 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Non-Local Contrastive Attention for Image Super-Resolution
Jan 11, 2022

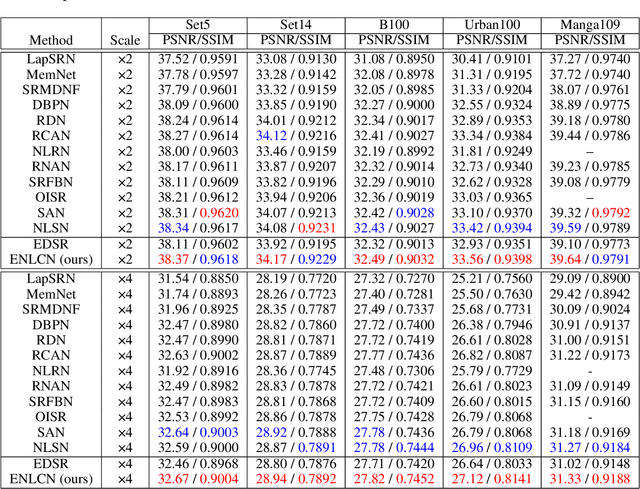
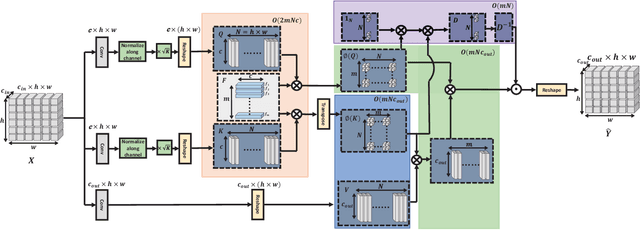

Non-Local Attention (NLA) brings significant improvement for Single Image Super-Resolution (SISR) by leveraging intrinsic feature correlation in natural images. However, NLA gives noisy information large weights and consumes quadratic computation resources with respect to the input size, limiting its performance and application. In this paper, we propose a novel Efficient Non-Local Contrastive Attention (ENLCA) to perform long-range visual modeling and leverage more relevant non-local features. Specifically, ENLCA consists of two parts, Efficient Non-Local Attention (ENLA) and Sparse Aggregation. ENLA adopts the kernel method to approximate exponential function and obtains linear computation complexity. For Sparse Aggregation, we multiply inputs by an amplification factor to focus on informative features, yet the variance of approximation increases exponentially. Therefore, contrastive learning is applied to further separate relevant and irrelevant features. To demonstrate the effectiveness of ENLCA, we build an architecture called Efficient Non-Local Contrastive Network (ENLCN) by adding a few of our modules in a simple backbone. Extensive experimental results show that ENLCN reaches superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
Cascaded Cross MLP-Mixer GANs for Cross-View Image Translation
Oct 19, 2021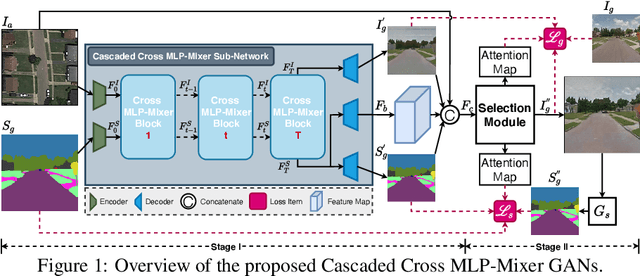
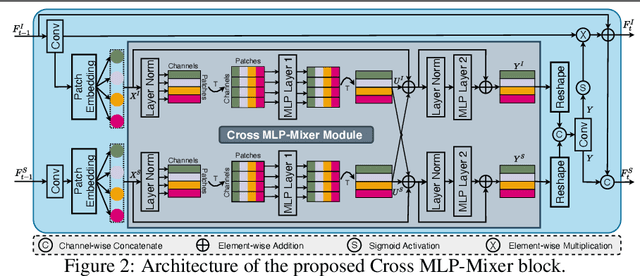
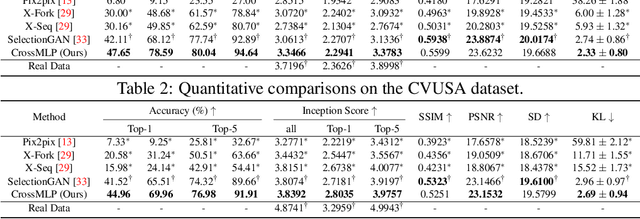

It is hard to generate an image at target view well for previous cross-view image translation methods that directly adopt a simple encoder-decoder or U-Net structure, especially for drastically different views and severe deformation cases. To ease this problem, we propose a novel two-stage framework with a new Cascaded Cross MLP-Mixer (CrossMLP) sub-network in the first stage and one refined pixel-level loss in the second stage. In the first stage, the CrossMLP sub-network learns the latent transformation cues between image code and semantic map code via our novel CrossMLP blocks. Then the coarse results are generated progressively under the guidance of those cues. Moreover, in the second stage, we design a refined pixel-level loss that eases the noisy semantic label problem with more reasonable regularization in a more compact fashion for better optimization. Extensive experimental results on Dayton~\cite{vo2016localizing} and CVUSA~\cite{workman2015wide} datasets show that our method can generate significantly better results than state-of-the-art methods. The source code and trained models are available at https://github.com/Amazingren/CrossMLP.
End-to-End Neuro-Symbolic Architecture for Image-to-Image Reasoning Tasks
Jun 06, 2021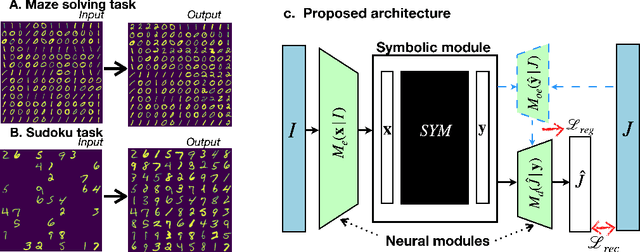
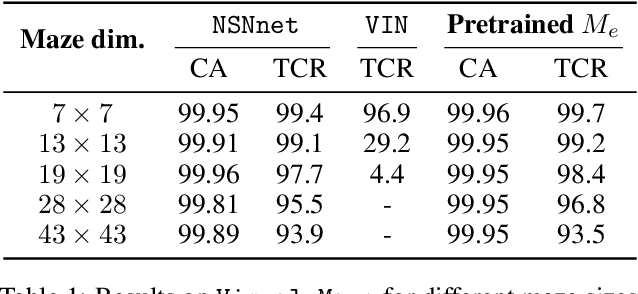

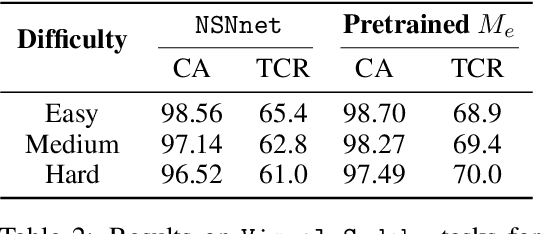
Neural models and symbolic algorithms have recently been combined for tasks requiring both perception and reasoning. Neural models ground perceptual input into a conceptual vocabulary, on which a classical reasoning algorithm is applied to generate output. A key limitation is that such neural-to-symbolic models can only be trained end-to-end for tasks where the output space is symbolic. In this paper, we study neural-symbolic-neural models for reasoning tasks that require a conversion from an image input (e.g., a partially filled sudoku) to an image output (e.g., the image of the completed sudoku). While designing such a three-step hybrid architecture may be straightforward, the key technical challenge is end-to-end training -- how to backpropagate without intermediate supervision through the symbolic component. We propose NSNnet, an architecture that combines an image reconstruction loss with a novel output encoder to generate a supervisory signal, develops update algorithms that leverage policy gradient methods for supervision, and optimizes loss using a novel subsampling heuristic. We experiment on problem settings where symbolic algorithms are easily specified: a visual maze solving task and a visual Sudoku solver where the supervision is in image form. Experiments show high accuracy with significantly less data compared to purely neural approaches.
End-to-end Learning for Image-based Detection of Molecular Alterations in Digital Pathology
Jun 30, 2022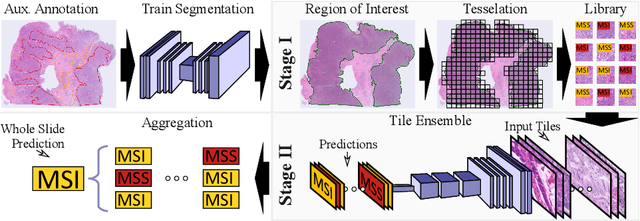
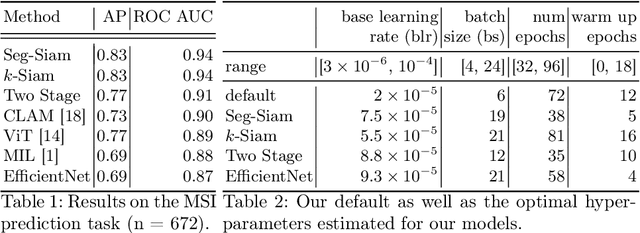
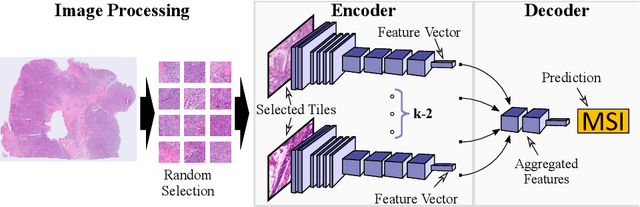
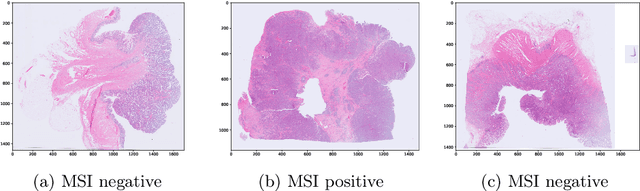
Current approaches for classification of whole slide images (WSI) in digital pathology predominantly utilize a two-stage learning pipeline. The first stage identifies areas of interest (e.g. tumor tissue), while the second stage processes cropped tiles from these areas in a supervised fashion. During inference, a large number of tiles are combined into a unified prediction for the entire slide. A major drawback of such approaches is the requirement for task-specific auxiliary labels which are not acquired in clinical routine. We propose a novel learning pipeline for WSI classification that is trainable end-to-end and does not require any auxiliary annotations. We apply our approach to predict molecular alterations for a number of different use-cases, including detection of microsatellite instability in colorectal tumors and prediction of specific mutations for colon, lung, and breast cancer cases from The Cancer Genome Atlas. Results reach AUC scores of up to 94% and are shown to be competitive with state of the art two-stage pipelines. We believe our approach can facilitate future research in digital pathology and contribute to solve a large range of problems around the prediction of cancer phenotypes, hopefully enabling personalized therapies for more patients in future.
Modeling Human Preference and Stochastic Error for Medical Image Segmentation with Multiple Annotators
Nov 26, 2021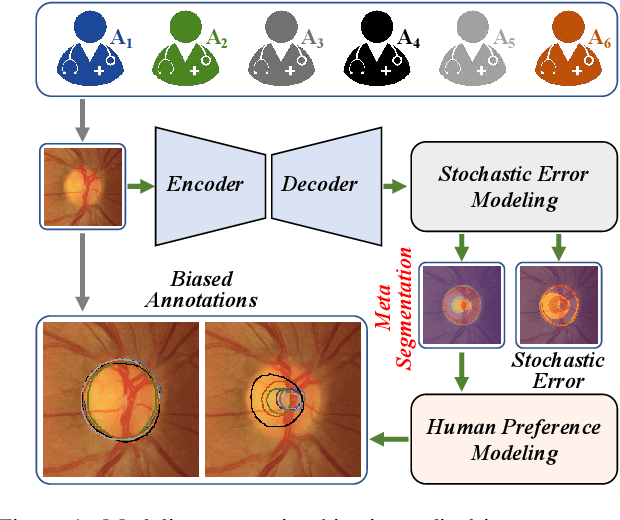
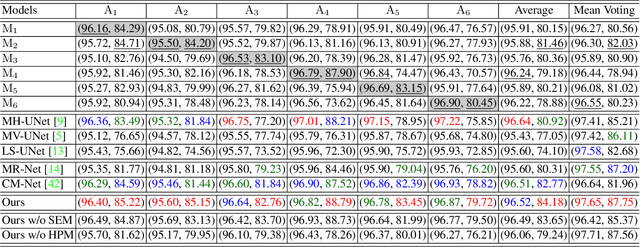
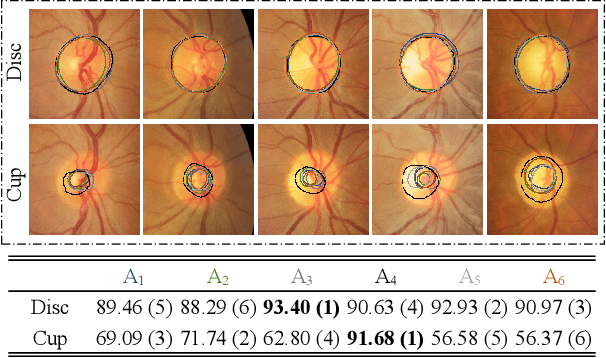
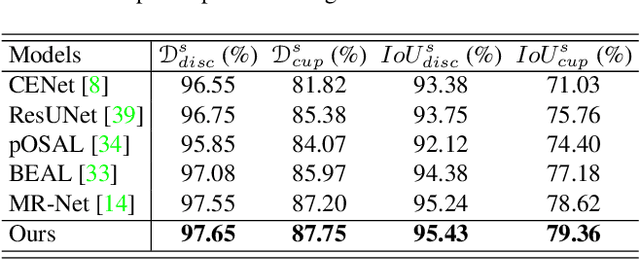
Manual annotation of medical images is highly subjective, leading to inevitable and huge annotation biases. Deep learning models may surpass human performance on a variety of tasks, but they may also mimic or amplify these biases. Although we can have multiple annotators and fuse their annotations to reduce stochastic errors, we cannot use this strategy to handle the bias caused by annotators' preferences. In this paper, we highlight the issue of annotator-related biases on medical image segmentation tasks, and propose a Preference-involved Annotation Distribution Learning (PADL) framework to address it from the perspective of disentangling an annotator's preference from stochastic errors using distribution learning so as to produce not only a meta segmentation but also the segmentation possibly made by each annotator. Under this framework, a stochastic error modeling (SEM) module estimates the meta segmentation map and average stochastic error map, and a series of human preference modeling (HPM) modules estimate each annotator's segmentation and the corresponding stochastic error. We evaluated our PADL framework on two medical image benchmarks with different imaging modalities, which have been annotated by multiple medical professionals, and achieved promising performance on all five medical image segmentation tasks.
A Projection-Based K-space Transformer Network for Undersampled Radial MRI Reconstruction with Limited Training Subjects
Jun 15, 2022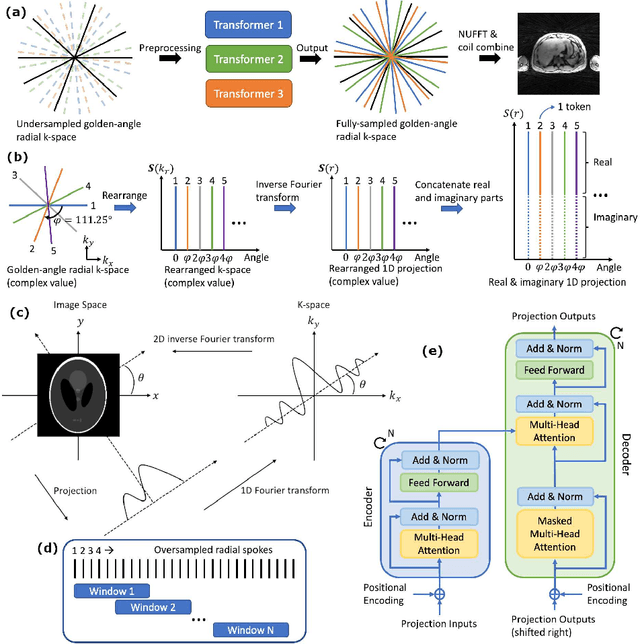
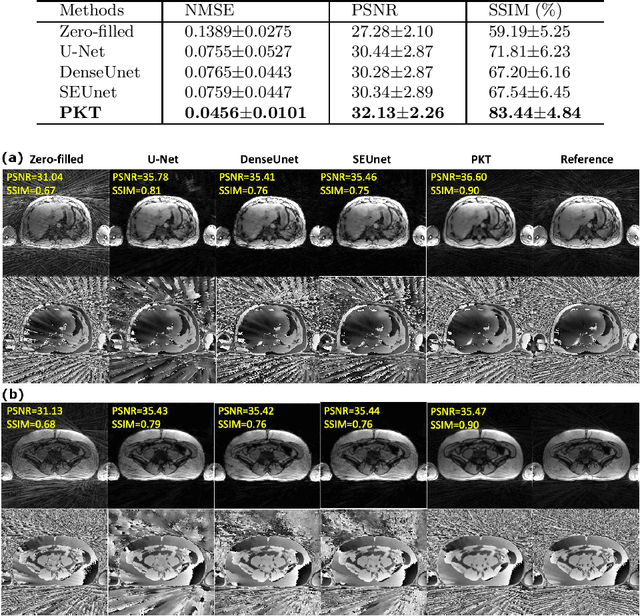
The recent development of deep learning combined with compressed sensing enables fast reconstruction of undersampled MR images and has achieved state-of-the-art performance for Cartesian k-space trajectories. However, non-Cartesian trajectories such as the radial trajectory need to be transformed onto a Cartesian grid in each iteration of the network training, slowing down the training process and posing inconvenience and delay during training. Multiple iterations of nonuniform Fourier transform in the networks offset the deep learning advantage of fast inference. Current approaches typically either work on image-to-image networks or grid the non-Cartesian trajectories before the network training to avoid the repeated gridding process. However, the image-to-image networks cannot ensure the k-space data consistency in the reconstructed images and the pre-processing of non-Cartesian k-space leads to gridding errors which cannot be compensated by the network training. Inspired by the Transformer network to handle long-range dependencies in sequence transduction tasks, we propose to rearrange the radial spokes to sequential data based on the chronological order of acquisition and use the Transformer to predict unacquired radial spokes from acquired ones. We propose novel data augmentation methods to generate a large amount of training data from a limited number of subjects. The network can be generated to different anatomical structures. Experimental results show superior performance of the proposed framework compared to state-of-the-art deep neural networks.
MLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling
Sep 24, 2021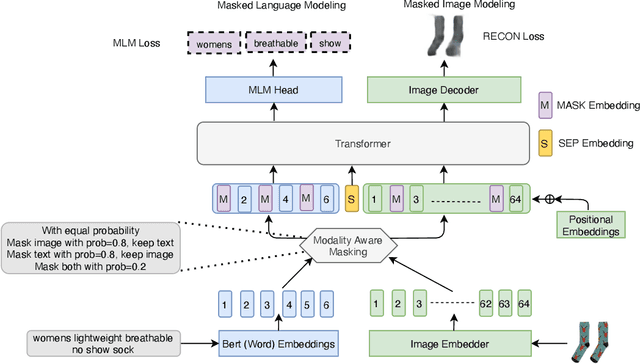

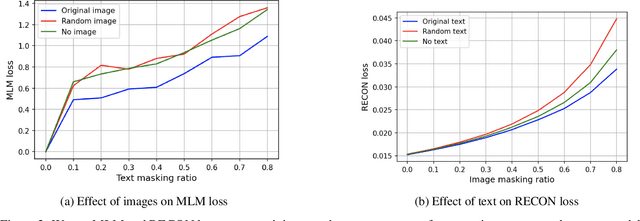
Vision-and-Language Pre-training (VLP) improves model performance for downstream tasks that require image and text inputs. Current VLP approaches differ on (i) model architecture (especially image embedders), (ii) loss functions, and (iii) masking policies. Image embedders are either deep models like ResNet or linear projections that directly feed image-pixels into the transformer. Typically, in addition to the Masked Language Modeling (MLM) loss, alignment-based objectives are used for cross-modality interaction, and RoI feature regression and classification tasks for Masked Image-Region Modeling (MIRM). Both alignment and MIRM objectives mostly do not have ground truth. Alignment-based objectives require pairings of image and text and heuristic objective functions. MIRM relies on object detectors. Masking policies either do not take advantage of multi-modality or are strictly coupled with alignments generated by other models. In this paper, we present Masked Language and Image Modeling (MLIM) for VLP. MLIM uses two loss functions: Masked Language Modeling (MLM) loss and image reconstruction (RECON) loss. We propose Modality Aware Masking (MAM) to boost cross-modality interaction and take advantage of MLM and RECON losses that separately capture text and image reconstruction quality. Using MLM + RECON tasks coupled with MAM, we present a simplified VLP methodology and show that it has better downstream task performance on a proprietary e-commerce multi-modal dataset.
On the Activation Function Dependence of the Spectral Bias of Neural Networks
Aug 10, 2022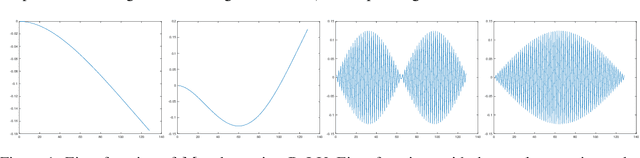
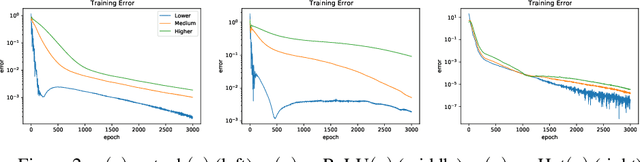
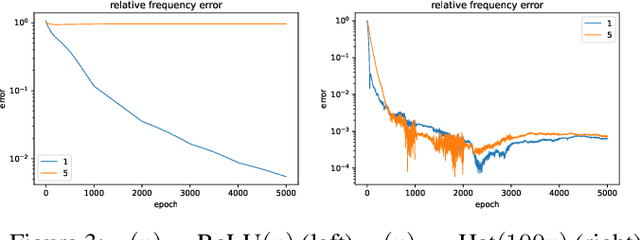
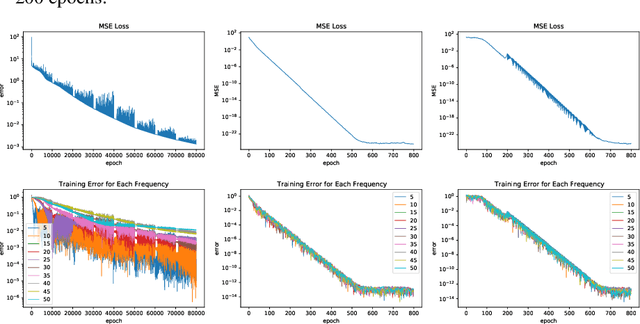
Neural networks are universal function approximators which are known to generalize well despite being dramatically overparameterized. We study this phenomenon from the point of view of the spectral bias of neural networks. Our contributions are two-fold. First, we provide a theoretical explanation for the spectral bias of ReLU neural networks by leveraging connections with the theory of finite element methods. Second, based upon this theory we predict that switching the activation function to a piecewise linear B-spline, namely the Hat function, will remove this spectral bias, which we verify empirically in a variety of settings. Our empirical studies also show that neural networks with the Hat activation function are trained significantly faster using stochastic gradient descent and ADAM. Combined with previous work showing that the Hat activation function also improves generalization accuracy on image classification tasks, this indicates that using the Hat activation provides significant advantages over the ReLU on certain problems.
Apple Counting using Convolutional Neural Networks
Aug 24, 2022



Estimating accurate and reliable fruit and vegetable counts from images in real-world settings, such as orchards, is a challenging problem that has received significant recent attention. Estimating fruit counts before harvest provides useful information for logistics planning. While considerable progress has been made toward fruit detection, estimating the actual counts remains challenging. In practice, fruits are often clustered together. Therefore, methods that only detect fruits fail to offer general solutions to estimate accurate fruit counts. Furthermore, in horticultural studies, rather than a single yield estimate, finer information such as the distribution of the number of apples per cluster is desirable. In this work, we formulate fruit counting from images as a multi-class classification problem and solve it by training a Convolutional Neural Network. We first evaluate the per-image accuracy of our method and compare it with a state-of-the-art method based on Gaussian Mixture Models over four test datasets. Even though the parameters of the Gaussian Mixture Model-based method are specifically tuned for each dataset, our network outperforms it in three out of four datasets with a maximum of 94\% accuracy. Next, we use the method to estimate the yield for two datasets for which we have ground truth. Our method achieved 96-97\% accuracies. For additional details please see our video here: https://www.youtube.com/watch?v=Le0mb5P-SYc}{https://www.youtube.com/watch?v=Le0mb5P-SYc.
Weakly Supervised Airway Orifice Segmentation in Video Bronchoscopy
Aug 24, 2022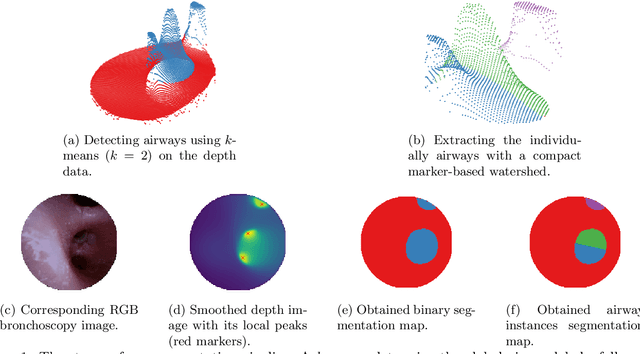
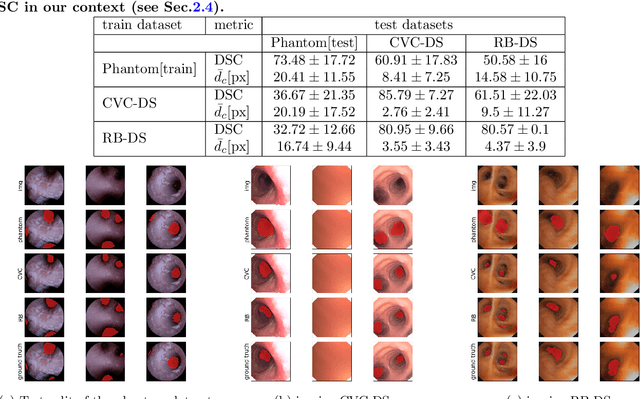
Video bronchoscopy is routinely conducted for biopsies of lung tissue suspected for cancer, monitoring of COPD patients and clarification of acute respiratory problems at intensive care units. The navigation within complex bronchial trees is particularly challenging and physically demanding, requiring long-term experiences of physicians. This paper addresses the automatic segmentation of bronchial orifices in bronchoscopy videos. Deep learning-based approaches to this task are currently hampered due to the lack of readily-available ground truth segmentation data. Thus, we present a data-driven pipeline consisting of a k-means followed by a compact marker-based watershed algorithm which enables to generate airway instance segmentation maps from given depth images. In this way, these traditional algorithms serve as weak supervision for training a shallow CNN directly on RGB images solely based on a phantom dataset. We evaluate generalization capabilities of this model on two in-vivo datasets covering 250 frames on 21 different bronchoscopies. We demonstrate that its performance is comparable to those models being directly trained on in-vivo data, reaching an average error of 11 vs 5 pixels for the detected centers of the airway segmentation by an image resolution of 128x128. Our quantitative and qualitative results indicate that in the context of video bronchoscopy, phantom data and weak supervision using non-learning-based approaches enable to gain a semantic understanding of airway structures.