 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
A Closer Look at Cross-Domain Few-Shot Object Detection: Fine-Tuning Matters and Parallel Decoder Helps
Mar 30, 2026Few-shot object detection (FSOD) is challenging due to unstable optimization and limited generalization arising from the scarcity of training samples. To address these issues, we propose a hybrid ensemble decoder that enhances generalization during fine-tuning. Inspired by ensemble learning, the decoder comprises a shared hierarchical layer followed by multiple parallel decoder branches, where each branch employs denoising queries either inherited from the shared layer or newly initialized to encourage prediction diversity. This design fully exploits pretrained weights without introducing additional parameters, and the resulting diverse predictions can be effectively ensembled to improve generalization. We further leverage a unified progressive fine-tuning framework with a plateau-aware learning rate schedule, which stabilizes optimization and achieves strong few-shot adaptation without complex data augmentations or extensive hyperparameter tuning. Extensive experiments on CD-FSOD, ODinW-13, and RF100-VL validate the effectiveness of our approach. Notably, on RF100-VL, which includes 100 datasets across diverse domains, our method achieves an average performance of 41.9 in the 10-shot setting, significantly outperforming the recent approach SAM3, which obtains 35.7. We further construct a mixed-domain test set from CD-FSOD to evaluate robustness to out-of-distribution (OOD) samples, showing that our proposed modules lead to clear improvement gains. These results highlight the effectiveness, generalization, and robustness of the proposed method. Code is available at: https://github.com/Intellindust-AI-Lab/FT-FSOD.
EdgeCrafter: Compact ViTs for Edge Dense Prediction via Task-Specialized Distillation
Mar 19, 2026Deploying high-performance dense prediction models on resource-constrained edge devices remains challenging due to strict limits on computation and memory. In practice, lightweight systems for object detection, instance segmentation, and pose estimation are still dominated by CNN-based architectures such as YOLO, while compact Vision Transformers (ViTs) often struggle to achieve similarly strong accuracy efficiency tradeoff, even with large scale pretraining. We argue that this gap is largely due to insufficient task specific representation learning in small scale ViTs, rather than an inherent mismatch between ViTs and edge dense prediction. To address this issue, we introduce EdgeCrafter, a unified compact ViT framework for edge dense prediction centered on ECDet, a detection model built from a distilled compact backbone and an edge-friendly encoder decoder design. On the COCO dataset, ECDet-S achieves 51.7 AP with fewer than 10M parameters using only COCO annotations. For instance segmentation, ECInsSeg achieves performance comparable to RF-DETR while using substantially fewer parameters. For pose estimation, ECPose-X reaches 74.8 AP, significantly outperforming YOLO26Pose-X (71.6 AP) despite the latter's reliance on extensive Objects365 pretraining. These results show that compact ViTs, when paired with task-specialized distillation and edge-aware design, can be a practical and competitive option for edge dense prediction. Code is available at: https://intellindust-ai-lab.github.io/projects/EdgeCrafter/
From Misclassifications to Outliers: Joint Reliability Assessment in Classification
Mar 04, 2026Building reliable classifiers is a fundamental challenge for deploying machine learning in real-world applications. A reliable system should not only detect out-of-distribution (OOD) inputs but also anticipate in-distribution (ID) errors by assigning low confidence to potentially misclassified samples. Yet, most prior work treats OOD detection and failure prediction as separated problems, overlooking their closed connection. We argue that reliability requires evaluating them jointly. To this end, we propose a unified evaluation framework that integrates OOD detection and failure prediction, quantified by our new metrics DS-F1 and DS-AURC, where DS denotes double scoring functions. Experiments on the OpenOOD benchmark show that double scoring functions yield classifiers that are substantially more reliable than traditional single scoring approaches. Our analysis further reveals that OOD-based approaches provide notable gains under simple or far-OOD shifts, but only marginal benefits under more challenging near-OOD conditions. Beyond evaluation, we extend the reliable classifier SURE and introduce SURE+, a new approach that significantly improves reliability across diverse scenarios. Together, our framework, metrics, and method establish a new benchmark for trustworthy classification and offer practical guidance for deploying robust models in real-world settings. The source code is publicly available at https://github.com/Intellindust-AI-Lab/SUREPlus.
FSOD-VFM: Few-Shot Object Detection with Vision Foundation Models and Graph Diffusion
Feb 03, 2026In this paper, we present FSOD-VFM: Few-Shot Object Detectors with Vision Foundation Models, a framework that leverages vision foundation models to tackle the challenge of few-shot object detection. FSOD-VFM integrates three key components: a universal proposal network (UPN) for category-agnostic bounding box generation, SAM2 for accurate mask extraction, and DINOv2 features for efficient adaptation to new object categories. Despite the strong generalization capabilities of foundation models, the bounding boxes generated by UPN often suffer from overfragmentation, covering only partial object regions and leading to numerous small, false-positive proposals rather than accurate, complete object detections. To address this issue, we introduce a novel graph-based confidence reweighting method. In our approach, predicted bounding boxes are modeled as nodes in a directed graph, with graph diffusion operations applied to propagate confidence scores across the network. This reweighting process refines the scores of proposals, assigning higher confidence to whole objects and lower confidence to local, fragmented parts. This strategy improves detection granularity and effectively reduces the occurrence of false-positive bounding box proposals. Through extensive experiments on Pascal-5$^i$, COCO-20$^i$, and CD-FSOD datasets, we demonstrate that our method substantially outperforms existing approaches, achieving superior performance without requiring additional training. Notably, on the challenging CD-FSOD dataset, which spans multiple datasets and domains, our FSOD-VFM achieves 31.6 AP in the 10-shot setting, substantially outperforming previous training-free methods that reach only 21.4 AP. Code is available at: https://intellindust-ai-lab.github.io/projects/FSOD-VFM.
Transformer-Unet: Raw Image Processing with Unet
Sep 17, 2021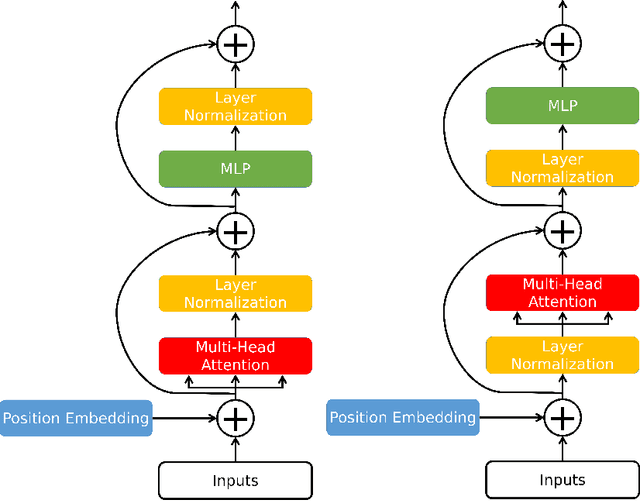

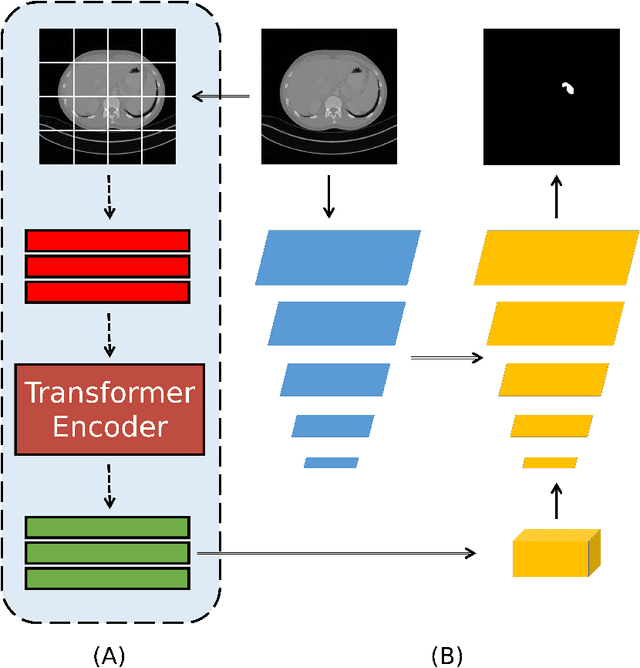
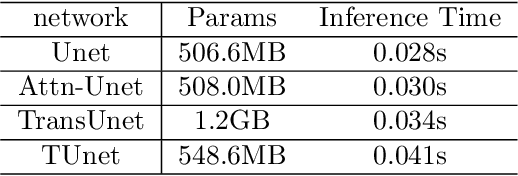
Medical image segmentation have drawn massive attention as it is important in biomedical image analysis. Good segmentation results can assist doctors with their judgement and further improve patients' experience. Among many available pipelines in medical image analysis, Unet is one of the most popular neural networks as it keeps raw features by adding concatenation between encoder and decoder, which makes it still widely used in industrial field. In the mean time, as a popular model which dominates natural language process tasks, transformer is now introduced to computer vision tasks and have seen promising results in object detection, image classification and semantic segmentation tasks. Therefore, the combination of transformer and Unet is supposed to be more efficient than both methods working individually. In this article, we propose Transformer-Unet by adding transformer modules in raw images instead of feature maps in Unet and test our network in CT82 datasets for Pancreas segmentation accordingly. We form an end-to-end network and gain segmentation results better than many previous Unet based algorithms in our experiment. We demonstrate our network and show our experimental results in this paper accordingly.