 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Generalization Capabilities of Large Language Models on Code Reasoning
Apr 07, 2025We assess how the code reasoning abilities of large language models (LLMs) generalize to different kinds of programs. We present techniques for obtaining in- and out-of-distribution programs with different characteristics: code sampled from a domain-specific language, code automatically generated by an LLM, code collected from competitive programming contests, and mutated versions of these programs. We also present an experimental methodology for evaluating LLM generalization by comparing their performance on these programs. We perform an extensive evaluation across 10 state-of-the-art models from the past year, obtaining insights into their generalization capabilities over time and across different classes of programs. Our results highlight that while earlier models exhibit behavior consistent with pattern matching, the latest models exhibit strong generalization abilities on code reasoning.
S4: Self-Supervised Sensing Across the Spectrum
May 02, 2024Satellite image time series (SITS) segmentation is crucial for many applications like environmental monitoring, land cover mapping and agricultural crop type classification. However, training models for SITS segmentation remains a challenging task due to the lack of abundant training data, which requires fine grained annotation. We propose S4 a new self-supervised pre-training approach that significantly reduces the requirement for labeled training data by utilizing two new insights: (a) Satellites capture images in different parts of the spectrum such as radio frequencies, and visible frequencies. (b) Satellite imagery is geo-registered allowing for fine-grained spatial alignment. We use these insights to formulate pre-training tasks in S4. We also curate m2s2-SITS, a large-scale dataset of unlabeled, spatially-aligned, multi-modal and geographic specific SITS that serves as representative pre-training data for S4. Finally, we evaluate S4 on multiple SITS segmentation datasets and demonstrate its efficacy against competing baselines while using limited labeled data.
Training Certifiably Robust Neural Networks Against Semantic Perturbations
Jul 22, 2022
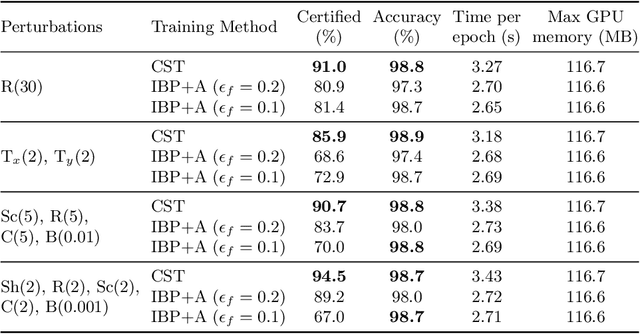
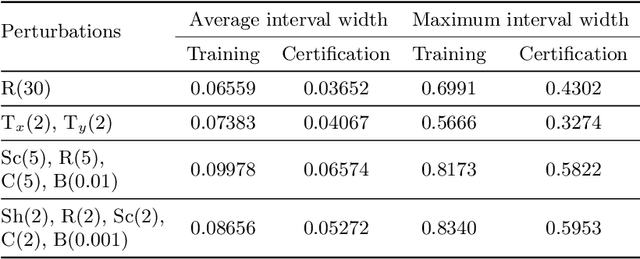
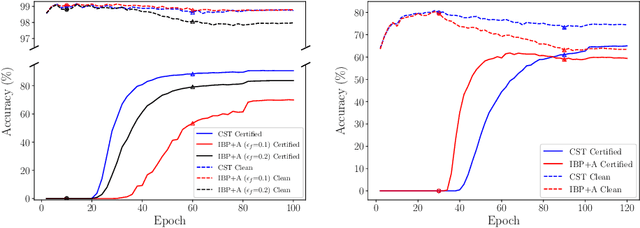
Semantic image perturbations, such as scaling and rotation, have been shown to easily deceive deep neural networks (DNNs). Hence, training DNNs to be certifiably robust to these perturbations is critical. However, no prior work has been able to incorporate the objective of deterministic semantic robustness into the training procedure, as existing deterministic semantic verifiers are exceedingly slow. To address these challenges, we propose Certified Semantic Training (CST), the first training framework for deterministic certified robustness against semantic image perturbations. Our framework leverages a novel GPU-optimized verifier that, unlike existing works, is fast enough for use in training. Our results show that networks trained via CST consistently achieve both better provable semantic robustness and clean accuracy, compared to networks trained via baselines based on existing works.