 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise Distribution Adaptive Self-Supervised Image Denoising using Tweedie Distribution and Score Matching
Dec 05, 2021

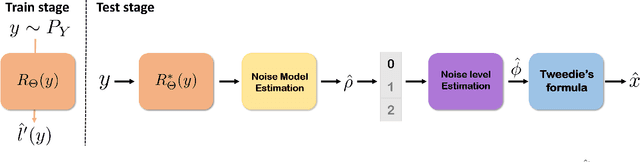
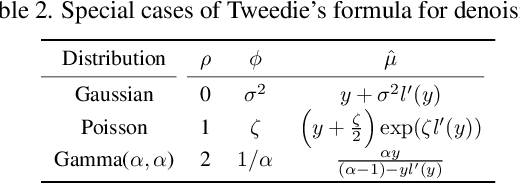

Tweedie distributions are a special case of exponential dispersion models, which are often used in classical statistics as distributions for generalized linear models. Here, we reveal that Tweedie distributions also play key roles in modern deep learning era, leading to a distribution independent self-supervised image denoising formula without clean reference images. Specifically, by combining with the recent Noise2Score self-supervised image denoising approach and the saddle point approximation of Tweedie distribution, we can provide a general closed-form denoising formula that can be used for large classes of noise distributions without ever knowing the underlying noise distribution. Similar to the original Noise2Score, the new approach is composed of two successive steps: score matching using perturbed noisy images, followed by a closed form image denoising formula via distribution-independent Tweedie's formula. This also suggests a systematic algorithm to estimate the noise model and noise parameters for a given noisy image data set. Through extensive experiments, we demonstrate that the proposed method can accurately estimate noise models and parameters, and provide the state-of-the-art self-supervised image denoising performance in the benchmark dataset and real-world dataset.
Stochastic Optimization of 3D Non-Cartesian Sampling Trajectory (SNOPY)
Sep 22, 2022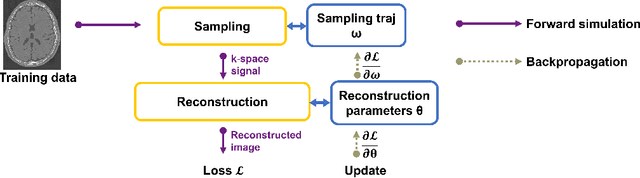
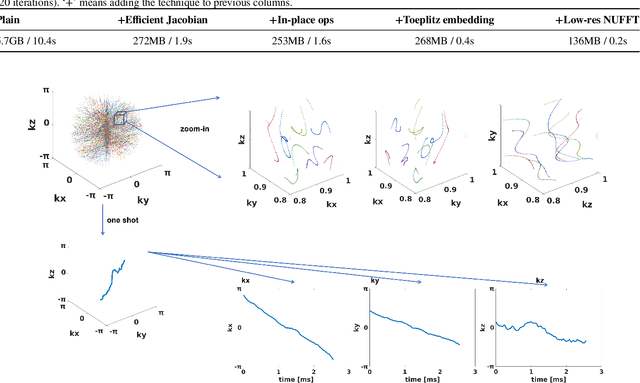

Optimizing 3D k-space sampling trajectories for efficient MRI is important yet challenging. This work proposes a generalized framework for optimizing 3D non-Cartesian sampling patterns via data-driven optimization. We built a differentiable MRI system model to enable gradient-based methods for sampling trajectory optimization. By combining training losses, the algorithm can simultaneously optimize multiple properties of sampling patterns, including image quality, hardware constraints (maximum slew rate and gradient strength), reduced peripheral nerve stimulation (PNS), and parameter-weighted contrast. The proposed method can either optimize the gradient waveform (spline-based freeform optimization) or optimize properties of given sampling trajectories (such as the rotation angle of radial trajectories). Notably, the method optimizes sampling trajectories synergistically with either model-based or learning-based reconstruction methods. We proposed several strategies to alleviate the severe non-convexity and huge computation demand posed by the high-dimensional optimization. The corresponding code is organized as an open-source, easy-to-use toolbox. We applied the optimized trajectory to multiple applications including structural and functional imaging. In the simulation studies, the reconstruction PSNR of a 3D kooshball trajectory was increased by 4 dB with SNOPY optimization. In the prospective studies, by optimizing the rotation angles of a stack-of-stars (SOS) trajectory, SNOPY improved the PSNR by 1.4dB compared to the best empirical method. Optimizing the gradient waveform of a rotational EPI trajectory improved subjects' rating of the PNS effect from 'strong' to 'mild.' In short, SNOPY provides an efficient data-driven and optimization-based method to tailor non-Cartesian sampling trajectories.
Training Certifiably Robust Neural Networks Against Semantic Perturbations
Jul 22, 2022
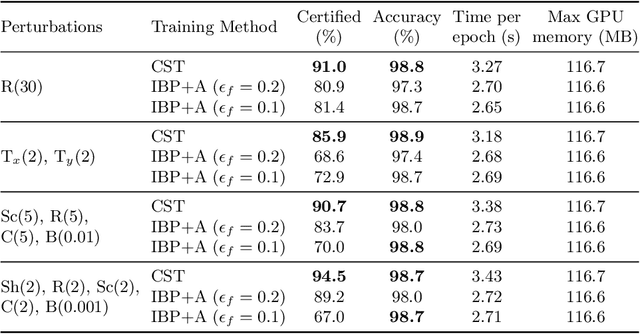
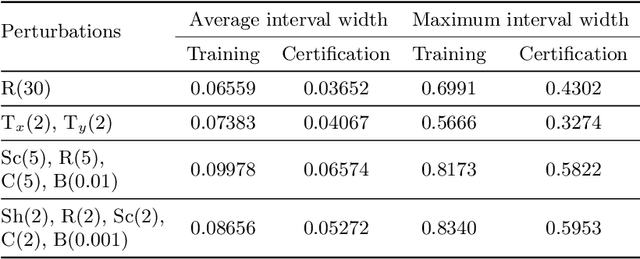
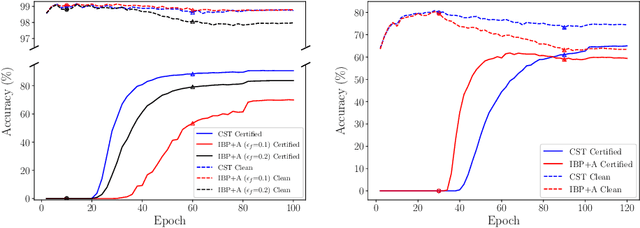
Semantic image perturbations, such as scaling and rotation, have been shown to easily deceive deep neural networks (DNNs). Hence, training DNNs to be certifiably robust to these perturbations is critical. However, no prior work has been able to incorporate the objective of deterministic semantic robustness into the training procedure, as existing deterministic semantic verifiers are exceedingly slow. To address these challenges, we propose Certified Semantic Training (CST), the first training framework for deterministic certified robustness against semantic image perturbations. Our framework leverages a novel GPU-optimized verifier that, unlike existing works, is fast enough for use in training. Our results show that networks trained via CST consistently achieve both better provable semantic robustness and clean accuracy, compared to networks trained via baselines based on existing works.
Homography augumented momentum constrastive learning for SAR image retrieval
Sep 21, 2021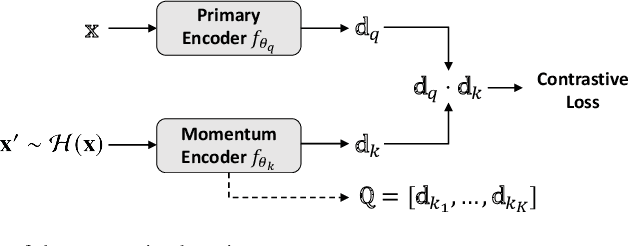
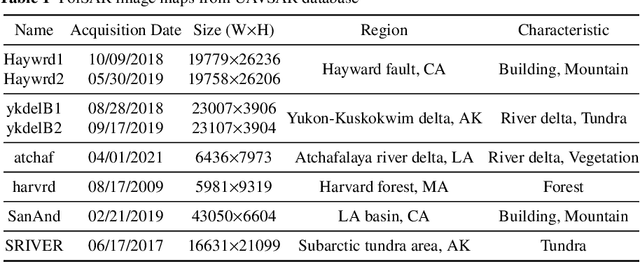
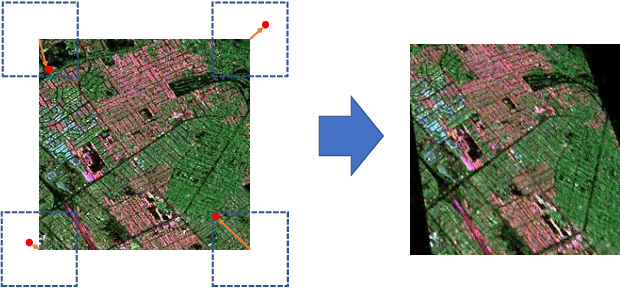
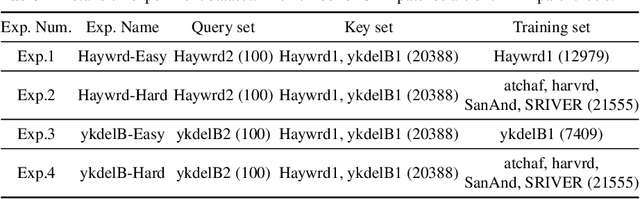
Deep learning-based image retrieval has been emphasized in computer vision. Representation embedding extracted by deep neural networks (DNNs) not only aims at containing semantic information of the image, but also can manage large-scale image retrieval tasks. In this work, we propose a deep learning-based image retrieval approach using homography transformation augmented contrastive learning to perform large-scale synthetic aperture radar (SAR) image search tasks. Moreover, we propose a training method for the DNNs induced by contrastive learning that does not require any labeling procedure. This may enable tractability of large-scale datasets with relative ease. Finally, we verify the performance of the proposed method by conducting experiments on the polarimetric SAR image datasets.
D-Former: A U-shaped Dilated Transformer for 3D Medical Image Segmentation
Jan 03, 2022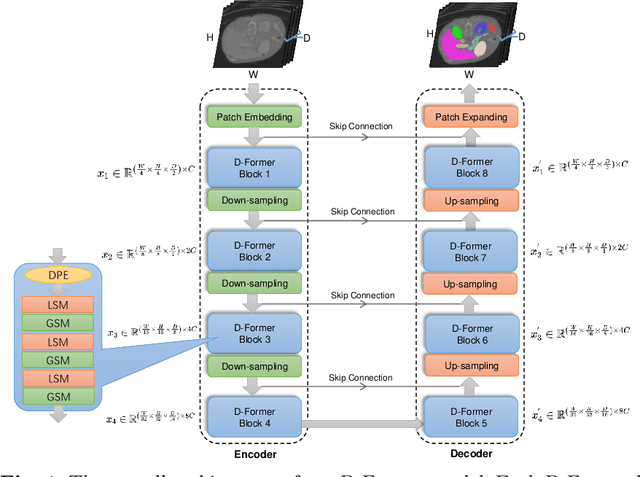
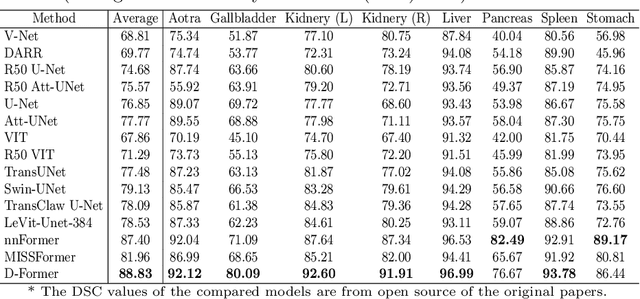
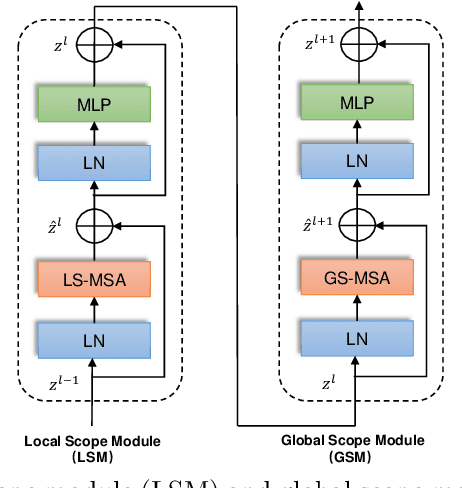
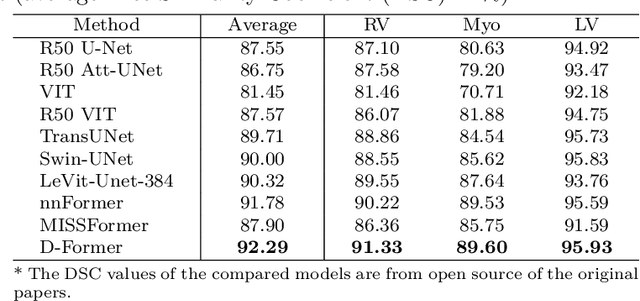
Computer-aided medical image segmentation has been applied widely in diagnosis and treatment to obtain clinically useful information of shapes and volumes of target organs and tissues. In the past several years, convolutional neural network (CNN) based methods (e.g., U-Net) have dominated this area, but still suffered from inadequate long-range information capturing. Hence, recent work presented computer vision Transformer variants for medical image segmentation tasks and obtained promising performances. Such Transformers model long-range dependency by computing pair-wise patch relations. However, they incur prohibitive computational costs, especially on 3D medical images (e.g., CT and MRI). In this paper, we propose a new method called Dilated Transformer, which conducts self-attention for pair-wise patch relations captured alternately in local and global scopes. Inspired by dilated convolution kernels, we conduct the global self-attention in a dilated manner, enlarging receptive fields without increasing the patches involved and thus reducing computational costs. Based on this design of Dilated Transformer, we construct a U-shaped encoder-decoder hierarchical architecture called D-Former for 3D medical image segmentation. Experiments on the Synapse and ACDC datasets show that our D-Former model, trained from scratch, outperforms various competitive CNN-based or Transformer-based segmentation models at a low computational cost without time-consuming per-training process.
Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks
Aug 10, 2022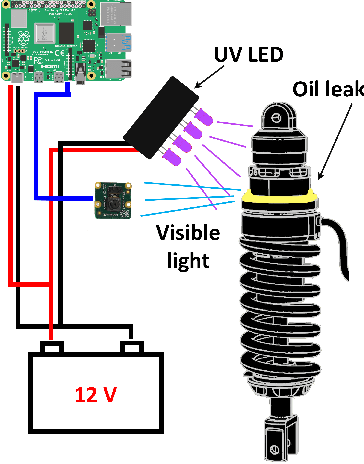

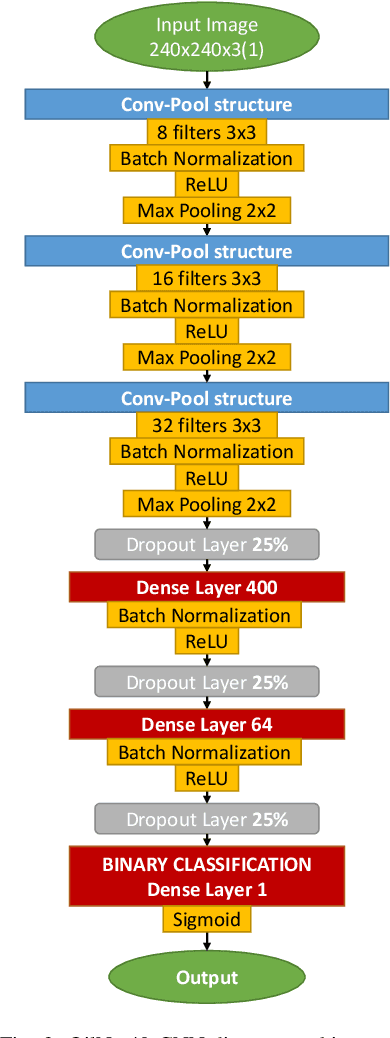
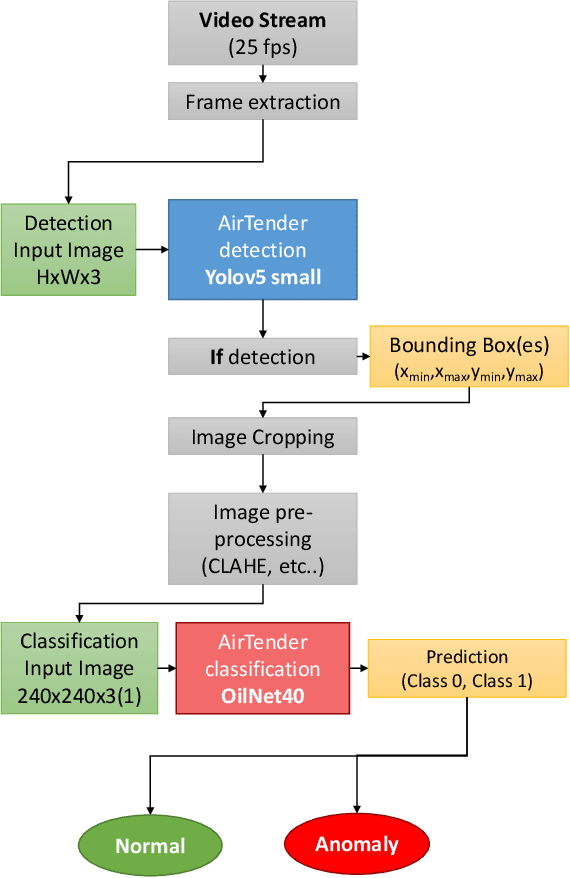
In this work, we describe in detail how Deep Learning and Computer Vision can help to detect fault events of the AirTender system, an aftermarket motorcycle damping system component. One of the most effective ways to monitor the AirTender functioning is to look for oil stains on its surface. Starting from real-time images, AirTender is first detected in the motorbike suspension system and then a binary classifier determines whether AirTender is spilling oil or not. The detection is made with the help of the Yolo5 architecture, whereas the classification is carried out with the help of a suitably designed Convolutional Neural Network, OilNet40. In order to detect oil leaks more clearly, we dilute the oil in AirTender with a fluorescent dye with excitation wavelength peak of approximately 390 nm. AirTender is then illuminated with suitable UV LEDs. The whole system is an attempt to design a low-cost detection setup. An on-board device, such as a mini-computer, is placed near the suspension system and connected to a full hd camera framing AirTender. The on-board device, through our Neural Network algorithm, is then able to localize and classify AirTender as normally functioning (non-leak image) or anomaly (leak image).
Character Generation through Self-Supervised Vectorization
Aug 03, 2022

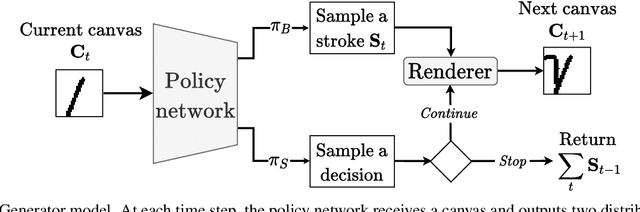
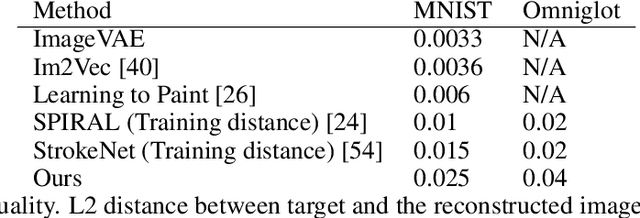
The prevalent approach in self-supervised image generation is to operate on pixel level representations. While this approach can produce high quality images, it cannot benefit from the simplicity and innate quality of vectorization. Here we present a drawing agent that operates on stroke-level representation of images. At each time step, the agent first assesses the current canvas and decides whether to stop or keep drawing. When a 'draw' decision is made, the agent outputs a program indicating the stroke to be drawn. As a result, it produces a final raster image by drawing the strokes on a canvas, using a minimal number of strokes and dynamically deciding when to stop. We train our agent through reinforcement learning on MNIST and Omniglot datasets for unconditional generation and parsing (reconstruction) tasks. We utilize our parsing agent for exemplar generation and type conditioned concept generation in Omniglot challenge without any further training. We present successful results on all three generation tasks and the parsing task. Crucially, we do not need any stroke-level or vector supervision; we only use raster images for training.
Learning Generalized Non-Rigid Multimodal Biomedical Image Registration from Generic Point Set Data
Jul 22, 2022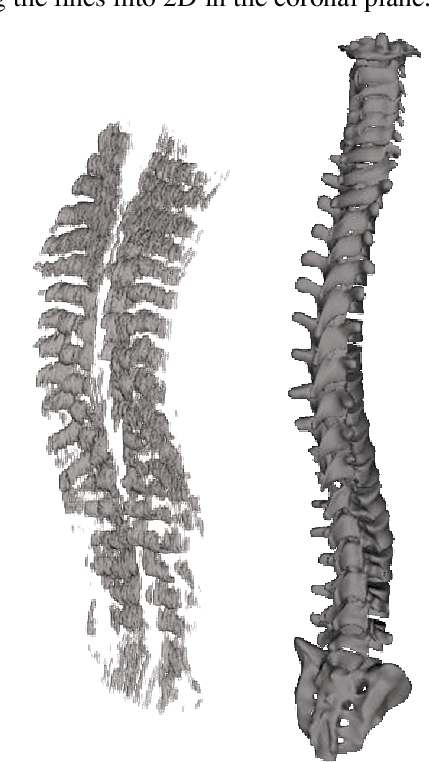
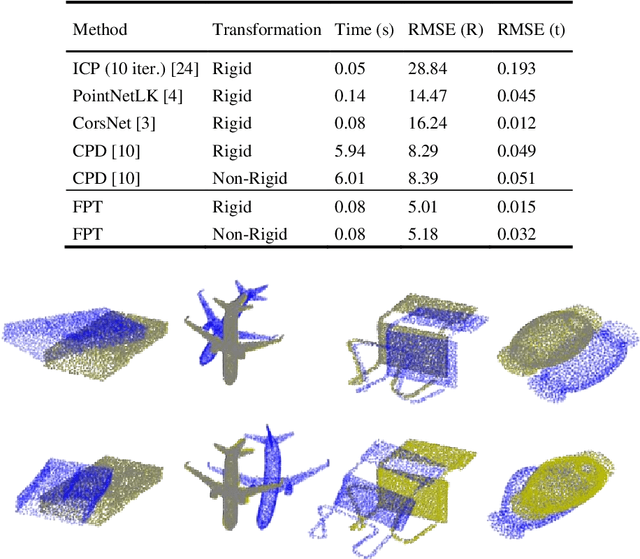
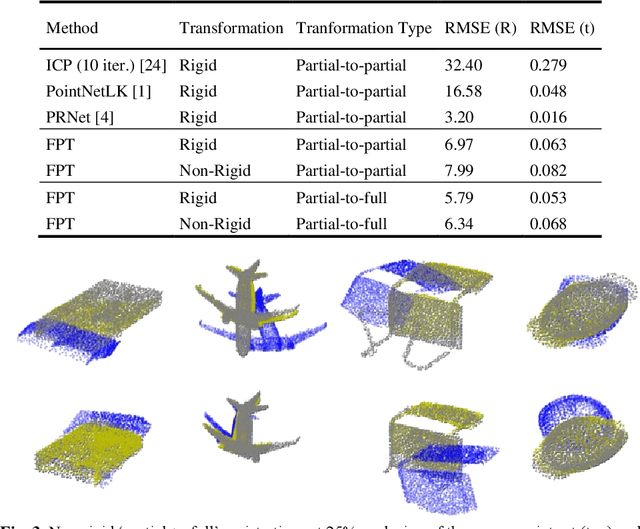
Free Point Transformer (FPT) has been proposed as a data-driven, non-rigid point set registration approach using deep neural networks. As FPT does not assume constraints based on point vicinity or correspondence, it may be trained simply and in a flexible manner by minimizing an unsupervised loss based on the Chamfer Distance. This makes FPT amenable to real-world medical imaging applications where ground-truth deformations may be infeasible to obtain, or in scenarios where only a varying degree of completeness in the point sets to be aligned is available. To test the limit of the correspondence finding ability of FPT and its dependency on training data sets, this work explores the generalizability of the FPT from well-curated non-medical data sets to medical imaging data sets. First, we train FPT on the ModelNet40 dataset to demonstrate its effectiveness and the superior registration performance of FPT over iterative and learning-based point set registration methods. Second, we demonstrate superior performance in rigid and non-rigid registration and robustness to missing data. Last, we highlight the interesting generalizability of the ModelNet-trained FPT by registering reconstructed freehand ultrasound scans of the spine and generic spine models without additional training, whereby the average difference to the ground truth curvatures is 1.3 degrees, across 13 patients.
Self-supervised Matting-specific Portrait Enhancement and Generation
Aug 13, 2022
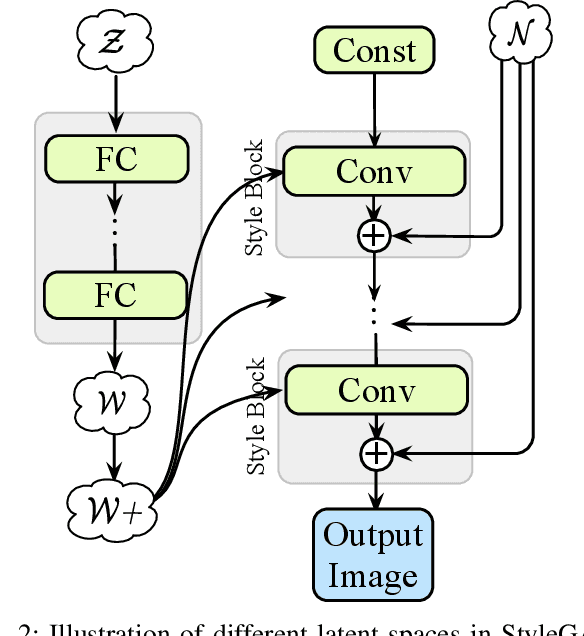
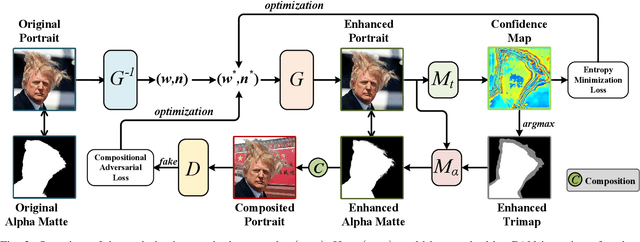

We resolve the ill-posed alpha matting problem from a completely different perspective. Given an input portrait image, instead of estimating the corresponding alpha matte, we focus on the other end, to subtly enhance this input so that the alpha matte can be easily estimated by any existing matting models. This is accomplished by exploring the latent space of GAN models. It is demonstrated that interpretable directions can be found in the latent space and they correspond to semantic image transformations. We further explore this property in alpha matting. Particularly, we invert an input portrait into the latent code of StyleGAN, and our aim is to discover whether there is an enhanced version in the latent space which is more compatible with a reference matting model. We optimize multi-scale latent vectors in the latent spaces under four tailored losses, ensuring matting-specificity and subtle modifications on the portrait. We demonstrate that the proposed method can refine real portrait images for arbitrary matting models, boosting the performance of automatic alpha matting by a large margin. In addition, we leverage the generative property of StyleGAN, and propose to generate enhanced portrait data which can be treated as the pseudo GT. It addresses the problem of expensive alpha matte annotation, further augmenting the matting performance of existing models. Code is available at~\url{https://github.com/cnnlstm/StyleGAN_Matting}.
Beyond Visual Field of View: Perceiving 3D Environment with Echoes and Vision
Jul 03, 2022
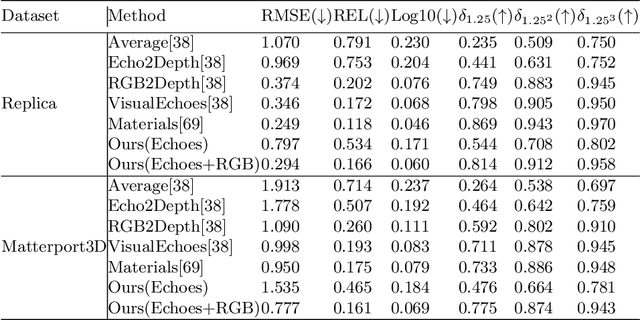
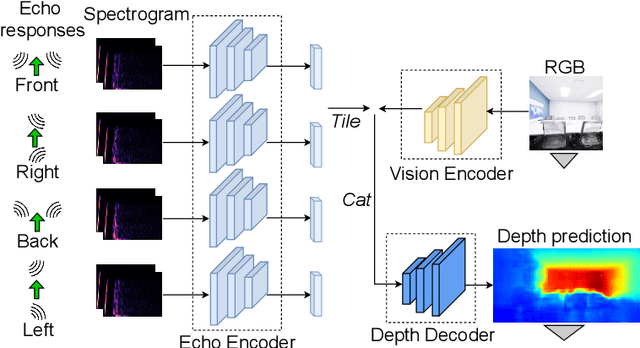
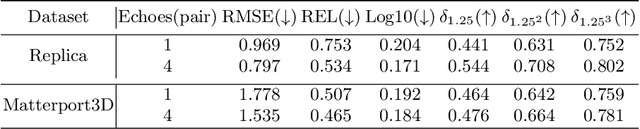
This paper focuses on perceiving and navigating 3D environments using echoes and RGB image. In particular, we perform depth estimation by fusing RGB image with echoes, received from multiple orientations. Unlike previous works, we go beyond the field of view of the RGB and estimate dense depth maps for substantially larger parts of the environment. We show that the echoes provide holistic and in-expensive information about the 3D structures complementing the RGB image. Moreover, we study how echoes and the wide field-of-view depth maps can be utilised in robot navigation. We compare the proposed methods against recent baselines using two sets of challenging realistic 3D environments: Replica and Matterport3D. The implementation and pre-trained models will be made publicly available.