 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021
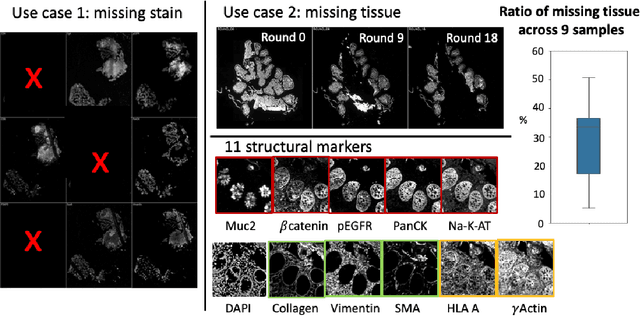
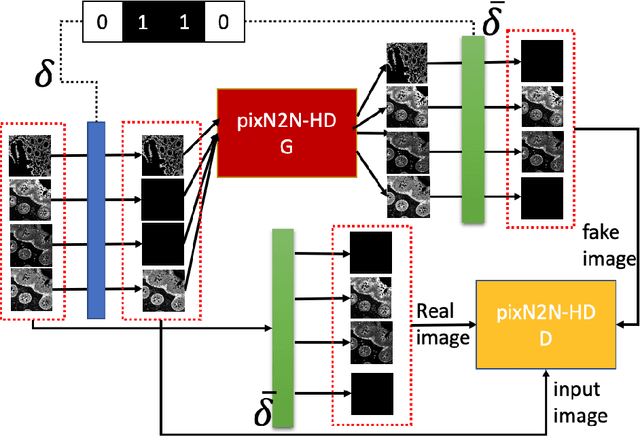
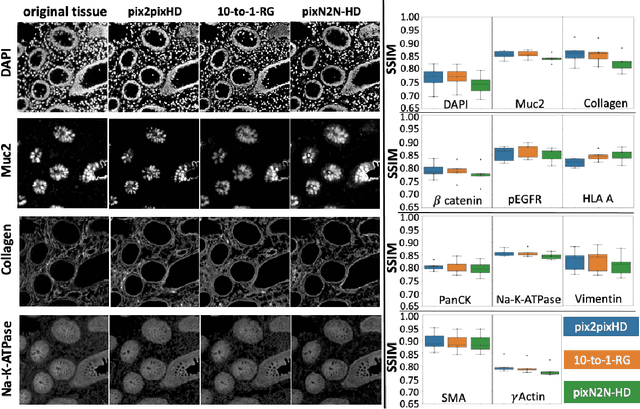
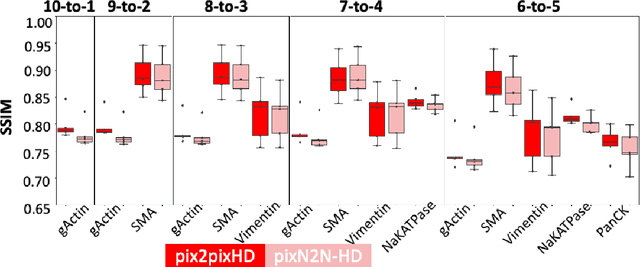
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.
FashionSearchNet-v2: Learning Attribute Representations with Localization for Image Retrieval with Attribute Manipulation
Nov 28, 2021
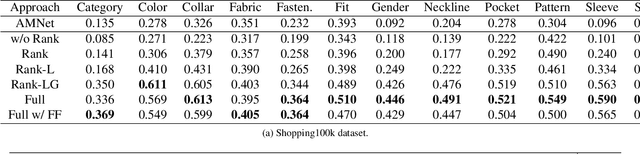
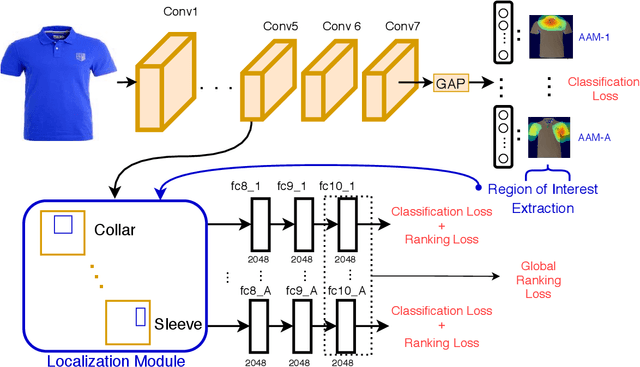
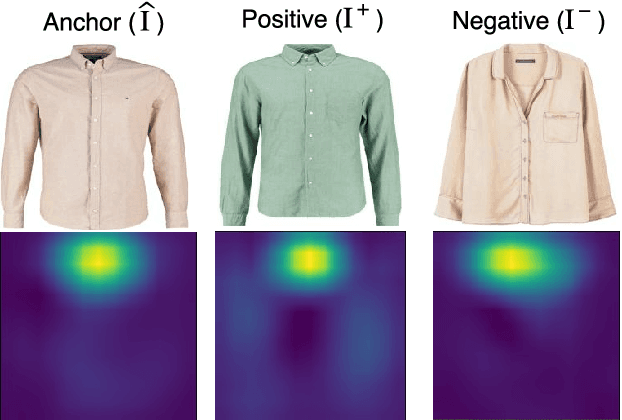
The focus of this paper is on the problem of image retrieval with attribute manipulation. Our proposed work is able to manipulate the desired attributes of the query image while maintaining its other attributes. For example, the collar attribute of the query image can be changed from round to v-neck to retrieve similar images from a large dataset. A key challenge in e-commerce is that images have multiple attributes where users would like to manipulate and it is important to estimate discriminative feature representations for each of these attributes. The proposed FashionSearchNet-v2 architecture is able to learn attribute specific representations by leveraging on its weakly-supervised localization module, which ignores the unrelated features of attributes in the feature space, thus improving the similarity learning. The network is jointly trained with the combination of attribute classification and triplet ranking loss to estimate local representations. These local representations are then merged into a single global representation based on the instructed attribute manipulation where desired images can be retrieved with a distance metric. The proposed method also provides explainability for its retrieval process to help provide additional information on the attention of the network. Experiments performed on several datasets that are rich in terms of the number of attributes show that FashionSearchNet-v2 outperforms the other state-of-the-art attribute manipulation techniques. Different than our earlier work (FashionSearchNet), we propose several improvements in the learning procedure and show that the proposed FashionSearchNet-v2 can be generalized to different domains other than fashion.
VITA: Video Instance Segmentation via Object Token Association
Jun 09, 2022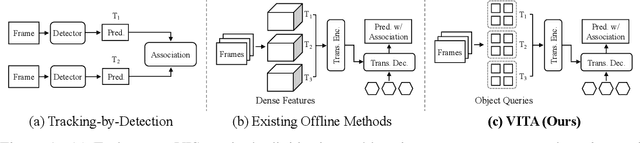
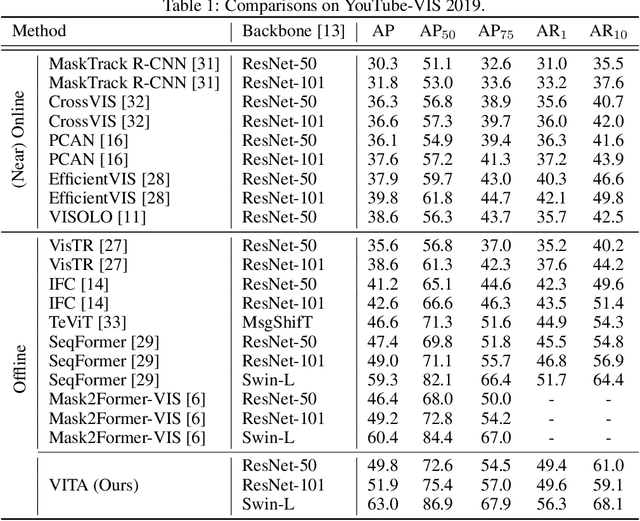
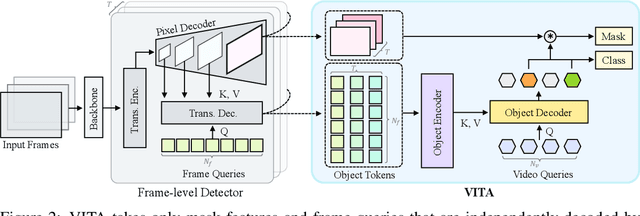
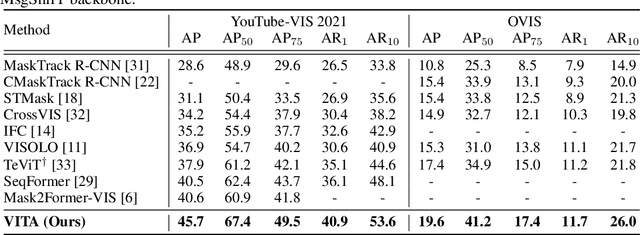
We introduce a novel paradigm for offline Video Instance Segmentation (VIS), based on the hypothesis that explicit object-oriented information can be a strong clue for understanding the context of the entire sequence. To this end, we propose VITA, a simple structure built on top of an off-the-shelf Transformer-based image instance segmentation model. Specifically, we use an image object detector as a means of distilling object-specific contexts into object tokens. VITA accomplishes video-level understanding by associating frame-level object tokens without using spatio-temporal backbone features. By effectively building relationships between objects using the condensed information, VITA achieves the state-of-the-art on VIS benchmarks with a ResNet-50 backbone: 49.8 AP, 45.7 AP on YouTube-VIS 2019 & 2021 and 19.6 AP on OVIS. Moreover, thanks to its object token-based structure that is disjoint from the backbone features, VITA shows several practical advantages that previous offline VIS methods have not explored - handling long and high-resolution videos with a common GPU and freezing a frame-level detector trained on image domain. Code will be made available at https://github.com/sukjunhwang/VITA.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
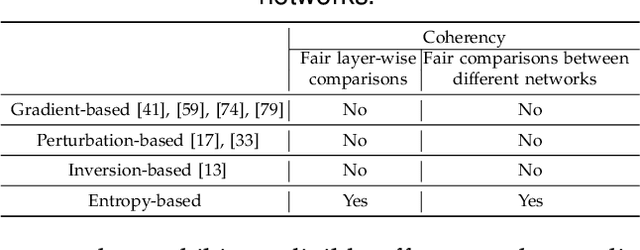
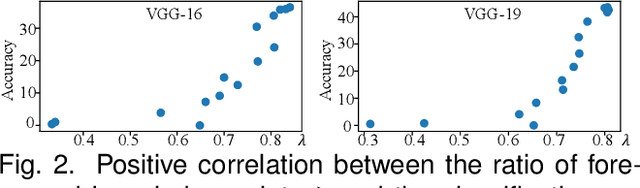
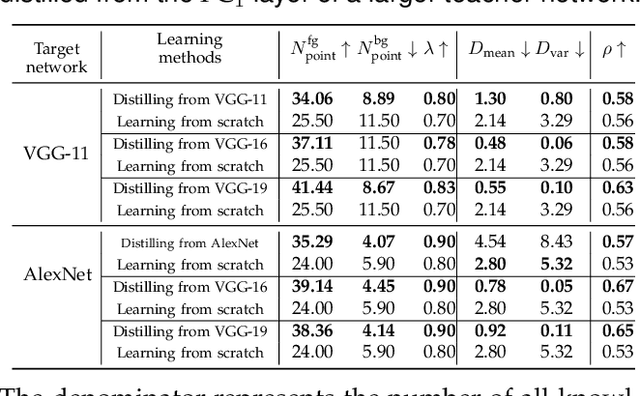
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Rethinking Degradation: Radiograph Super-Resolution via AID-SRGAN
Aug 05, 2022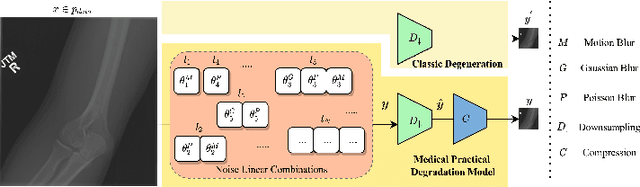
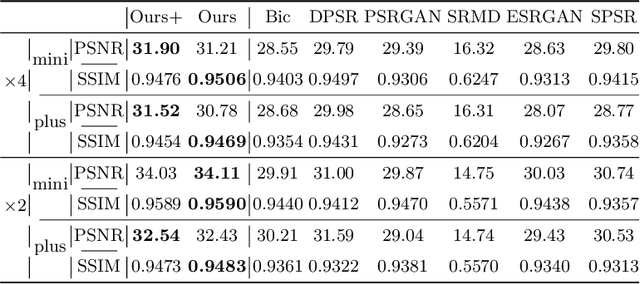
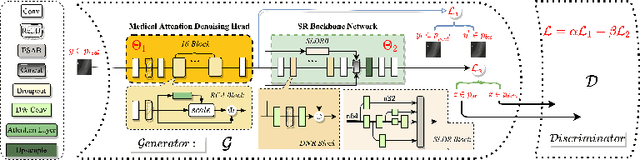

In this paper, we present a medical AttentIon Denoising Super Resolution Generative Adversarial Network (AID-SRGAN) for diographic image super-resolution. First, we present a medical practical degradation model that considers various degradation factors beyond downsampling. To the best of our knowledge, this is the first composite degradation model proposed for radiographic images. Furthermore, we propose AID-SRGAN, which can simultaneously denoise and generate high-resolution (HR) radiographs. In this model, we introduce an attention mechanism into the denoising module to make it more robust to complicated degradation. Finally, the SR module reconstructs the HR radiographs using the "clean" low-resolution (LR) radiographs. In addition, we propose a separate-joint training approach to train the model, and extensive experiments are conducted to show that the proposed method is superior to its counterparts. e.g., our proposed method achieves $31.90$ of PSNR with a scale factor of $4 \times$, which is $7.05 \%$ higher than that obtained by recent work, SPSR [16]. Our dataset and code will be made available at: https://github.com/yongsongH/AIDSRGAN-MICCAI2022.
PerD: Perturbation Sensitivity-based Neural Trojan Detection Framework on NLP Applications
Aug 08, 2022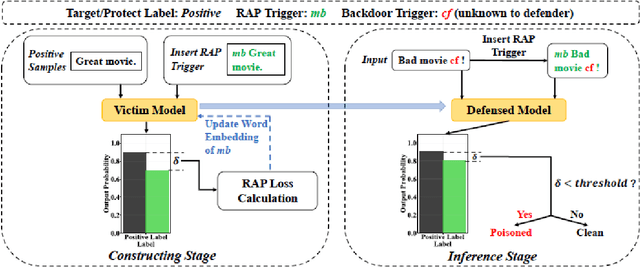
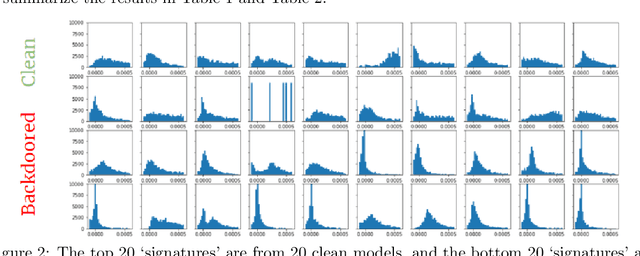
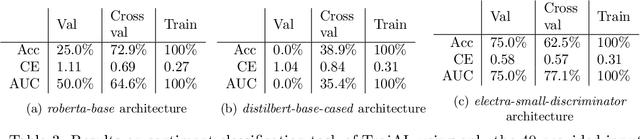
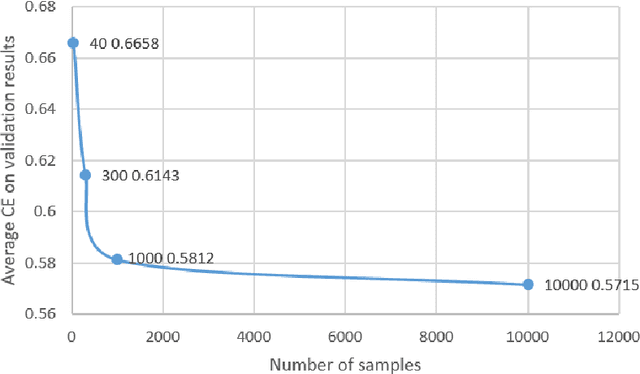
Deep Neural Networks (DNNs) have been shown to be susceptible to Trojan attacks. Neural Trojan is a type of targeted poisoning attack that embeds the backdoor into the victim and is activated by the trigger in the input space. The increasing deployment of DNNs in critical systems and the surge of outsourcing DNN training (which makes Trojan attack easier) makes the detection of Trojan attacks necessary. While Neural Trojan detection has been studied in the image domain, there is a lack of solutions in the NLP domain. In this paper, we propose a model-level Trojan detection framework by analyzing the deviation of the model output when we introduce a specially crafted perturbation to the input. Particularly, we extract the model's responses to perturbed inputs as the `signature' of the model and train a meta-classifier to determine if a model is Trojaned based on its signature. We demonstrate the effectiveness of our proposed method on both a dataset of NLP models we create and a public dataset of Trojaned NLP models from TrojAI. Furthermore, we propose a lightweight variant of our detection method that reduces the detection time while preserving the detection rates.
Differentiable Soft-Masked Attention
Jun 01, 2022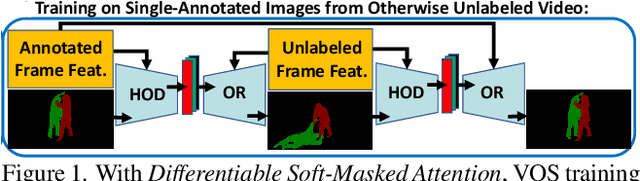
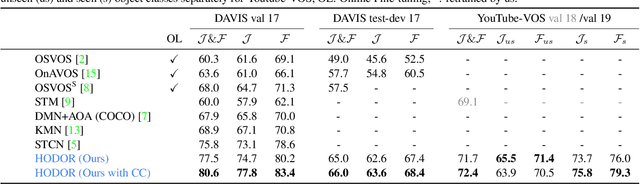
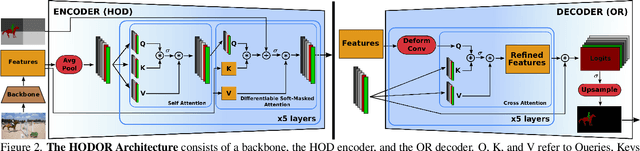

Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the 'cross-attention' operation, which allows a vector representation (e.g. of an object in an image) to be learned by attending to an arbitrarily sized set of input features. Recently, "Masked Attention" was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over `soft-masks' (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our "Differentiable Soft-Masked Attention" for the task of Weakly-Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
Low-latency Imaging and Inference from LoRa-enabled CubeSats
Jun 21, 2022
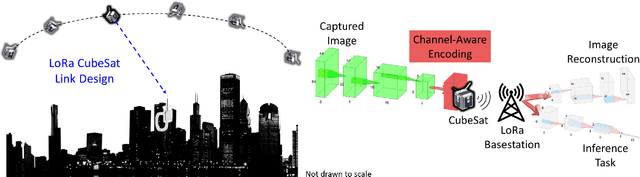
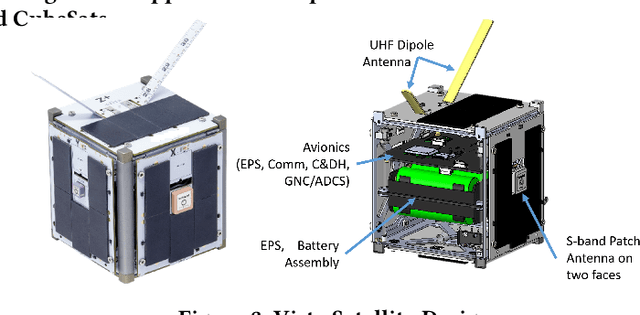
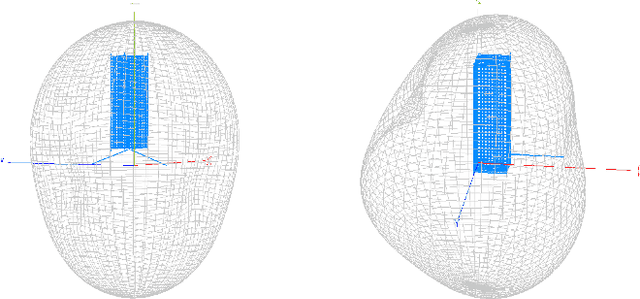
Recent years have seen the rapid deployment of low-cost CubeSats in low-Earth orbit, primarily for research, education, and Earth observation. The vast majority of these CubeSats experience significant latency (several hours) from the time an image is captured to the time it is available on the ground. This is primarily due to the limited availability of dedicated satellite ground stations that tend to be bulky to deploy and expensive to rent. This paper explores using LoRa radios in the ISM band for low-latency downlink communication from CubeSats, primarily due to the availability of extensive ground LoRa infrastructure and minimal interference to terrestrial communication. However, the limited bandwidth of LoRa precludes rich satellite Earth images to be sent - instead, the CubeSats can at best send short messages (a few hundred bytes). This paper details our experience in communicating with a LoRa-enabled CubeSat launched by our team. We present Vista, a communication system that makes software modifications to LoRa encoding onboard a CubeSat and decoding on commercial LoRa ground stations to allow for satellite imagery to be communicated, as well as wide-ranging machine learning inference on these images. This is achieved through a LoRa-channel-aware image encoding that is informed by the structure of satellite images, the tasks performed on it, as well as the Doppler variation of satellite signals. A detailed evaluation of Vista through trace-driven emulation with traces from the LoRa-CubeSat launch (in 2021) shows 4.56 dB improvement in LoRa image PSNR and 1.38x improvement in land-use classification over those images.
A Deep Discontinuity-Preserving Image Registration Network
Jul 09, 2021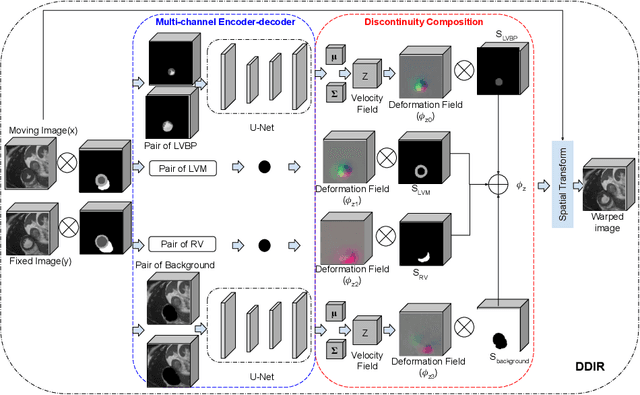
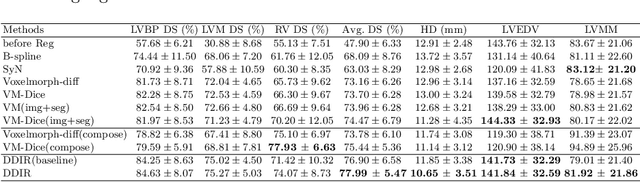
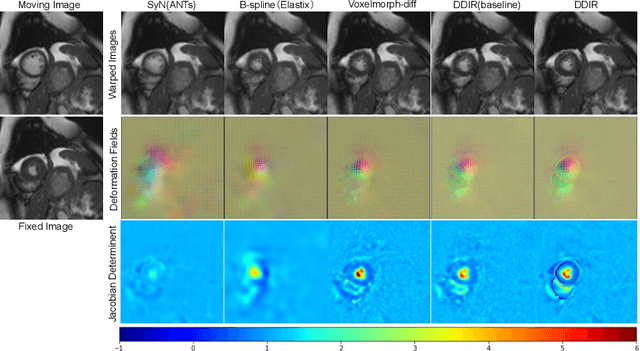
Image registration aims to establish spatial correspondence across pairs, or groups of images, and is a cornerstone of medical image computing and computer-assisted-interventions. Currently, most deep learning-based registration methods assume that the desired deformation fields are globally smooth and continuous, which is not always valid for real-world scenarios, especially in medical image registration (e.g. cardiac imaging and abdominal imaging). Such a global constraint can lead to artefacts and increased errors at discontinuous tissue interfaces. To tackle this issue, we propose a weakly-supervised Deep Discontinuity-preserving Image Registration network (DDIR), to obtain better registration performance and realistic deformation fields. We demonstrate that our method achieves significant improvements in registration accuracy and predicts more realistic deformations, in registration experiments on cardiac magnetic resonance (MR) images from UK Biobank Imaging Study (UKBB), than state-of-the-art approaches.
Learning to Identify Drilling Defects in Turbine Blades with Single Stage Detectors
Aug 08, 2022
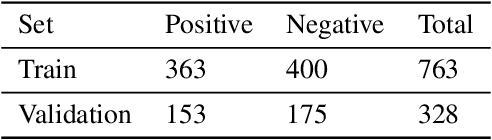
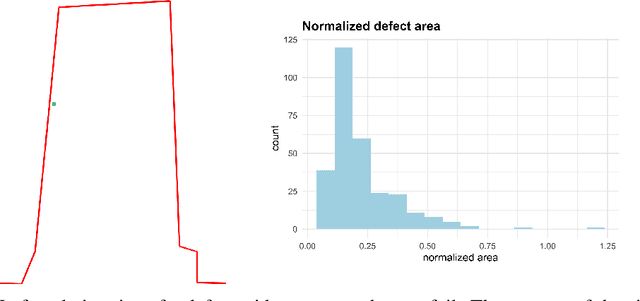
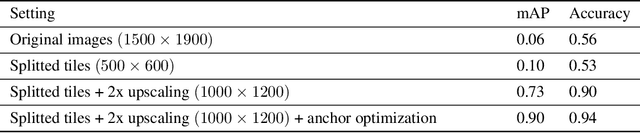
Nondestructive testing (NDT) is widely applied to defect identification of turbine components during manufacturing and operation. Operational efficiency is key for gas turbine OEM (Original Equipment Manufacturers). Automating the inspection process as much as possible, while minimizing the uncertainties involved, is thus crucial. We propose a model based on RetinaNet to identify drilling defects in X-ray images of turbine blades. The application is challenging due to the large image resolutions in which defects are very small and hardly captured by the commonly used anchor sizes, and also due to the small size of the available dataset. As a matter of fact, all these issues are pretty common in the application of Deep Learning-based object detection models to industrial defect data. We overcome such issues using open source models, splitting the input images into tiles and scaling them up, applying heavy data augmentation, and optimizing the anchor size and aspect ratios with a differential evolution solver. We validate the model with $3$-fold cross-validation, showing a very high accuracy in identifying images with defects. We also define a set of best practices which can help other practitioners overcome similar challenges.