 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Minimal Path Method with Embedded CNN
Apr 05, 2022
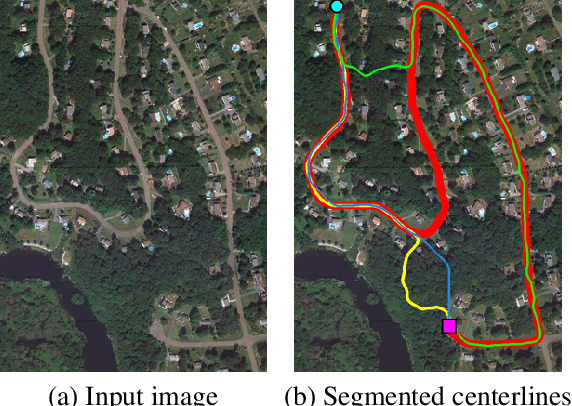
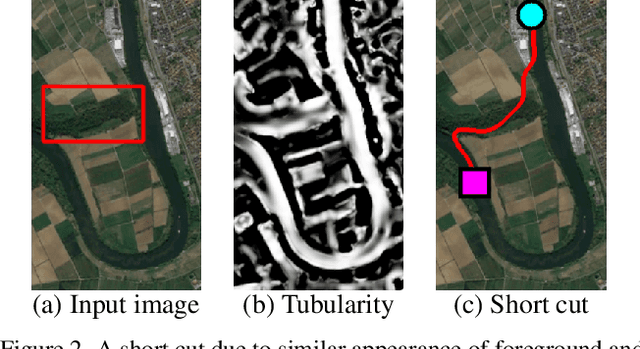

We propose Path-CNN, a method for the segmentation of centerlines of tubular structures by embedding convolutional neural networks (CNNs) into the progressive minimal path method. Minimal path methods are widely used for topology-aware centerline segmentation, but usually these methods rely on weak, hand-tuned image features. In contrast, CNNs use strong image features which are learned automatically from images. But CNNs usually do not take the topology of the results into account, and often require a large amount of annotations for training. We integrate CNNs into the minimal path method, so that both techniques benefit from each other: CNNs employ learned image features to improve the determination of minimal paths, while the minimal path method ensures the correct topology of the segmented centerlines, provides strong geometric priors to increase the performance of CNNs, and reduces the amount of annotations for the training of CNNs significantly. Our method has lower hardware requirements than many recent methods. Qualitative and quantitative comparison with other methods shows that Path-CNN achieves better performance, especially when dealing with tubular structures with complex shapes in challenging environments.
Learning the Effect of Registration Hyperparameters with HyperMorph
Mar 30, 2022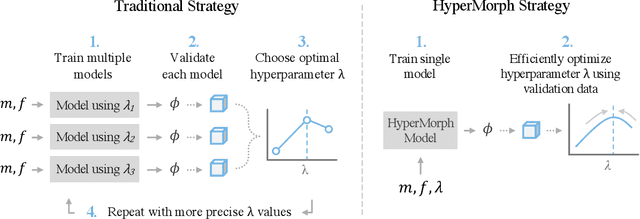
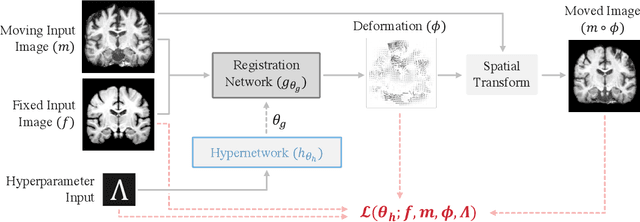

We introduce HyperMorph, a framework that facilitates efficient hyperparameter tuning in learning-based deformable image registration. Classical registration algorithms perform an iterative pair-wise optimization to compute a deformation field that aligns two images. Recent learning-based approaches leverage large image datasets to learn a function that rapidly estimates a deformation for a given image pair. In both strategies, the accuracy of the resulting spatial correspondences is strongly influenced by the choice of certain hyperparameter values. However, an effective hyperparameter search consumes substantial time and human effort as it often involves training multiple models for different fixed hyperparameter values and may lead to suboptimal registration. We propose an amortized hyperparameter learning strategy to alleviate this burden by learning the impact of hyperparameters on deformation fields. We design a meta network, or hypernetwork, that predicts the parameters of a registration network for input hyperparameters, thereby comprising a single model that generates the optimal deformation field corresponding to given hyperparameter values. This strategy enables fast, high-resolution hyperparameter search at test-time, reducing the inefficiency of traditional approaches while increasing flexibility. We also demonstrate additional benefits of HyperMorph, including enhanced robustness to model initialization and the ability to rapidly identify optimal hyperparameter values specific to a dataset, image contrast, task, or even anatomical region, all without the need to retrain models. We make our code publicly available at http://hypermorph.voxelmorph.net.
2-d signature of images and texture classification
May 10, 2022

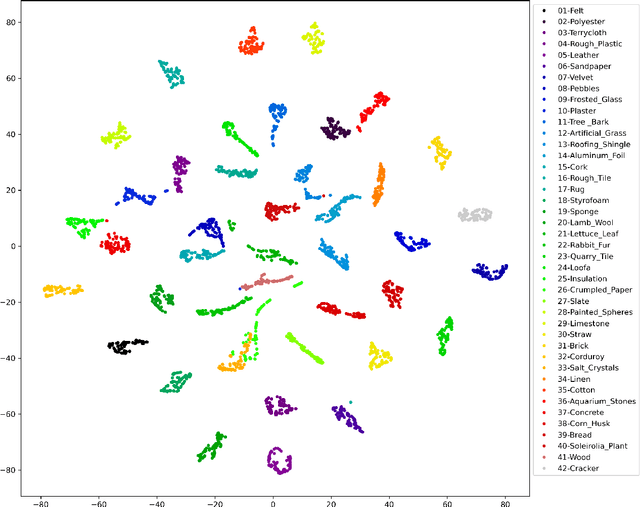
We introduce a proper notion of 2-dimensional signature for images. This object is inspired by the so-called rough paths theory, and it captures many essential features of a 2-dimensional object such as an image. It thus serves as a low-dimensional feature for pattern classification. Here we implement a simple procedure for texture classification. In this context, we show that a low dimensional set of features based on signatures produces an excellent accuracy.
Self-supervised Low Light Image Enhancement and Denoising
Mar 01, 2021
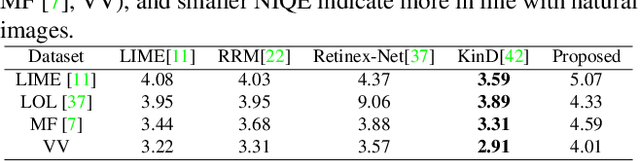
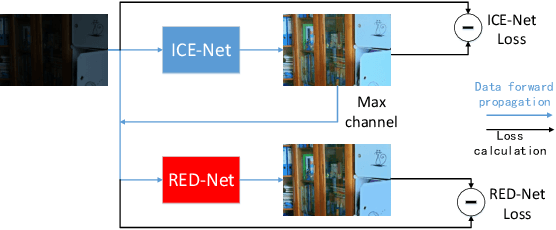
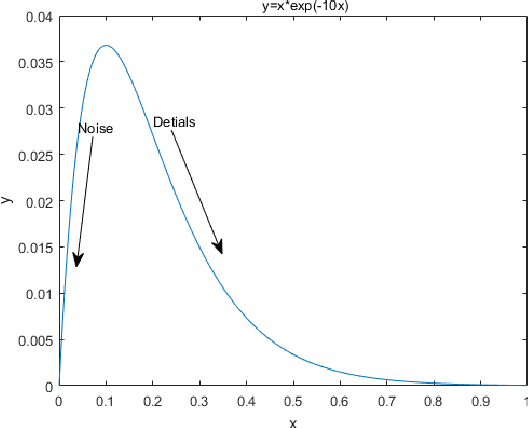
This paper proposes a self-supervised low light image enhancement method based on deep learning, which can improve the image contrast and reduce noise at the same time to avoid the blur caused by pre-/post-denoising. The method contains two deep sub-networks, an Image Contrast Enhancement Network (ICE-Net) and a Re-Enhancement and Denoising Network (RED-Net). The ICE-Net takes the low light image as input and produces a contrast enhanced image. The RED-Net takes the result of ICE-Net and the low light image as input, and can re-enhance the low light image and denoise at the same time. Both of the networks can be trained with low light images only, which is achieved by a Maximum Entropy based Retinex (ME-Retinex) model and an assumption that noises are independently distributed. In the ME-Retinex model, a new constraint on the reflectance image is introduced that the maximum channel of the reflectance image conforms to the maximum channel of the low light image and its entropy should be the largest, which converts the decomposition of reflectance and illumination in Retinex model to a non-ill-conditioned problem and allows the ICE-Net to be trained with a self-supervised way. The loss functions of RED-Net are carefully formulated to separate the noises and details during training, and they are based on the idea that, if noises are independently distributed, after the processing of smoothing filters (\eg mean filter), the gradient of the noise part should be smaller than the gradient of the detail part. It can be proved qualitatively and quantitatively through experiments that the proposed method is efficient.
Diffusion Models for Medical Anomaly Detection
Mar 08, 2022
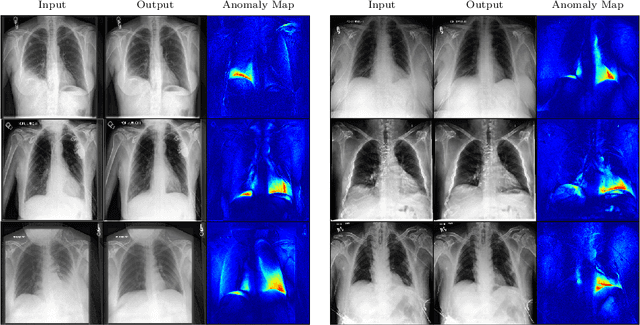
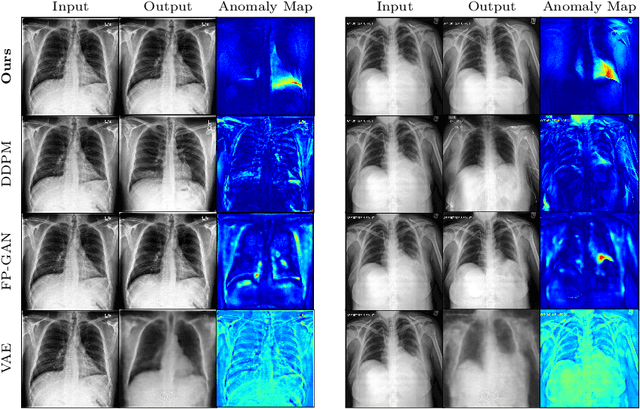
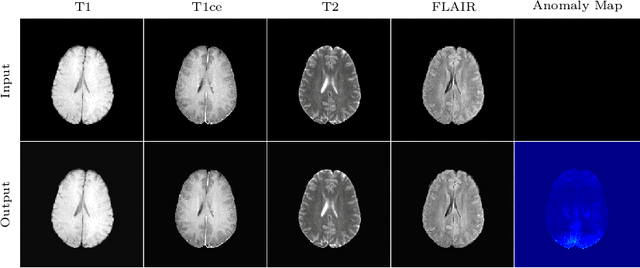
In medical applications, weakly supervised anomaly detection methods are of great interest, as only image-level annotations are required for training. Current anomaly detection methods mainly rely on generative adversarial networks or autoencoder models. Those models are often complicated to train or have difficulties to preserve fine details in the image. We present a novel weakly supervised anomaly detection method based on denoising diffusion implicit models. We combine the deterministic iterative noising and denoising scheme with classifier guidance for image-to-image translation between diseased and healthy subjects. Our method generates very detailed anomaly maps without the need for a complex training procedure. We evaluate our method on the BRATS2020 dataset for brain tumor detection and the CheXpert dataset for detecting pleural effusions.
Classical and learned MR to pseudo-CT mappings for accurate transcranial ultrasound simulation
Jun 30, 2022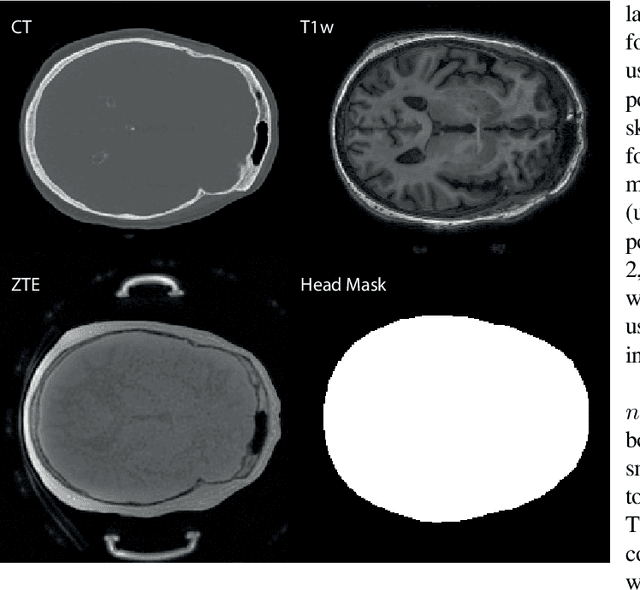
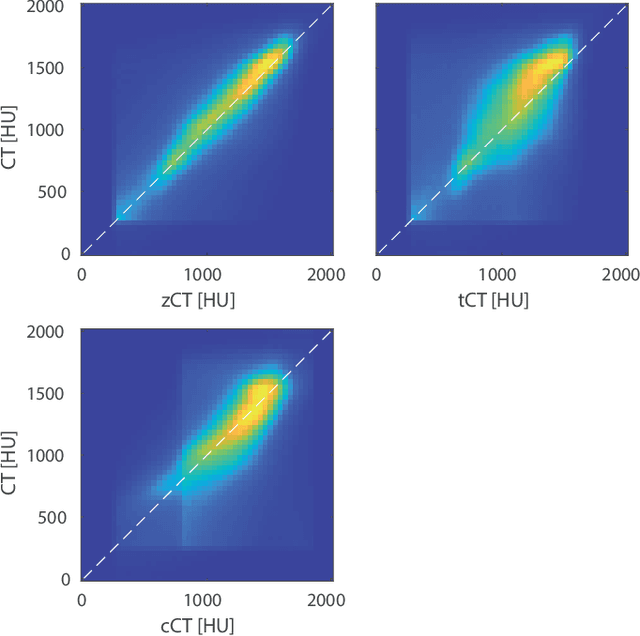
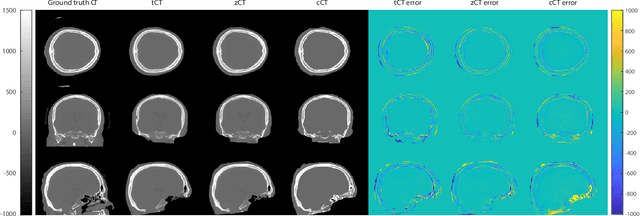
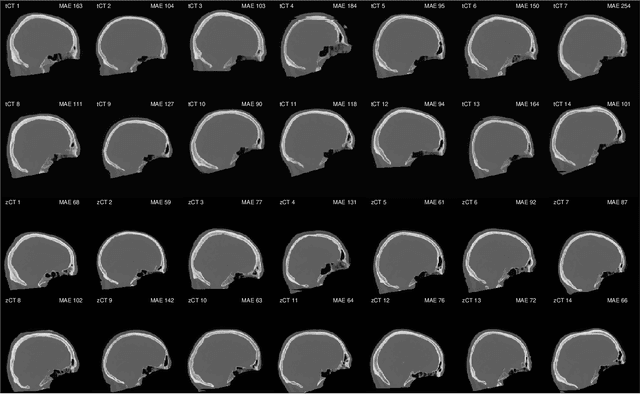
Model-based treatment planning for transcranial ultrasound therapy typically involves mapping the acoustic properties of the skull from an x-ray computed tomography (CT) image of the head. Here, three methods for generating pseudo-CT images from magnetic resonance (MR) images were compared as an alternative to CT. A convolutional neural network (U-Net) was trained on paired MR-CT images to generate pseudo-CT images from either T1-weighted or zero-echo time (ZTE) MR images (denoted tCT and zCT, respectively). A direct mapping from ZTE to pseudo-CT was also implemented (denoted cCT). When comparing the pseudo-CT and ground truth CT images for the test set, the mean absolute error was 133, 83, and 145 Hounsfield units (HU) across the whole head, and 398, 222, and 336 HU within the skull for the tCT, zCT, and cCT images, respectively. Ultrasound simulations were also performed using the generated pseudo-CT images and compared to simulations based on CT. An annular array transducer was used targeting the visual or motor cortex. The mean differences in the simulated focal pressure, focal position, and focal volume were 9.9%, 1.5 mm, and 15.1% for simulations based on the tCT images, 5.7%, 0.6 mm, and 5.7% for the zCT, and 6.7%, 0.9 mm, and 12.1% for the cCT. The improved results for images mapped from ZTE highlight the advantage of using imaging sequences which improve contrast of the skull bone. Overall, these results demonstrate that acoustic simulations based on MR images can give comparable accuracy to those based on CT.
Super-resolved multi-temporal segmentation with deep permutation-invariant networks
Apr 06, 2022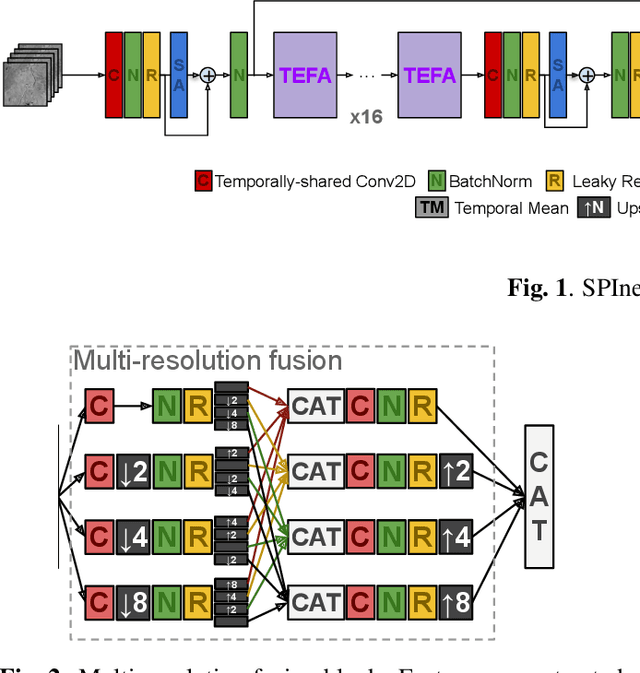
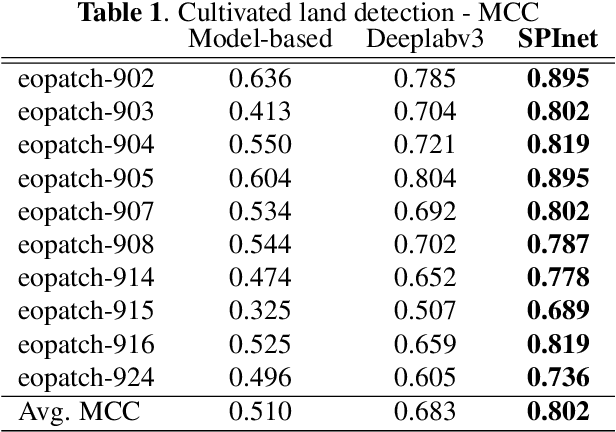


Multi-image super-resolution from multi-temporal satellite acquisitions of a scene has recently enjoyed great success thanks to new deep learning models. In this paper, we go beyond classic image reconstruction at a higher resolution by studying a super-resolved inference problem, namely semantic segmentation at a spatial resolution higher than the one of sensing platform. We expand upon recently proposed models exploiting temporal permutation invariance with a multi-resolution fusion module able to infer the rich semantic information needed by the segmentation task. The model presented in this paper has recently won the AI4EO challenge on Enhanced Sentinel 2 Agriculture.
Adaptively Sparse Regularization for Blind Image Restoration
Jan 23, 2021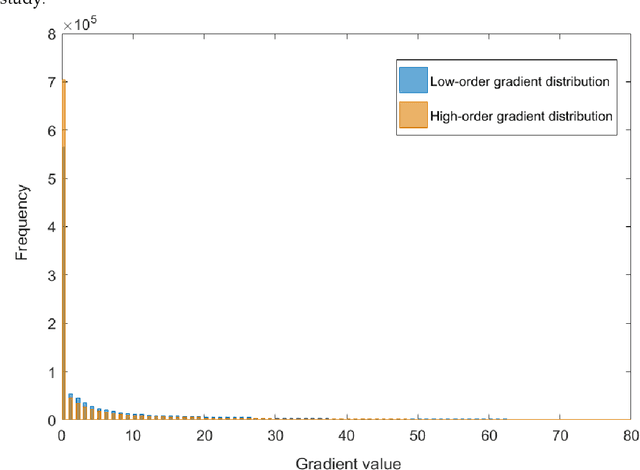
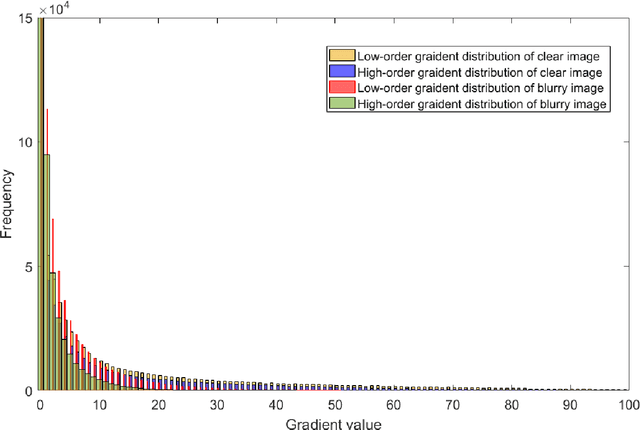

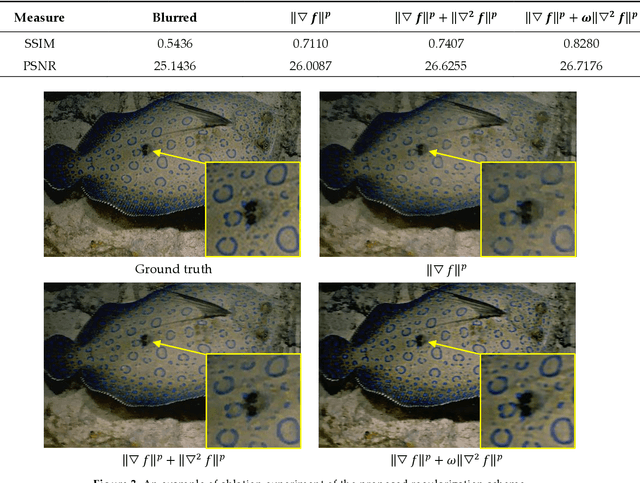
Image quality is the basis of image communication and understanding tasks. Due to the blur and noise effects caused by imaging, transmission and other processes, the image quality is degraded. Blind image restoration is widely used to improve image quality, where the main goal is to faithfully estimate the blur kernel and the latent sharp image. In this study, based on experimental observation and research, an adaptively sparse regularized minimization method is originally proposed. The high-order gradients combine with low-order ones to form a hybrid regularization term, and an adaptive operator derived from the image entropy is introduced to maintain a good convergence. Extensive experiments were conducted on different blur kernels and images. Compared with existing state-of-the-art blind deblurring methods, our method demonstrates superiority on the recovery accuracy.
SSMD: Semi-Supervised Medical Image Detection with Adaptive Consistency and Heterogeneous Perturbation
Jun 03, 2021Semi-Supervised classification and segmentation methods have been widely investigated in medical image analysis. Both approaches can improve the performance of fully-supervised methods with additional unlabeled data. However, as a fundamental task, semi-supervised object detection has not gained enough attention in the field of medical image analysis. In this paper, we propose a novel Semi-Supervised Medical image Detector (SSMD). The motivation behind SSMD is to provide free yet effective supervision for unlabeled data, by regularizing the predictions at each position to be consistent. To achieve the above idea, we develop a novel adaptive consistency cost function to regularize different components in the predictions. Moreover, we introduce heterogeneous perturbation strategies that work in both feature space and image space, so that the proposed detector is promising to produce powerful image representations and robust predictions. Extensive experimental results show that the proposed SSMD achieves the state-of-the-art performance at a wide range of settings. We also demonstrate the strength of each proposed module with comprehensive ablation studies.
Sequential Random Network for Fine-grained Image Classification
Mar 12, 2021
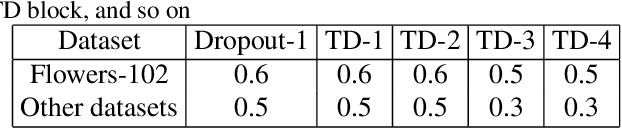
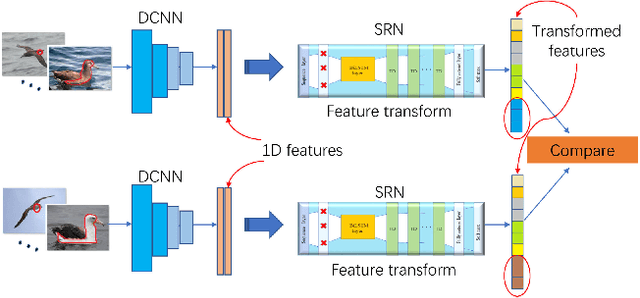
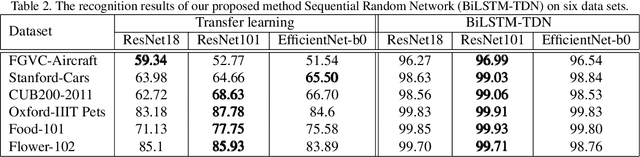
Deep Convolutional Neural Network (DCNN) and Transformer have achieved remarkable successes in image recognition. However, their performance in fine-grained image recognition is still difficult to meet the requirements of actual needs. This paper proposes a Sequence Random Network (SRN) to enhance the performance of DCNN. The output of DCNN is one-dimensional features. This one-dimensional feature abstractly represents image information, but it does not express well the detailed information of image. To address this issue, we use the proposed SRN which composed of BiLSTM and several Tanh-Dropout blocks (called BiLSTM-TDN), to further process DCNN one-dimensional features for highlighting the detail information of image. After the feature transform by BiLSTM-TDN, the recognition performance has been greatly improved. We conducted the experiments on six fine-grained image datasets. Except for FGVC-Aircraft, the accuracies of the proposed methods on the other datasets exceeded 99%. Experimental results show that BiLSTM-TDN is far superior to the existing state-of-the-art methods. In addition to DCNN, BiLSTM-TDN can also be extended to other models, such as Transformer.