 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CabViT: Cross Attention among Blocks for Vision Transformer
Nov 14, 2022
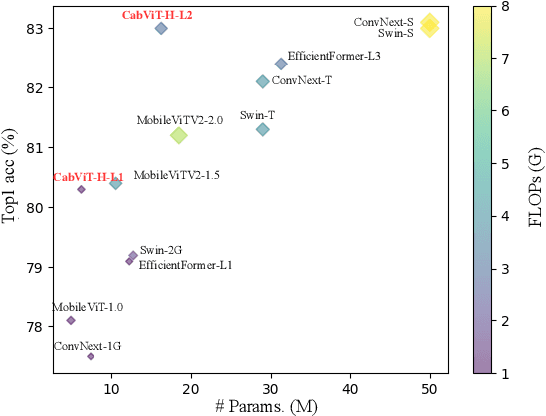
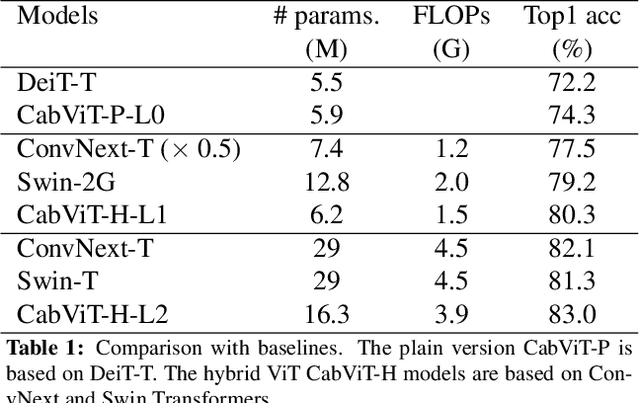
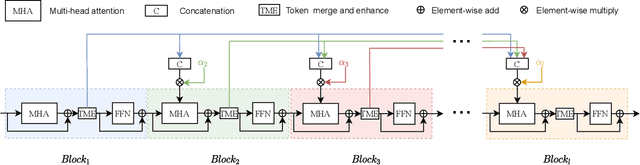
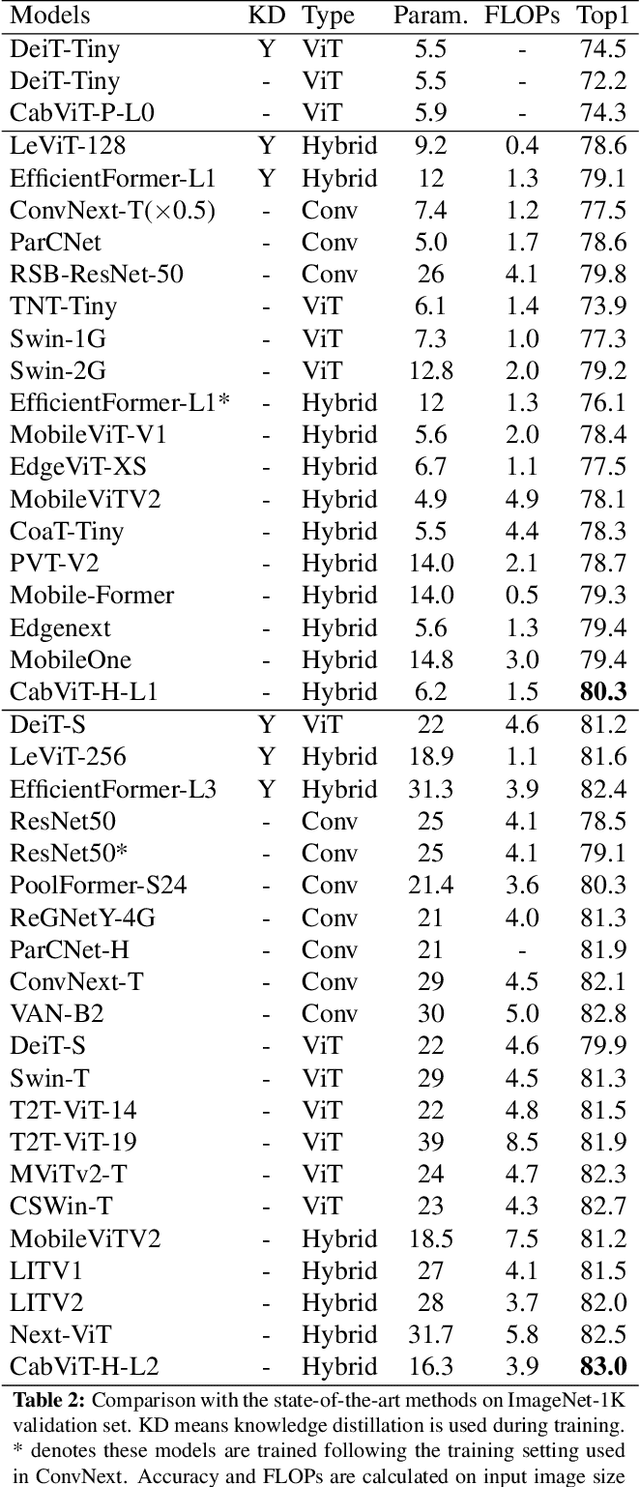
Since the vision transformer (ViT) has achieved impressive performance in image classification, an increasing number of researchers pay their attentions to designing more efficient vision transformer models. A general research line is reducing computational cost of self attention modules by adopting sparse attention or using local attention windows. In contrast, we propose to design high performance transformer based architectures by densifying the attention pattern. Specifically, we propose cross attention among blocks of ViT (CabViT), which uses tokens from previous blocks in the same stage as extra input to the multi-head attention of transformers. The proposed CabViT enhances the interactions of tokens across blocks with potentially different semantics, and encourages more information flows to the lower levels, which together improves model performance and model convergence with limited extra cost. Based on the proposed CabViT, we design a series of CabViT models which achieve the best trade-off between model size, computational cost and accuracy. For instance without the need of knowledge distillation to strength the training, CabViT achieves 83.0% top-1 accuracy on Imagenet with only 16.3 million parameters and about 3.9G FLOPs, saving almost half parameters and 13% computational cost while gaining 0.9% higher accuracy compared with ConvNext, use 52% of parameters but gaining 0.6% accuracy compared with distilled EfficientFormer
Semantic-SuPer: A Semantic-aware Surgical Perception Framework for Endoscopic Tissue Classification, Reconstruction, and Tracking
Oct 29, 2022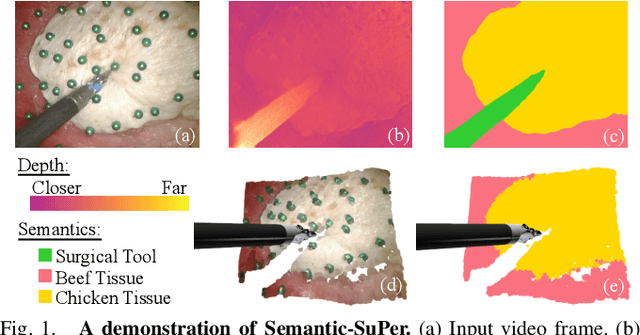
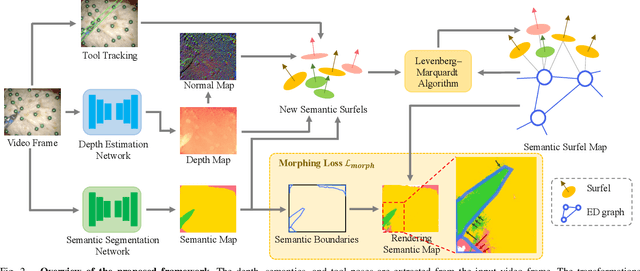


Accurate and robust tracking and reconstruction of the surgical scene is a critical enabling technology toward autonomous robotic surgery. Existing algorithms for 3D perception in surgery mainly rely on geometric information, while we propose to also leverage semantic information inferred from the endoscopic video using image segmentation algorithms. In this paper, we present a novel, comprehensive surgical perception framework, Semantic-SuPer, that integrates geometric and semantic information to facilitate data association, 3D reconstruction, and tracking of endoscopic scenes, benefiting downstream tasks like surgical navigation. The proposed framework is demonstrated on challenging endoscopic data with deforming tissue, showing its advantages over our baseline and several other state-of the-art approaches. Our code and dataset will be available at https://github.com/ucsdarclab/Python-SuPer.
Content-Based Search for Deep Generative Models
Oct 06, 2022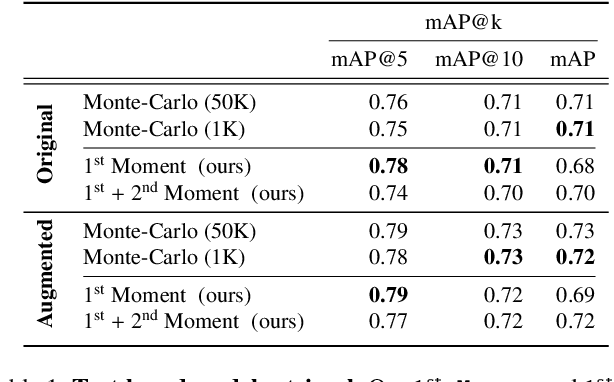
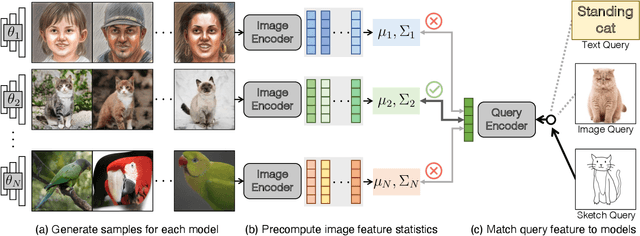
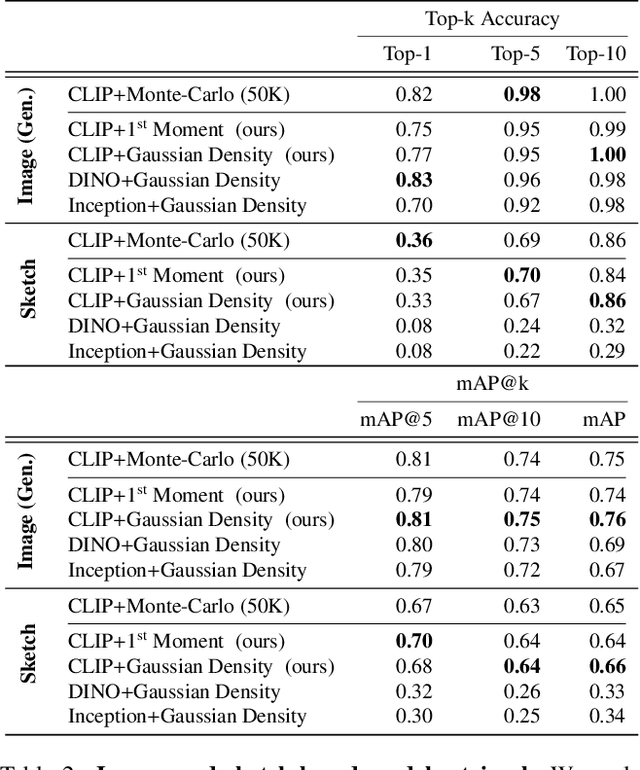

The growing proliferation of pretrained generative models has made it infeasible for a user to be fully cognizant of every model in existence. To address this need, we introduce the task of content-based model search: given a query and a large set of generative models, find the models that best match the query. Because each generative model produces a distribution of images, we formulate the search problem as an optimization to maximize the probability of generating a query match given a model. We develop approximations to make this problem tractable when the query is an image, a sketch, a text description, another generative model, or a combination of the above. We benchmark our method in both accuracy and speed over a set of generative models. We demonstrate that our model search retrieves suitable models for image editing and reconstruction, few-shot transfer learning, and latent space interpolation. Finally, we deploy our search algorithm to our online generative model-sharing platform at https://modelverse.cs.cmu.edu.
Multi-modal unsupervised brain image registration using edge maps
Feb 22, 2022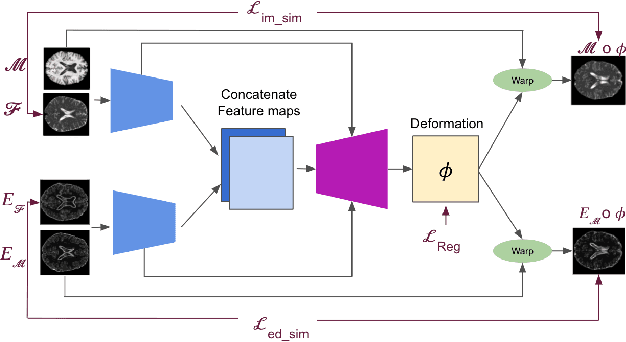
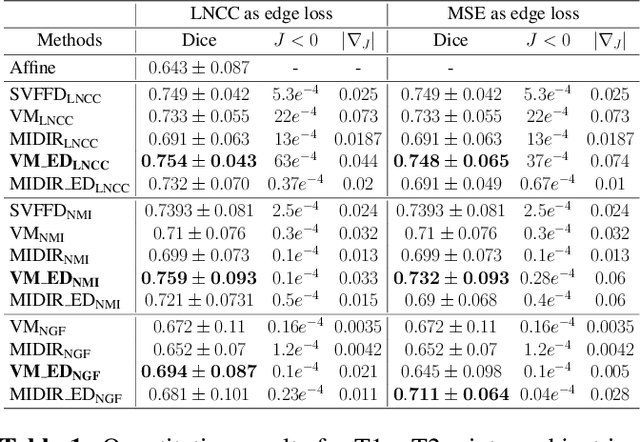


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.
BEV Lane Det: Fast Lane Detection on BEV Ground
Oct 12, 2022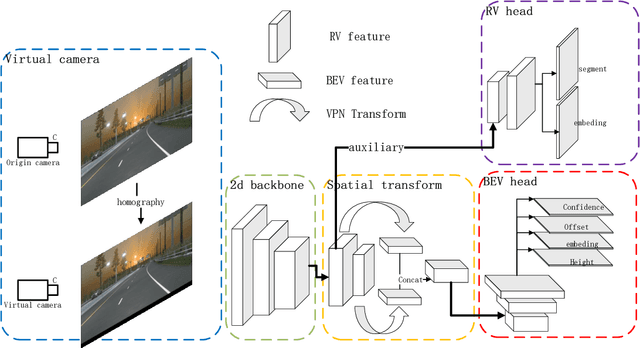
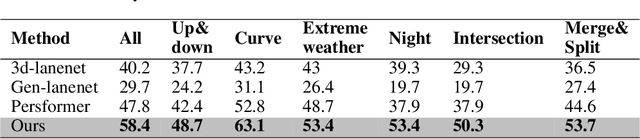
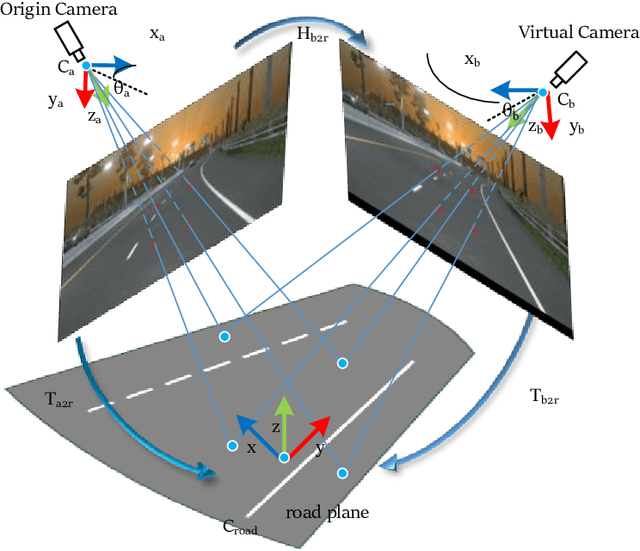

Recently, 3D lane detection has been an actively developing area in autonomous driving which is the key to routing the vehicle. This work proposes a deployment-oriented monocular 3D lane detector with only naive CNN and FC layers. This detector achieved state-of-the-art results on the Apollo 3D Lane Synthetic dataset and OpenLane real-world dataset with 96 FPS runtime speed. We conduct three techniques in our detector: (1) Virtual Camera eliminates the difference in poses of cameras mounted on different vehicles. (2) Spatial Feature Pyramid Transform as a light-weighed image-view to bird-eye view transformer can utilize scales of image-view featmaps. (3) Yolo Style Lane Representation makes a good balance between bird-eye view resolution and runtime speed. Meanwhile, it can reduce the inefficiency caused by the class imbalance due to the sparsity of the lane detection task during training. Combining these three techniques, we obtained a 58.4% F1-score on the OpenLane dataset, which is a 10.6% improvement over the baseline. On the Apollo dataset, we achieved an F1-score of 96.9%, which is 4% points of supremacy over the best on the leaderboard. The source code will release soon.
Accelerating Score-based Generative Models for High-Resolution Image Synthesis
Jun 09, 2022



Score-based generative models (SGMs) have recently emerged as a promising class of generative models. The key idea is to produce high-quality images by recurrently adding Gaussian noises and gradients to a Gaussian sample until converging to the target distribution, a.k.a. the diffusion sampling. To ensure stability of convergence in sampling and generation quality, however, this sequential sampling process has to take a small step size and many sampling iterations (e.g., 2000). Several acceleration methods have been proposed with focus on low-resolution generation. In this work, we consider the acceleration of high-resolution generation with SGMs, a more challenging yet more important problem. We prove theoretically that this slow convergence drawback is primarily due to the ignorance of the target distribution. Further, we introduce a novel Target Distribution Aware Sampling (TDAS) method by leveraging the structural priors in space and frequency domains. Extensive experiments on CIFAR-10, CelebA, LSUN, and FFHQ datasets validate that TDAS can consistently accelerate state-of-the-art SGMs, particularly on more challenging high resolution (1024x1024) image generation tasks by up to 18.4x, whilst largely maintaining the synthesis quality. With fewer sampling iterations, TDAS can still generate good quality images. In contrast, the existing methods degrade drastically or even fails completely
Token Transformer: Can class token help window-based transformer build better long-range interactions?
Nov 11, 2022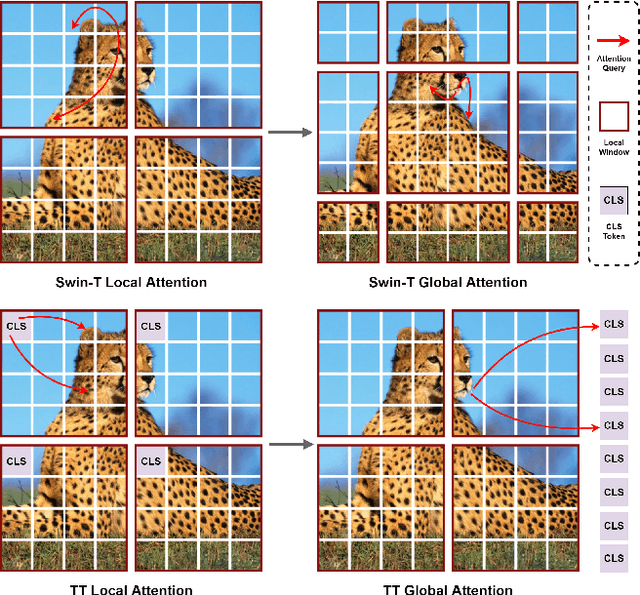
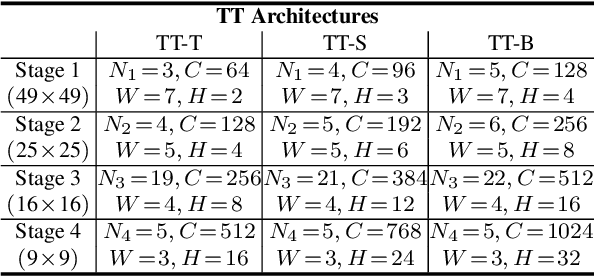

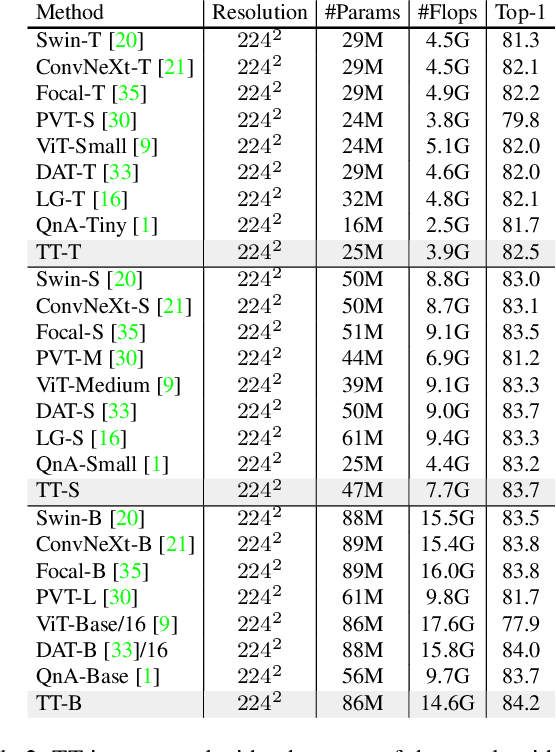
Compared with the vanilla transformer, the window-based transformer offers a better trade-off between accuracy and efficiency. Although the window-based transformer has made great progress, its long-range modeling capabilities are limited due to the size of the local window and the window connection scheme. To address this problem, we propose a novel Token Transformer (TT). The core mechanism of TT is the addition of a Class (CLS) token for summarizing window information in each local window. We refer to this type of token interaction as CLS Attention. These CLS tokens will interact spatially with the tokens in each window to enable long-range modeling. In order to preserve the hierarchical design of the window-based transformer, we designed Feature Inheritance Module (FIM) in each phase of TT to deliver the local window information from the previous phase to the CLS token in the next phase. In addition, we have designed a Spatial-Channel Feedforward Network (SCFFN) in TT, which can mix CLS tokens and embedded tokens on the spatial domain and channel domain without additional parameters. Extensive experiments have shown that our TT achieves competitive results with low parameters in image classification and downstream tasks.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 19, 2022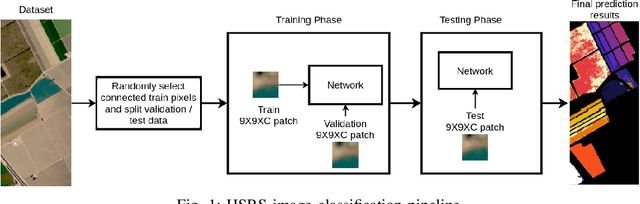

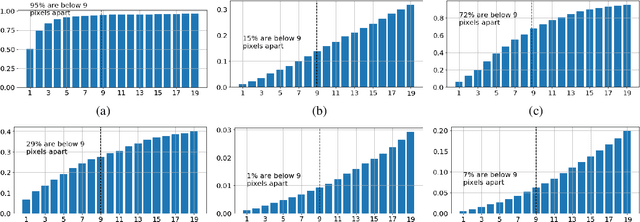
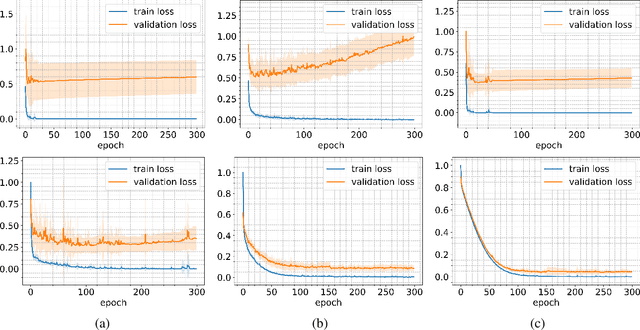
Employing deep neural networks for Hyper-spectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use a special class of deep neural networks, namely Bayesian neural network, to classify HSRS images. To the extent of our knowledge, this is the first time that this class of neural networks has been used in HSRS image classification. Bayesian neural networks provide an inherent tool for measuring uncertainty. We show that a Bayesian network can outperform a similarly-constructed non-Bayesian convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Moreover, experimental results for the Pavia Centre, Salinas, and Botswana datasets show that the Bayesian network is more stable and robust to model pruning. Furthermore, we analyze the prediction uncertainty of the Bayesian model and show that the prediction uncertainty metric can provide information about the model predictions and has a positive correlation with the prediction error.
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022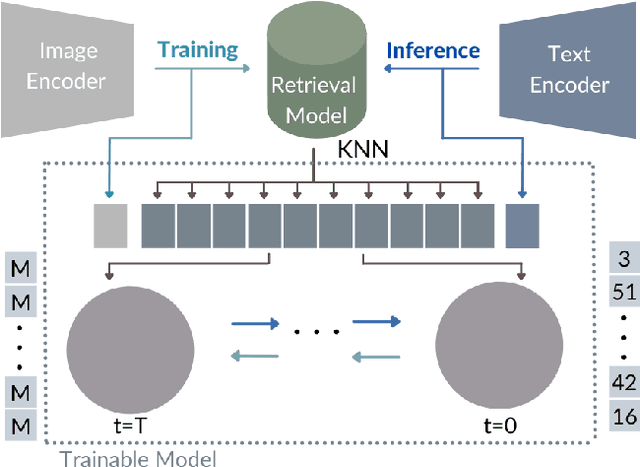
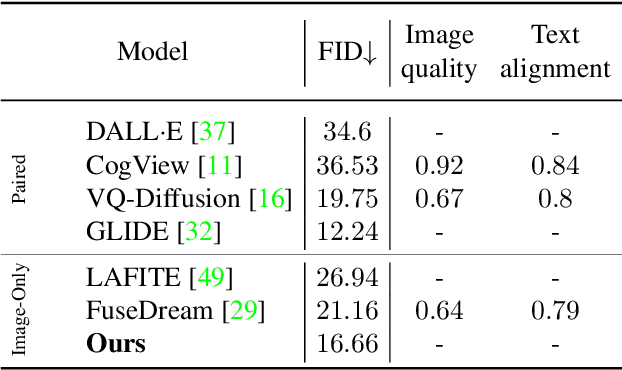
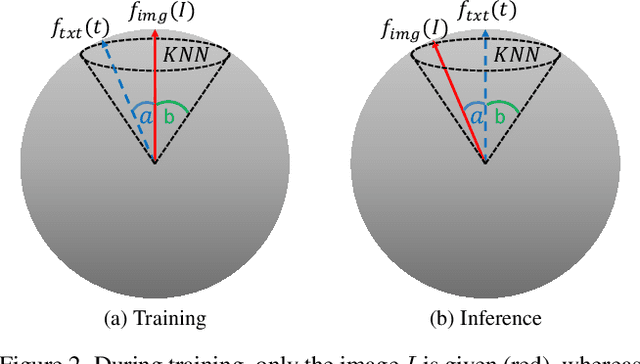

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
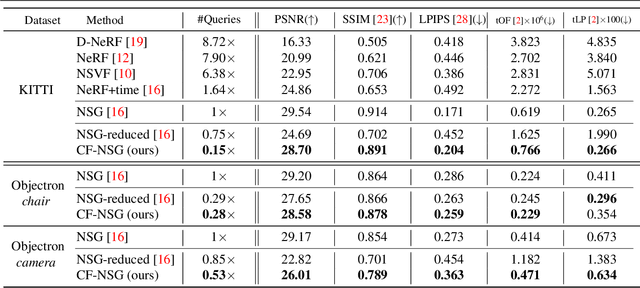
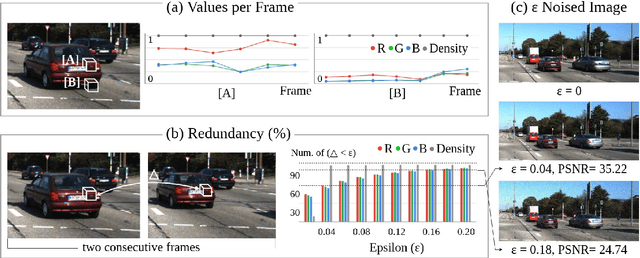

Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG