 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Reconstruction of Three-Quarter Sampling Measurements Using Recurrent Local Joint Sparse Deconvolution and Extrapolation
May 05, 2022
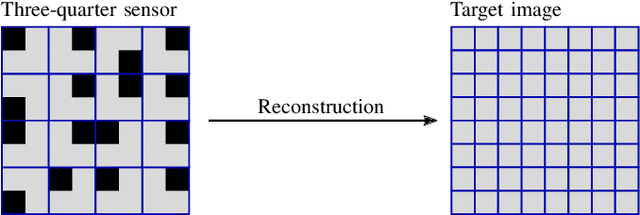
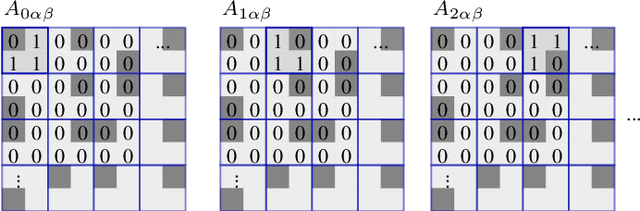
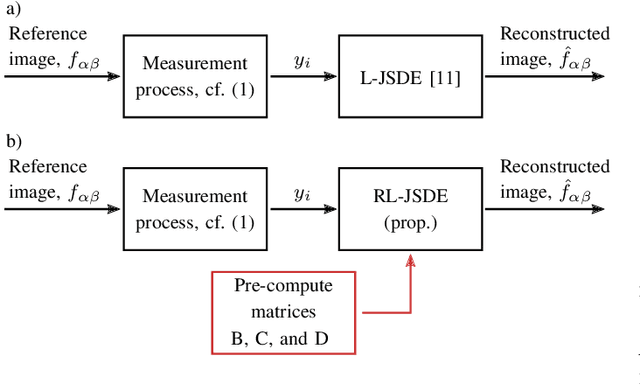
Recently, non-regular three-quarter sampling has shown to deliver an increased image quality of image sensors by using differently oriented L-shaped pixels compared to the same number of square pixels. A three-quarter sampling sensor can be understood as a conventional low-resolution sensor where one quadrant of each square pixel is opaque. Subsequent to the measurement, the data can be reconstructed on a regular grid with twice the resolution in both spatial dimensions using an appropriate reconstruction algorithm. For this reconstruction, local joint sparse deconvolution and extrapolation (L-JSDE) has shown to perform very well. As a disadvantage, L-JSDE requires long computation times of several dozen minutes per megapixel. In this paper, we propose a faster version of L-JSDE called recurrent L-JSDE (RL-JSDE) which is a reformulation of L-JSDE. For reasonable recurrent measurement patterns, RL-JSDE provides significant speedups on both CPU and GPU without sacrificing image quality. Compared to L-JSDE, 20-fold and 733-fold speedups are achieved on CPU and GPU, respectively.
Image simulation for space applications with the SurRender software
Jun 21, 2021



Image Processing algorithms for vision-based navigation require reliable image simulation capacities. In this paper we explain why traditional rendering engines may present limitations that are potentially critical for space applications. We introduce Airbus SurRender software v7 and provide details on features that make it a very powerful space image simulator. We show how SurRender is at the heart of the development processes of our computer vision solutions and we provide a series of illustrations of rendered images for various use cases ranging from Moon and Solar System exploration, to in orbit rendezvous and planetary robotics.
Improving Ensemble Distillation With Weight Averaging and Diversifying Perturbation
Jun 30, 2022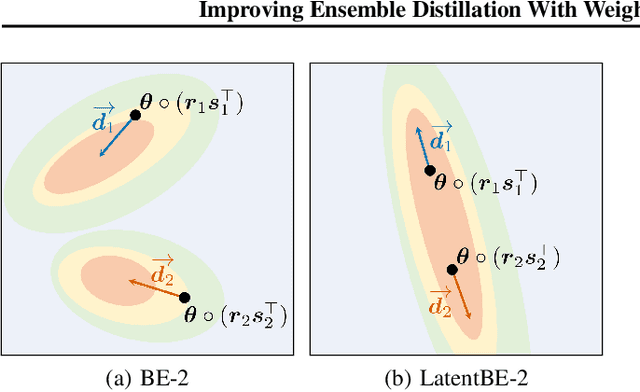

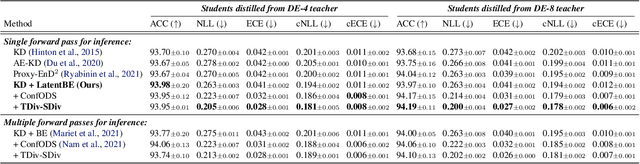

Ensembles of deep neural networks have demonstrated superior performance, but their heavy computational cost hinders applying them for resource-limited environments. It motivates distilling knowledge from the ensemble teacher into a smaller student network, and there are two important design choices for this ensemble distillation: 1) how to construct the student network, and 2) what data should be shown during training. In this paper, we propose a weight averaging technique where a student with multiple subnetworks is trained to absorb the functional diversity of ensemble teachers, but then those subnetworks are properly averaged for inference, giving a single student network with no additional inference cost. We also propose a perturbation strategy that seeks inputs from which the diversities of teachers can be better transferred to the student. Combining these two, our method significantly improves upon previous methods on various image classification tasks.
Generalizable Cross-modality Medical Image Segmentation via Style Augmentation and Dual Normalization
Dec 21, 2021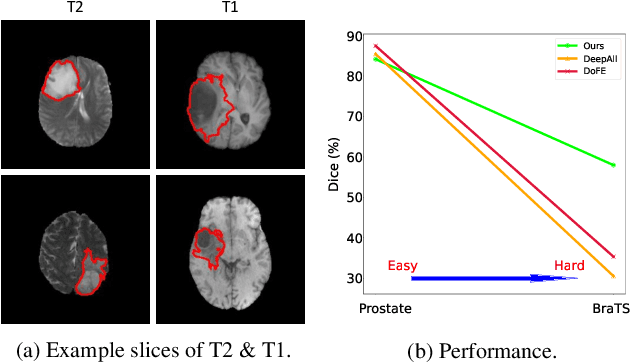
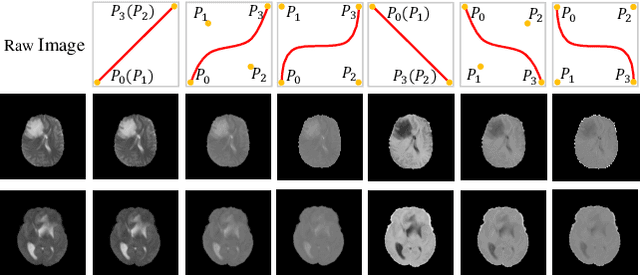
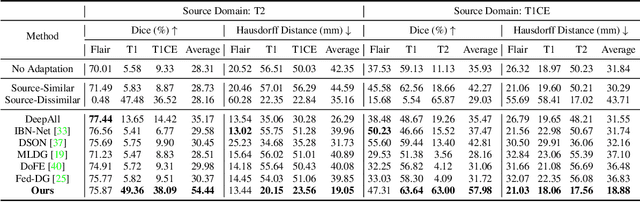
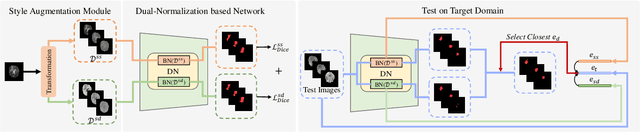
For medical image segmentation, imagine if a model was only trained using MR images in source domain, how about its performance to directly segment CT images in target domain? This setting, namely generalizable cross-modality segmentation, owning its clinical potential, is much more challenging than other related settings, e.g., domain adaptation. To achieve this goal, we in this paper propose a novel dual-normalization module by leveraging the augmented source-similar and source-dissimilar images during our generalizable segmentation. To be specific, given a single source domain, aiming to simulate the possible appearance change in unseen target domains, we first utilize a nonlinear transformation to augment source-similar and source-dissimilar images. Then, to sufficiently exploit these two types of augmentations, our proposed dual-normalization based model employs a shared backbone yet independent batch normalization layer for separate normalization. Afterwards, we put forward a style-based selection scheme to automatically choose the appropriate path in the test stage. Extensive experiments on three publicly available datasets, i.e., BraTS, Cross-Modality Cardiac and Abdominal Multi-Organ dataset, have demonstrated that our method outperforms other state-of-the-art domain generalization methods.
MetaHistoSeg: A Python Framework for Meta Learning in Histopathology Image Segmentation
Sep 29, 2021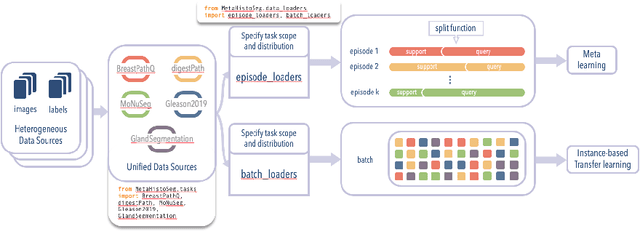

Few-shot learning is a standard practice in most deep learning based histopathology image segmentation, given the relatively low number of digitized slides that are generally available. While many models have been developed for domain specific histopathology image segmentation, cross-domain generalization remains a key challenge for properly validating models. Here, tooling and datasets to benchmark model performance across histopathological domains are lacking. To address this limitation, we introduce MetaHistoSeg - a Python framework that implements unique scenarios in both meta learning and instance based transfer learning. Designed for easy extension to customized datasets and task sampling schemes, the framework empowers researchers with the ability of rapid model design and experimentation. We also curate a histopathology meta dataset - a benchmark dataset for training and validating models on out-of-distribution performance across a range of cancer types. In experiments we showcase the usage of MetaHistoSeg with the meta dataset and find that both meta-learning and instance based transfer learning deliver comparable results on average, but in some cases tasks can greatly benefit from one over the other.
Active Domain Adaptation with Multi-level Contrastive Units for Semantic Segmentation
May 25, 2022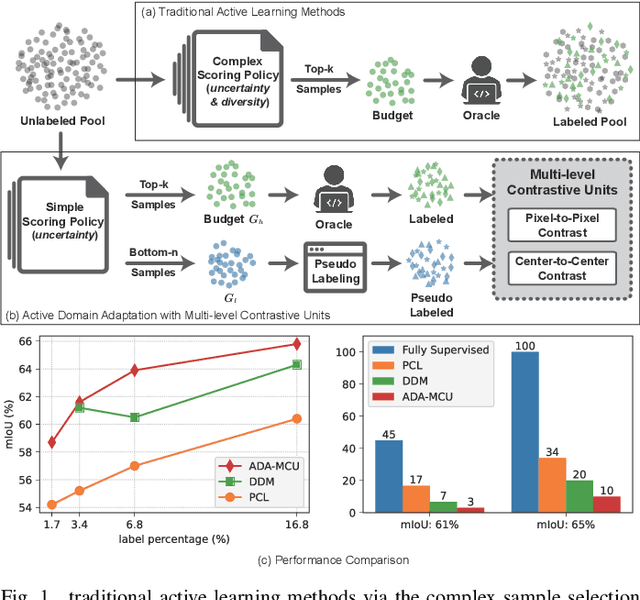
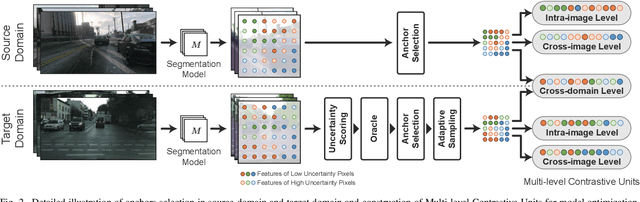
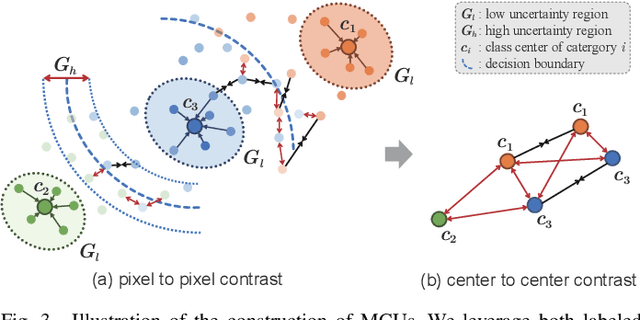
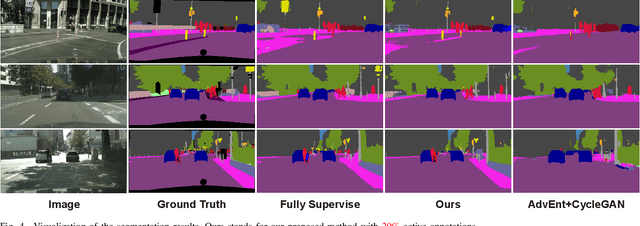
To further reduce the cost of semi-supervised domain adaptation (SSDA) labeling, a more effective way is to use active learning (AL) to annotate a selected subset with specific properties. However, domain adaptation tasks are always addressed in two interactive aspects: domain transfer and the enhancement of discrimination, which requires the selected data to be both uncertain under the model and diverse in feature space. Contrary to active learning in classification tasks, it is usually challenging to select pixels that contain both the above properties in segmentation tasks, leading to the complex design of pixel selection strategy. To address such an issue, we propose a novel Active Domain Adaptation scheme with Multi-level Contrastive Units (ADA-MCU) for semantic image segmentation. A simple pixel selection strategy followed with the construction of multi-level contrastive units is introduced to optimize the model for both domain adaptation and active supervised learning. In practice, MCUs are constructed from intra-image, cross-image, and cross-domain levels by using both labeled and unlabeled pixels. At each level, we define contrastive losses from center-to-center and pixel-to-pixel manners, with the aim of jointly aligning the category centers and reducing outliers near the decision boundaries. In addition, we also introduce a categories correlation matrix to implicitly describe the relationship between categories, which are used to adjust the weights of the losses for MCUs. Extensive experimental results on standard benchmarks show that the proposed method achieves competitive performance against state-of-the-art SSDA methods with 50% fewer labeled pixels and significantly outperforms state-of-the-art with a large margin by using the same level of annotation cost.
Gabor is Enough: Interpretable Deep Denoising with a Gabor Synthesis Dictionary Prior
Apr 23, 2022
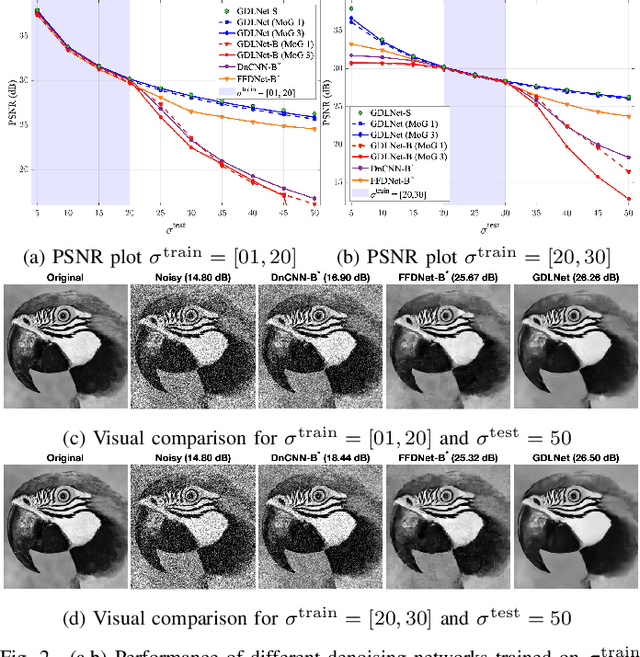

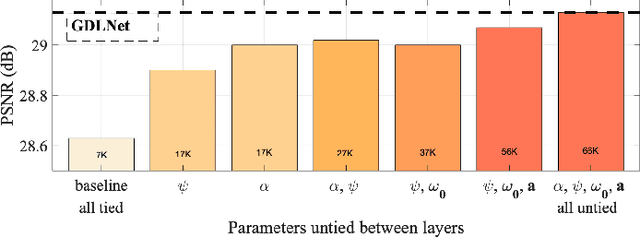
Image processing neural networks, natural and artificial, have a long history with orientation-selectivity, often described mathematically as Gabor filters. Gabor-like filters have been observed in the early layers of CNN classifiers and even throughout low-level image processing networks. In this work, we take this observation to the extreme and explicitly constrain the filters of a natural-image denoising CNN to be learned 2D real Gabor filters. Surprisingly, we find that the proposed network (GDLNet) can achieve near state-of-the-art denoising performance amongst popular fully convolutional neural networks, with only a fraction of the learned parameters. We further verify that this parameterization maintains the noise-level generalization (training vs. inference mismatch) characteristics of the base network, and investigate the contribution of individual Gabor filter parameters to the performance of the denoiser. We present positive findings for the interpretation of dictionary learning networks as performing accelerated sparse-coding via the importance of untied learned scale parameters between network layers. Our network's success suggests that representations used by low-level image processing CNNs can be as simple and interpretable as Gabor filterbanks.
Pyramid Medical Transformer for Medical Image Segmentation
Apr 29, 2021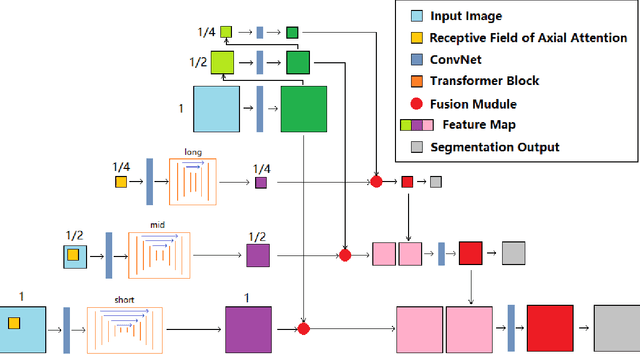
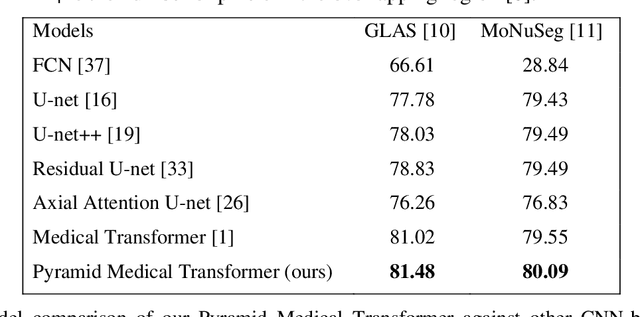
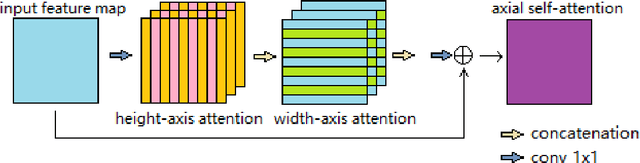
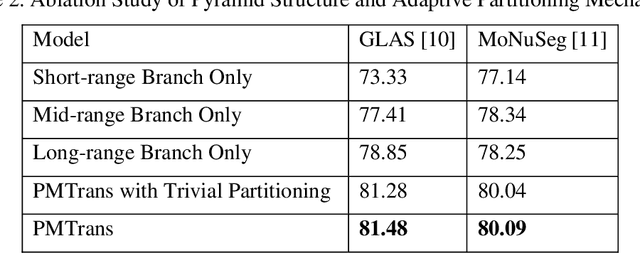
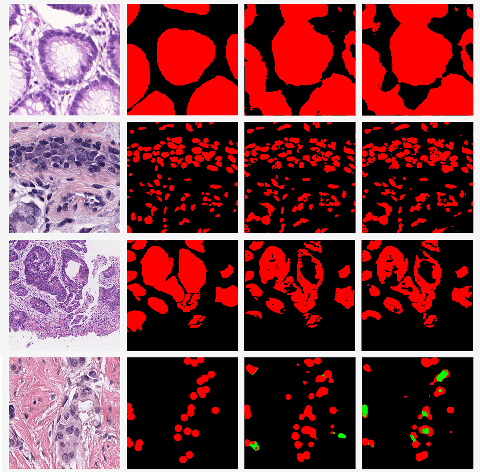
Deep neural networks have been a prevailing technique in the field of medical image processing. However, the most popular convolutional neural networks (CNNs) based methods for medical image segmentation are imperfect because they cannot adequately model long-range pixel relations. Transformers and the self-attention mechanism are recently proposed to effectively learn long-range dependencies by modeling all pairs of word-to-word attention regardless of their positions. The idea has also been extended to the computer vision field by creating and treating image patches as embeddings. Considering the computation complexity for whole image self-attention, current transformer-based models settle for a rigid partitioning scheme that would potentially lose informative relations. Besides, current medical transformers model global context on full resolution images, leading to unnecessary computation costs. To address these issues, we developed a novel method to integrate multi-scale attention and CNN feature extraction using a pyramidal network architecture, namely Pyramid Medical Transformer (PMTrans). The PMTrans captured multi-range relations by working on multi-resolution images. An adaptive partitioning scheme was implemented to retain informative relations and to access different receptive fields efficiently. Experimental results on two medical image datasets, gland segmentation and MoNuSeg datasets, showed that PMTrans outperformed the latest CNN-based and transformer-based models for medical image segmentation.
Revisiting Binary Local Image Description for Resource Limited Devices
Aug 18, 2021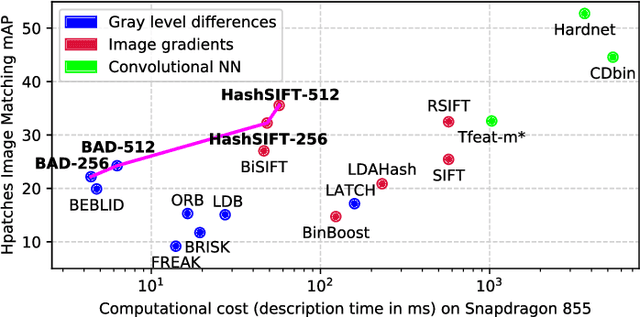
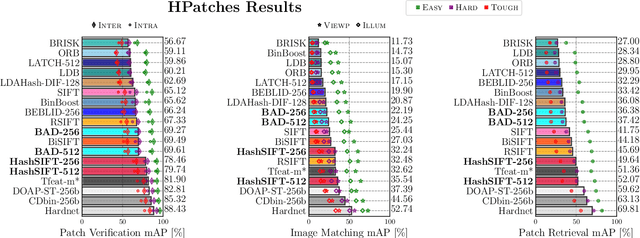
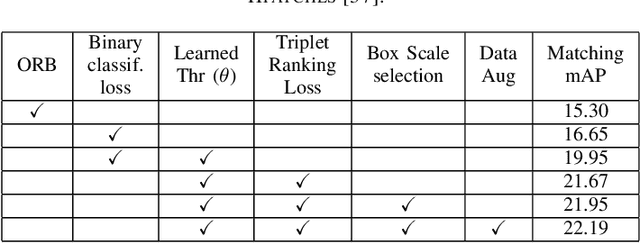
The advent of a panoply of resource limited devices opens up new challenges in the design of computer vision algorithms with a clear compromise between accuracy and computational requirements. In this paper we present new binary image descriptors that emerge from the application of triplet ranking loss, hard negative mining and anchor swapping to traditional features based on pixel differences and image gradients. These descriptors, BAD (Box Average Difference) and HashSIFT, establish new operating points in the state-of-the-art's accuracy vs.\ resources trade-off curve. In our experiments we evaluate the accuracy, execution time and energy consumption of the proposed descriptors. We show that BAD bears the fastest descriptor implementation in the literature while HashSIFT approaches in accuracy that of the top deep learning-based descriptors, being computationally more efficient. We have made the source code public.
Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling
Jul 09, 2022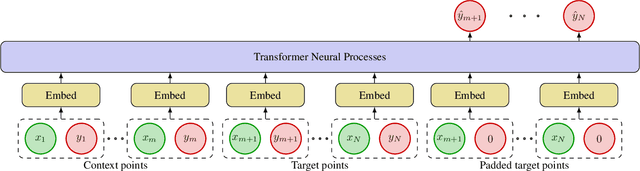
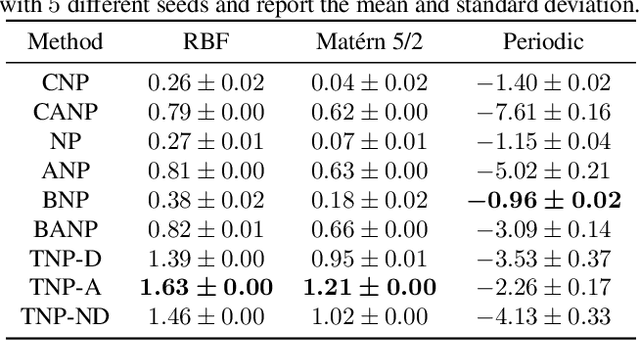
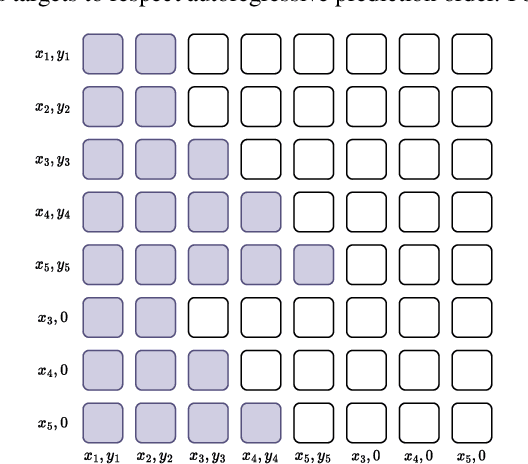
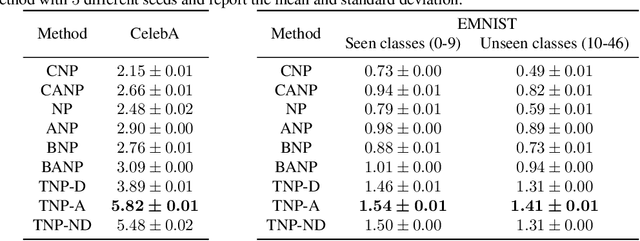
Neural Processes (NPs) are a popular class of approaches for meta-learning. Similar to Gaussian Processes (GPs), NPs define distributions over functions and can estimate uncertainty in their predictions. However, unlike GPs, NPs and their variants suffer from underfitting and often have intractable likelihoods, which limit their applications in sequential decision making. We propose Transformer Neural Processes (TNPs), a new member of the NP family that casts uncertainty-aware meta learning as a sequence modeling problem. We learn TNPs via an autoregressive likelihood-based objective and instantiate it with a novel transformer-based architecture. The model architecture respects the inductive biases inherent to the problem structure, such as invariance to the observed data points and equivariance to the unobserved points. We further investigate knobs within the TNP framework that tradeoff expressivity of the decoding distribution with extra computation. Empirically, we show that TNPs achieve state-of-the-art performance on various benchmark problems, outperforming all previous NP variants on meta regression, image completion, contextual multi-armed bandits, and Bayesian optimization.