 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for V2X Orchestration
Nov 12, 2022
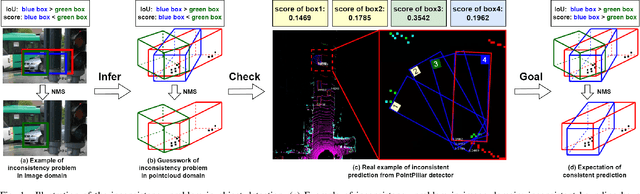

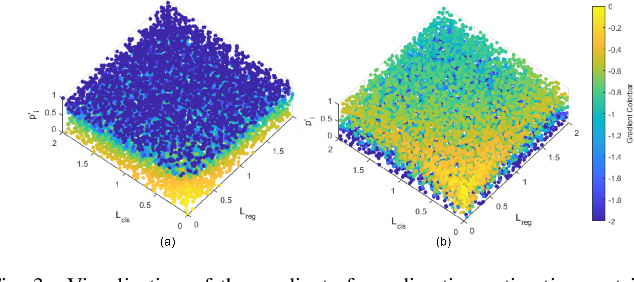
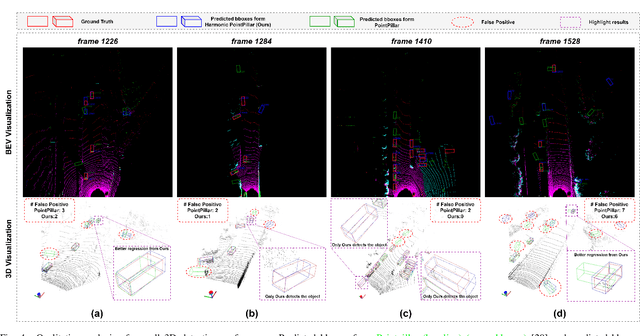
Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency.
Investigations in Audio Captioning: Addressing Vocabulary Imbalance and Evaluating Suitability of Language-Centric Performance Metrics
Nov 12, 2022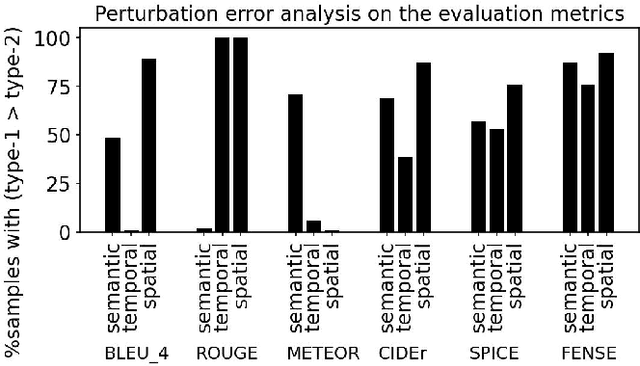
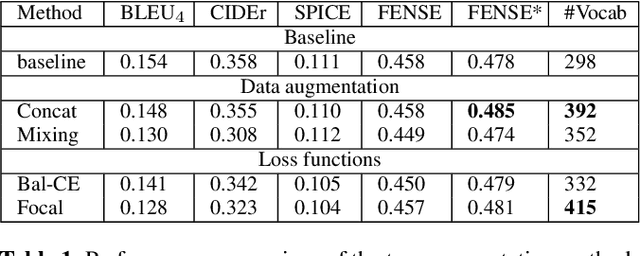
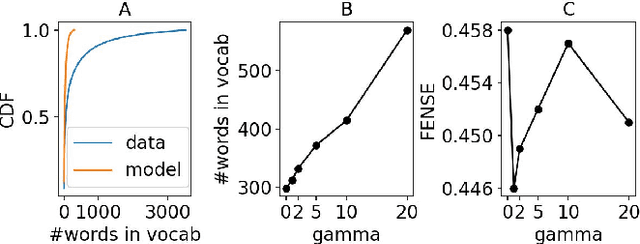
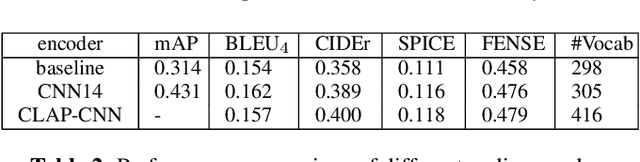
The analysis, processing, and extraction of meaningful information from sounds all around us is the subject of the broader area of audio analytics. Audio captioning is a recent addition to the domain of audio analytics, a cross-modal translation task that focuses on generating natural descriptions from sound events occurring in an audio stream. In this work, we identify and improve on three main challenges in automated audio captioning: i) data scarcity, ii) imbalance or limitations in the audio captions vocabulary, and iii) the proper performance evaluation metric that can best capture both auditory and semantic characteristics. We find that generally adopted loss functions can result in an unfair vocabulary imbalance during model training. We propose two audio captioning augmentation methods that enrich the training dataset and the vocabulary size. We further underline the need for in-domain pretraining by exploring the suitability of audio encoders that were previously trained on different audio tasks. Finally, we systematically explore five performance metrics borrowed from the image captioning domain and highlight their limitations for the audio domain.
A Survey of Cross-Modality Brain Image Synthesis
Feb 16, 2022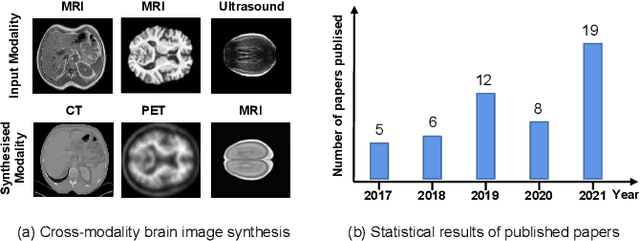
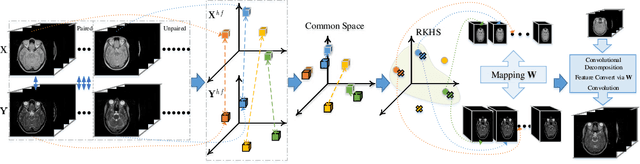
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. A realistic solution is to explore either an unsupervised learning or a semi-supervised learning to synthesize the absent neuroimaging data. In this paper, we tend to approach multi-modality brain image synthesis task from different perspectives, which include the level of supervision, the range of modality synthesis, and the synthesis-based downstream tasks. Particularly, we provide in-depth analysis on how cross-modality brain image synthesis can improve the performance of different downstream tasks. Finally, we evaluate the challenges and provide several open directions for this community. All resources are available at https://github.com/M-3LAB/awesome-multimodal-brain-image-systhesis
Perception-Distortion Trade-off in the SR Space Spanned by Flow Models
Sep 18, 2022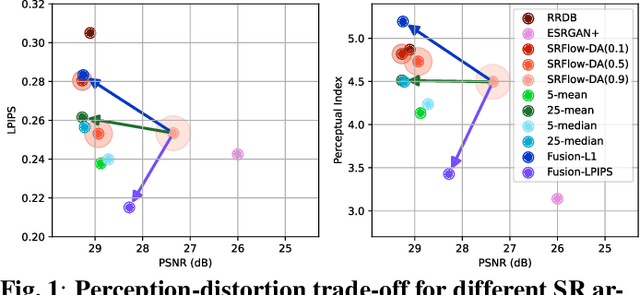
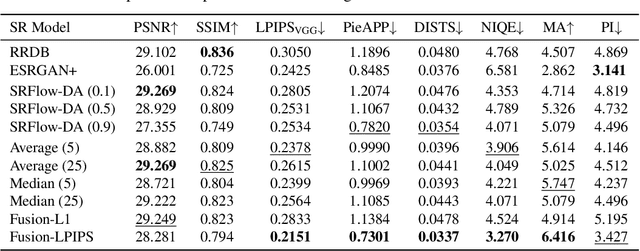


Flow-based generative super-resolution (SR) models learn to produce a diverse set of feasible SR solutions, called the SR space. Diversity of SR solutions increases with the temperature ($\tau$) of latent variables, which introduces random variations of texture among sample solutions, resulting in visual artifacts and low fidelity. In this paper, we present a simple but effective image ensembling/fusion approach to obtain a single SR image eliminating random artifacts and improving fidelity without significantly compromising perceptual quality. We achieve this by benefiting from a diverse set of feasible photo-realistic solutions in the SR space spanned by flow models. We propose different image ensembling and fusion strategies which offer multiple paths to move sample solutions in the SR space to more desired destinations in the perception-distortion plane in a controllable manner depending on the fidelity vs. perceptual quality requirements of the task at hand. Experimental results demonstrate that our image ensembling/fusion strategy achieves more promising perception-distortion trade-off compared to sample SR images produced by flow models and adversarially trained models in terms of both quantitative metrics and visual quality.
VBLC: Visibility Boosting and Logit-Constraint Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Nov 22, 2022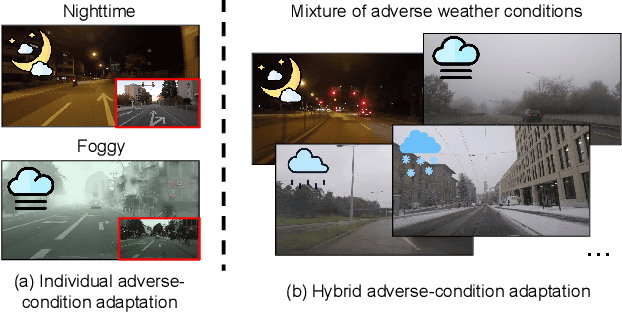
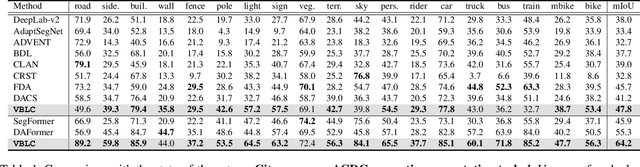
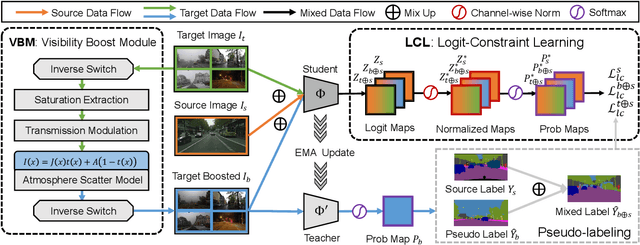

Generalizing models trained on normal visual conditions to target domains under adverse conditions is demanding in the practical systems. One prevalent solution is to bridge the domain gap between clear- and adverse-condition images to make satisfactory prediction on the target. However, previous methods often reckon on additional reference images of the same scenes taken from normal conditions, which are quite tough to collect in reality. Furthermore, most of them mainly focus on individual adverse condition such as nighttime or foggy, weakening the model versatility when encountering other adverse weathers. To overcome the above limitations, we propose a novel framework, Visibility Boosting and Logit-Constraint learning (VBLC), tailored for superior normal-to-adverse adaptation. VBLC explores the potential of getting rid of reference images and resolving the mixture of adverse conditions simultaneously. In detail, we first propose the visibility boost module to dynamically improve target images via certain priors in the image level. Then, we figure out the overconfident drawback in the conventional cross-entropy loss for self-training method and devise the logit-constraint learning, which enforces a constraint on logit outputs during training to mitigate this pain point. To the best of our knowledge, this is a new perspective for tackling such a challenging task. Extensive experiments on two normal-to-adverse domain adaptation benchmarks, i.e., Cityscapes -> ACDC and Cityscapes -> FoggyCityscapes + RainCityscapes, verify the effectiveness of VBLC, where it establishes the new state of the art. Code is available at https://github.com/BIT-DA/VBLC.
Don't Watch Me: A Spatio-Temporal Trojan Attack on Deep-Reinforcement-Learning-Augment Autonomous Driving
Nov 22, 2022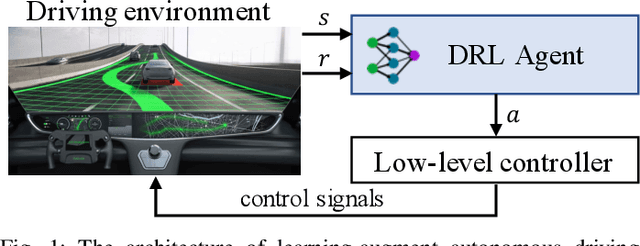
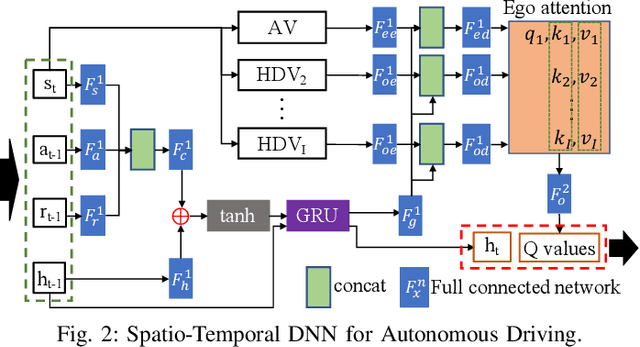
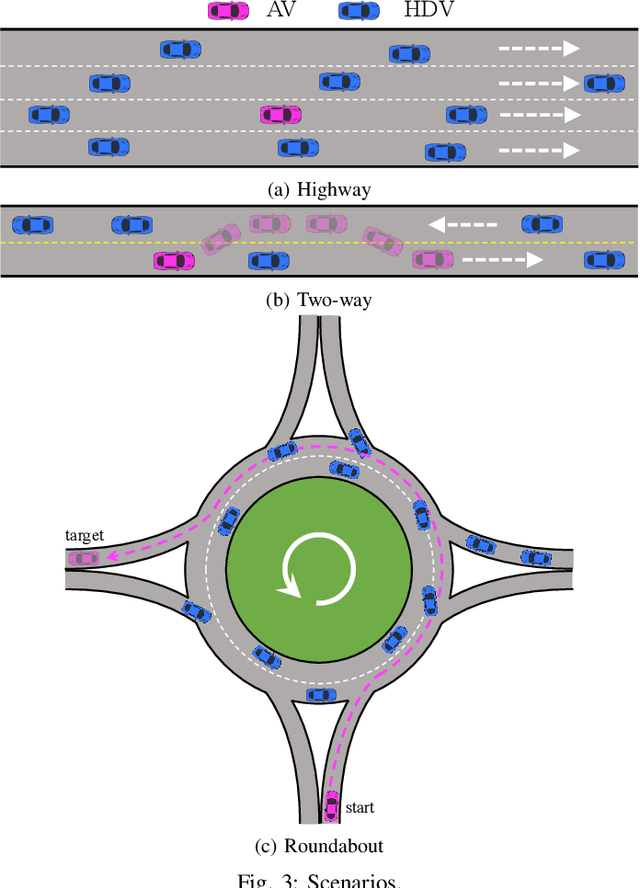
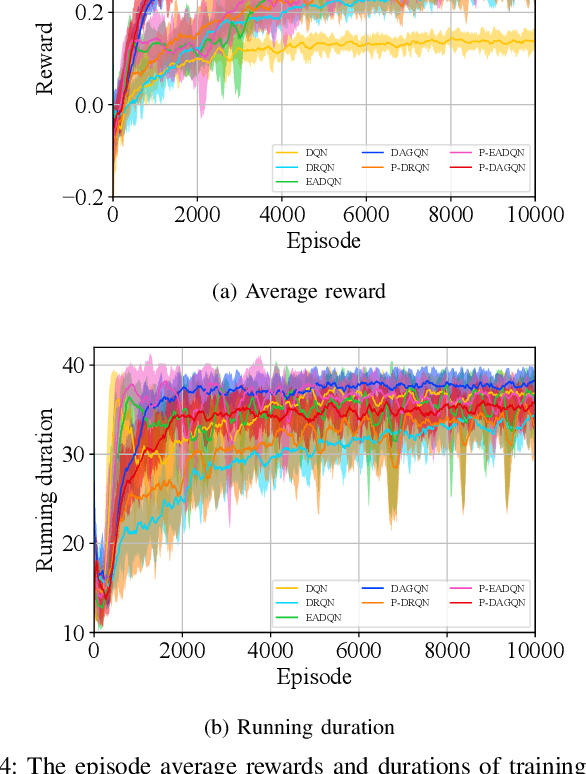
Deep reinforcement learning (DRL) is one of the most popular algorithms to realize an autonomous driving (AD) system. The key success factor of DRL is that it embraces the perception capability of deep neural networks which, however, have been proven vulnerable to Trojan attacks. Trojan attacks have been widely explored in supervised learning (SL) tasks (e.g., image classification), but rarely in sequential decision-making tasks solved by DRL. Hence, in this paper, we explore Trojan attacks on DRL for AD tasks. First, we propose a spatio-temporal DRL algorithm based on the recurrent neural network and attention mechanism to prove that capturing spatio-temporal traffic features is the key factor to the effectiveness and safety of a DRL-augment AD system. We then design a spatial-temporal Trojan attack on DRL policies, where the trigger is hidden in a sequence of spatial and temporal traffic features, rather than a single instant state used in existing Trojan on SL and DRL tasks. With our Trojan, the adversary acts as a surrounding normal vehicle and can trigger attacks via specific spatial-temporal driving behaviors, rather than physical or wireless access. Through extensive experiments, we show that while capturing spatio-temporal traffic features can improve the performance of DRL for different AD tasks, they suffer from Trojan attacks since our designed Trojan shows high stealthy (various spatio-temporal trigger patterns), effective (less than 3.1\% performance variance rate and more than 98.5\% attack success rate), and sustainable to existing advanced defenses.
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022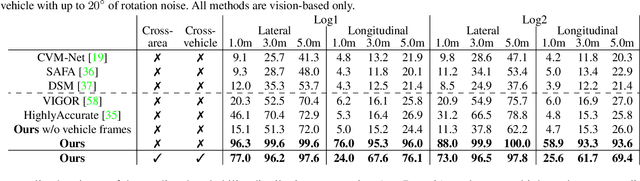
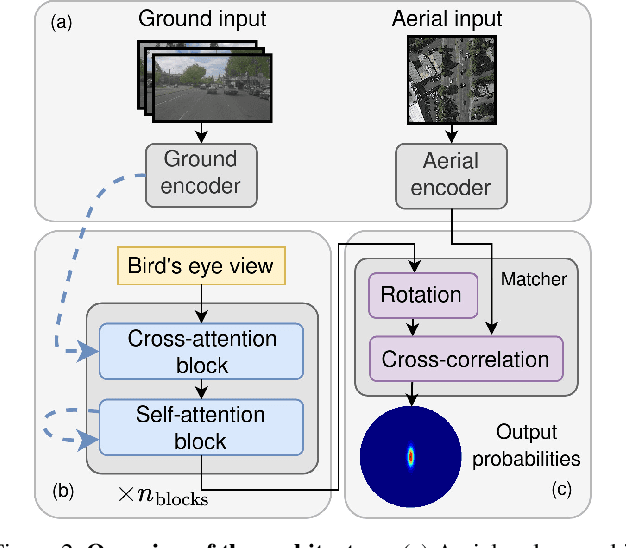
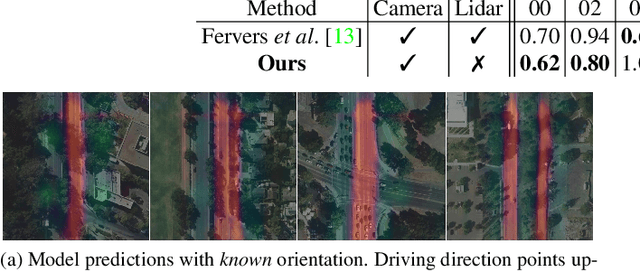
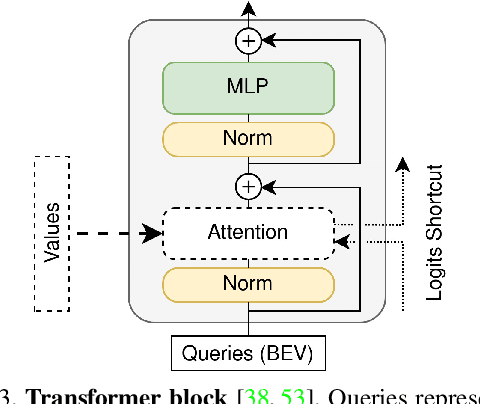
This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.
Interpreting Neural Networks through the Polytope Lens
Nov 22, 2022

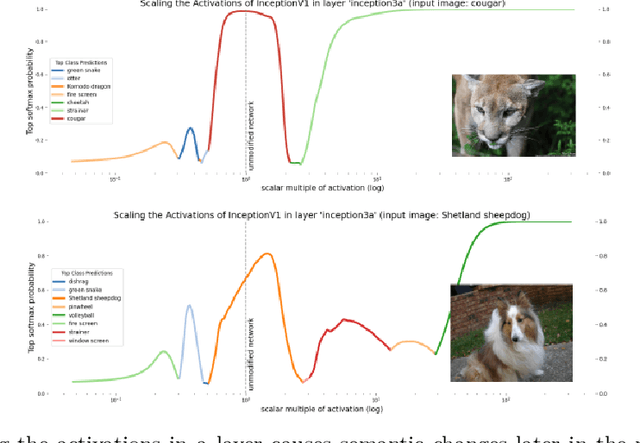
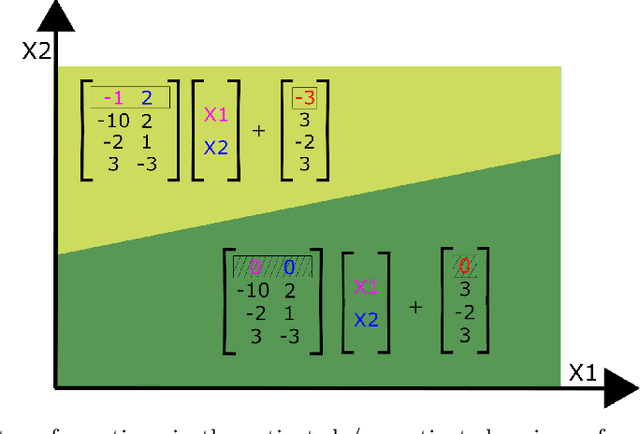
Mechanistic interpretability aims to explain what a neural network has learned at a nuts-and-bolts level. What are the fundamental primitives of neural network representations? Previous mechanistic descriptions have used individual neurons or their linear combinations to understand the representations a network has learned. But there are clues that neurons and their linear combinations are not the correct fundamental units of description: directions cannot describe how neural networks use nonlinearities to structure their representations. Moreover, many instances of individual neurons and their combinations are polysemantic (i.e. they have multiple unrelated meanings). Polysemanticity makes interpreting the network in terms of neurons or directions challenging since we can no longer assign a specific feature to a neural unit. In order to find a basic unit of description that does not suffer from these problems, we zoom in beyond just directions to study the way that piecewise linear activation functions (such as ReLU) partition the activation space into numerous discrete polytopes. We call this perspective the polytope lens. The polytope lens makes concrete predictions about the behavior of neural networks, which we evaluate through experiments on both convolutional image classifiers and language models. Specifically, we show that polytopes can be used to identify monosemantic regions of activation space (while directions are not in general monosemantic) and that the density of polytope boundaries reflect semantic boundaries. We also outline a vision for what mechanistic interpretability might look like through the polytope lens.
Towards Universal GAN Image Detection
Dec 23, 2021
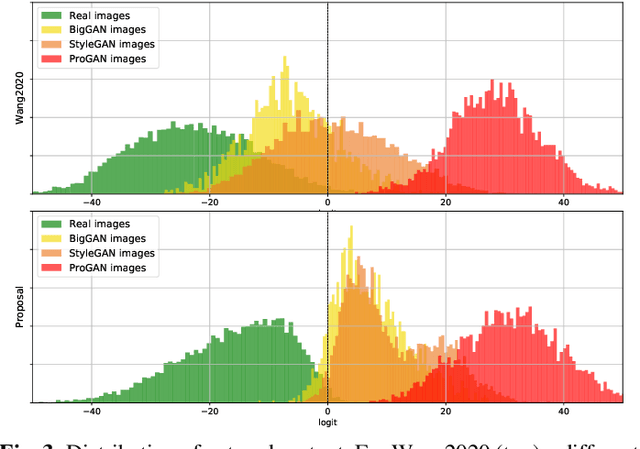
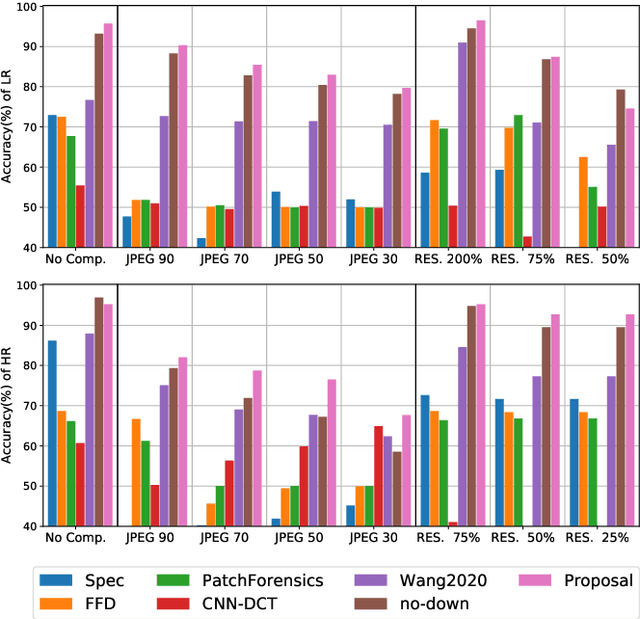
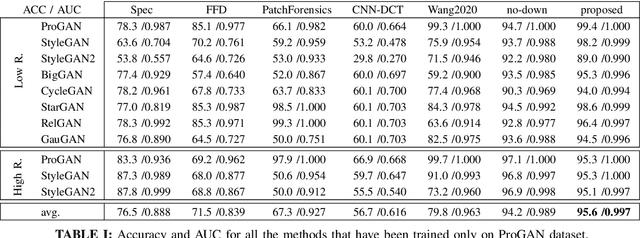
The ever higher quality and wide diffusion of fake images have spawn a quest for reliable forensic tools. Many GAN image detectors have been proposed, recently. In real world scenarios, however, most of them show limited robustness and generalization ability. Moreover, they often rely on side information not available at test time, that is, they are not universal. We investigate these problems and propose a new GAN image detector based on a limited sub-sampling architecture and a suitable contrastive learning paradigm. Experiments carried out in challenging conditions prove the proposed method to be a first step towards universal GAN image detection, ensuring also good robustness to common image impairments, and good generalization to unseen architectures.
Rhombic Grids Reduce the Number of Voxels in Fast Pulse-Echo Ultrasound Imaging
Oct 10, 2022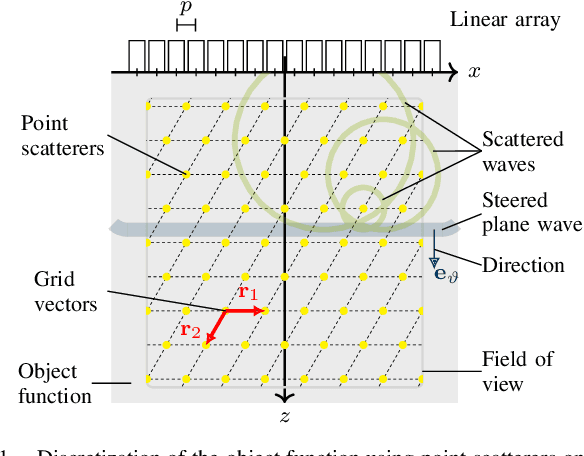
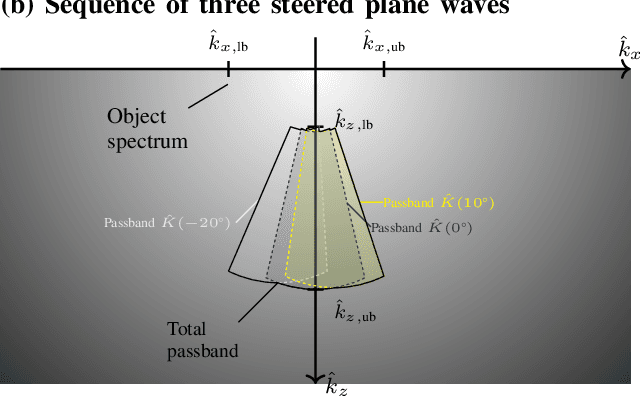
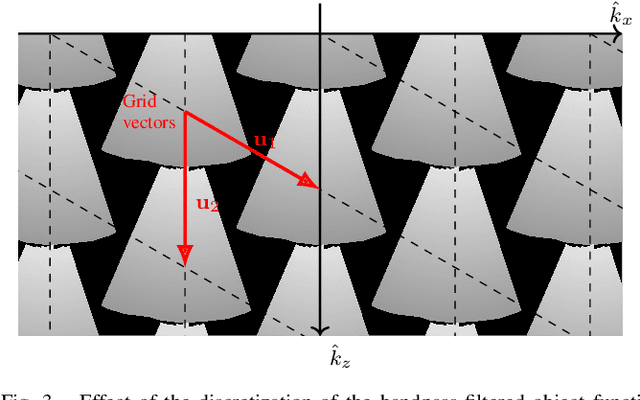
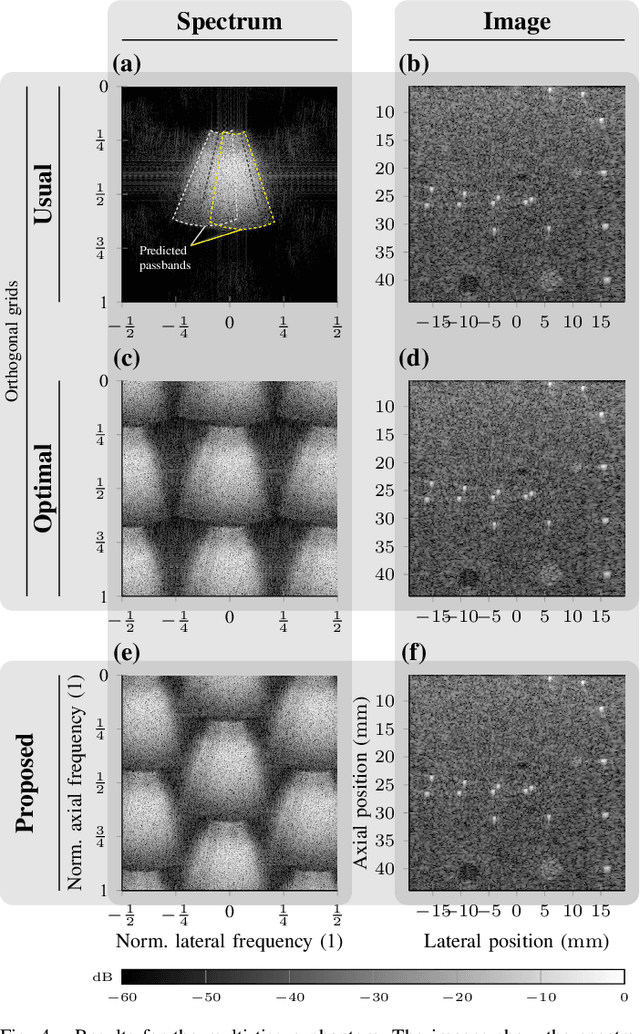
Ultrafast imaging modes, such as coherent plane-wave compounding (CPWC), capture a large field of view in a single pulse-echo measurement using parallel receive focusing. The number of foci or, equivalently, the number of volume elements (voxels) in the image determines the computational costs and the memory consumption of the image formation. Herein, 120{\deg} rhombic grids are proposed to specify the voxel positions and reduce the number of voxels in comparison to orthogonal grids. The proposed grids derive from the bivariate sampling theorem and the spectral properties of the images formed by the delay-and-sum algorithm in CPWC. A phantom experiment validated the proposed grids and showed reductions in the number of voxels by 81.4 % and 14.7 % in comparison to the usual and optimal orthogonal grids, respectively. Mean structural similarity indices above 96.6 % and relative root mean-squared errors below 6.8 % confirmed the visual equivalence of all images after interpolations to the usual orthogonal grid.