 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PVBM: A Python Vasculature Biomarker Toolbox Based On Retinal Blood Vessel Segmentation
Jul 31, 2022
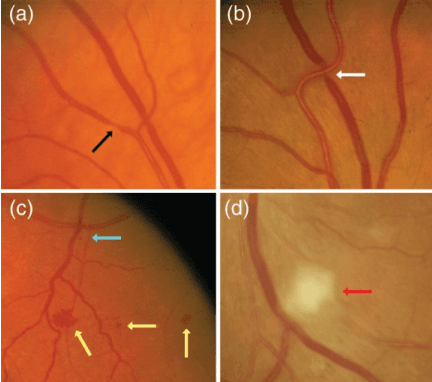
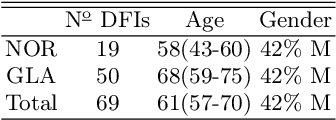
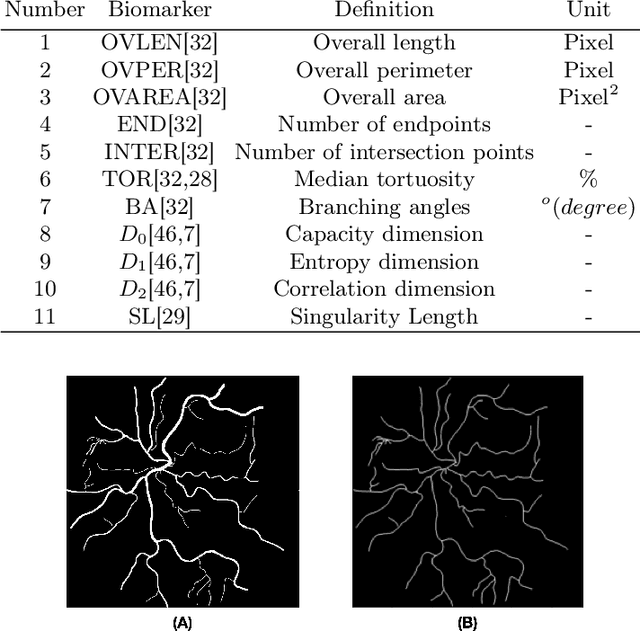
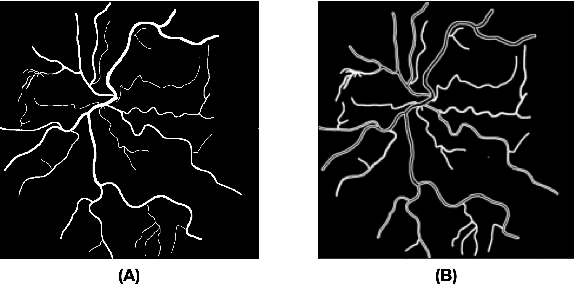
Introduction: Blood vessels can be non-invasively visualized from a digital fundus image (DFI). Several studies have shown an association between cardiovascular risk and vascular features obtained from DFI. Recent advances in computer vision and image segmentation enable automatising DFI blood vessel segmentation. There is a need for a resource that can automatically compute digital vasculature biomarkers (VBM) from these segmented DFI. Methods: In this paper, we introduce a Python Vasculature BioMarker toolbox, denoted PVBM. A total of 11 VBMs were implemented. In particular, we introduce new algorithmic methods to estimate tortuosity and branching angles. Using PVBM, and as a proof of usability, we analyze geometric vascular differences between glaucomatous patients and healthy controls. Results: We built a fully automated vasculature biomarker toolbox based on DFI segmentations and provided a proof of usability to characterize the vascular changes in glaucoma. For arterioles and venules, all biomarkers were significant and lower in glaucoma patients compared to healthy controls except for tortuosity, venular singularity length and venular branching angles. Conclusion: We have automated the computation of 11 VBMs from retinal blood vessel segmentation. The PVBM toolbox is made open source under a GNU GPL 3 license and is available on physiozoo.com (following publication).
Transformer-Unet: Raw Image Processing with Unet
Sep 17, 2021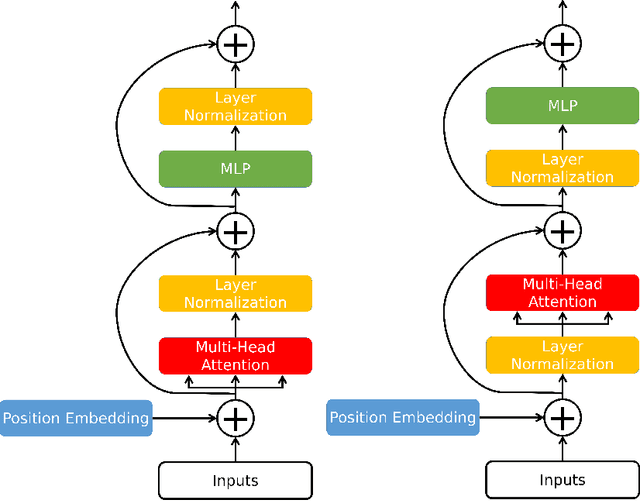

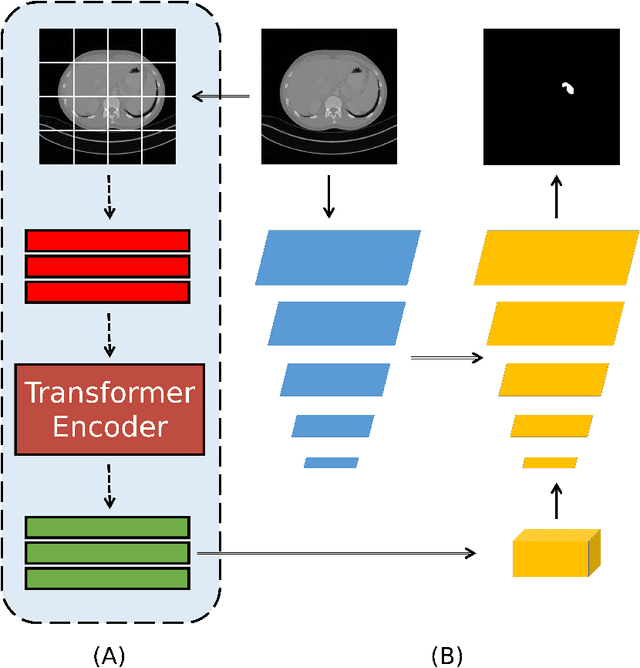
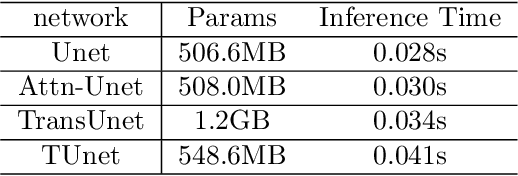
Medical image segmentation have drawn massive attention as it is important in biomedical image analysis. Good segmentation results can assist doctors with their judgement and further improve patients' experience. Among many available pipelines in medical image analysis, Unet is one of the most popular neural networks as it keeps raw features by adding concatenation between encoder and decoder, which makes it still widely used in industrial field. In the mean time, as a popular model which dominates natural language process tasks, transformer is now introduced to computer vision tasks and have seen promising results in object detection, image classification and semantic segmentation tasks. Therefore, the combination of transformer and Unet is supposed to be more efficient than both methods working individually. In this article, we propose Transformer-Unet by adding transformer modules in raw images instead of feature maps in Unet and test our network in CT82 datasets for Pancreas segmentation accordingly. We form an end-to-end network and gain segmentation results better than many previous Unet based algorithms in our experiment. We demonstrate our network and show our experimental results in this paper accordingly.
CounTR: Transformer-based Generalised Visual Counting
Aug 29, 2022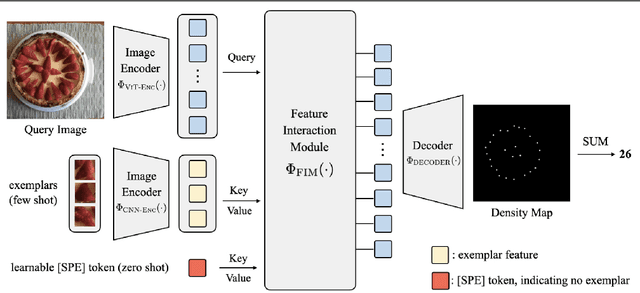
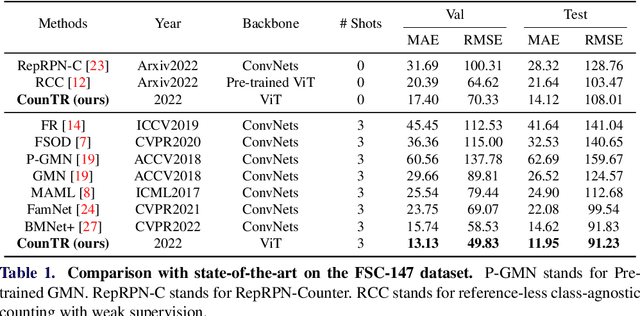

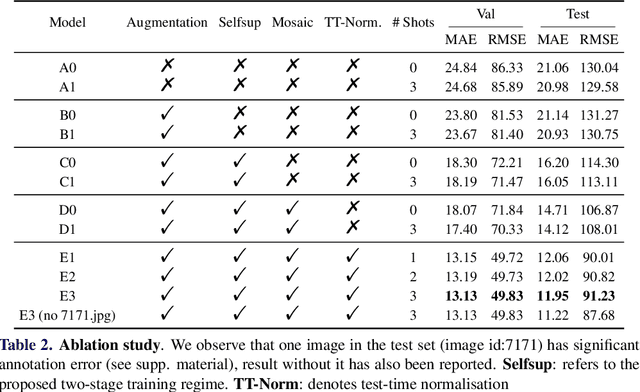
In this paper, we consider the problem of generalised visual object counting, with the goal of developing a computational model for counting the number of objects from arbitrary semantic categories, using arbitrary number of "exemplars", i.e. zero-shot or few-shot counting. To this end, we make the following four contributions: (1) We introduce a novel transformer-based architecture for generalised visual object counting, termed as Counting Transformer (CounTR), which explicitly capture the similarity between image patches or with given "exemplars" with the attention mechanism;(2) We adopt a two-stage training regime, that first pre-trains the model with self-supervised learning, and followed by supervised fine-tuning;(3) We propose a simple, scalable pipeline for synthesizing training images with a large number of instances or that from different semantic categories, explicitly forcing the model to make use of the given "exemplars";(4) We conduct thorough ablation studies on the large-scale counting benchmark, e.g. FSC-147, and demonstrate state-of-the-art performance on both zero and few-shot settings.
Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution
Mar 17, 2022
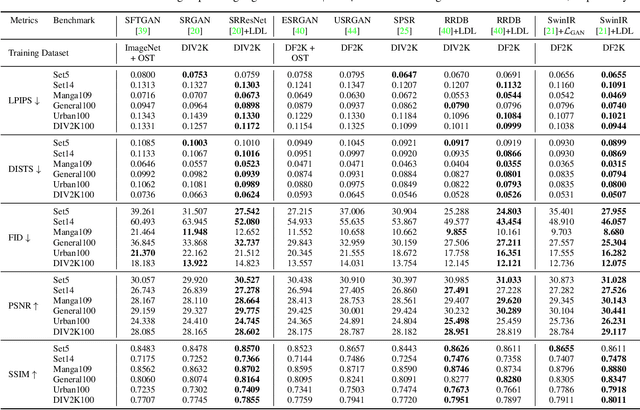
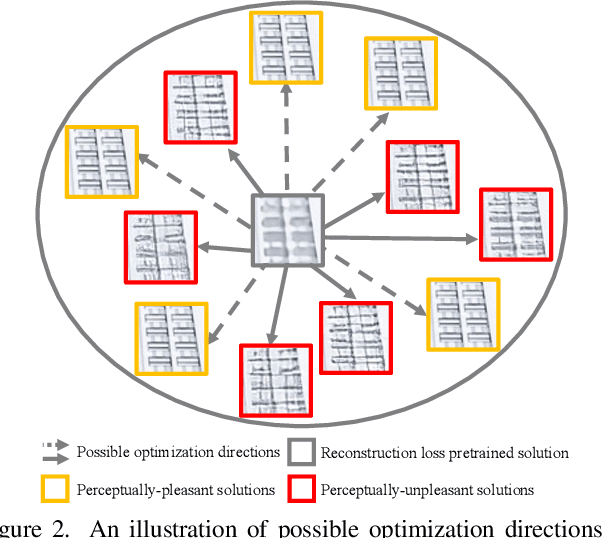
Single image super-resolution (SISR) with generative adversarial networks (GAN) has recently attracted increasing attention due to its potentials to generate rich details. However, the training of GAN is unstable, and it often introduces many perceptually unpleasant artifacts along with the generated details. In this paper, we demonstrate that it is possible to train a GAN-based SISR model which can stably generate perceptually realistic details while inhibiting visual artifacts. Based on the observation that the local statistics (e.g., residual variance) of artifact areas are often different from the areas of perceptually friendly details, we develop a framework to discriminate between GAN-generated artifacts and realistic details, and consequently generate an artifact map to regularize and stabilize the model training process. Our proposed locally discriminative learning (LDL) method is simple yet effective, which can be easily plugged in off-the-shelf SISR methods and boost their performance. Experiments demonstrate that LDL outperforms the state-of-the-art GAN based SISR methods, achieving not only higher reconstruction accuracy but also superior perceptual quality on both synthetic and real-world datasets. Codes and models are available at https://github.com/csjliang/LDL.
Just Noticeable Difference Modeling for Face Recognition System
Sep 13, 2022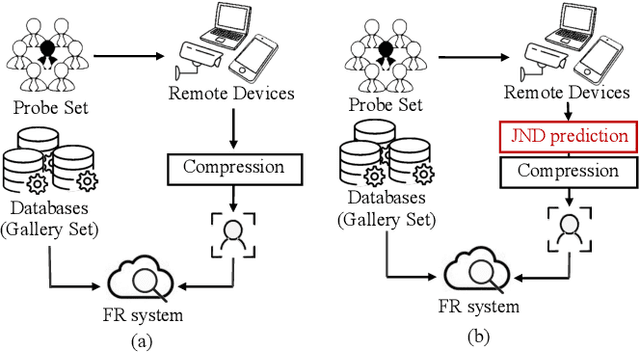
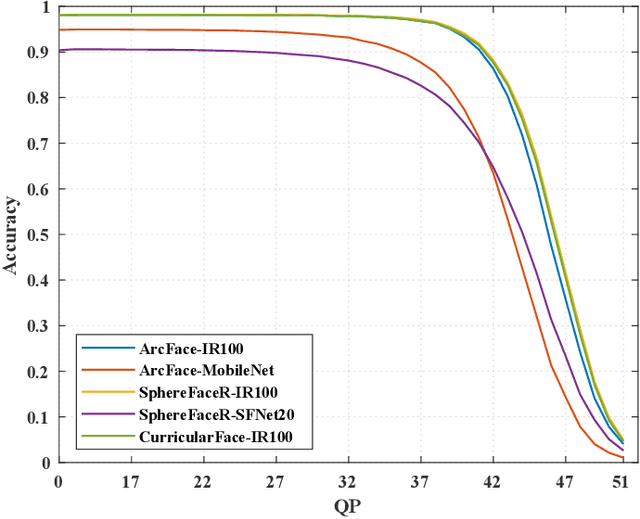
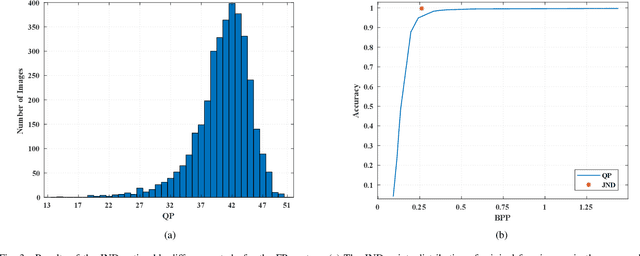
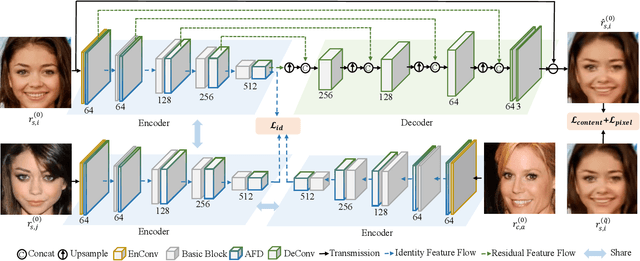
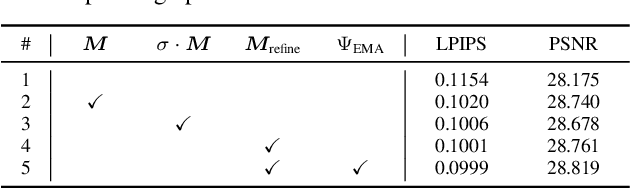
High-quality face images are required to guarantee the stability and reliability of automatic face recognition (FR) systems in surveillance and security scenarios. However, a massive amount of face data is usually compressed before being analyzed due to limitations on transmission or storage. The compressed images may lose the powerful identity information, resulting in the performance degradation of the FR system. Herein, we make the first attempt to study just noticeable difference (JND) for the FR system, which can be defined as the maximum distortion that the FR system cannot notice. More specifically, we establish a JND dataset including 3530 original images and 137,670 compressed images generated by advanced reference encoding/decoding software based on the Versatile Video Coding (VVC) standard (VTM-15.0). Subsequently, we develop a novel JND prediction model to directly infer JND images for the FR system. In particular, in order to maximum redundancy removal without impairment of robust identity information, we apply the encoder with multiple feature extraction and attention-based feature decomposition modules to progressively decompose face features into two uncorrelated components, i.e., identity and residual features, via self-supervised learning. Then, the residual feature is fed into the decoder to generate the residual map. Finally, the predicted JND map is obtained by subtracting the residual map from the original image. Experimental results have demonstrated that the proposed model achieves higher accuracy of JND map prediction compared with the state-of-the-art JND models, and is capable of saving more bits while maintaining the performance of the FR system compared with VTM-15.0.
Shaken, and Stirred: Long-Range Dependencies Enable Robust Outlier Detection with PixelCNN++
Aug 29, 2022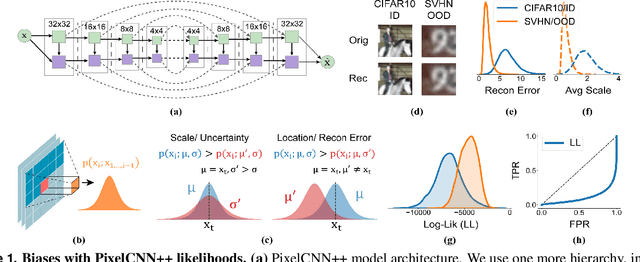
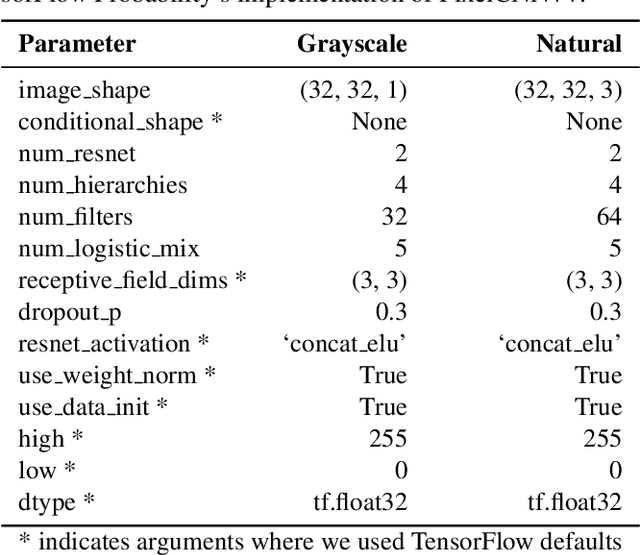
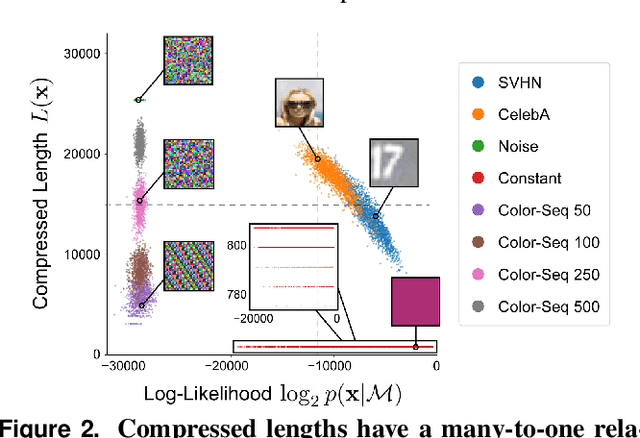
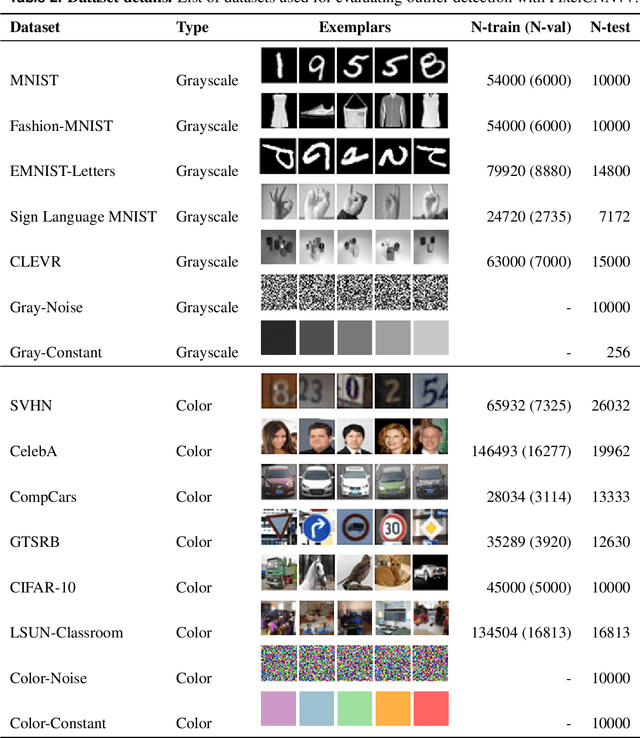
Reliable outlier detection is critical for real-world applications of deep learning models. Likelihoods produced by deep generative models, although extensively studied, have been largely dismissed as being impractical for outlier detection. For one, deep generative model likelihoods are readily biased by low-level input statistics. Second, many recent solutions for correcting these biases are computationally expensive or do not generalize well to complex, natural datasets. Here, we explore outlier detection with a state-of-the-art deep autoregressive model: PixelCNN++. We show that biases in PixelCNN++ likelihoods arise primarily from predictions based on local dependencies. We propose two families of bijective transformations that we term "shaking" and "stirring", which ameliorate low-level biases and isolate the contribution of long-range dependencies to the PixelCNN++ likelihood. These transformations are computationally inexpensive and readily applied at evaluation time. We evaluate our approaches extensively with five grayscale and six natural image datasets and show that they achieve or exceed state-of-the-art outlier detection performance. In sum, lightweight remedies suffice to achieve robust outlier detection on images with deep generative models.
Neural Radiance Transfer Fields for Relightable Novel-view Synthesis with Global Illumination
Jul 27, 2022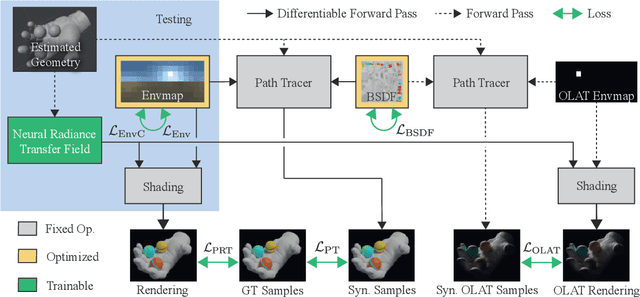
Given a set of images of a scene, the re-rendering of this scene from novel views and lighting conditions is an important and challenging problem in Computer Vision and Graphics. On the one hand, most existing works in Computer Vision usually impose many assumptions regarding the image formation process, e.g. direct illumination and predefined materials, to make scene parameter estimation tractable. On the other hand, mature Computer Graphics tools allow modeling of complex photo-realistic light transport given all the scene parameters. Combining these approaches, we propose a method for scene relighting under novel views by learning a neural precomputed radiance transfer function, which implicitly handles global illumination effects using novel environment maps. Our method can be solely supervised on a set of real images of the scene under a single unknown lighting condition. To disambiguate the task during training, we tightly integrate a differentiable path tracer in the training process and propose a combination of a synthesized OLAT and a real image loss. Results show that the recovered disentanglement of scene parameters improves significantly over the current state of the art and, thus, also our re-rendering results are more realistic and accurate.
Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
Oct 15, 2021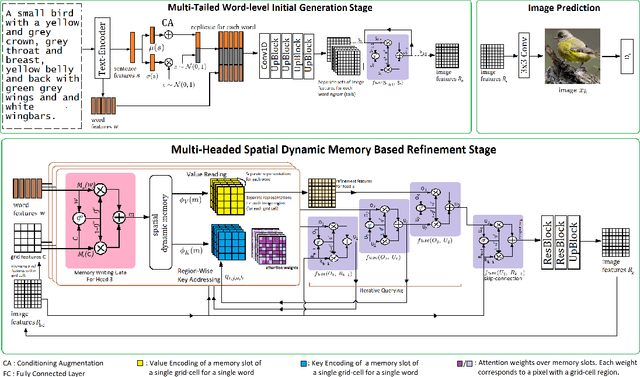


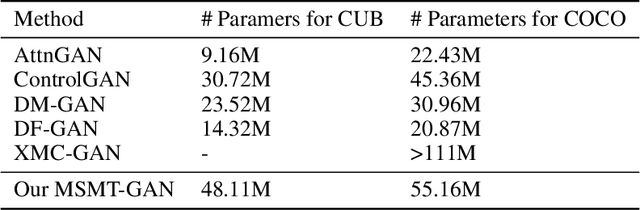
Synthesizing high-quality, realistic images from text-descriptions is a challenging task, and current methods synthesize images from text in a multi-stage manner, typically by first generating a rough initial image and then refining image details at subsequent stages. However, existing methods that follow this paradigm suffer from three important limitations. Firstly, they synthesize initial images without attempting to separate image attributes at a word-level. As a result, object attributes of initial images (that provide a basis for subsequent refinement) are inherently entangled and ambiguous in nature. Secondly, by using common text-representations for all regions, current methods prevent us from interpreting text in fundamentally different ways at different parts of an image. Different image regions are therefore only allowed to assimilate the same type of information from text at each refinement stage. Finally, current methods generate refinement features only once at each refinement stage and attempt to address all image aspects in a single shot. This single-shot refinement limits the precision with which each refinement stage can learn to improve the prior image. Our proposed method introduces three novel components to address these shortcomings: (1) An initial generation stage that explicitly generates separate sets of image features for each word n-gram. (2) A spatial dynamic memory module for refinement of images. (3) An iterative multi-headed mechanism to make it easier to improve upon multiple image aspects. Experimental results demonstrate that our Multi-Headed Spatial Dynamic Memory image refinement with our Multi-Tailed Word-level Initial Generation (MSMT-GAN) performs favourably against the previous state of the art on the CUB and COCO datasets.
Deep Metric Color Embeddings for Splicing Localization in Severely Degraded Images
Jun 21, 2022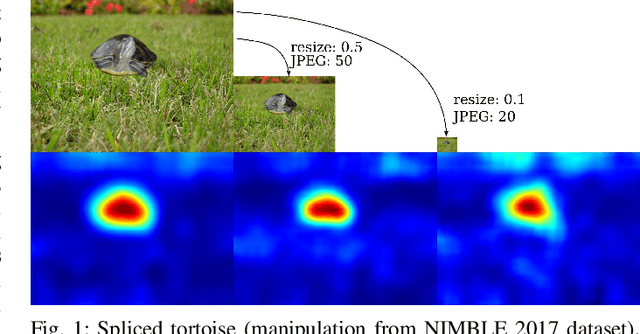
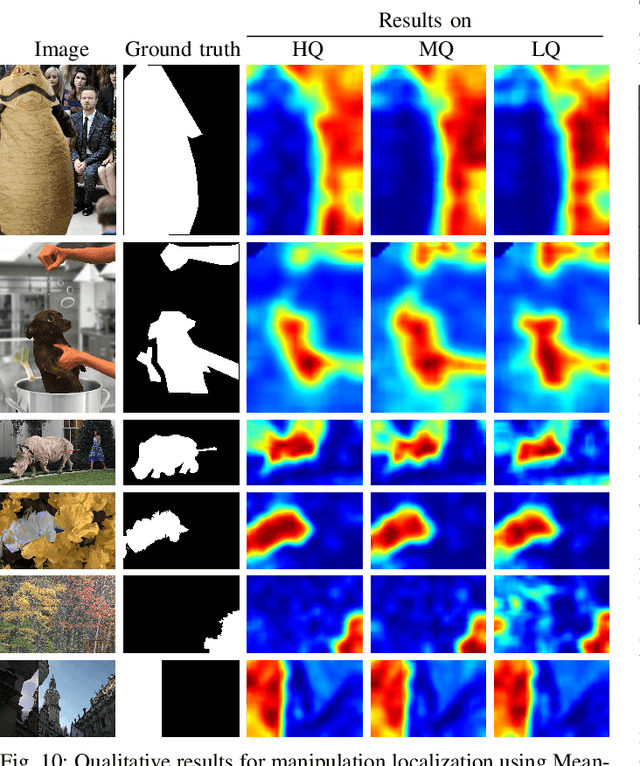
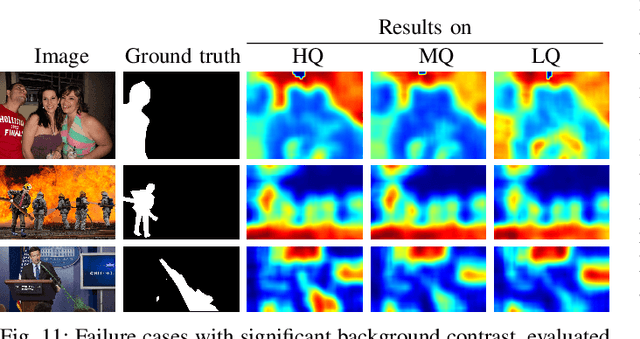
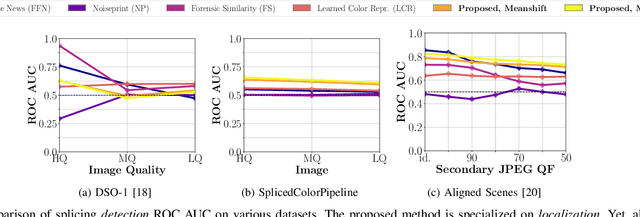
One common task in image forensics is to detect spliced images, where multiple source images are composed to one output image. Most of the currently best performing splicing detectors leverage high-frequency artifacts. However, after an image underwent strong compression, most of the high frequency artifacts are not available anymore. In this work, we explore an alternative approach to splicing detection, which is potentially better suited for images in-the-wild, subject to strong compression and downsampling. Our proposal is to model the color formation of an image. The color formation largely depends on variations at the scale of scene objects, and is hence much less dependent on high-frequency artifacts. We learn a deep metric space that is on one hand sensitive to illumination color and camera white-point estimation, but on the other hand insensitive to variations in object color. Large distances in the embedding space indicate that two image regions either stem from different scenes or different cameras. In our evaluation, we show that the proposed embedding space outperforms the state of the art on images that have been subject to strong compression and downsampling. We confirm in two further experiments the dual nature of the metric space, namely to both characterize the acquisition camera and the scene illuminant color. As such, this work resides at the intersection of physics-based and statistical forensics with benefits from both sides.
Dual Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 15, 2021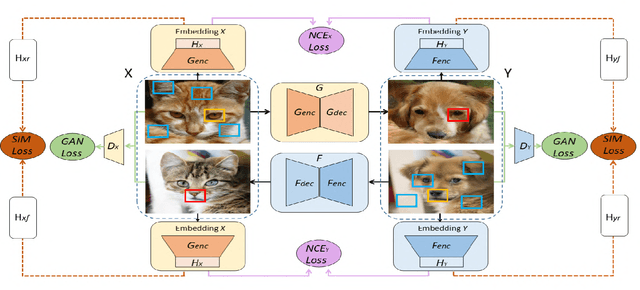
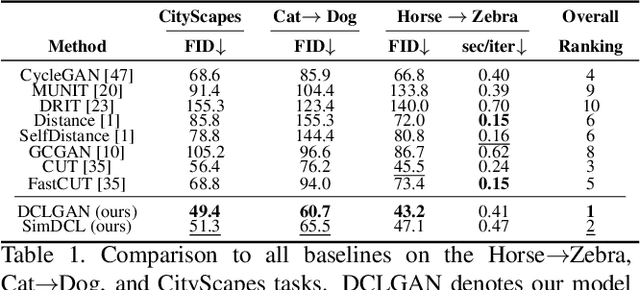


Unsupervised image-to-image translation tasks aim to find a mapping between a source domain X and a target domain Y from unpaired training data. Contrastive learning for Unpaired image-to-image Translation (CUT) yields state-of-the-art results in modeling unsupervised image-to-image translation by maximizing mutual information between input and output patches using only one encoder for both domains. In this paper, we propose a novel method based on contrastive learning and a dual learning setting (exploiting two encoders) to infer an efficient mapping between unpaired data. Additionally, while CUT suffers from mode collapse, a variant of our method efficiently addresses this issue. We further demonstrate the advantage of our approach through extensive ablation studies demonstrating superior performance comparing to recent approaches in multiple challenging image translation tasks. Lastly, we demonstrate that the gap between unsupervised methods and supervised methods can be efficiently closed.