 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Loop Unrolled Shallow Equilibrium Regularizer (LUSER) -- A Memory-Efficient Inverse Problem Solver
Oct 10, 2022
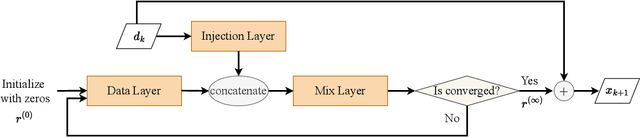

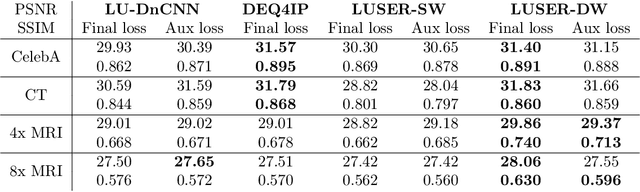
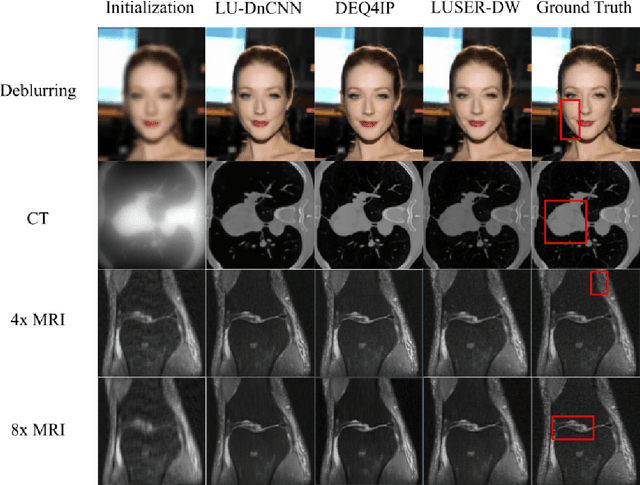
In inverse problems we aim to reconstruct some underlying signal of interest from potentially corrupted and often ill-posed measurements. Classical optimization-based techniques proceed by optimizing a data consistency metric together with a regularizer. Current state-of-the-art machine learning approaches draw inspiration from such techniques by unrolling the iterative updates for an optimization-based solver and then learning a regularizer from data. This loop unrolling (LU) method has shown tremendous success, but often requires a deep model for the best performance leading to high memory costs during training. Thus, to address the balance between computation cost and network expressiveness, we propose an LU algorithm with shallow equilibrium regularizers (LUSER). These implicit models are as expressive as deeper convolutional networks, but far more memory efficient during training. The proposed method is evaluated on image deblurring, computed tomography (CT), as well as single-coil Magnetic Resonance Imaging (MRI) tasks and shows similar, or even better, performance while requiring up to 8 times less computational resources during training when compared against a more typical LU architecture with feedforward convolutional regularizers.
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
Aug 08, 2022
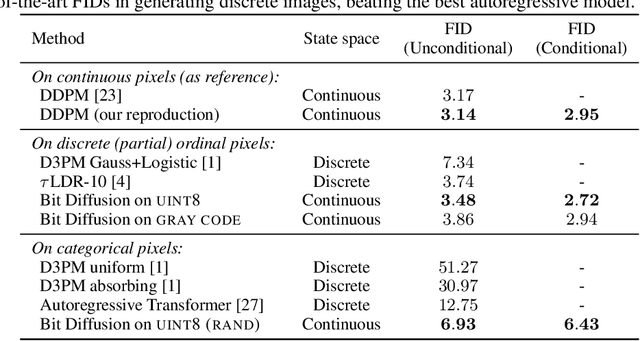


We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and ImageNet-64x64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
Adaptive sampling for scanning pixel cameras
Aug 01, 2022
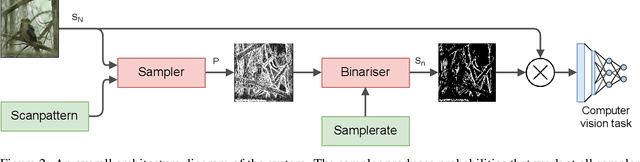
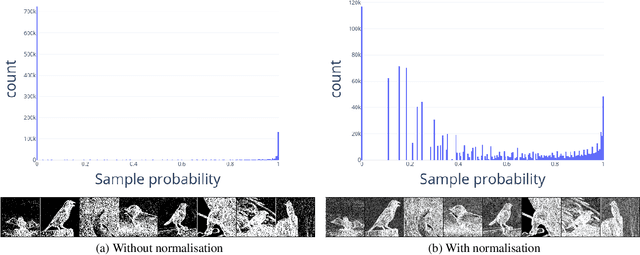
A scanning pixel camera is a novel low-cost, low-power sensor that is not diffraction limited. It produces data as a sequence of samples extracted from various parts of the scene during the course of a scan. It can provide very detailed images at the expense of samplerates and slow image acquisition time. This paper proposes a new algorithm which allows the sensor to adapt the samplerate over the course of this sequence. This makes it possible to overcome some of these limitations by minimising the bandwidth and time required to image and transmit a scene, while maintaining image quality. We examine applications to image classification and semantic segmentation and are able to achieve similar results compared to a fully sampled input, while using 80% fewer samples
Utilizing supervised models to infer consensus labels and their quality from data with multiple annotators
Oct 13, 2022
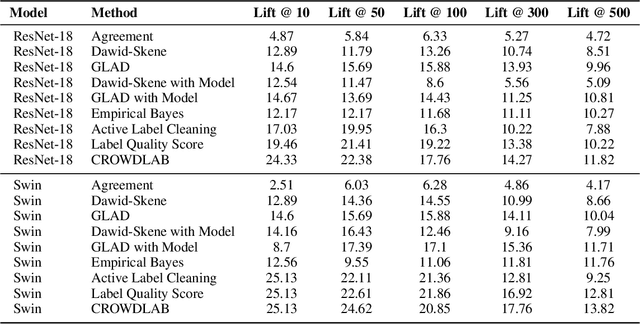
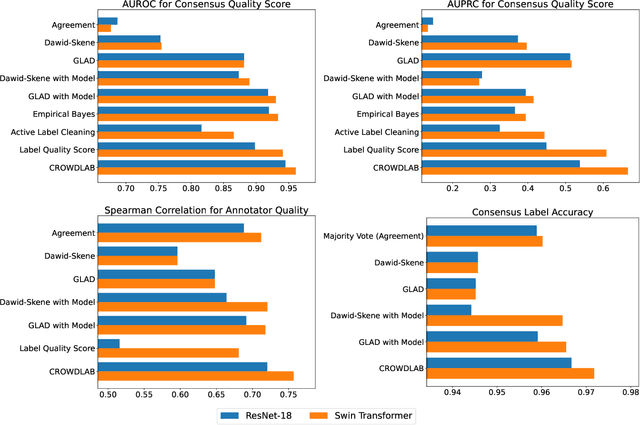
Real-world data for classification is often labeled by multiple annotators. For analyzing such data, we introduce CROWDLAB, a straightforward approach to estimate: (1) A consensus label for each example that aggregates the individual annotations (more accurately than aggregation via majority-vote or other algorithms used in crowdsourcing); (2) A confidence score for how likely each consensus label is correct (via well-calibrated estimates that account for the number of annotations for each example and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier); (3) A rating for each annotator quantifying the overall correctness of their labels. While many algorithms have been proposed to estimate related quantities in crowdsourcing, these often rely on sophisticated generative models with iterative inference schemes, whereas CROWDLAB is based on simple weighted ensembling. Many algorithms also rely solely on annotator statistics, ignoring the features of the examples from which the annotations derive. CROWDLAB in contrast utilizes any classifier model trained on these features, which can generalize between examples with similar features. In evaluations on real-world multi-annotator image data, our proposed method provides superior estimates for (1)-(3) than many alternative algorithms.
Large-scale Bilingual Language-Image Contrastive Learning
Mar 28, 2022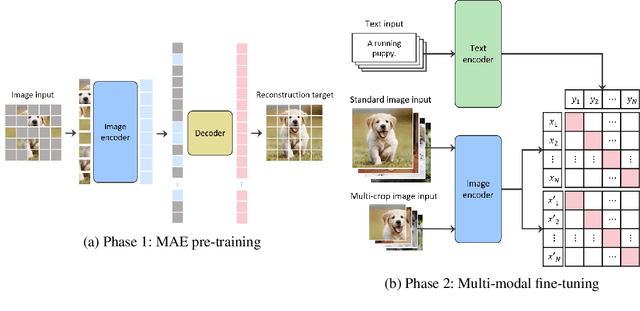
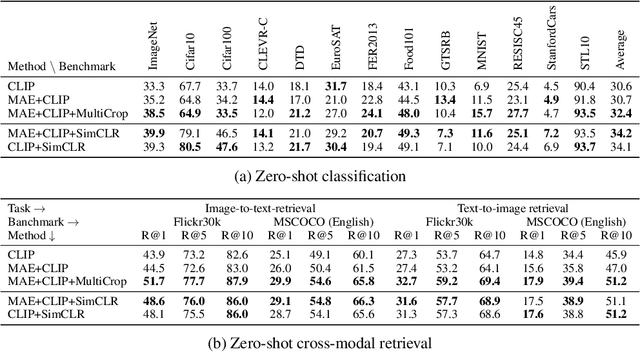
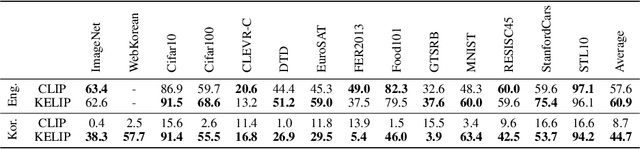
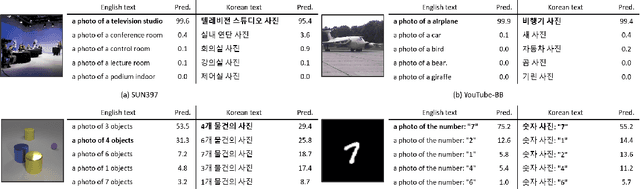
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Toward 3D Spatial Reasoning for Human-like Text-based Visual Question Answering
Sep 21, 2022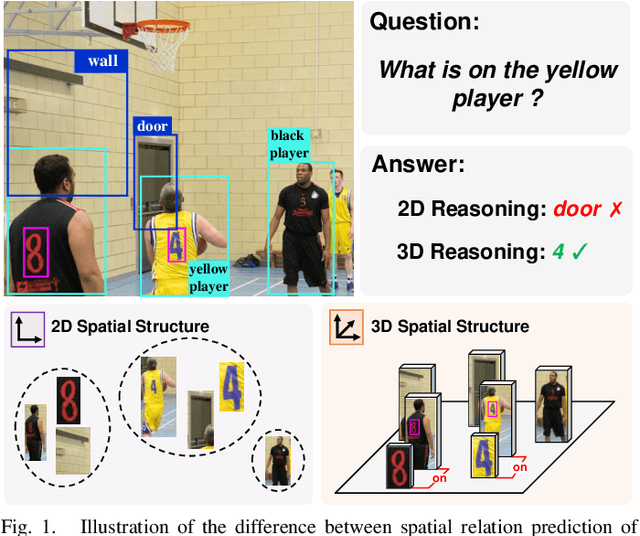
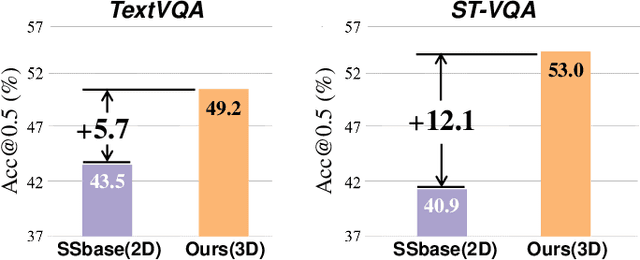
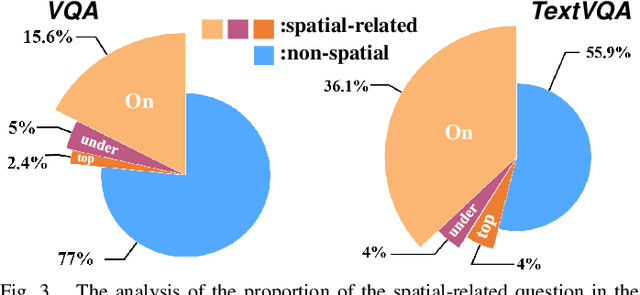
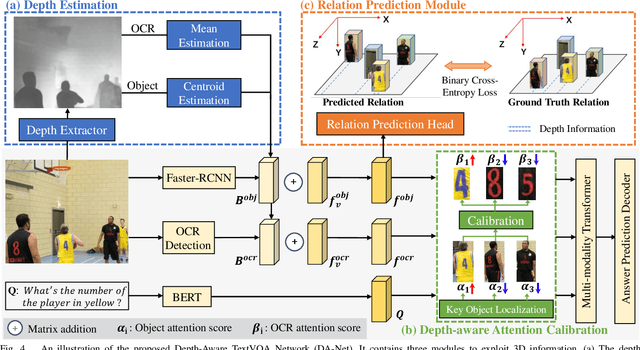
Text-based Visual Question Answering~(TextVQA) aims to produce correct answers for given questions about the images with multiple scene texts. In most cases, the texts naturally attach to the surface of the objects. Therefore, spatial reasoning between texts and objects is crucial in TextVQA. However, existing approaches are constrained within 2D spatial information learned from the input images and rely on transformer-based architectures to reason implicitly during the fusion process. Under this setting, these 2D spatial reasoning approaches cannot distinguish the fine-grain spatial relations between visual objects and scene texts on the same image plane, thereby impairing the interpretability and performance of TextVQA models. In this paper, we introduce 3D geometric information into a human-like spatial reasoning process to capture the contextual knowledge of key objects step-by-step. %we formulate a human-like spatial reasoning process by introducing 3D geometric information for capturing key objects' contextual knowledge. To enhance the model's understanding of 3D spatial relationships, Specifically, (i)~we propose a relation prediction module for accurately locating the region of interest of critical objects; (ii)~we design a depth-aware attention calibration module for calibrating the OCR tokens' attention according to critical objects. Extensive experiments show that our method achieves state-of-the-art performance on TextVQA and ST-VQA datasets. More encouragingly, our model surpasses others by clear margins of 5.7\% and 12.1\% on questions that involve spatial reasoning in TextVQA and ST-VQA valid split. Besides, we also verify the generalizability of our model on the text-based image captioning task.
The Value of AI Guidance in Human Examination of Synthetically-Generated Faces
Aug 22, 2022



Face image synthesis has progressed beyond the point at which humans can effectively distinguish authentic faces from synthetically generated ones. Recently developed synthetic face image detectors boast "better-than-human" discriminative ability, especially those guided by human perceptual intelligence during the model's training process. In this paper, we investigate whether these human-guided synthetic face detectors can assist non-expert human operators in the task of synthetic image detection when compared to models trained without human-guidance. We conducted a large-scale experiment with more than 1,560 subjects classifying whether an image shows an authentic or synthetically-generated face, and annotate regions that supported their decisions. In total, 56,015 annotations across 3,780 unique face images were collected. All subjects first examined samples without any AI support, followed by samples given (a) the AI's decision ("synthetic" or "authentic"), (b) class activation maps illustrating where the model deems salient for its decision, or (c) both the AI's decision and AI's saliency map. Synthetic faces were generated with six modern Generative Adversarial Networks. Interesting observations from this experiment include: (1) models trained with human-guidance offer better support to human examination of face images when compared to models trained traditionally using cross-entropy loss, (2) binary decisions presented to humans offers better support than saliency maps, (3) understanding the AI's accuracy helps humans to increase trust in a given model and thus increase their overall accuracy. This work demonstrates that although humans supported by machines achieve better-than-random accuracy of synthetic face detection, the ways of supplying humans with AI support and of building trust are key factors determining high effectiveness of the human-AI tandem.
Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach
Apr 21, 2022



Collecting paired training data is difficult in practice, but the unpaired samples broadly exist. Current approaches aim at generating synthesized training data from the unpaired samples by exploring the relationship between the corrupted and clean data. This work proposes LUD-VAE, a deep generative method to learn the joint probability density function from data sampled from marginal distributions. Our approach is based on a carefully designed probabilistic graphical model in which the clean and corrupted data domains are conditionally independent. Using variational inference, we maximize the evidence lower bound (ELBO) to estimate the joint probability density function. Furthermore, we show that the ELBO is computable without paired samples under the inference invariant assumption. This property provides the mathematical rationale of our approach in the unpaired setting. Finally, we apply our method to real-world image denoising and super-resolution tasks and train the models using the synthetic data generated by the LUD-VAE. Experimental results validate the advantages of our method over other learnable approaches.
Arbitrary Style Transfer with Structure Enhancement by Combining the Global and Local Loss
Jul 23, 2022
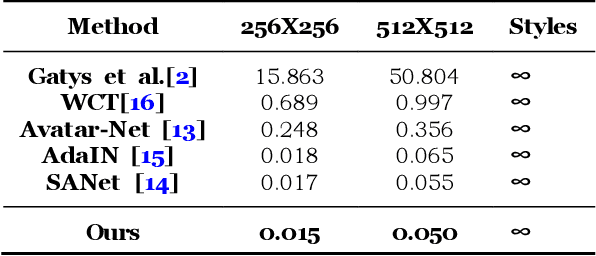
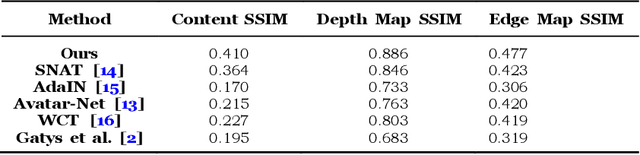
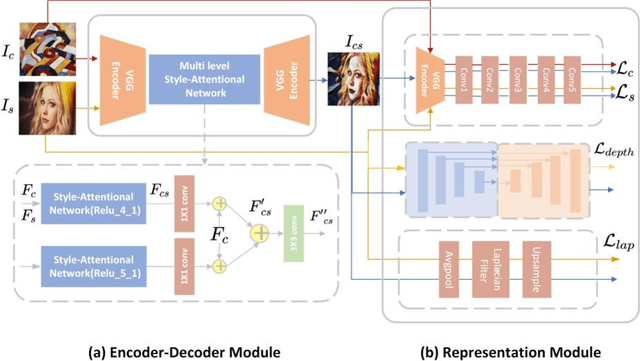
Arbitrary style transfer generates an artistic image which combines the structure of a content image and the artistic style of the artwork by using only one trained network. The image representation used in this method contains content structure representation and the style patterns representation, which is usually the features representation of high-level in the pre-trained classification networks. However, the traditional classification networks were designed for classification which usually focus on high-level features and ignore other features. As the result, the stylized images distribute style elements evenly throughout the image and make the overall image structure unrecognizable. To solve this problem, we introduce a novel arbitrary style transfer method with structure enhancement by combining the global and local loss. The local structure details are represented by Lapstyle and the global structure is controlled by the image depth. Experimental results demonstrate that our method can generate higher-quality images with impressive visual effects on several common datasets, comparing with other state-of-the-art methods.
OCR for TIFF Compressed Document Images Directly in Compressed Domain Using Text segmentation and Hidden Markov Model
Sep 13, 2022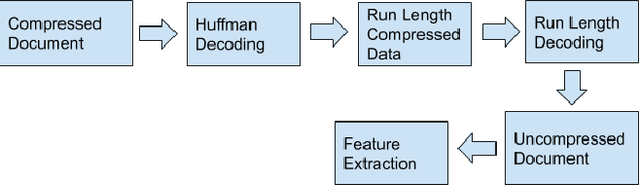

In today's technological era, document images play an important and integral part in our day to day life, and specifically with the surge of Covid-19, digitally scanned documents have become key source of communication, thus avoiding any sort of infection through physical contact. Storage and transmission of scanned document images is a very memory intensive task, hence compression techniques are being used to reduce the image size before archival and transmission. To extract information or to operate on the compressed images, we have two ways of doing it. The first way is to decompress the image and operate on it and subsequently compress it again for the efficiency of storage and transmission. The other way is to use the characteristics of the underlying compression algorithm to directly process the images in their compressed form without involving decompression and re-compression. In this paper, we propose a novel idea of developing an OCR for CCITT (The International Telegraph and Telephone Consultative Committee) compressed machine printed TIFF document images directly in the compressed domain. After segmenting text regions into lines and words, HMM is applied for recognition using three coding modes of CCITT- horizontal, vertical and the pass mode. Experimental results show that OCR on pass modes give a promising results.