 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorGuard: Online Backdoor Defense for Deep Reinforcement Learning
May 07, 2026Backdoor attacks pose a serious threat to deep reinforcement learning (DRL). Current defenses typically rely on reward anomalies to reverse-engineer triggers and model finetuning to remove backdoors. However, complex trigger patterns undermine their robustness, and fine-tuning entails high costs, limiting practical utility. Therefore, we shift defense concerns to trigger-agnostic backdoor output behaviors and propose BehaviorGuard, an online behavior-based backdoor detection and mitigation framework for DRL. Specifically, we find that regardless of attacks, backdoored policies induce consistent shifts in action distributions to ensure reliable activation, leaving detectable traces in high-quantile regions and distribution tails, even in the absence of triggers. Based on this, we design a novel metric that captures behavioral drift in action distributions to identify and suppress backdoor actions at runtime. To our knowledge, this is the first online backdoor defense that counters attacks both in single- and multi-agent DRL. Evaluated across diverse benchmarks with different backdoor attacks, BehaviorGuard consistently surpasses prior methods in both efficacy and efficiency.
* 11 pages
Joint Scheduling of Sensing Data Offloading and Edge Inference for Multi-UAV Networks
May 05, 2026Unmanned aerial vehicles (UAVs) often collaborate by collecting and offloading sensing streams to an edge server, where a deep neural network (DNN) model performs cross-stream alignment, fusion, and inference. However, the coupling between wireless offloading and DNN execution makes end-to-end latency minimization challenging. To address this issue, this paper investigates efficient edge inference in multi-UAV networks. Specifically, a multi-UAV collaborative edge inference model is first established, in which UAV sensing streams are processed by a multi-branch DNN on a multi-core accelerator. Based on this model, an end-to-end latency minimization problem with a synchronization penalty is formulated. A genetic algorithm (GA)-based full joint scheduler, termed \texttt{GA-Joint}, is then developed to obtain high-quality scheduling solutions. To reduce the search complexity, two lightweight variants, termed \texttt{GA-DAG} and \texttt{GA-DACS}, are further proposed. Simulation results demonstrate that the proposed GA-based scheduling algorithms achieve lower end-to-end latency than \texttt{Decoupled-Greedy} and \texttt{Joint-Greedy}, which represent decoupled and joint greedy scheduling schemes, respectively, in most cases. Furthermore, \texttt{GA-DACS} achieves performance close to that of \texttt{GA-Joint} in many cases and even delivers slightly lower latency in certain scenarios.
BLAST: A Stealthy Backdoor Leverage Attack against Cooperative Multi-Agent Deep Reinforcement Learning based Systems
Jan 03, 2025



Recent studies have shown that cooperative multi-agent deep reinforcement learning (c-MADRL) is under the threat of backdoor attacks. Once a backdoor trigger is observed, it will perform malicious actions leading to failures or malicious goals. However, existing backdoor attacks suffer from several issues, e.g., instant trigger patterns lack stealthiness, the backdoor is trained or activated by an additional network, or all agents are backdoored. To this end, in this paper, we propose a novel backdoor leverage attack against c-MADRL, BLAST, which attacks the entire multi-agent team by embedding the backdoor only in a single agent. Firstly, we introduce adversary spatiotemporal behavior patterns as the backdoor trigger rather than manual-injected fixed visual patterns or instant status and control the period to perform malicious actions. This method can guarantee the stealthiness and practicality of BLAST. Secondly, we hack the original reward function of the backdoor agent via unilateral guidance to inject BLAST, so as to achieve the \textit{leverage attack effect} that can pry open the entire multi-agent system via a single backdoor agent. We evaluate our BLAST against 3 classic c-MADRL algorithms (VDN, QMIX, and MAPPO) in 2 popular c-MADRL environments (SMAC and Pursuit), and 2 existing defense mechanisms. The experimental results demonstrate that BLAST can achieve a high attack success rate while maintaining a low clean performance variance rate.
A Spatiotemporal Stealthy Backdoor Attack against Cooperative Multi-Agent Deep Reinforcement Learning
Sep 12, 2024



Recent studies have shown that cooperative multi-agent deep reinforcement learning (c-MADRL) is under the threat of backdoor attacks. Once a backdoor trigger is observed, it will perform abnormal actions leading to failures or malicious goals. However, existing proposed backdoors suffer from several issues, e.g., fixed visual trigger patterns lack stealthiness, the backdoor is trained or activated by an additional network, or all agents are backdoored. To this end, in this paper, we propose a novel backdoor attack against c-MADRL, which attacks the entire multi-agent team by embedding the backdoor only in a single agent. Firstly, we introduce adversary spatiotemporal behavior patterns as the backdoor trigger rather than manual-injected fixed visual patterns or instant status and control the attack duration. This method can guarantee the stealthiness and practicality of injected backdoors. Secondly, we hack the original reward function of the backdoored agent via reward reverse and unilateral guidance during training to ensure its adverse influence on the entire team. We evaluate our backdoor attacks on two classic c-MADRL algorithms VDN and QMIX, in a popular c-MADRL environment SMAC. The experimental results demonstrate that our backdoor attacks are able to reach a high attack success rate (91.6\%) while maintaining a low clean performance variance rate (3.7\%).
A Scale-Arbitrary Image Super-Resolution Network Using Frequency-domain Information
Dec 08, 2022



Image super-resolution (SR) is a technique to recover lost high-frequency information in low-resolution (LR) images. Spatial-domain information has been widely exploited to implement image SR, so a new trend is to involve frequency-domain information in SR tasks. Besides, image SR is typically application-oriented and various computer vision tasks call for image arbitrary magnification. Therefore, in this paper, we study image features in the frequency domain to design a novel scale-arbitrary image SR network. First, we statistically analyze LR-HR image pairs of several datasets under different scale factors and find that the high-frequency spectra of different images under different scale factors suffer from different degrees of degradation, but the valid low-frequency spectra tend to be retained within a certain distribution range. Then, based on this finding, we devise an adaptive scale-aware feature division mechanism using deep reinforcement learning, which can accurately and adaptively divide the frequency spectrum into the low-frequency part to be retained and the high-frequency one to be recovered. Finally, we design a scale-aware feature recovery module to capture and fuse multi-level features for reconstructing the high-frequency spectrum at arbitrary scale factors. Extensive experiments on public datasets show the superiority of our method compared with state-of-the-art methods.
Don't Watch Me: A Spatio-Temporal Trojan Attack on Deep-Reinforcement-Learning-Augment Autonomous Driving
Nov 22, 2022Deep reinforcement learning (DRL) is one of the most popular algorithms to realize an autonomous driving (AD) system. The key success factor of DRL is that it embraces the perception capability of deep neural networks which, however, have been proven vulnerable to Trojan attacks. Trojan attacks have been widely explored in supervised learning (SL) tasks (e.g., image classification), but rarely in sequential decision-making tasks solved by DRL. Hence, in this paper, we explore Trojan attacks on DRL for AD tasks. First, we propose a spatio-temporal DRL algorithm based on the recurrent neural network and attention mechanism to prove that capturing spatio-temporal traffic features is the key factor to the effectiveness and safety of a DRL-augment AD system. We then design a spatial-temporal Trojan attack on DRL policies, where the trigger is hidden in a sequence of spatial and temporal traffic features, rather than a single instant state used in existing Trojan on SL and DRL tasks. With our Trojan, the adversary acts as a surrounding normal vehicle and can trigger attacks via specific spatial-temporal driving behaviors, rather than physical or wireless access. Through extensive experiments, we show that while capturing spatio-temporal traffic features can improve the performance of DRL for different AD tasks, they suffer from Trojan attacks since our designed Trojan shows high stealthy (various spatio-temporal trigger patterns), effective (less than 3.1\% performance variance rate and more than 98.5\% attack success rate), and sustainable to existing advanced defenses.
A Temporal-Pattern Backdoor Attack to Deep Reinforcement Learning
May 05, 2022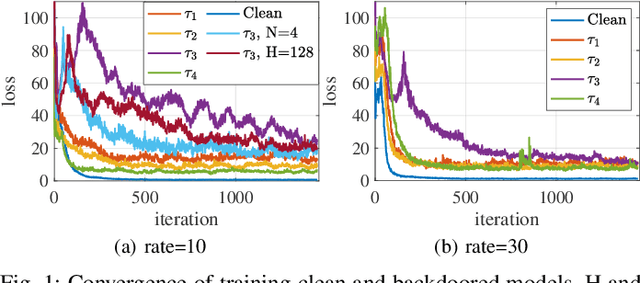
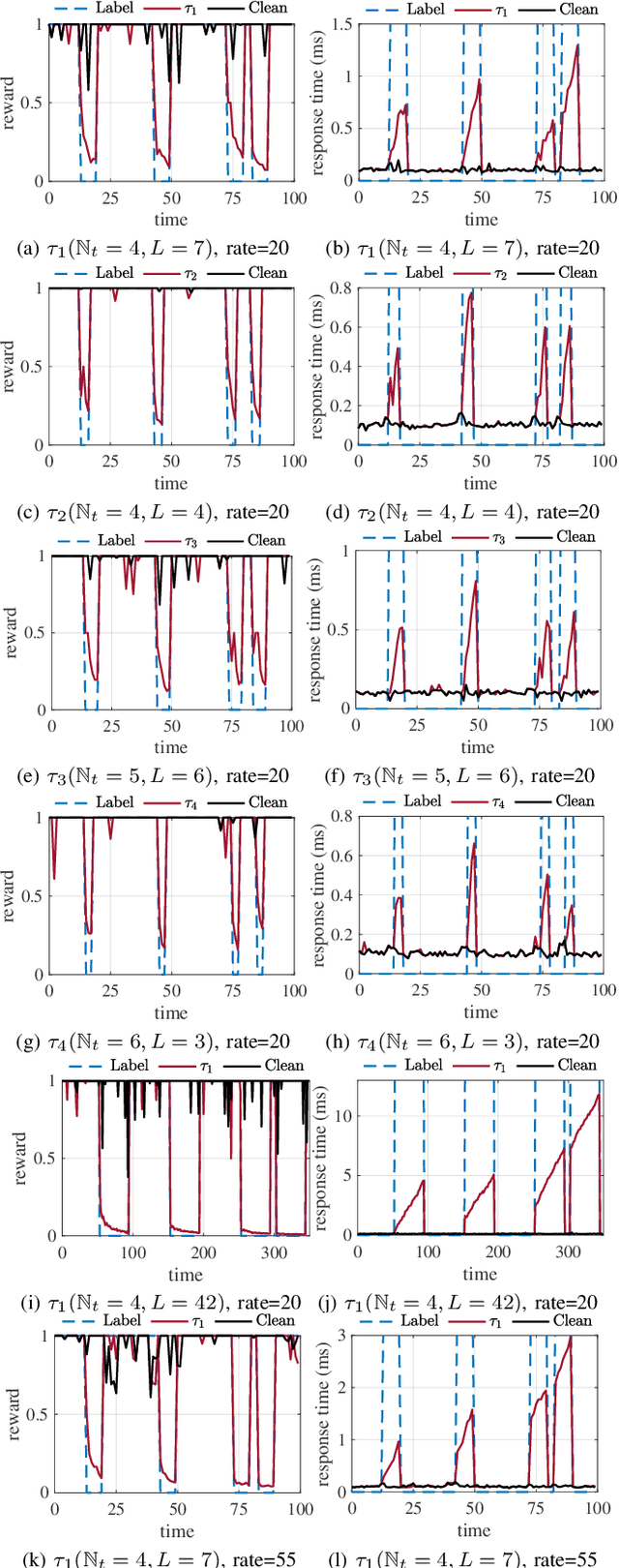
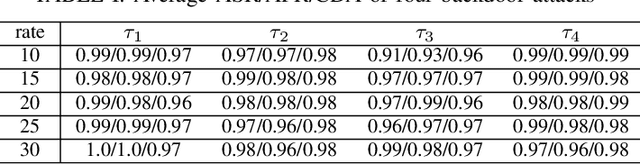
Deep reinforcement learning (DRL) has made significant achievements in many real-world applications. But these real-world applications typically can only provide partial observations for making decisions due to occlusions and noisy sensors. However, partial state observability can be used to hide malicious behaviors for backdoors. In this paper, we explore the sequential nature of DRL and propose a novel temporal-pattern backdoor attack to DRL, whose trigger is a set of temporal constraints on a sequence of observations rather than a single observation, and effect can be kept in a controllable duration rather than in the instant. We validate our proposed backdoor attack to a typical job scheduling task in cloud computing. Numerous experimental results show that our backdoor can achieve excellent effectiveness, stealthiness, and sustainability. Our backdoor's average clean data accuracy and attack success rate can reach 97.8% and 97.5%, respectively.