 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop-Think-AutoRegress: Language Modeling with Latent Diffusion Planning
Feb 24, 2026The Stop-Think-AutoRegress Language Diffusion Model (STAR-LDM) integrates latent diffusion planning with autoregressive generation. Unlike conventional autoregressive language models limited to token-by-token decisions, STAR-LDM incorporates a "thinking" phase that pauses generation to refine a semantic plan through diffusion before continuing. This enables global planning in continuous space prior to committing to discrete tokens. Evaluations show STAR-LDM significantly outperforms similar-sized models on language understanding benchmarks and achieves $>70\%$ win rates in LLM-as-judge comparisons for narrative coherence and commonsense reasoning. The architecture also allows straightforward control through lightweight classifiers, enabling fine-grained steering of attributes without model retraining while maintaining better fluency-control trade-offs than specialized approaches.
Imitation Learning for Multi-turn LM Agents via On-policy Expert Corrections
Dec 16, 2025



A popular paradigm for training LM agents relies on imitation learning, fine-tuning on expert trajectories. However, we show that the off-policy nature of imitation learning for multi-turn LM agents suffers from the fundamental limitation known as covariate shift: as the student policy's behavior diverges from the expert's, it encounters states not present in the training data, reducing the effectiveness of fine-tuning. Taking inspiration from the classic DAgger algorithm, we propose a novel data generation methodology for addressing covariate shift for multi-turn LLM training. We introduce on-policy expert corrections (OECs), partially on-policy data generated by starting rollouts with a student model and then switching to an expert model part way through the trajectory. We explore the effectiveness of our data generation technique in the domain of software engineering (SWE) tasks, a multi-turn setting where LLM agents must interact with a development environment to fix software bugs. Our experiments compare OEC data against various other on-policy and imitation learning approaches on SWE agent problems and train models using a common rejection sampling (i.e., using environment reward) combined with supervised fine-tuning technique. Experiments find that OEC trajectories show a relative 14% and 13% improvement over traditional imitation learning in the 7b and 32b setting, respectively, on SWE-bench verified. Our results demonstrate the need for combining expert demonstrations with on-policy data for effective multi-turn LM agent training.
LAION-5B: An open large-scale dataset for training next generation image-text models
Oct 16, 2022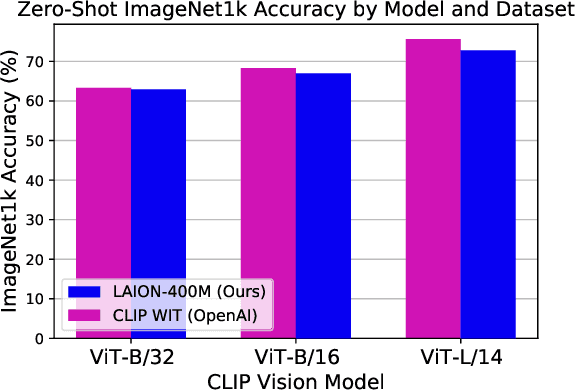

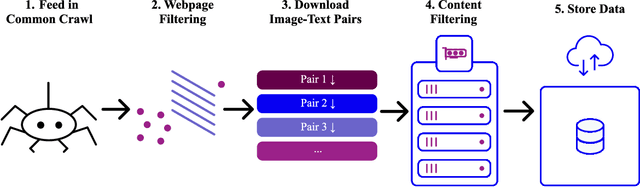
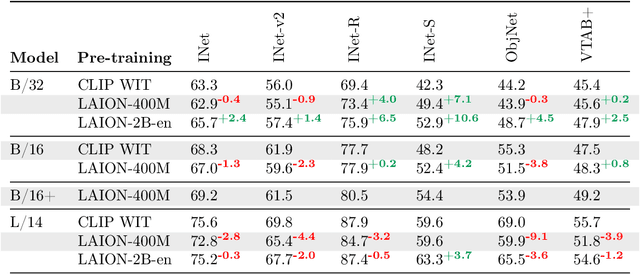
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection. Announcement page https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
LANTERN-RD: Enabling Deep Learning for Mitigation of the Invasive Spotted Lanternfly
May 12, 2022

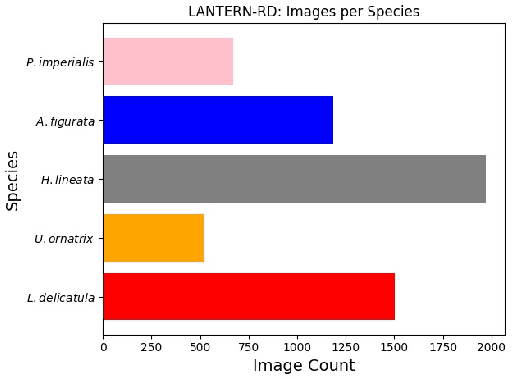
The Spotted Lanternfly (SLF) is an invasive planthopper that threatens the local biodiversity and agricultural economy of regions such as the Northeastern United States and Japan. As researchers scramble to study the insect, there is a great potential for computer vision tasks such as detection, pose estimation, and accurate identification to have important downstream implications in containing the SLF. However, there is currently no publicly available dataset for training such AI models. To enable computer vision applications and motivate advancements to challenge the invasive SLF problem, we propose LANTERN-RD, the first curated image dataset of the spotted lanternfly and its look-alikes, featuring images with varied lighting conditions, diverse backgrounds, and subjects in assorted poses. A VGG16-based baseline CNN validates the potential of this dataset for stimulating fresh computer vision applications to accelerate invasive SLF research. Additionally, we implement the trained model in a simple mobile classification application in order to directly empower responsible public mitigation efforts. The overarching mission of this work is to introduce a novel SLF image dataset and release a classification framework that enables computer vision applications, boosting studies surrounding the invasive SLF and assisting in minimizing its agricultural and economic damage.