 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pythae: Unifying Generative Autoencoders in Python -- A Benchmarking Use Case
Jun 16, 2022
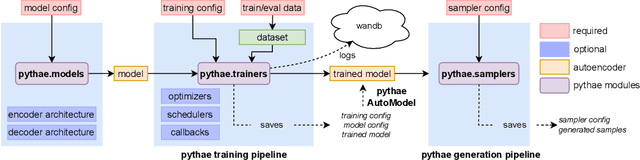
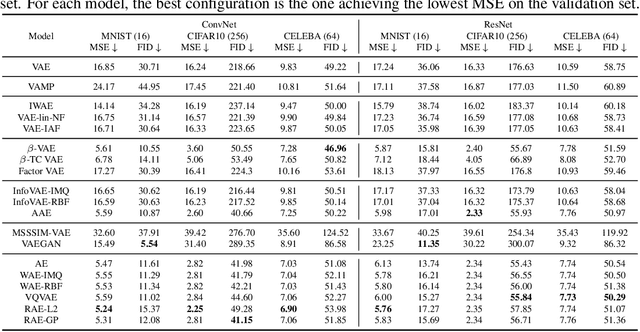
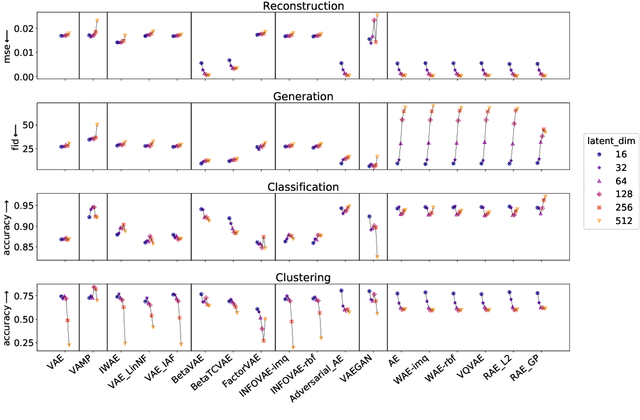
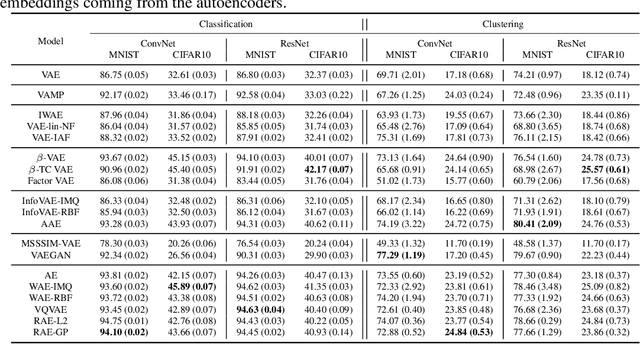
In recent years, deep generative models have attracted increasing interest due to their capacity to model complex distributions. Among those models, variational autoencoders have gained popularity as they have proven both to be computationally efficient and yield impressive results in multiple fields. Following this breakthrough, extensive research has been done in order to improve the original publication, resulting in a variety of different VAE models in response to different tasks. In this paper we present Pythae, a versatile open-source Python library providing both a unified implementation and a dedicated framework allowing straightforward, reproducible and reliable use of generative autoencoder models. We then propose to use this library to perform a case study benchmark where we present and compare 19 generative autoencoder models representative of some of the main improvements on downstream tasks such as image reconstruction, generation, classification, clustering and interpolation. The open-source library can be found at https://github.com/clementchadebec/benchmark_VAE.
Zero-Episode Few-Shot Contrastive Predictive Coding: Solving intelligence tests without prior training
May 04, 2022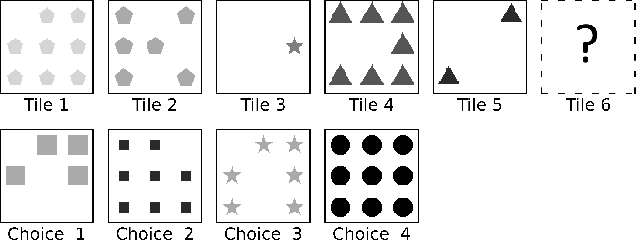
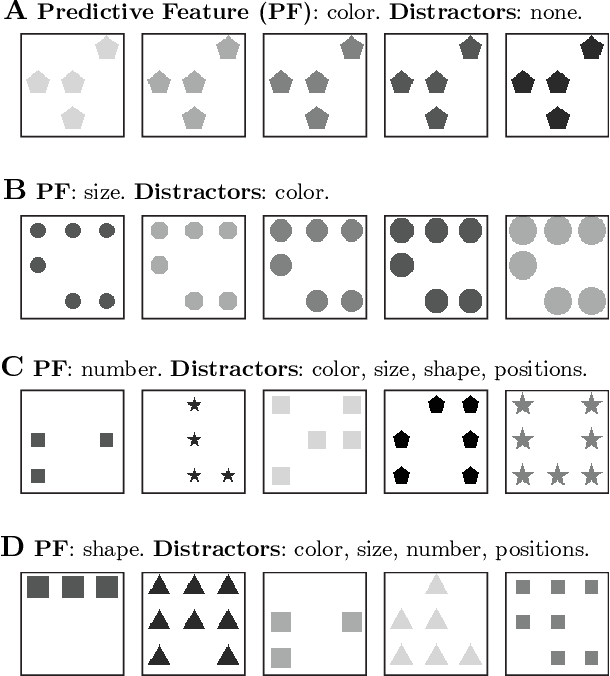
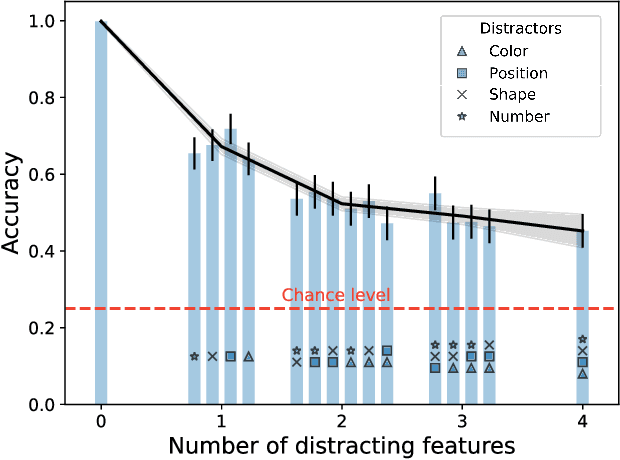
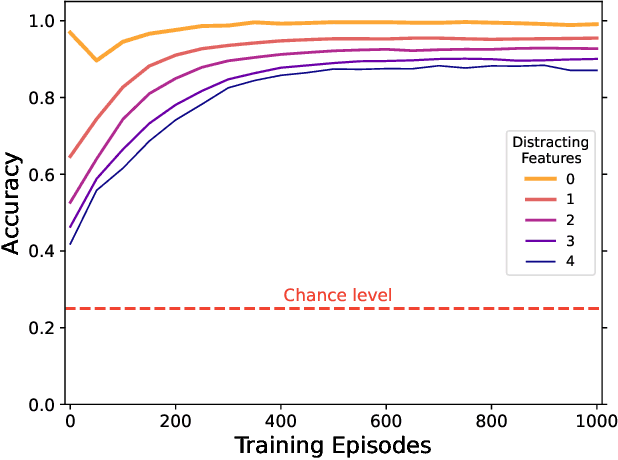
Video prediction models often combine three components: an encoder from pixel space to a small latent space, a latent space prediction model, and a generative model back to pixel space. However, the large and unpredictable pixel space makes training such models difficult, requiring many training examples. We argue that finding a predictive latent variable and using it to evaluate the consistency of a future image enables data-efficient predictions because it precludes the necessity of a generative model training. To demonstrate it, we created sequence completion intelligence tests in which the task is to identify a predictably changing feature in a sequence of images and use this prediction to select the subsequent image. We show that a one-dimensional Markov Contrastive Predictive Coding (M-CPC_1D) model solves these tests efficiently, with only five examples. Finally, we demonstrate the usefulness of M-CPC_1D in solving two tasks without prior training: anomaly detection and stochastic movement video prediction.
PLATON: Pruning Large Transformer Models with Upper Confidence Bound of Weight Importance
Jun 25, 2022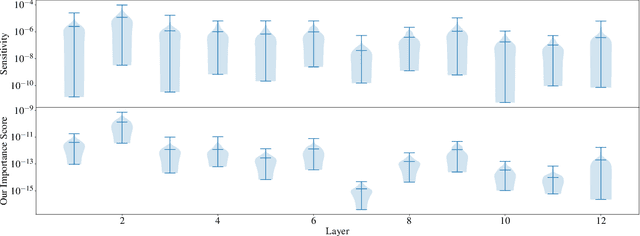
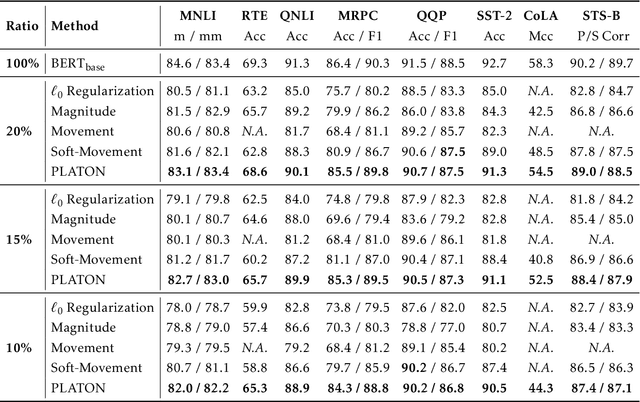
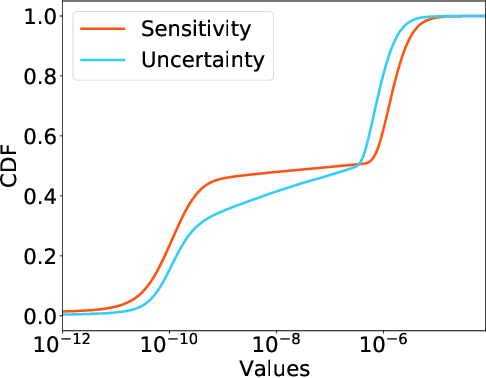
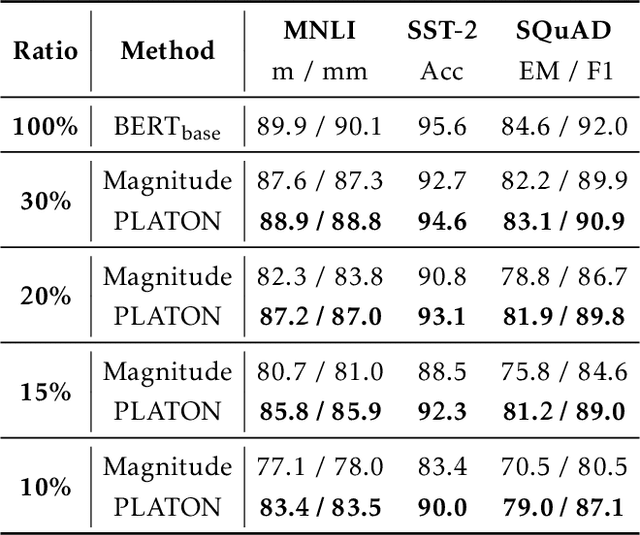
Large Transformer-based models have exhibited superior performance in various natural language processing and computer vision tasks. However, these models contain enormous amounts of parameters, which restrict their deployment to real-world applications. To reduce the model size, researchers prune these models based on the weights' importance scores. However, such scores are usually estimated on mini-batches during training, which incurs large variability/uncertainty due to mini-batch sampling and complicated training dynamics. As a result, some crucial weights could be pruned by commonly used pruning methods because of such uncertainty, which makes training unstable and hurts generalization. To resolve this issue, we propose PLATON, which captures the uncertainty of importance scores by upper confidence bound (UCB) of importance estimation. In particular, for the weights with low importance scores but high uncertainty, PLATON tends to retain them and explores their capacity. We conduct extensive experiments with several Transformer-based models on natural language understanding, question answering and image classification to validate the effectiveness of PLATON. Results demonstrate that PLATON manifests notable improvement under different sparsity levels. Our code is publicly available at https://github.com/QingruZhang/PLATON.
Contrastive Semantic Similarity Learning for Image Captioning Evaluation with Intrinsic Auto-encoder
Jun 29, 2021
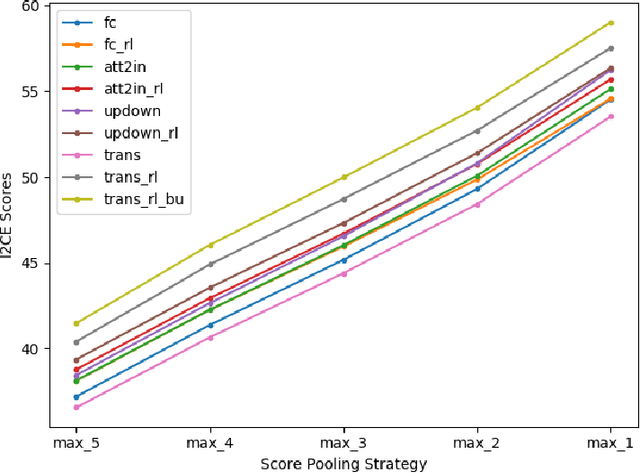
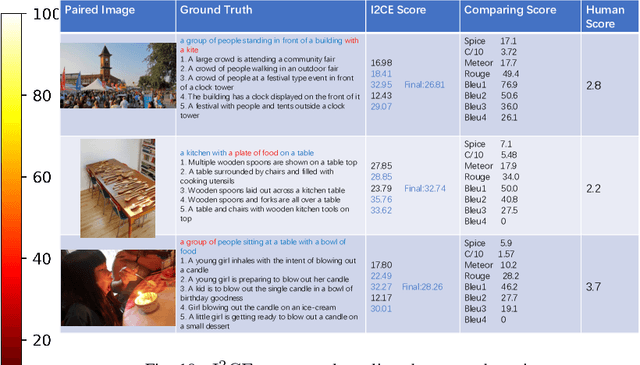
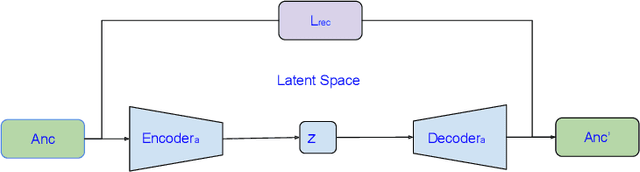
Automatically evaluating the quality of image captions can be very challenging since human language is quite flexible that there can be various expressions for the same meaning. Most of the current captioning metrics rely on token level matching between candidate caption and the ground truth label sentences. It usually neglects the sentence-level information. Motivated by the auto-encoder mechanism and contrastive representation learning advances, we propose a learning-based metric for image captioning, which we call Intrinsic Image Captioning Evaluation($I^2CE$). We develop three progressive model structures to learn the sentence level representations--single branch model, dual branches model, and triple branches model. Our empirical tests show that $I^2CE$ trained with dual branches structure achieves better consistency with human judgments to contemporary image captioning evaluation metrics. Furthermore, We select several state-of-the-art image captioning models and test their performances on the MS COCO dataset concerning both contemporary metrics and the proposed $I^2CE$. Experiment results show that our proposed method can align well with the scores generated from other contemporary metrics. On this concern, the proposed metric could serve as a novel indicator of the intrinsic information between captions, which may be complementary to the existing ones.
LANTERN-RD: Enabling Deep Learning for Mitigation of the Invasive Spotted Lanternfly
May 12, 2022

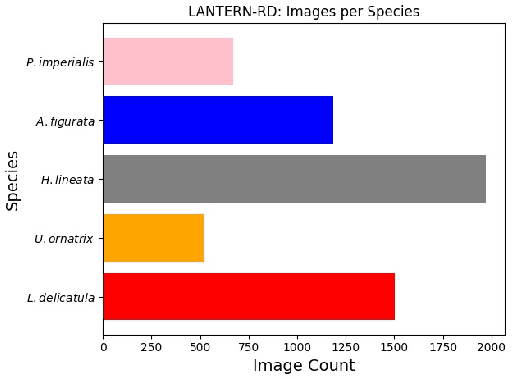
The Spotted Lanternfly (SLF) is an invasive planthopper that threatens the local biodiversity and agricultural economy of regions such as the Northeastern United States and Japan. As researchers scramble to study the insect, there is a great potential for computer vision tasks such as detection, pose estimation, and accurate identification to have important downstream implications in containing the SLF. However, there is currently no publicly available dataset for training such AI models. To enable computer vision applications and motivate advancements to challenge the invasive SLF problem, we propose LANTERN-RD, the first curated image dataset of the spotted lanternfly and its look-alikes, featuring images with varied lighting conditions, diverse backgrounds, and subjects in assorted poses. A VGG16-based baseline CNN validates the potential of this dataset for stimulating fresh computer vision applications to accelerate invasive SLF research. Additionally, we implement the trained model in a simple mobile classification application in order to directly empower responsible public mitigation efforts. The overarching mission of this work is to introduce a novel SLF image dataset and release a classification framework that enables computer vision applications, boosting studies surrounding the invasive SLF and assisting in minimizing its agricultural and economic damage.
FlowNet-PET: Unsupervised Learning to Perform Respiratory Motion Correction in PET Imaging
May 27, 2022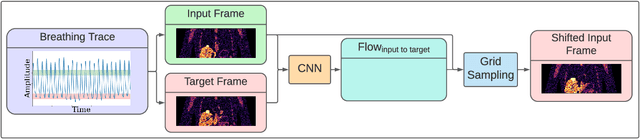
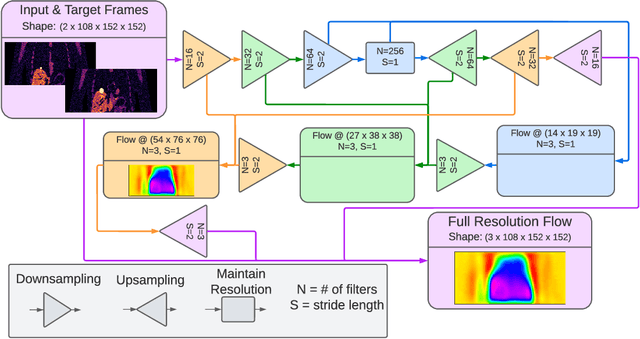
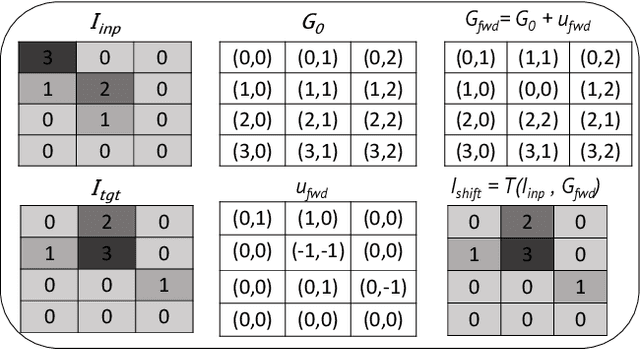
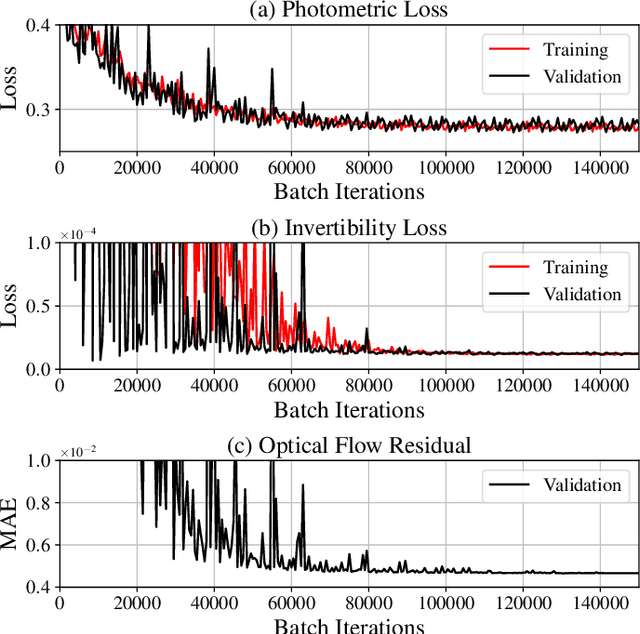
To correct for breathing motion in PET imaging, an interpretable and unsupervised deep learning technique, FlowNet-PET, was constructed. The network was trained to predict the optical flow between two PET frames from different breathing amplitude ranges. As a result, the trained model groups different retrospectively-gated PET images together into a motion-corrected single bin, providing a final image with similar counting statistics as a non-gated image, but without the blurring effects that were initially observed. As a proof-of-concept, FlowNet-PET was applied to anthropomorphic digital phantom data, which provided the possibility to design robust metrics to quantify the corrections. When comparing the predicted optical flows to the ground truths, the median absolute error was found to be smaller than the pixel and slice widths, even for the phantom with a diaphragm movement of 21 mm. The improvements were illustrated by comparing against images without motion and computing the intersection over union (IoU) of the tumors as well as the enclosed activity and coefficient of variation (CoV) within the no-motion tumor volume before and after the corrections were applied. The average relative improvements provided by the network were 54%, 90%, and 76% for the IoU, total activity, and CoV, respectively. The results were then compared against the conventional retrospective phase binning approach. FlowNet-PET achieved similar results as retrospective binning, but only required one sixth of the scan duration. The code and data used for training and analysis has been made publicly available (https://github.com/teaghan/FlowNet_PET).
Sequence-aware multimodal page classification of Brazilian legal documents
Jul 02, 2022
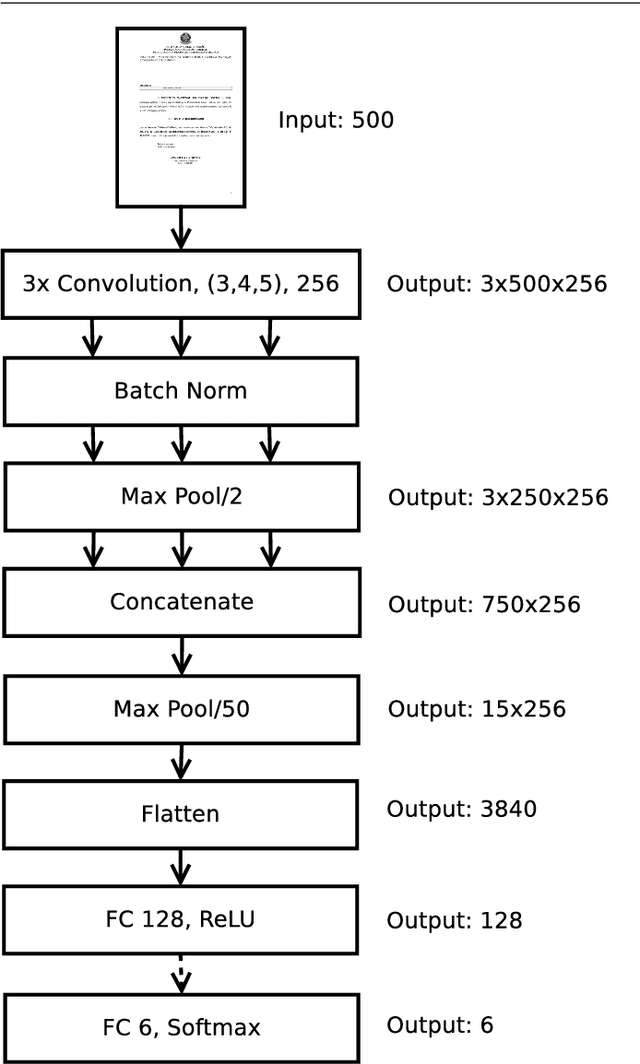
The Brazilian Supreme Court receives tens of thousands of cases each semester. Court employees spend thousands of hours to execute the initial analysis and classification of those cases -- which takes effort away from posterior, more complex stages of the case management workflow. In this paper, we explore multimodal classification of documents from Brazil's Supreme Court. We train and evaluate our methods on a novel multimodal dataset of 6,510 lawsuits (339,478 pages) with manual annotation assigning each page to one of six classes. Each lawsuit is an ordered sequence of pages, which are stored both as an image and as a corresponding text extracted through optical character recognition. We first train two unimodal classifiers: a ResNet pre-trained on ImageNet is fine-tuned on the images, and a convolutional network with filters of multiple kernel sizes is trained from scratch on document texts. We use them as extractors of visual and textual features, which are then combined through our proposed Fusion Module. Our Fusion Module can handle missing textual or visual input by using learned embeddings for missing data. Moreover, we experiment with bi-directional Long Short-Term Memory (biLSTM) networks and linear-chain conditional random fields to model the sequential nature of the pages. The multimodal approaches outperform both textual and visual classifiers, especially when leveraging the sequential nature of the pages.
U-PET: MRI-based Dementia Detection with Joint Generation of Synthetic FDG-PET Images
Jun 16, 2022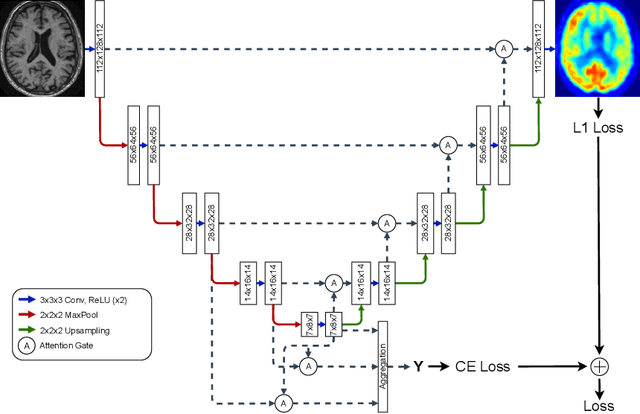
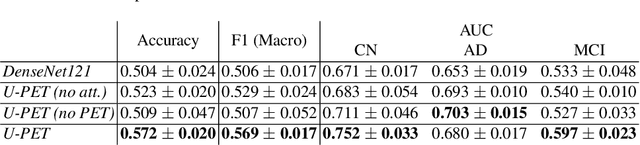
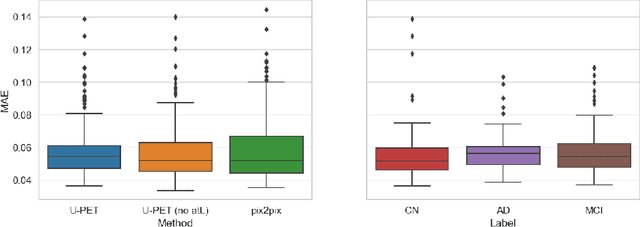
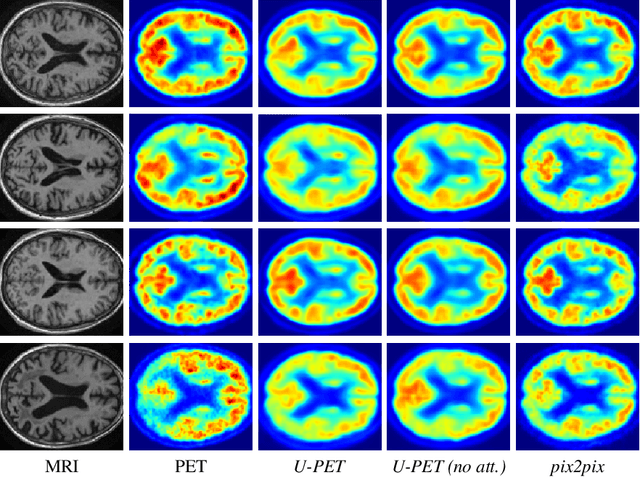
Alzheimer's disease (AD) is the most common cause of dementia. An early detection is crucial for slowing down the disease and mitigating risks related to the progression. While the combination of MRI and FDG-PET is the best image-based tool for diagnosis, FDG-PET is not always available. The reliable detection of Alzheimer's disease with only MRI could be beneficial, especially in regions where FDG-PET might not be affordable for all patients. To this end, we propose a multi-task method based on U-Net that takes T1-weighted MR images as an input to generate synthetic FDG-PET images and classifies the dementia progression of the patient into cognitive normal (CN), cognitive impairment (MCI), and AD. The attention gates used in both task heads can visualize the most relevant parts of the brain, guiding the examiner and adding interpretability. Results show the successful generation of synthetic FDG-PET images and a performance increase in disease classification over the naive single-task baseline.
GLANCE: Global to Local Architecture-Neutral Concept-based Explanations
Jul 05, 2022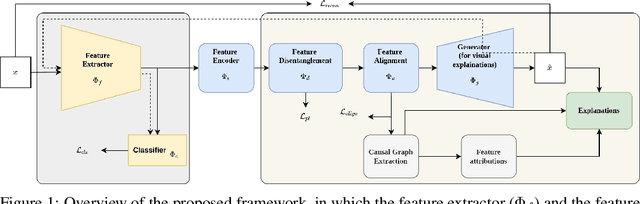

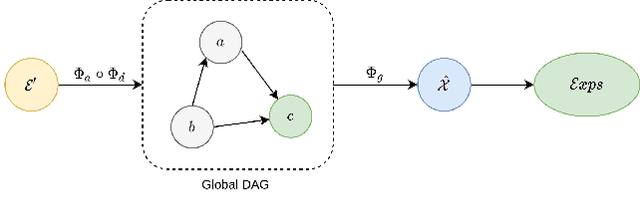
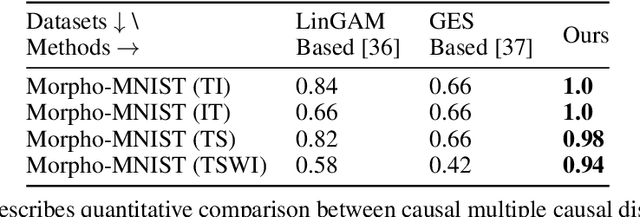
Most of the current explainability techniques focus on capturing the importance of features in input space. However, given the complexity of models and data-generating processes, the resulting explanations are far from being `complete', in that they lack an indication of feature interactions and visualization of their `effect'. In this work, we propose a novel twin-surrogate explainability framework to explain the decisions made by any CNN-based image classifier (irrespective of the architecture). For this, we first disentangle latent features from the classifier, followed by aligning these features to observed/human-defined `context' features. These aligned features form semantically meaningful concepts that are used for extracting a causal graph depicting the `perceived' data-generating process, describing the inter- and intra-feature interactions between unobserved latent features and observed `context' features. This causal graph serves as a global model from which local explanations of different forms can be extracted. Specifically, we provide a generator to visualize the `effect' of interactions among features in latent space and draw feature importance therefrom as local explanations. Our framework utilizes adversarial knowledge distillation to faithfully learn a representation from the classifiers' latent space and use it for extracting visual explanations. We use the styleGAN-v2 architecture with an additional regularization term to enforce disentanglement and alignment. We demonstrate and evaluate explanations obtained with our framework on Morpho-MNIST and on the FFHQ human faces dataset. Our framework is available at \url{https://github.com/koriavinash1/GLANCE-Explanations}.
Non-Semantic Evaluation of Image Forensics Tools: Methodology and Database
May 04, 2021
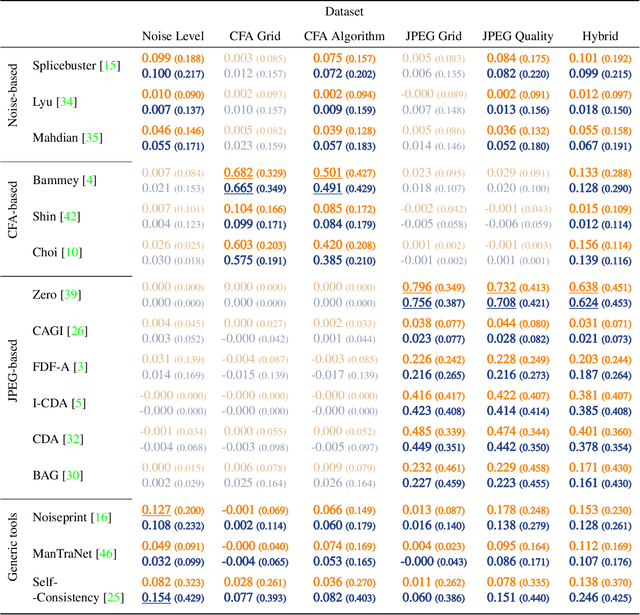


With the aim of evaluating image forensics tools, we propose a methodology to create forgeries traces, leaving intact the semantics of the image. Thus, the only forgery cues left are the specific alterations of one or several aspects of the image formation pipeline. This methodology creates automatically forged images that are challenging to detect for forensic tools and overcomes the problem of creating convincing semantic forgeries. Based on this methodology, we create the Trace database and conduct an evaluation of the main state-of-the-art image forensics tools.