 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
It Isn't Sh!tposting, It's My CAT Posting
May 18, 2022
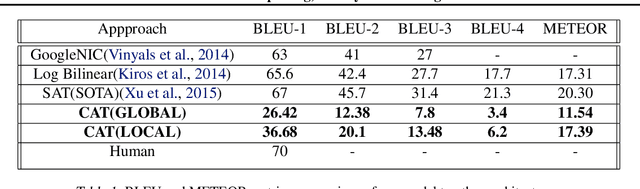


In this paper, we describe a novel architecture which can generate hilarious captions for a given input image. The architecture is split into two halves, i.e. image captioning and hilarious text conversion. The architecture starts with a pre-trained CNN model, VGG16 in this implementation, and applies attention LSTM on it to generate normal caption. These normal captions then are fed forward to our hilarious text conversion transformer which converts this text into something hilarious while maintaining the context of the input image. The architecture can also be split into two halves and only the seq2seq transformer can be used to generate hilarious caption by inputting a sentence.This paper aims to help everyday user to be more lazy and hilarious at the same time by generating captions using CATNet.
UniToBrain dataset: a Brain Perfusion Dataset
Aug 01, 2022The CT perfusion (CTP) is a medical exam for measuring the passage of a bolus of contrast solution through the brain on a pixel-by-pixel basis. The objective is to draw "perfusion maps" (namely cerebral blood volume, cerebral blood flow and time to peak) very rapidly for ischemic lesions, and to be able to distinguish between core and penumubra regions. A precise and quick diagnosis, in a context of ischemic stroke, can determine the fate of the brain tissues and guide the intervention and treatment in emergency conditions. In this work we present UniToBrain dataset, the very first open-source dataset for CTP. It comprises a cohort of more than a hundred of patients, and it is accompanied by patients metadata and ground truth maps obtained with state-of-the-art algorithms. We also propose a novel neural networks-based algorithm, using the European library ECVL and EDDL for the image processing and developing deep learning models respectively. The results obtained by the neural network models match the ground truth and open the road towards potential sub-sampling of the required number of CT maps, which impose heavy radiation doses to the patients.
Image scaling by de la Vallée-Poussin filtered interpolation
Sep 28, 2021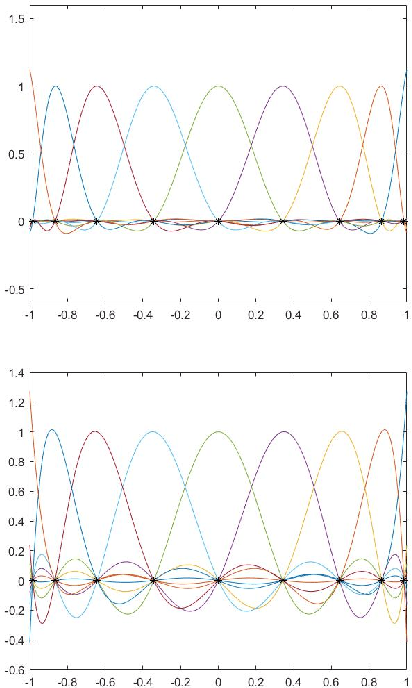
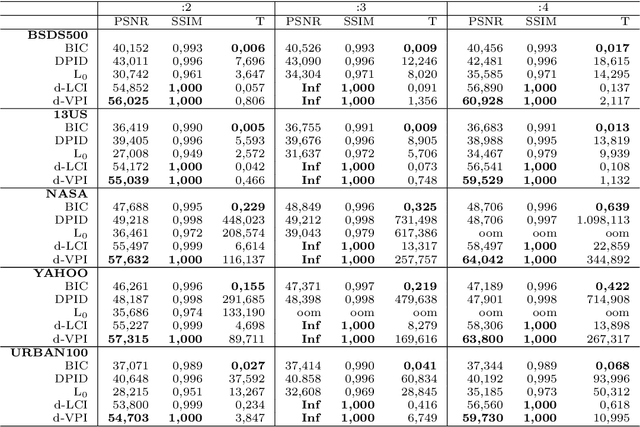
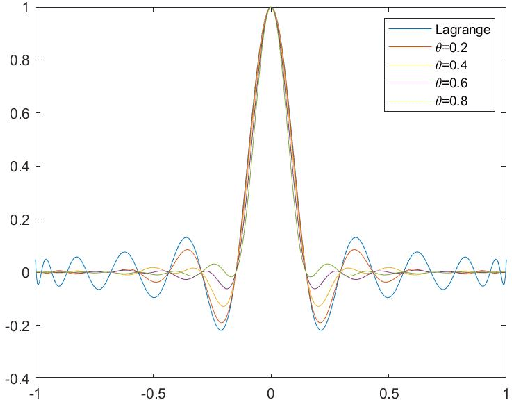
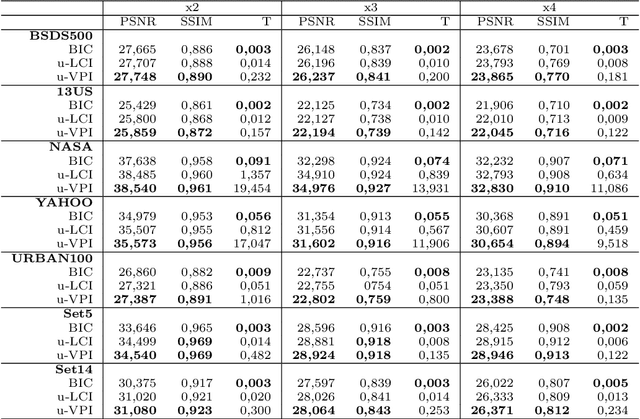
We present a new image scaling method both for downscaling and upscaling, running with any scale factor or desired size. It is based on the sampling of an approximating bivariate polynomial, which globally interpolates the data and is defined by a filter of de la Vall\'ee Poussin type whose action ray is suitable regulated to improve the approximation. The method has been tested on a significant number of different image datasets. The results are evaluated in qualitative and quantitative terms and compared with other available competitive methods. The perceived quality of the resulting scaled images is such that important details are preserved, and the appearance of artifacts is low. Very high-quality measure values in downscaling and the competitive ones in upscaling evidence the effectiveness of the method. Good visual quality, limited computational effort, and moderate memory demanding make the method suitable for real-world applications.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 26, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Data privacy protection in microscopic image analysis for material data mining
Nov 09, 2021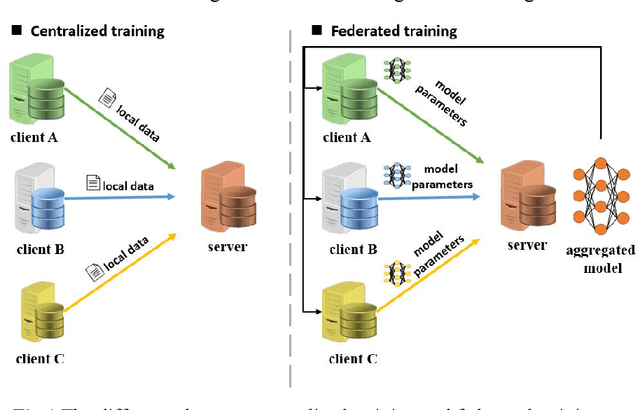
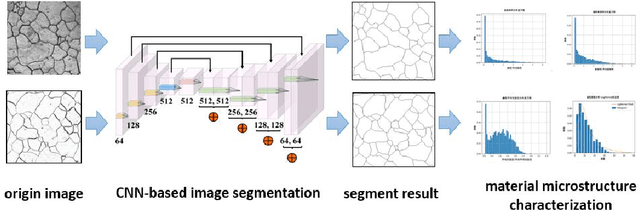
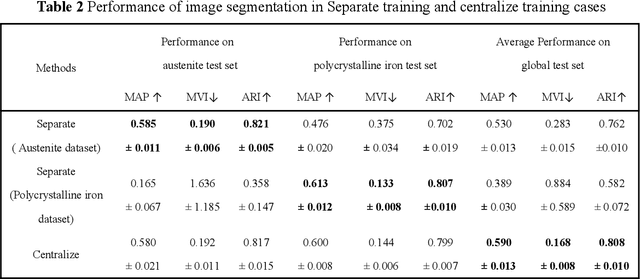
Recent progress in material data mining has been driven by high-capacity models trained on large datasets. However, collecting experimental data has been extremely costly owing to the amount of human effort and expertise required. Therefore, material researchers are often reluctant to easily disclose their private data, which leads to the problem of data island, and it is difficult to collect a large amount of data to train high-quality models. In this study, a material microstructure image feature extraction algorithm FedTransfer based on data privacy protection is proposed. The core contributions are as follows: 1) the federated learning algorithm is introduced into the polycrystalline microstructure image segmentation task to make full use of different user data to carry out machine learning, break the data island and improve the model generalization ability under the condition of ensuring the privacy and security of user data; 2) A data sharing strategy based on style transfer is proposed. By sharing style information of images that is not urgent for user confidentiality, it can reduce the performance penalty caused by the distribution difference of data among different users.
A Survey of Deep Fake Detection for Trial Courts
May 31, 2022
Recently, image manipulation has achieved rapid growth due to the advancement of sophisticated image editing tools. A recent surge of generated fake imagery and videos using neural networks is DeepFake. DeepFake algorithms can create fake images and videos that humans cannot distinguish from authentic ones. (GANs) have been extensively used for creating realistic images without accessing the original images. Therefore, it is become essential to detect fake videos to avoid spreading false information. This paper presents a survey of methods used to detect DeepFakes and datasets available for detecting DeepFakes in the literature to date. We present extensive discussions and research trends related to DeepFake technologies.
MR-Contrast-Aware Image-to-Image Translations with Generative Adversarial Networks
Apr 03, 2021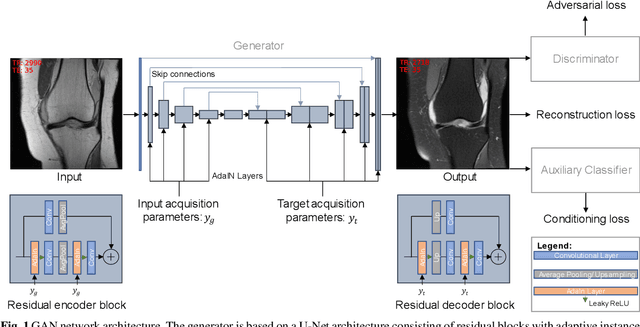
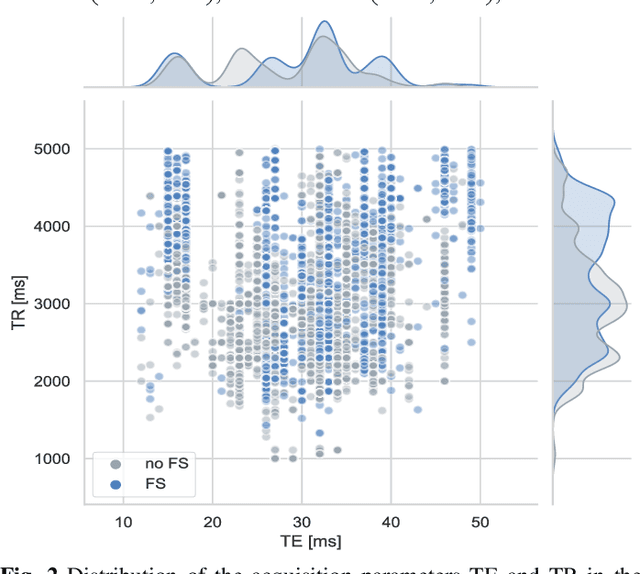
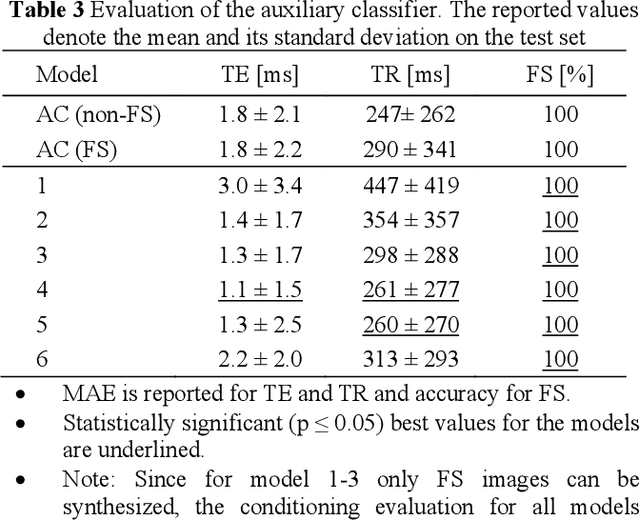
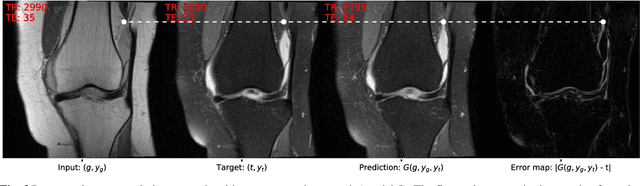
Purpose A Magnetic Resonance Imaging (MRI) exam typically consists of several sequences that yield different image contrasts. Each sequence is parameterized through multiple acquisition parameters that influence image contrast, signal-to-noise ratio, acquisition time, and/or resolution. Depending on the clinical indication, different contrasts are required by the radiologist to make a diagnosis. As MR sequence acquisition is time consuming and acquired images may be corrupted due to motion, a method to synthesize MR images with adjustable contrast properties is required. Methods Therefore, we trained an image-to-image generative adversarial network conditioned on the MR acquisition parameters repetition time and echo time. Our approach is motivated by style transfer networks, whereas the "style" for an image is explicitly given in our case, as it is determined by the MR acquisition parameters our network is conditioned on. Results This enables us to synthesize MR images with adjustable image contrast. We evaluated our approach on the fastMRI dataset, a large set of publicly available MR knee images, and show that our method outperforms a benchmark pix2pix approach in the translation of non-fat-saturated MR images to fat-saturated images. Our approach yields a peak signal-to-noise ratio and structural similarity of 24.48 and 0.66, surpassing the pix2pix benchmark model significantly. Conclusion Our model is the first that enables fine-tuned contrast synthesis, which can be used to synthesize missing MR contrasts or as a data augmentation technique for AI training in MRI.
Image coding for machines: an end-to-end learned approach
Aug 23, 2021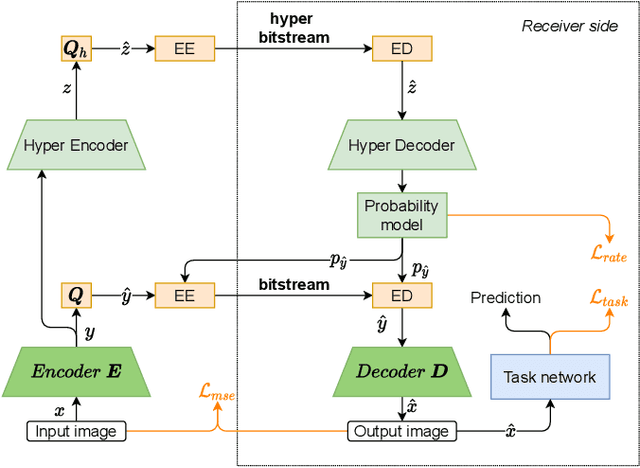

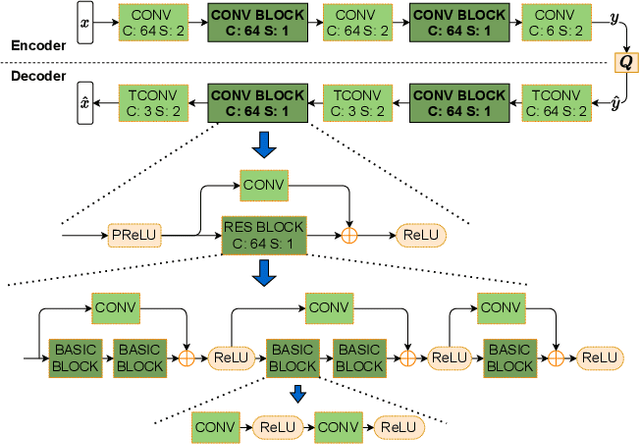
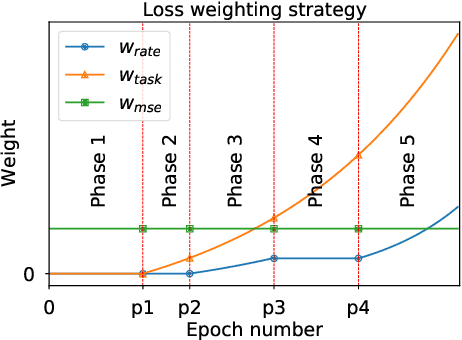
Over recent years, deep learning-based computer vision systems have been applied to images at an ever-increasing pace, oftentimes representing the only type of consumption for those images. Given the dramatic explosion in the number of images generated per day, a question arises: how much better would an image codec targeting machine-consumption perform against state-of-the-art codecs targeting human-consumption? In this paper, we propose an image codec for machines which is neural network (NN) based and end-to-end learned. In particular, we propose a set of training strategies that address the delicate problem of balancing competing loss functions, such as computer vision task losses, image distortion losses, and rate loss. Our experimental results show that our NN-based codec outperforms the state-of-the-art Versa-tile Video Coding (VVC) standard on the object detection and instance segmentation tasks, achieving -37.87% and -32.90% of BD-rate gain, respectively, while being fast thanks to its compact size. To the best of our knowledge, this is the first end-to-end learned machine-targeted image codec.
* Added typo fixes since the version accepted in IEEE ICASSP2021
Revisiting the "Video" in Video-Language Understanding
Jun 03, 2022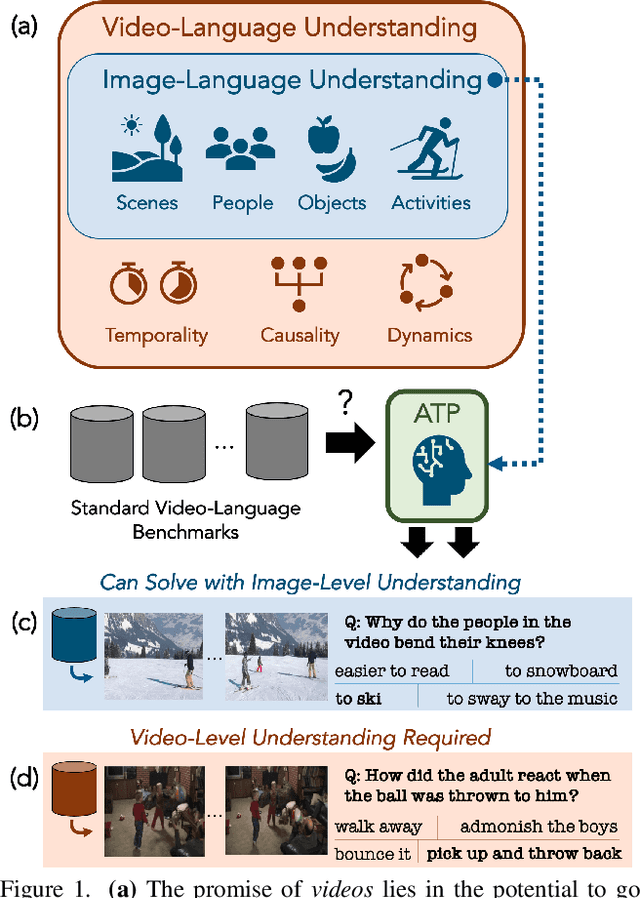


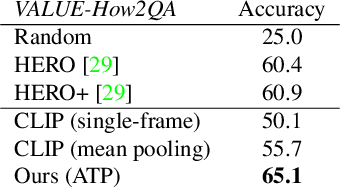
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
Large Scale Transfer Learning for Differentially Private Image Classification
May 06, 2022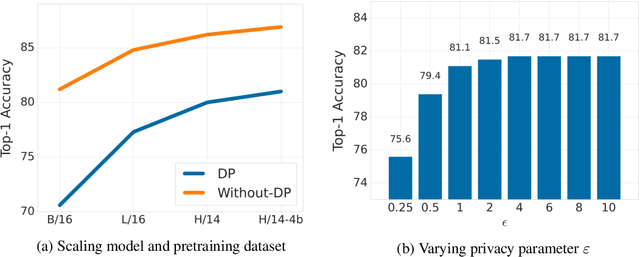
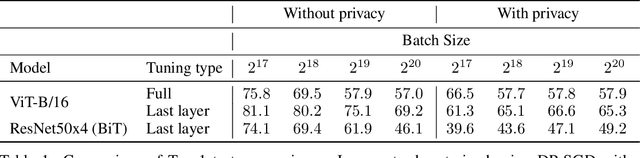
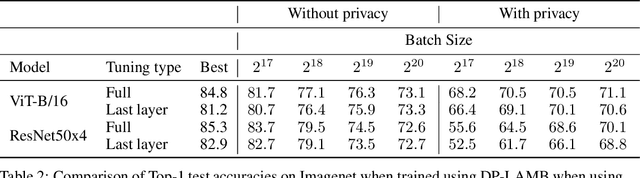
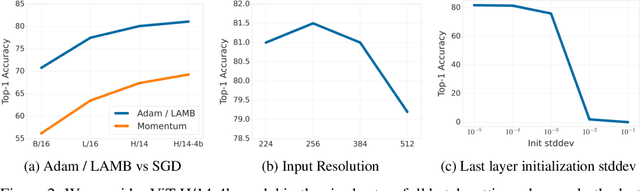
Differential Privacy (DP) provides a formal framework for training machine learning models with individual example level privacy. Training models with DP protects the model against leakage of sensitive data in a potentially adversarial setting. In the field of deep learning, Differentially Private Stochastic Gradient Descent (DP-SGD) has emerged as a popular private training algorithm. Private training using DP-SGD protects against leakage by injecting noise into individual example gradients, such that the trained model weights become nearly independent of the use any particular training example. While this result is quite appealing, the computational cost of training large-scale models with DP-SGD is substantially higher than non-private training. This is further exacerbated by the fact that increasing the number of parameters leads to larger degradation in utility with DP. In this work, we zoom in on the ImageNet dataset and demonstrate that similar to the non-private case, pre-training over-parameterized models on a large public dataset can lead to substantial gains when the model is finetuned privately. Moreover, by systematically comparing private and non-private models across a range of huge batch sizes, we find that similar to non-private setting, choice of optimizer can further improve performance substantially with DP. By switching from DP-SGD to DP-LAMB we saw improvement of up to 20$\%$ points (absolute). Finally, we show that finetuning just the last layer for a \emph{single step} in the full batch setting leads to both SOTA results of 81.7 $\%$ under a wide privacy budget range of $\epsilon \in [4, 10]$ and $\delta$ = $10^{-6}$ while minimizing the computational overhead substantially.