 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-aware multimodal page classification of Brazilian legal documents
Jul 15, 2022
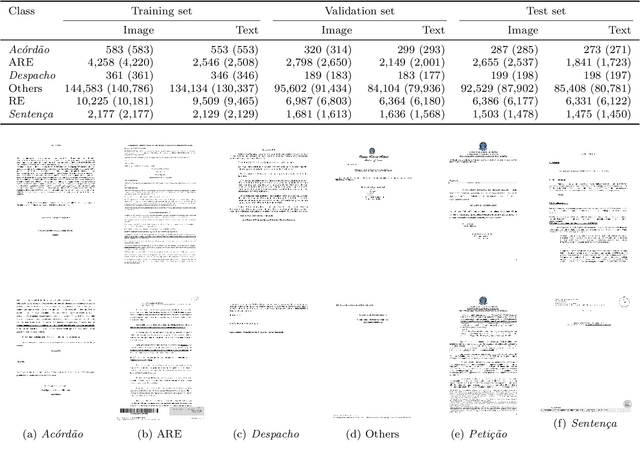
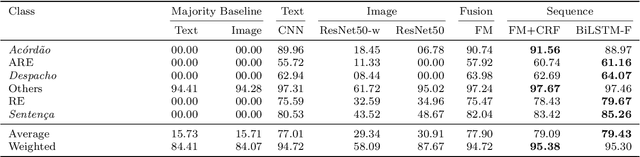
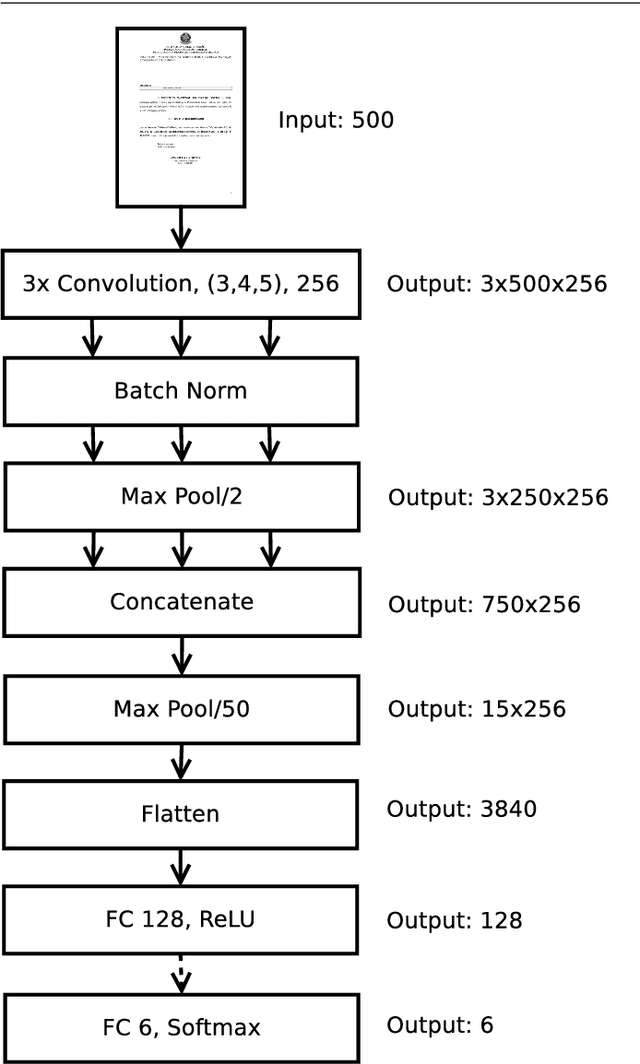
The Brazilian Supreme Court receives tens of thousands of cases each semester. Court employees spend thousands of hours to execute the initial analysis and classification of those cases -- which takes effort away from posterior, more complex stages of the case management workflow. In this paper, we explore multimodal classification of documents from Brazil's Supreme Court. We train and evaluate our methods on a novel multimodal dataset of 6,510 lawsuits (339,478 pages) with manual annotation assigning each page to one of six classes. Each lawsuit is an ordered sequence of pages, which are stored both as an image and as a corresponding text extracted through optical character recognition. We first train two unimodal classifiers: a ResNet pre-trained on ImageNet is fine-tuned on the images, and a convolutional network with filters of multiple kernel sizes is trained from scratch on document texts. We use them as extractors of visual and textual features, which are then combined through our proposed Fusion Module. Our Fusion Module can handle missing textual or visual input by using learned embeddings for missing data. Moreover, we experiment with bi-directional Long Short-Term Memory (biLSTM) networks and linear-chain conditional random fields to model the sequential nature of the pages. The multimodal approaches outperform both textual and visual classifiers, especially when leveraging the sequential nature of the pages.
* 11 pages, 6 figures. This preprint, which was originally written on 8 April 2021, has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this article is published in the International Journal on Document Analysis and Recognition, and is available online at https://doi.org/10.1007/s10032-022-00406-7 and https://rdcu.be/cRvvV
Towards robustness under occlusion for face recognition
Sep 19, 2021


In this paper, we evaluate the effects of occlusions in the performance of a face recognition pipeline that uses a ResNet backbone. The classifier was trained on a subset of the CelebA-HQ dataset containing 5,478 images from 307 classes, to achieve top-1 error rate of 17.91%. We designed 8 different occlusion masks which were applied to the input images. This caused a significant drop in the classifier performance: its error rate for each mask became at least two times worse than before. In order to increase robustness under occlusions, we followed two approaches. The first is image inpainting using the pre-trained pluralistic image completion network. The second is Cutmix, a regularization strategy consisting of mixing training images and their labels using rectangular patches, making the classifier more robust against input corruptions. Both strategies revealed effective and interesting results were observed. In particular, the Cutmix approach makes the network more robust without requiring additional steps at the application time, though its training time is considerably longer. Our datasets containing the different occlusion masks as well as their inpainted counterparts are made publicly available to promote research on the field.
Domain adaptation for person re-identification on new unlabeled data using AlignedReID++
Jun 29, 2021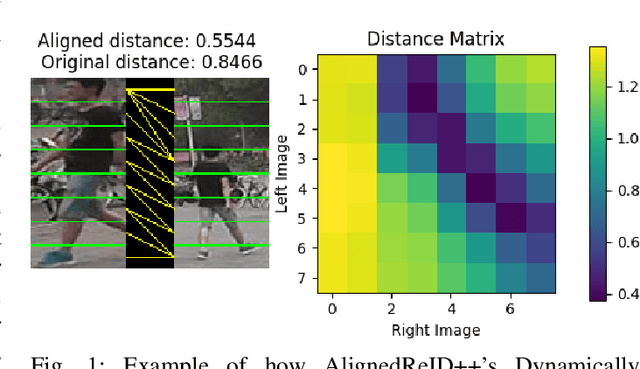
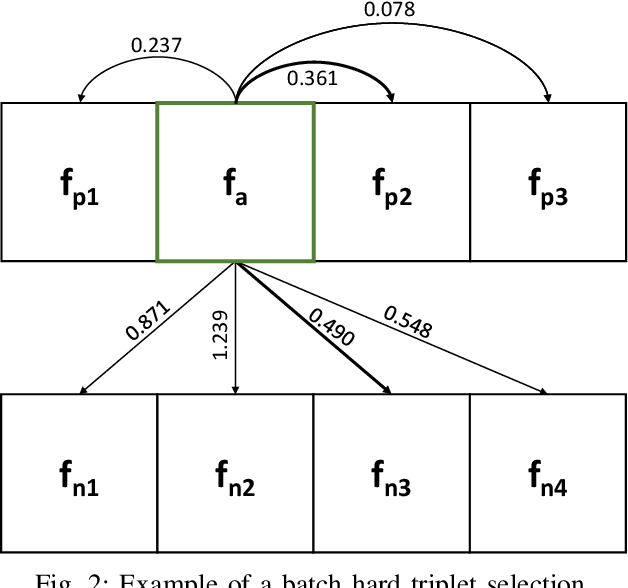


In the world where big data reigns and there is plenty of hardware prepared to gather a huge amount of non structured data, data acquisition is no longer a problem. Surveillance cameras are ubiquitous and they capture huge numbers of people walking across different scenes. However, extracting value from this data is challenging, specially for tasks that involve human images, such as face recognition and person re-identification. Annotation of this kind of data is a challenging and expensive task. In this work we propose a domain adaptation workflow to allow CNNs that were trained in one domain to be applied to another domain without the need for new annotation of the target data. Our method uses AlignedReID++ as the baseline, trained using a Triplet loss with batch hard. Domain adaptation is done by using pseudo-labels generated using an unsupervised learning strategy. Our results show that domain adaptation techniques really improve the performance of the CNN when applied in the target domain.
Learn by Guessing: Multi-Step Pseudo-Label Refinement for Person Re-Identification
Jan 04, 2021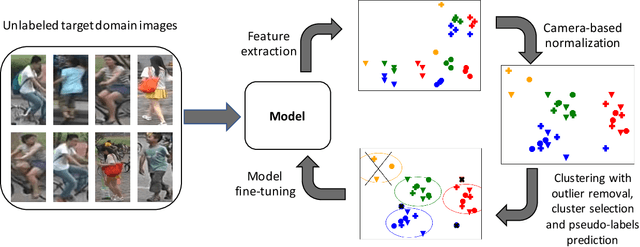

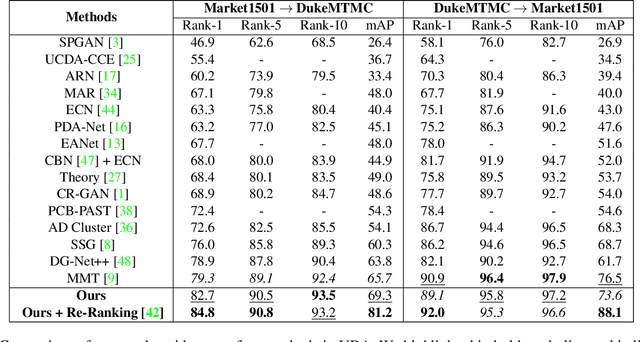
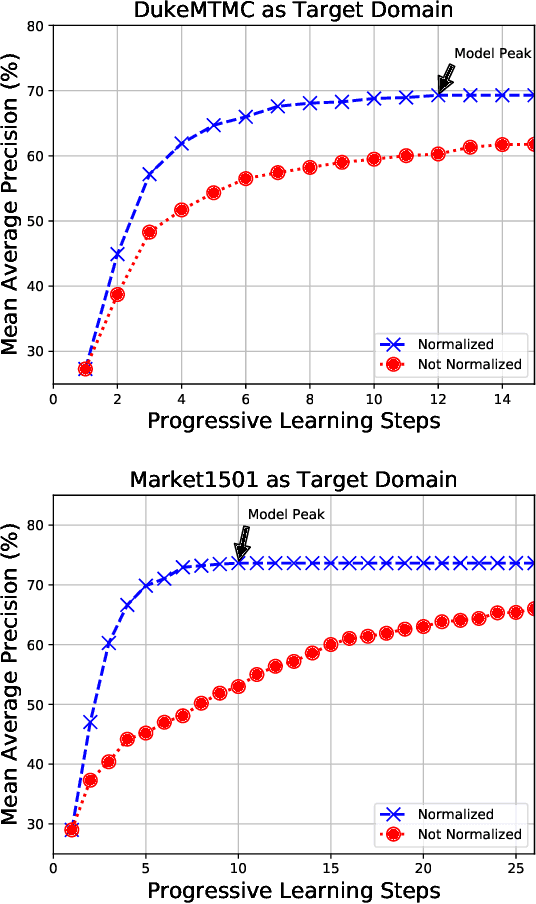
Unsupervised Domain Adaptation (UDA) methods for person Re-Identification (Re-ID) rely on target domain samples to model the marginal distribution of the data. To deal with the lack of target domain labels, UDA methods leverage information from labeled source samples and unlabeled target samples. A promising approach relies on the use of unsupervised learning as part of the pipeline, such as clustering methods. The quality of the clusters clearly plays a major role in methods performance, but this point has been overlooked. In this work, we propose a multi-step pseudo-label refinement method to select the best possible clusters and keep improving them so that these clusters become closer to the class divisions without knowledge of the class labels. Our refinement method includes a cluster selection strategy and a camera-based normalization method which reduces the within-domain variations caused by the use of multiple cameras in person Re-ID. This allows our method to reach state-of-the-art UDA results on DukeMTMC-Market1501 (source-target). We surpass state-of-the-art for UDA Re-ID by 3.4% on Market1501-DukeMTMC datasets, which is a more challenging adaptation setup because the target domain (DukeMTMC) has eight distinct cameras. Furthermore, the camera-based normalization method causes a significant reduction in the number of iterations required for training convergence.
Assessment of algorithms for mitosis detection in breast cancer histopathology images
Nov 21, 2014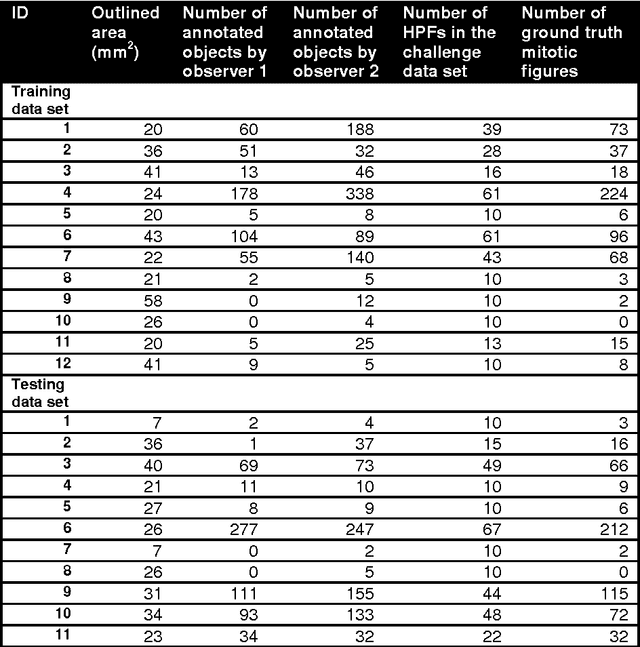

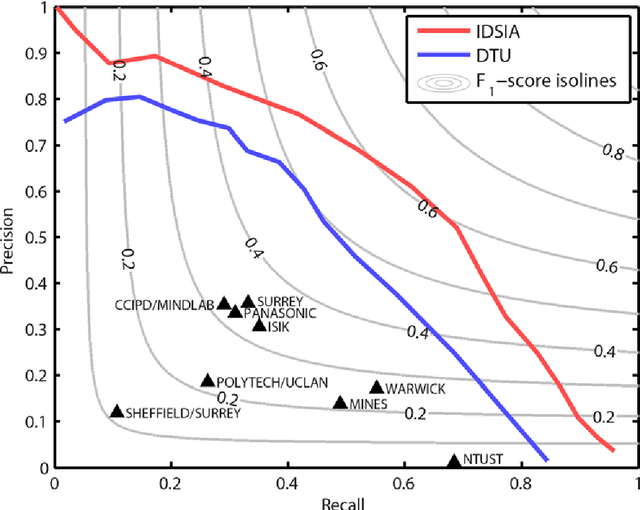
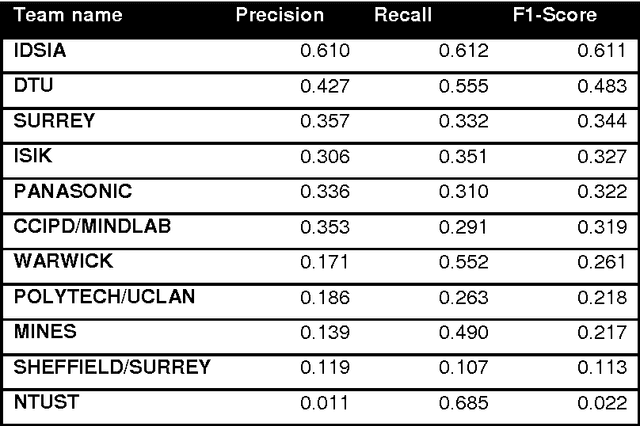
The proliferative activity of breast tumors, which is routinely estimated by counting of mitotic figures in hematoxylin and eosin stained histology sections, is considered to be one of the most important prognostic markers. However, mitosis counting is laborious, subjective and may suffer from low inter-observer agreement. With the wider acceptance of whole slide images in pathology labs, automatic image analysis has been proposed as a potential solution for these issues. In this paper, the results from the Assessment of Mitosis Detection Algorithms 2013 (AMIDA13) challenge are described. The challenge was based on a data set consisting of 12 training and 11 testing subjects, with more than one thousand annotated mitotic figures by multiple observers. Short descriptions and results from the evaluation of eleven methods are presented. The top performing method has an error rate that is comparable to the inter-observer agreement among pathologists.