 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Capable, Less Cooperative? When LLMs Fail At Zero-Cost Collaboration
Apr 09, 2026Large language model (LLM) agents increasingly coordinate in multi-agent systems, yet we lack an understanding of where and why cooperation failures may arise. In many real-world coordination problems, from knowledge sharing in organizations to code documentation, helping others carries negligible personal cost while generating substantial collective benefits. However, whether LLM agents cooperate when helping neither benefits nor harms the helper, while being given explicit instructions to do so, remains unknown. We build a multi-agent setup designed to study cooperative behavior in a frictionless environment, removing all strategic complexity from cooperation. We find that capability does not predict cooperation: OpenAI o3 achieves only 17% of optimal collective performance while OpenAI o3-mini reaches 50%, despite identical instructions to maximize group revenue. Through a causal decomposition that automates one side of agent communication, we separate cooperation failures from competence failures, tracing their origins through agent reasoning analysis. Testing targeted interventions, we find that explicit protocols double performance for low-competence models, and tiny sharing incentives improve models with weak cooperation. Our findings suggest that scaling intelligence alone will not solve coordination problems in multi-agent systems and will require deliberate cooperative design, even when helping others costs nothing.
Do Large Language Models Know What They Are Capable Of?
Dec 31, 2025We investigate whether large language models (LLMs) can predict whether they will succeed on a given task and whether their predictions improve as they progress through multi-step tasks. We also investigate whether LLMs can learn from in-context experiences to make better decisions about whether to pursue a task in scenarios where failure is costly. All LLMs we tested are overconfident, but most predict their success with better-than-random discriminatory power. We find that newer and larger LLMs generally do not have greater discriminatory power, though Claude models do show such a trend. On multi-step agentic tasks, the overconfidence of several frontier LLMs worsens as they progress through the tasks, and reasoning LLMs perform comparably to or worse than non-reasoning LLMs. With in-context experiences of failure, some but not all LLMs reduce their overconfidence leading to significantly improved decision making, while others do not. Interestingly, all LLMs' decisions are approximately rational given their estimated probabilities of success, yet their overly-optimistic estimates result in poor decision making. These results suggest that current LLM agents are hindered by their lack of awareness of their own capabilities. We discuss the implications of LLMs' awareness of their capabilities for AI misuse and misalignment risks.
Auditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
RepliBench: Evaluating the autonomous replication capabilities of language model agents
Apr 21, 2025Uncontrollable autonomous replication of language model agents poses a critical safety risk. To better understand this risk, we introduce RepliBench, a suite of evaluations designed to measure autonomous replication capabilities. RepliBench is derived from a decomposition of these capabilities covering four core domains: obtaining resources, exfiltrating model weights, replicating onto compute, and persisting on this compute for long periods. We create 20 novel task families consisting of 86 individual tasks. We benchmark 5 frontier models, and find they do not currently pose a credible threat of self-replication, but succeed on many components and are improving rapidly. Models can deploy instances from cloud compute providers, write self-propagating programs, and exfiltrate model weights under simple security setups, but struggle to pass KYC checks or set up robust and persistent agent deployments. Overall the best model we evaluated (Claude 3.7 Sonnet) has a >50% pass@10 score on 15/20 task families, and a >50% pass@10 score for 9/20 families on the hardest variants. These findings suggest autonomous replication capability could soon emerge with improvements in these remaining areas or with human assistance.
Interpreting Neural Networks through the Polytope Lens
Nov 22, 2022



Mechanistic interpretability aims to explain what a neural network has learned at a nuts-and-bolts level. What are the fundamental primitives of neural network representations? Previous mechanistic descriptions have used individual neurons or their linear combinations to understand the representations a network has learned. But there are clues that neurons and their linear combinations are not the correct fundamental units of description: directions cannot describe how neural networks use nonlinearities to structure their representations. Moreover, many instances of individual neurons and their combinations are polysemantic (i.e. they have multiple unrelated meanings). Polysemanticity makes interpreting the network in terms of neurons or directions challenging since we can no longer assign a specific feature to a neural unit. In order to find a basic unit of description that does not suffer from these problems, we zoom in beyond just directions to study the way that piecewise linear activation functions (such as ReLU) partition the activation space into numerous discrete polytopes. We call this perspective the polytope lens. The polytope lens makes concrete predictions about the behavior of neural networks, which we evaluate through experiments on both convolutional image classifiers and language models. Specifically, we show that polytopes can be used to identify monosemantic regions of activation space (while directions are not in general monosemantic) and that the density of polytope boundaries reflect semantic boundaries. We also outline a vision for what mechanistic interpretability might look like through the polytope lens.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022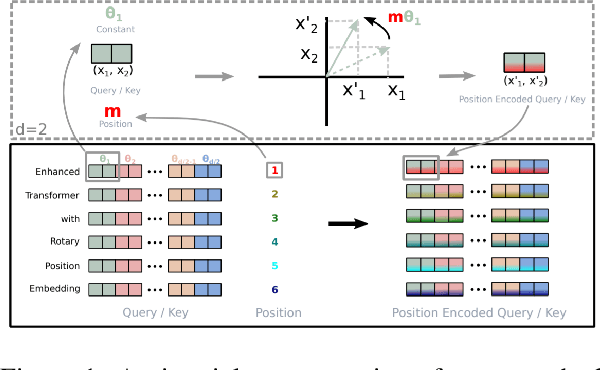
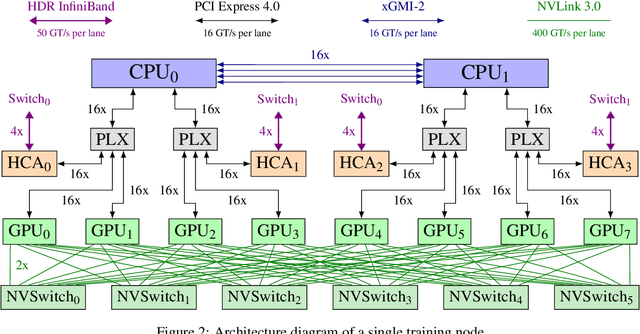

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020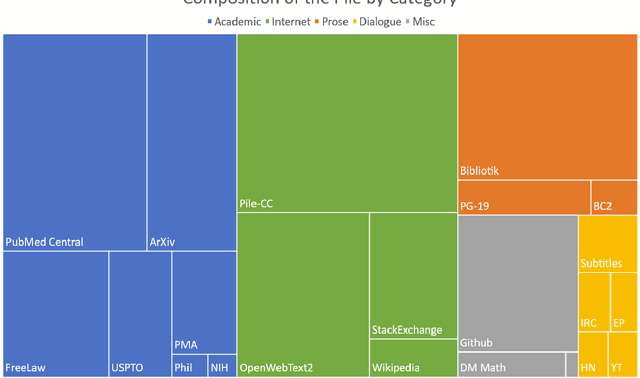
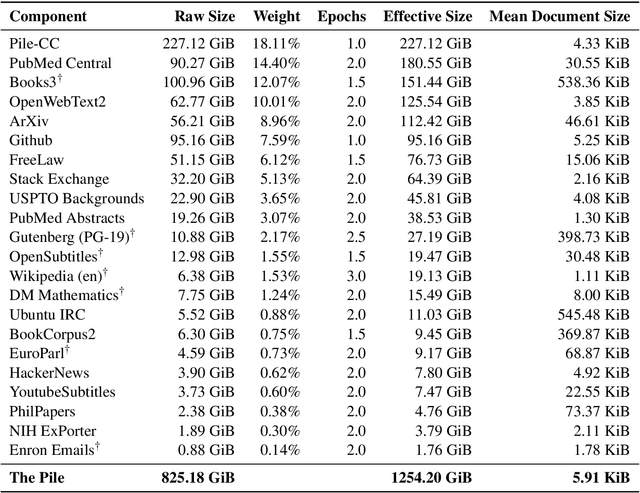
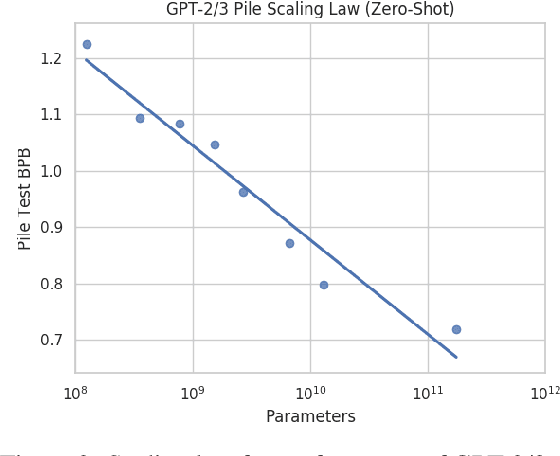
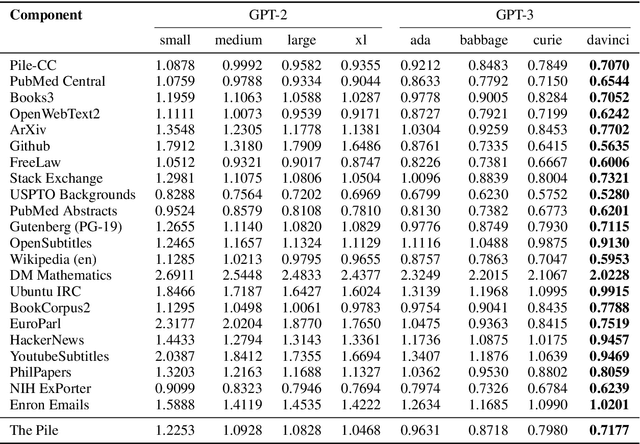
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.