 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sequence-aware multimodal page classification of Brazilian legal documents
Jul 02, 2022

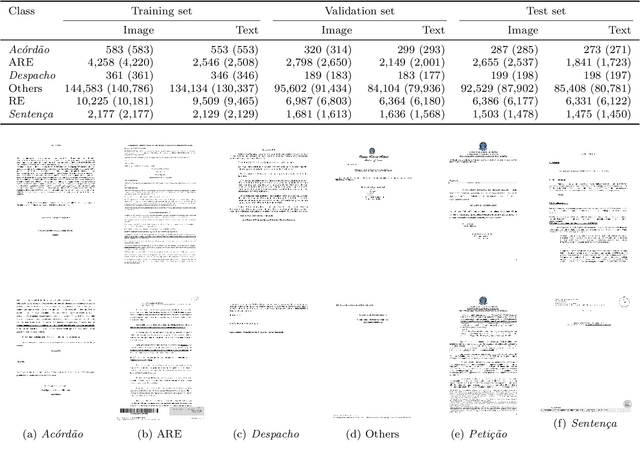
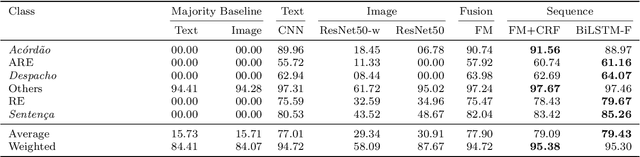
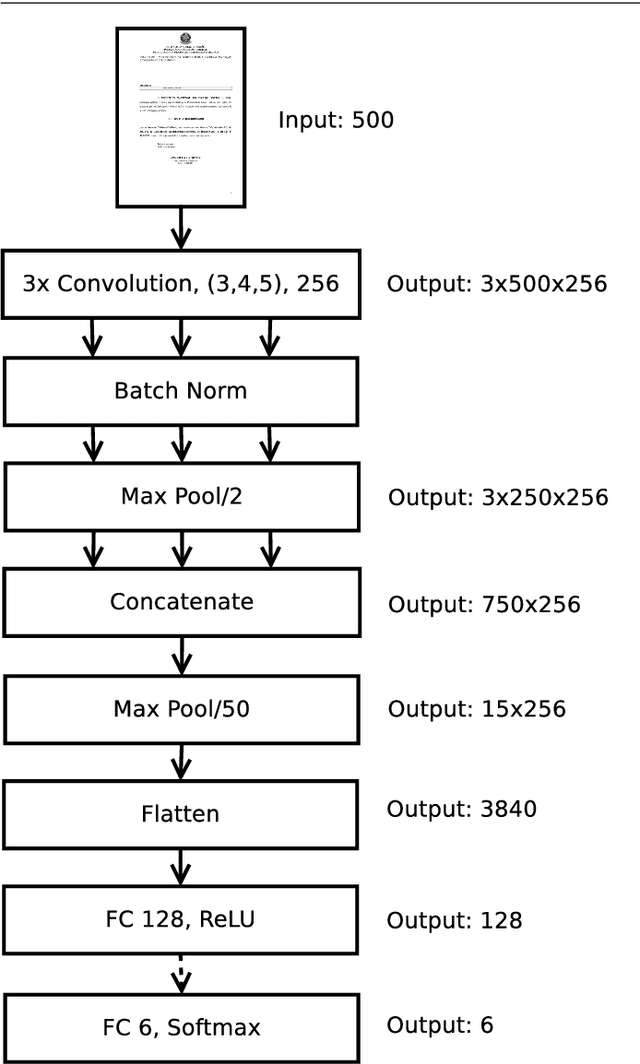
The Brazilian Supreme Court receives tens of thousands of cases each semester. Court employees spend thousands of hours to execute the initial analysis and classification of those cases -- which takes effort away from posterior, more complex stages of the case management workflow. In this paper, we explore multimodal classification of documents from Brazil's Supreme Court. We train and evaluate our methods on a novel multimodal dataset of 6,510 lawsuits (339,478 pages) with manual annotation assigning each page to one of six classes. Each lawsuit is an ordered sequence of pages, which are stored both as an image and as a corresponding text extracted through optical character recognition. We first train two unimodal classifiers: a ResNet pre-trained on ImageNet is fine-tuned on the images, and a convolutional network with filters of multiple kernel sizes is trained from scratch on document texts. We use them as extractors of visual and textual features, which are then combined through our proposed Fusion Module. Our Fusion Module can handle missing textual or visual input by using learned embeddings for missing data. Moreover, we experiment with bi-directional Long Short-Term Memory (biLSTM) networks and linear-chain conditional random fields to model the sequential nature of the pages. The multimodal approaches outperform both textual and visual classifiers, especially when leveraging the sequential nature of the pages.
U-PET: MRI-based Dementia Detection with Joint Generation of Synthetic FDG-PET Images
Jun 16, 2022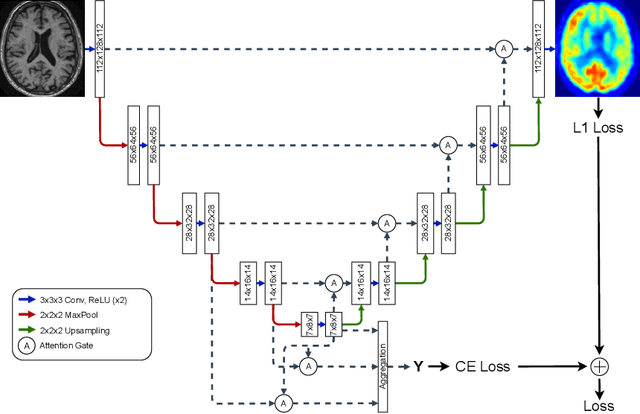
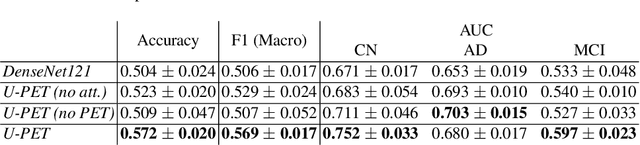
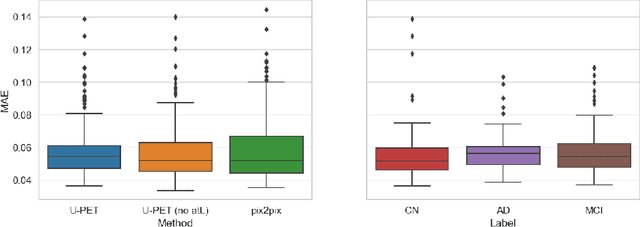
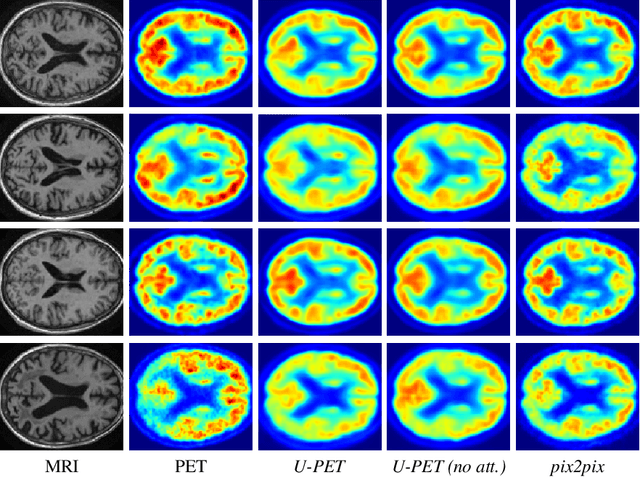
Alzheimer's disease (AD) is the most common cause of dementia. An early detection is crucial for slowing down the disease and mitigating risks related to the progression. While the combination of MRI and FDG-PET is the best image-based tool for diagnosis, FDG-PET is not always available. The reliable detection of Alzheimer's disease with only MRI could be beneficial, especially in regions where FDG-PET might not be affordable for all patients. To this end, we propose a multi-task method based on U-Net that takes T1-weighted MR images as an input to generate synthetic FDG-PET images and classifies the dementia progression of the patient into cognitive normal (CN), cognitive impairment (MCI), and AD. The attention gates used in both task heads can visualize the most relevant parts of the brain, guiding the examiner and adding interpretability. Results show the successful generation of synthetic FDG-PET images and a performance increase in disease classification over the naive single-task baseline.
Lesion classification by model-based feature extraction: A differential affine invariant model of soft tissue elasticity
May 27, 2022
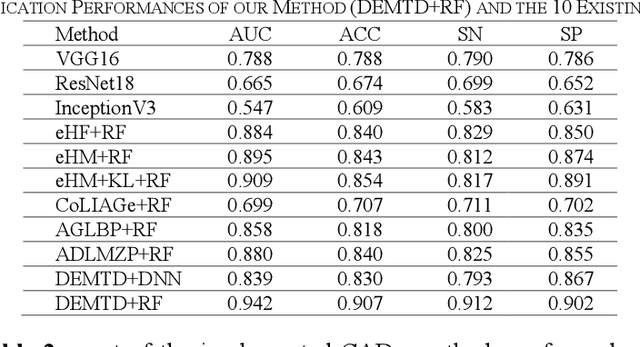
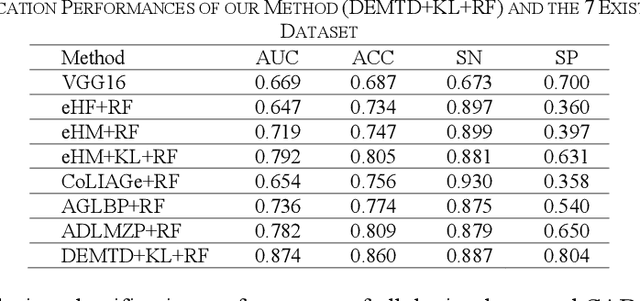
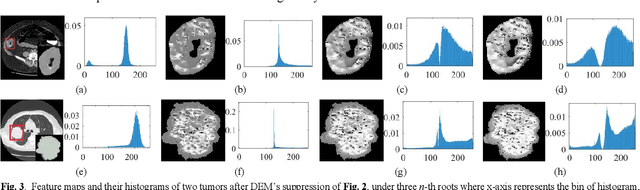
The elasticity of soft tissues has been widely considered as a characteristic property to differentiate between healthy and vicious tissues and, therefore, motivated several elasticity imaging modalities, such as Ultrasound Elastography, Magnetic Resonance Elastography, and Optical Coherence Elastography. This paper proposes an alternative approach of modeling the elasticity using Computed Tomography (CT) imaging modality for model-based feature extraction machine learning (ML) differentiation of lesions. The model describes a dynamic non-rigid (or elastic) deformation in differential manifold to mimic the soft tissues elasticity under wave fluctuation in vivo. Based on the model, three local deformation invariants are constructed by two tensors defined by the first and second order derivatives from the CT images and used to generate elastic feature maps after normalization via a novel signal suppression method. The model-based elastic image features are extracted from the feature maps and fed to machine learning to perform lesion classifications. Two pathologically proven image datasets of colon polyps (44 malignant and 43 benign) and lung nodules (46 malignant and 20 benign) were used to evaluate the proposed model-based lesion classification. The outcomes of this modeling approach reached the score of area under the curve of the receiver operating characteristics of 94.2 % for the polyps and 87.4 % for the nodules, resulting in an average gain of 5 % to 30 % over ten existing state-of-the-art lesion classification methods. The gains by modeling tissue elasticity for ML differentiation of lesions are striking, indicating the great potential of exploring the modeling strategy to other tissue properties for ML differentiation of lesions.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022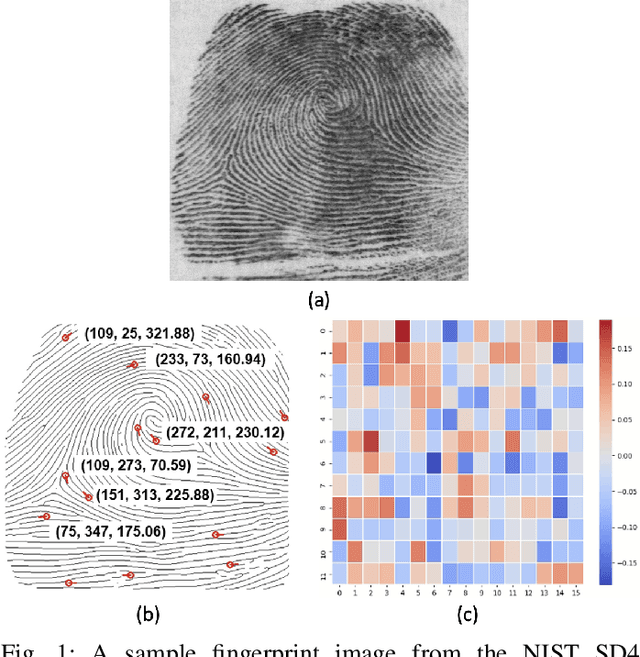

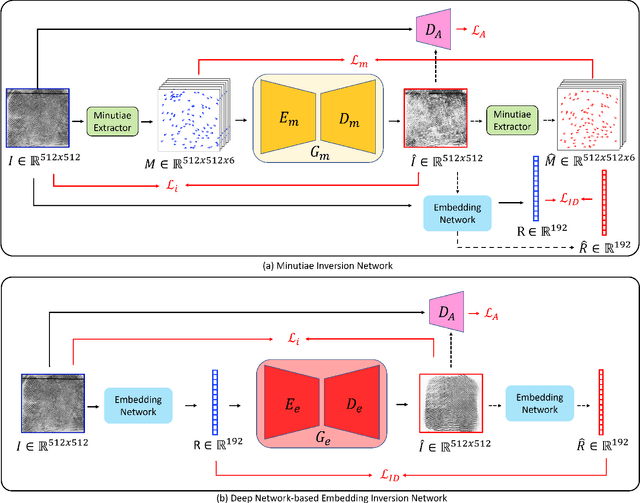

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.
GLANCE: Global to Local Architecture-Neutral Concept-based Explanations
Jul 05, 2022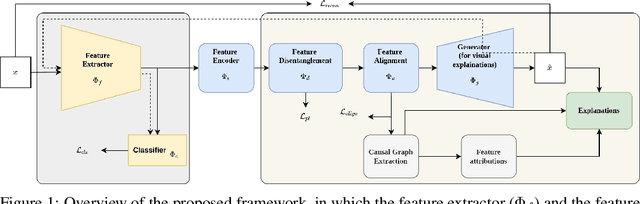

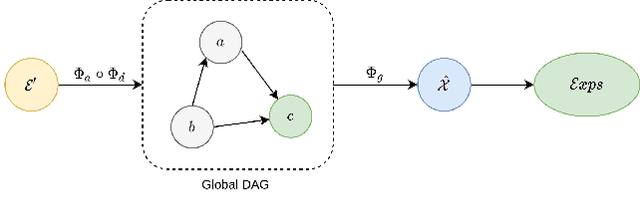
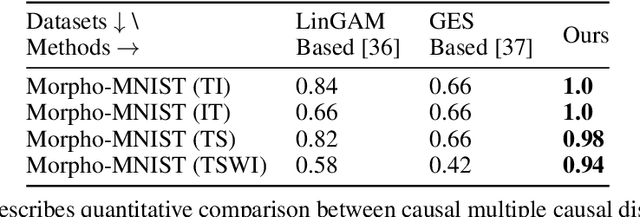
Most of the current explainability techniques focus on capturing the importance of features in input space. However, given the complexity of models and data-generating processes, the resulting explanations are far from being `complete', in that they lack an indication of feature interactions and visualization of their `effect'. In this work, we propose a novel twin-surrogate explainability framework to explain the decisions made by any CNN-based image classifier (irrespective of the architecture). For this, we first disentangle latent features from the classifier, followed by aligning these features to observed/human-defined `context' features. These aligned features form semantically meaningful concepts that are used for extracting a causal graph depicting the `perceived' data-generating process, describing the inter- and intra-feature interactions between unobserved latent features and observed `context' features. This causal graph serves as a global model from which local explanations of different forms can be extracted. Specifically, we provide a generator to visualize the `effect' of interactions among features in latent space and draw feature importance therefrom as local explanations. Our framework utilizes adversarial knowledge distillation to faithfully learn a representation from the classifiers' latent space and use it for extracting visual explanations. We use the styleGAN-v2 architecture with an additional regularization term to enforce disentanglement and alignment. We demonstrate and evaluate explanations obtained with our framework on Morpho-MNIST and on the FFHQ human faces dataset. Our framework is available at \url{https://github.com/koriavinash1/GLANCE-Explanations}.
Total Variation Optimization Layers for Computer Vision
Apr 07, 2022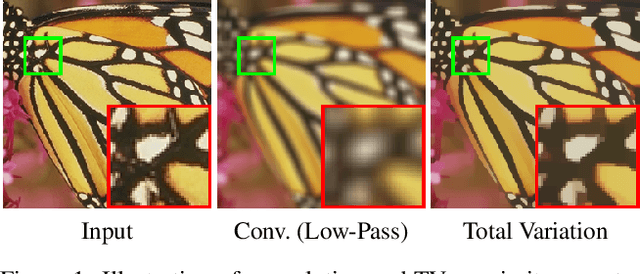



Optimization within a layer of a deep-net has emerged as a new direction for deep-net layer design. However, there are two main challenges when applying these layers to computer vision tasks: (a) which optimization problem within a layer is useful?; (b) how to ensure that computation within a layer remains efficient? To study question (a), in this work, we propose total variation (TV) minimization as a layer for computer vision. Motivated by the success of total variation in image processing, we hypothesize that TV as a layer provides useful inductive bias for deep-nets too. We study this hypothesis on five computer vision tasks: image classification, weakly supervised object localization, edge-preserving smoothing, edge detection, and image denoising, improving over existing baselines. To achieve these results we had to address question (b): we developed a GPU-based projected-Newton method which is $37\times$ faster than existing solutions.
Data-Driven Interpolation for Super-Scarce X-Ray Computed Tomography
May 16, 2022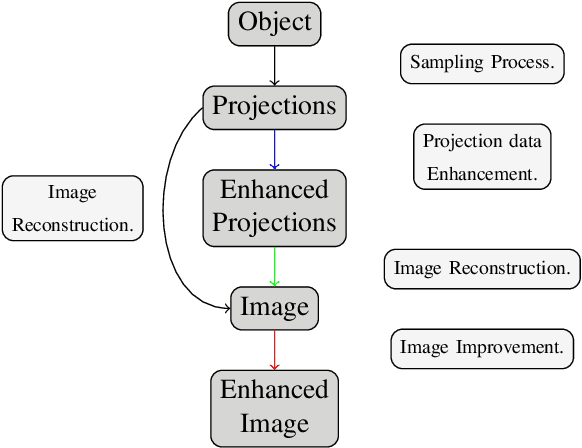
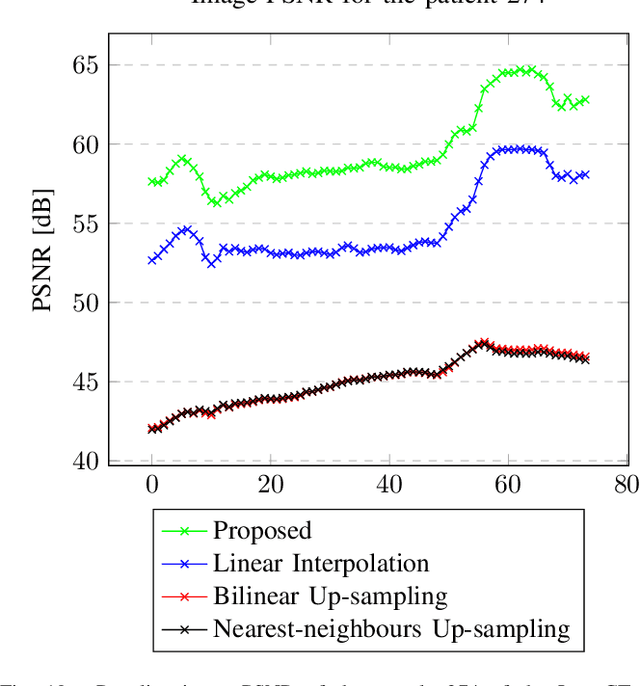
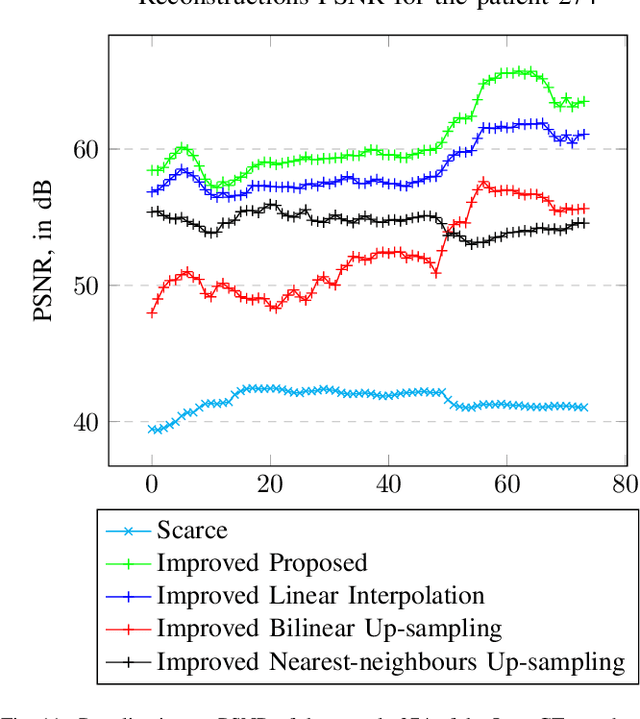
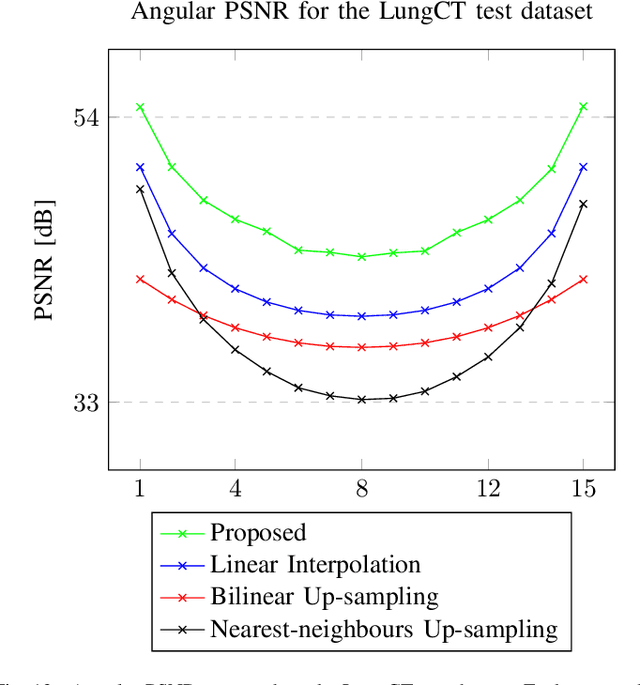
We address the problem of reconstructing X-Ray tomographic images from scarce measurements by interpolating missing acquisitions using a self-supervised approach. To do so, we train shallow neural networks to combine two neighbouring acquisitions into an estimated measurement at an intermediate angle. This procedure yields an enhanced sequence of measurements that can be reconstructed using standard methods, or further enhanced using regularisation approaches. Unlike methods that improve the sequence of acquisitions using an initial deterministic interpolation followed by machine-learning enhancement, we focus on inferring one measurement at once. This allows the method to scale to 3D, the computation to be faster and crucially, the interpolation to be significantly better than the current methods, when they exist. We also establish that a sequence of measurements must be processed as such, rather than as an image or a volume. We do so by comparing interpolation and up-sampling methods, and find that the latter significantly under-perform. We compare the performance of the proposed method against deterministic interpolation and up-sampling procedures and find that it outperforms them, even when used jointly with a state-of-the-art projection-data enhancement approach using machine-learning. These results are obtained for 2D and 3D imaging, on large biomedical datasets, in both projection space and image space.
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022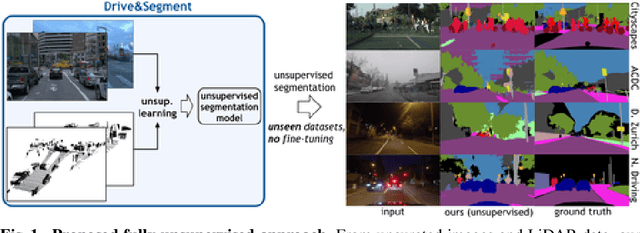
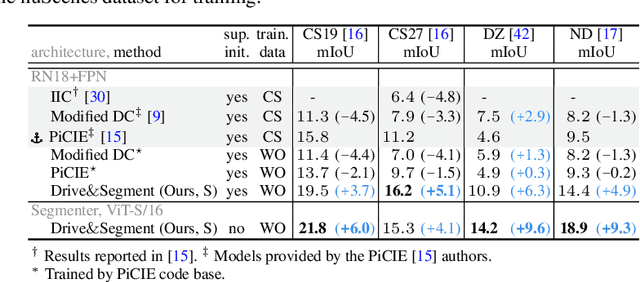
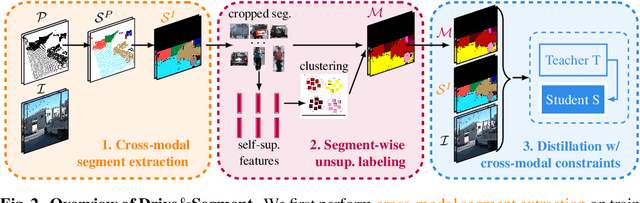
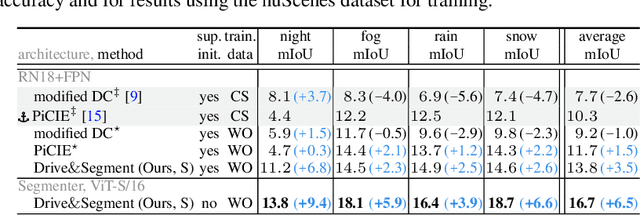
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
SemAttNet: Towards Attention-based Semantic Aware Guided Depth Completion
Apr 28, 2022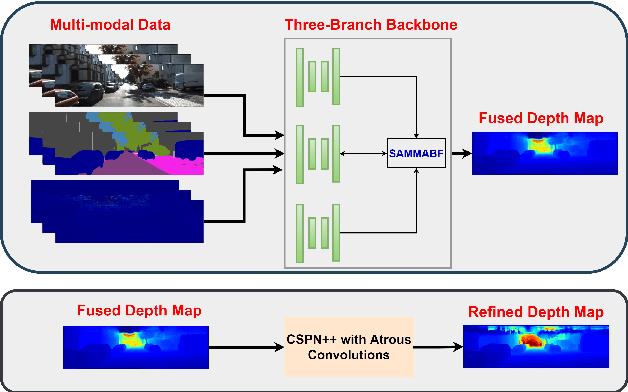
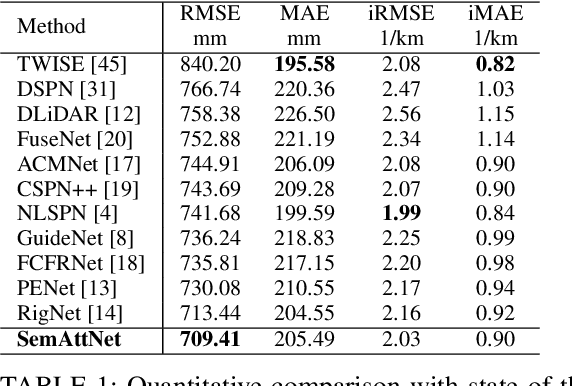
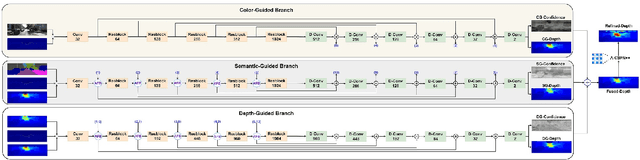

Depth completion involves recovering a dense depth map from a sparse map and an RGB image. Recent approaches focus on utilizing color images as guidance images to recover depth at invalid pixels. However, color images alone are not enough to provide the necessary semantic understanding of the scene. Consequently, the depth completion task suffers from sudden illumination changes in RGB images (e.g., shadows). In this paper, we propose a novel three-branch backbone comprising color-guided, semantic-guided, and depth-guided branches. Specifically, the color-guided branch takes a sparse depth map and RGB image as an input and generates color depth which includes color cues (e.g., object boundaries) of the scene. The predicted dense depth map of color-guided branch along-with semantic image and sparse depth map is passed as input to semantic-guided branch for estimating semantic depth. The depth-guided branch takes sparse, color, and semantic depths to generate the dense depth map. The color depth, semantic depth, and guided depth are adaptively fused to produce the output of our proposed three-branch backbone. In addition, we also propose to apply semantic-aware multi-modal attention-based fusion block (SAMMAFB) to fuse features between all three branches. We further use CSPN++ with Atrous convolutions to refine the dense depth map produced by our three-branch backbone. Extensive experiments show that our model achieves state-of-the-art performance in the KITTI depth completion benchmark at the time of submission.
Learning Compositional Representations for Effective Low-Shot Generalization
Apr 17, 2022
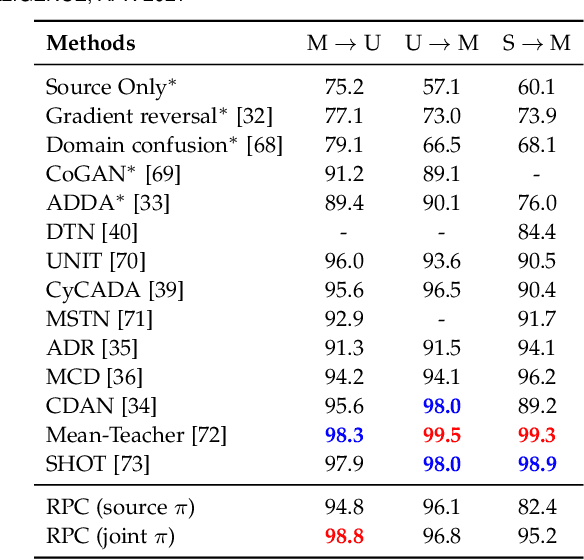
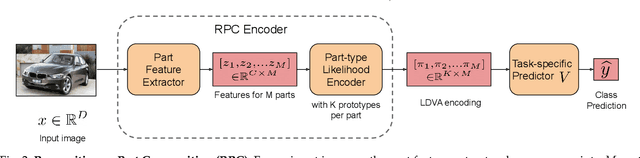
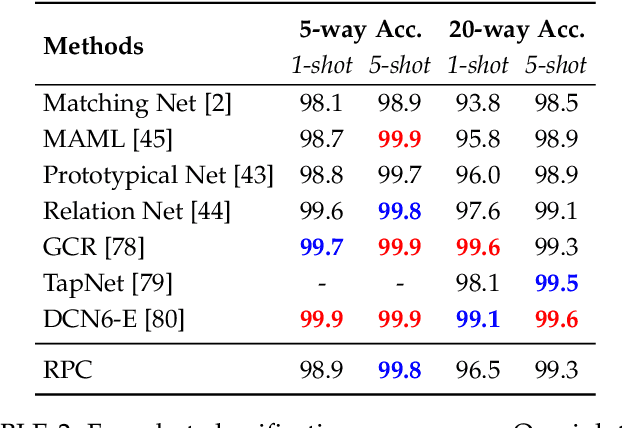
We propose Recognition as Part Composition (RPC), an image encoding approach inspired by human cognition. It is based on the cognitive theory that humans recognize complex objects by components, and that they build a small compact vocabulary of concepts to represent each instance with. RPC encodes images by first decomposing them into salient parts, and then encoding each part as a mixture of a small number of prototypes, each representing a certain concept. We find that this type of learning inspired by human cognition can overcome hurdles faced by deep convolutional networks in low-shot generalization tasks, like zero-shot learning, few-shot learning and unsupervised domain adaptation. Furthermore, we find a classifier using an RPC image encoder is fairly robust to adversarial attacks, that deep neural networks are known to be prone to. Given that our image encoding principle is based on human cognition, one would expect the encodings to be interpretable by humans, which we find to be the case via crowd-sourcing experiments. Finally, we propose an application of these interpretable encodings in the form of generating synthetic attribute annotations for evaluating zero-shot learning methods on new datasets.