconstruction from single or multitemporal joint SAR and optical images
Apr 01, 2022

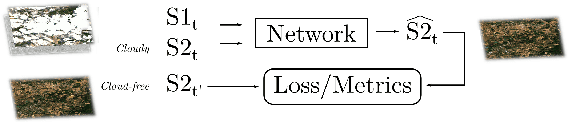
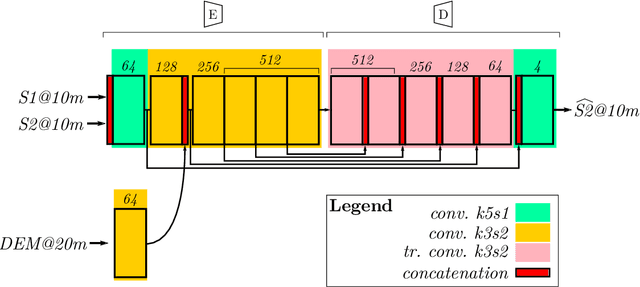
With the increasing availability of optical and synthetic aperture radar (SAR) images thanks to the Sentinel constellation, and the explosion of deep learning, new methods have emerged in recent years to tackle the reconstruction of optical images that are impacted by clouds. In this paper, we focus on the evaluation of convolutional neural networks that use jointly SAR and optical images to retrieve the missing contents in one single polluted optical image. We propose a simple framework that ease the creation of datasets for the training of deep nets targeting optical image reconstruction, and for the validation of machine learning based or deterministic approaches. These methods are quite different in terms of input images constraints, and comparing them is a problematic task not addressed in the literature. We show how space partitioning data structures help to query samples in terms of cloud coverage, relative acquisition date, pixel validity and relative proximity between SAR and optical images. We generate several datasets to compare the reconstructed images from networks that use a single pair of SAR and optical image, versus networks that use multiple pairs, and a traditional deterministic approach performing interpolation in temporal domain.