 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling
Paper and Code
Sep 24, 2021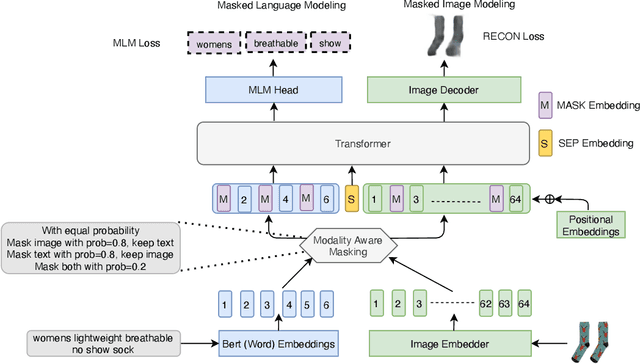

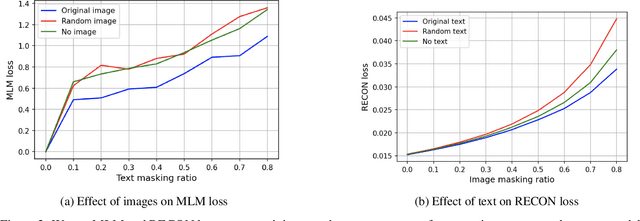
Vision-and-Language Pre-training (VLP) improves model performance for downstream tasks that require image and text inputs. Current VLP approaches differ on (i) model architecture (especially image embedders), (ii) loss functions, and (iii) masking policies. Image embedders are either deep models like ResNet or linear projections that directly feed image-pixels into the transformer. Typically, in addition to the Masked Language Modeling (MLM) loss, alignment-based objectives are used for cross-modality interaction, and RoI feature regression and classification tasks for Masked Image-Region Modeling (MIRM). Both alignment and MIRM objectives mostly do not have ground truth. Alignment-based objectives require pairings of image and text and heuristic objective functions. MIRM relies on object detectors. Masking policies either do not take advantage of multi-modality or are strictly coupled with alignments generated by other models. In this paper, we present Masked Language and Image Modeling (MLIM) for VLP. MLIM uses two loss functions: Masked Language Modeling (MLM) loss and image reconstruction (RECON) loss. We propose Modality Aware Masking (MAM) to boost cross-modality interaction and take advantage of MLM and RECON losses that separately capture text and image reconstruction quality. Using MLM + RECON tasks coupled with MAM, we present a simplified VLP methodology and show that it has better downstream task performance on a proprietary e-commerce multi-modal dataset.