 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image analysis for automatic measurement of crustose lichens
Mar 01, 2022
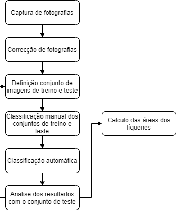
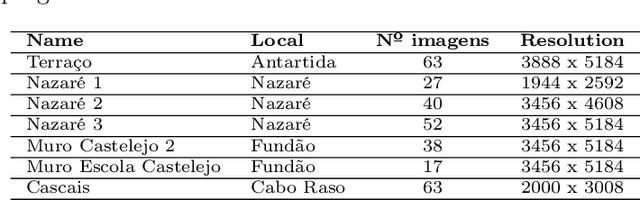


Lichens, organisms resulting from a symbiosis between a fungus and an algae, are frequently used as age estimators, especially in recent geological deposits and archaeological structures, using the correlation between lichen size and age. Current non-automated manual lichen and measurement (with ruler, calipers or using digital image processing tools) is a time-consuming and laborious process, especially when the number of samples is high. This work presents a workflow and set of image acquisition and processing tools developed to efficiently identify lichen thalli in flat rocky surfaces, and to produce relevant lichen size statistics (percentage cover, number of thalli, their area and perimeter). The developed workflow uses a regular digital camera for image capture along with specially designed targets to allow for automatic image correction and scale assignment. After this step, lichen identification is done in a flow comprising assisted image segmentation and classification based on interactive foreground extraction tool (GrabCut) and automatic classification of images using Simple Linear Iterative Clustering (SLIC) for image segmentation and Support Vector Machines (SV) and Random Forest classifiers. Initial evaluation shows promising results. The manual classification of images (for training) using GrabCut show an average speedup of 4 if compared with currently used techniques and presents an average precision of 95\%. The automatic classification using SLIC and SVM with default parameters produces results with average precision higher than 70\%. The developed system is flexible and allows a considerable reduction of processing time, the workflow allows it applicability to data sets of new lichen populations.
Improving the Robustness of Neural Multiplication Units with Reversible Stochasticity
Nov 10, 2022
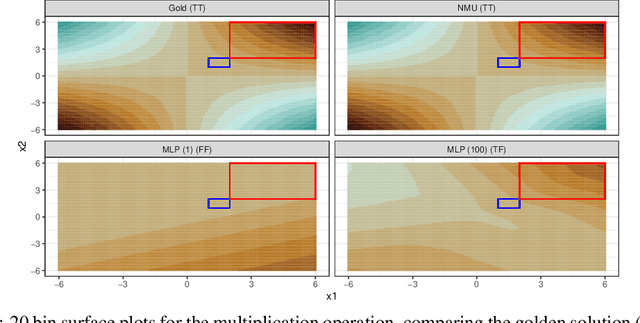

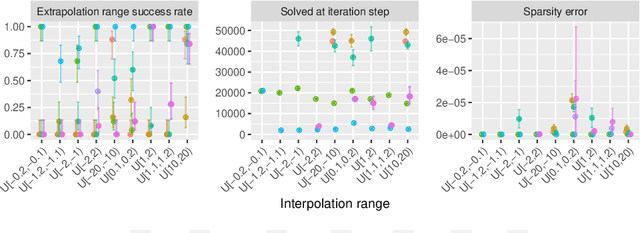
Multilayer Perceptrons struggle to learn certain simple arithmetic tasks. Specialist neural modules for arithmetic can outperform classical architectures with gains in extrapolation, interpretability and convergence speeds, but are highly sensitive to the training range. In this paper, we show that Neural Multiplication Units (NMUs) are unable to reliably learn tasks as simple as multiplying two inputs when given different training ranges. Causes of failure are linked to inductive and input biases which encourage convergence to solutions in undesirable optima. A solution, the stochastic NMU (sNMU), is proposed to apply reversible stochasticity, encouraging avoidance of such optima whilst converging to the true solution. Empirically, we show that stochasticity provides improved robustness with the potential to improve learned representations of upstream networks for numerical and image tasks.
One-shot Detail Retouching with Patch Space Neural Field based Transformation Blending
Oct 03, 2022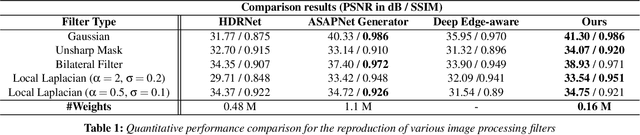
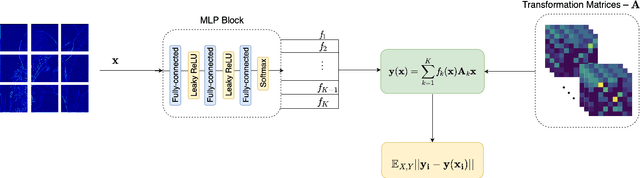

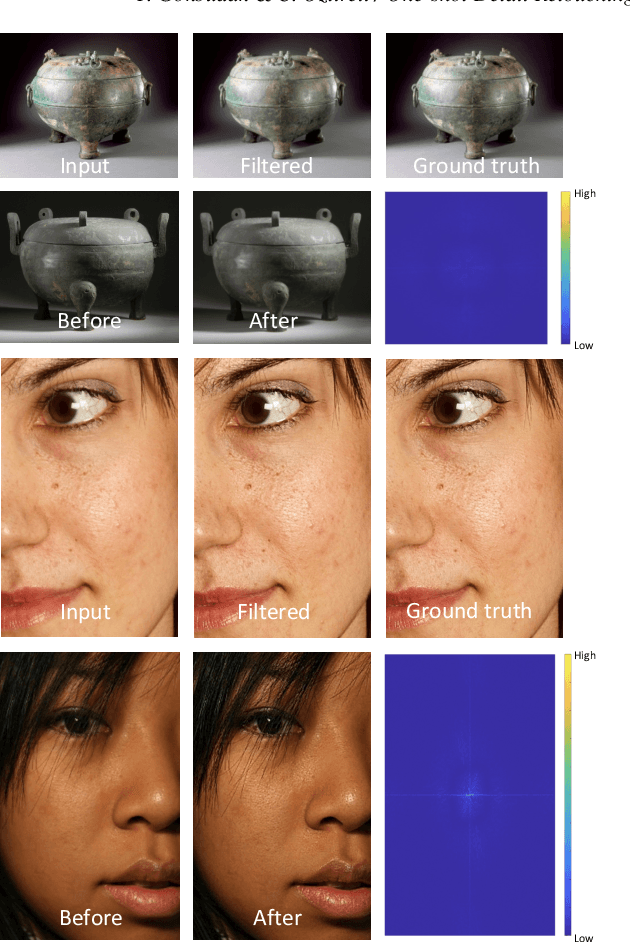
Photo retouching is a difficult task for novice users as it requires expert knowledge and advanced tools. Photographers often spend a great deal of time generating high-quality retouched photos with intricate details. In this paper, we introduce a one-shot learning based technique to automatically retouch details of an input image based on just a single pair of before and after example images. Our approach provides accurate and generalizable detail edit transfer to new images. We achieve these by proposing a new representation for image to image maps. Specifically, we propose neural field based transformation blending in the patch space for defining patch to patch transformations for each frequency band. This parametrization of the map with anchor transformations and associated weights, and spatio-spectral localized patches, allows us to capture details well while staying generalizable. We evaluate our technique both on known ground truth filtes and artist retouching edits. Our method accurately transfers complex detail retouching edits.
A Smart Recycling Bin Using Waste Image Classification At The Edge
Oct 02, 2022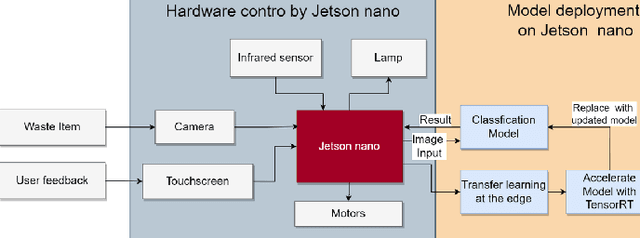
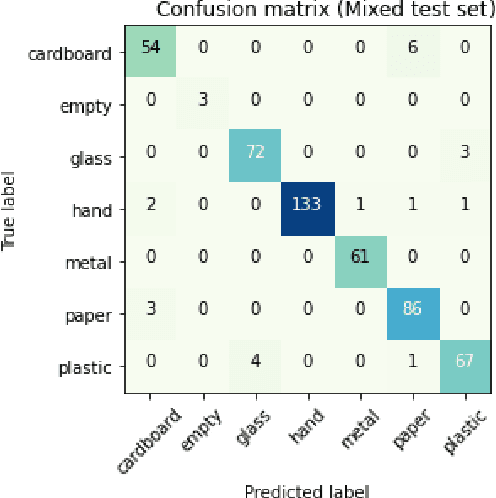
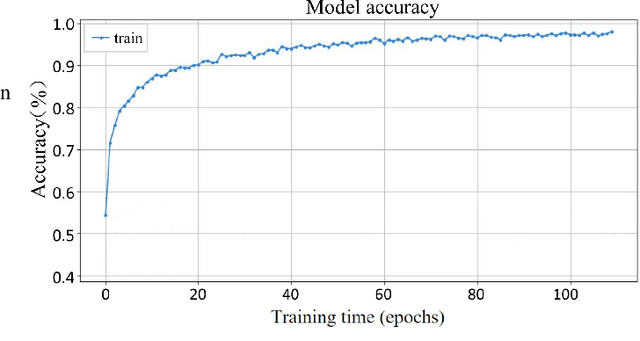
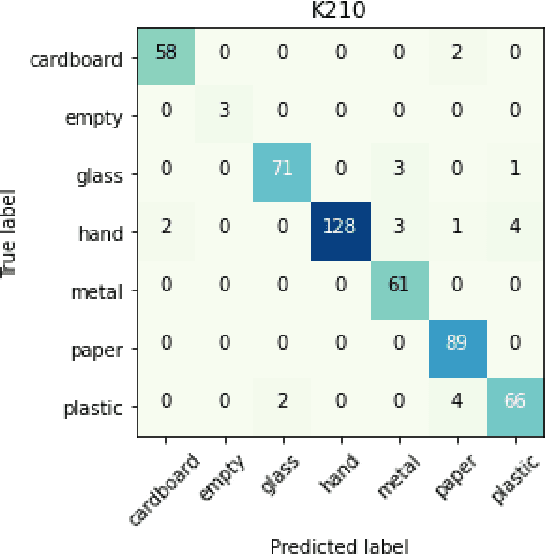
Rapid economic growth gives rise to the urgent demand for a more efficient waste recycling system. This work thereby developed an innovative recycling bin that automatically separates urban waste to increase the recycling rate. We collected 1800 recycling waste images and combined them with an existing public dataset to train classification models for two embedded systems, Jetson Nano and K210, targeting different markets. The model reached an accuracy of 95.98% on Jetson Nano and 96.64% on K210. A bin program was designed to collect feedback from users. On Jetson Nano, the overall power consumption of the application was reduced by 30% from the previous work to 4.7 W, while the second system, K210, only needed 0.89 W of power to operate. In summary, our work demonstrated a fully functional prototype of an energy-saving, high-accuracy smart recycling bin, which can be commercialized in the future to improve urban waste recycling.
Name Your Style: An Arbitrary Artist-aware Image Style Transfer
Mar 05, 2022
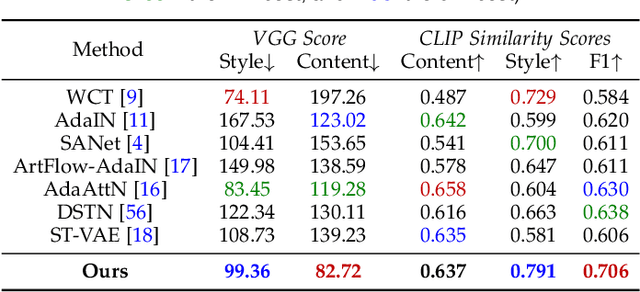
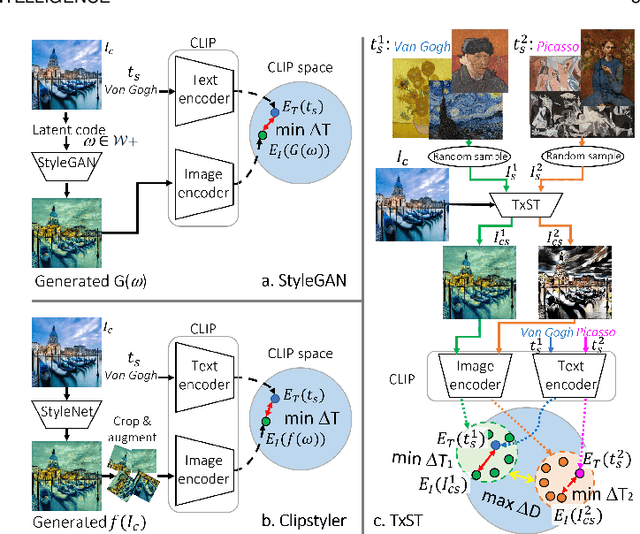
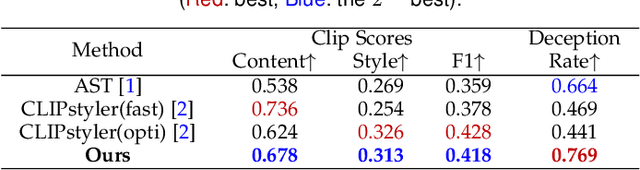
Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a text-driven image style transfer (TxST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient attention module that explores cross-attentions to fuse style and content features. Finally, we achieve an arbitrary artist-aware image style transfer to learn and transfer specific artistic characters such as Picasso, oil painting, or a rough sketch. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods on both image and textual styles. Moreover, it can mimic the styles of one or many artists to achieve attractive results, thus highlighting a promising direction in image style transfer.
ImaginaryNet: Learning Object Detectors without Real Images and Annotations
Oct 13, 2022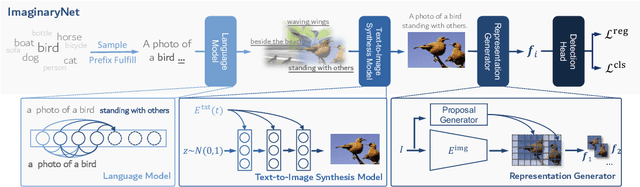
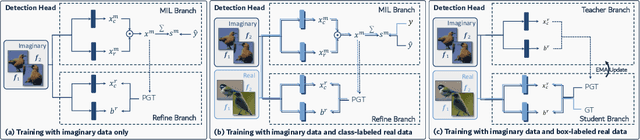

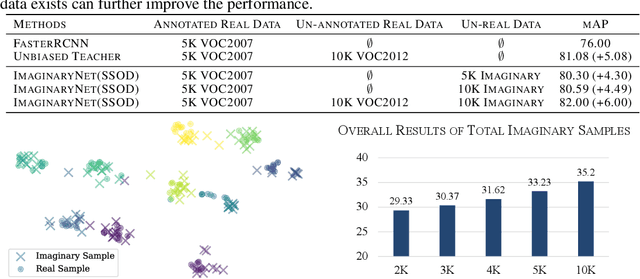
Without the demand of training in reality, humans can easily detect a known concept simply based on its language description. Empowering deep learning with this ability undoubtedly enables the neural network to handle complex vision tasks, e.g., object detection, without collecting and annotating real images. To this end, this paper introduces a novel challenging learning paradigm Imaginary-Supervised Object Detection (ISOD), where neither real images nor manual annotations are allowed for training object detectors. To resolve this challenge, we propose ImaginaryNet, a framework to synthesize images by combining pretrained language model and text-to-image synthesis model. Given a class label, the language model is used to generate a full description of a scene with a target object, and the text-to-image model deployed to generate a photo-realistic image. With the synthesized images and class labels, weakly supervised object detection can then be leveraged to accomplish ISOD. By gradually introducing real images and manual annotations, ImaginaryNet can collaborate with other supervision settings to further boost detection performance. Experiments show that ImaginaryNet can (i) obtain about 70% performance in ISOD compared with the weakly supervised counterpart of the same backbone trained on real data, (ii) significantly improve the baseline while achieving state-of-the-art or comparable performance by incorporating ImaginaryNet with other supervision settings.
What's in a Decade? Transforming Faces Through Time
Oct 17, 2022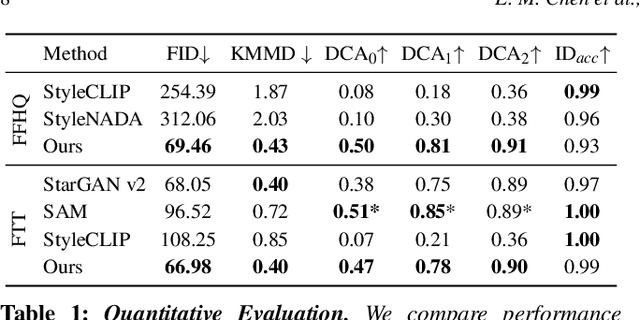

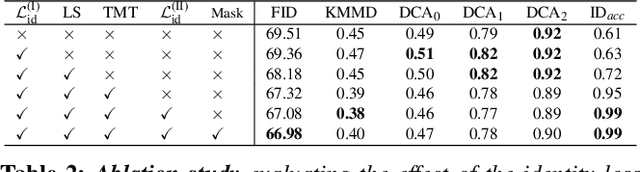
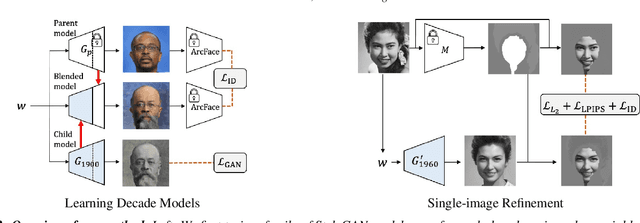
How can one visually characterize people in a decade? In this work, we assemble the Faces Through Time dataset, which contains over a thousand portrait images from each decade, spanning the 1880s to the present day. Using our new dataset, we present a framework for resynthesizing portrait images across time, imagining how a portrait taken during a particular decade might have looked like, had it been taken in other decades. Our framework optimizes a family of per-decade generators that reveal subtle changes that differentiate decade--such as different hairstyles or makeup--while maintaining the identity of the input portrait. Experiments show that our method is more effective in resynthesizing portraits across time compared to state-of-the-art image-to-image translation methods, as well as attribute-based and language-guided portrait editing models. Our code and data will be available at https://facesthroughtime.github.io
Identity Preserving Loss for Learned Image Compression
Apr 27, 2022

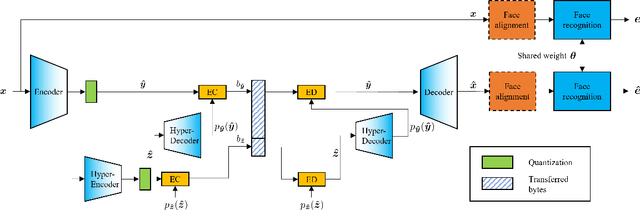

Deep learning model inference on embedded devices is challenging due to the limited availability of computation resources. A popular alternative is to perform model inference on the cloud, which requires transmitting images from the embedded device to the cloud. Image compression techniques are commonly employed in such cloud-based architectures to reduce transmission latency over low bandwidth networks. This work proposes an end-to-end image compression framework that learns domain-specific features to achieve higher compression ratios than standard HEVC/JPEG compression techniques while maintaining accuracy on downstream tasks (e.g., recognition). Our framework does not require fine-tuning of the downstream task, which allows us to drop-in any off-the-shelf downstream task model without retraining. We choose faces as an application domain due to the ready availability of datasets and off-the-shelf recognition models as representative downstream tasks. We present a novel Identity Preserving Reconstruction (IPR) loss function which achieves Bits-Per-Pixel (BPP) values that are ~38% and ~42% of CRF-23 HEVC compression for LFW (low-resolution) and CelebA-HQ (high-resolution) datasets, respectively, while maintaining parity in recognition accuracy. The superior compression ratio is achieved as the model learns to retain the domain-specific features (e.g., facial features) while sacrificing details in the background. Furthermore, images reconstructed by our proposed compression model are robust to changes in downstream model architectures. We show at-par recognition performance on the LFW dataset with an unseen recognition model while retaining a lower BPP value of ~38% of CRF-23 HEVC compression.
RUST: Latent Neural Scene Representations from Unposed Imagery
Nov 25, 2022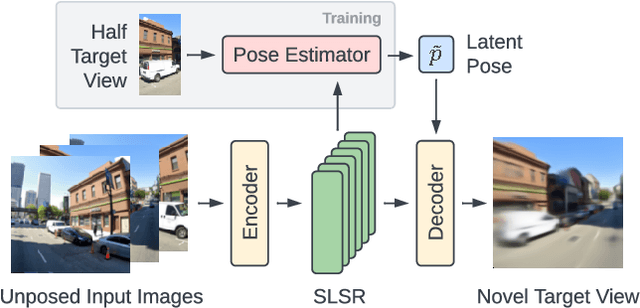
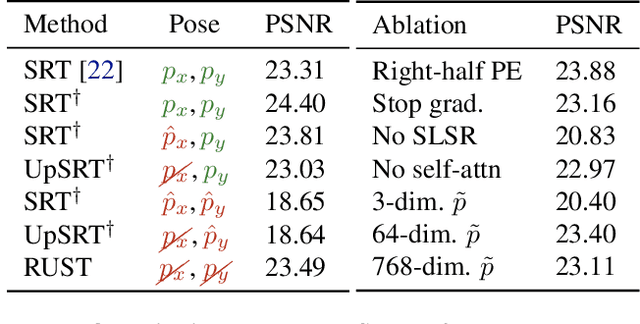
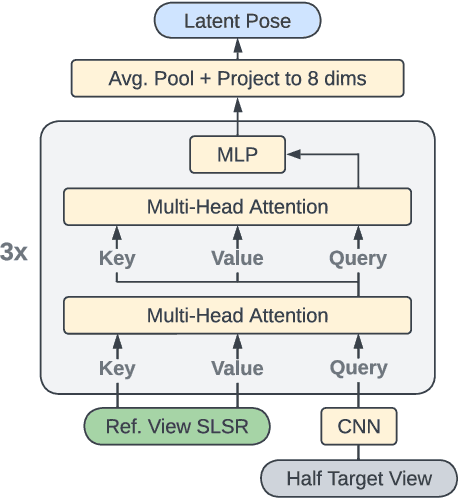
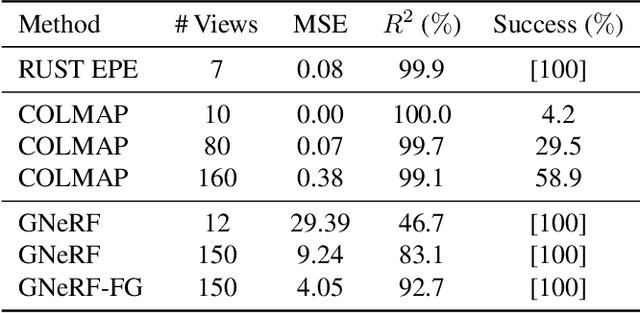
Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations.
EBHI:A New Enteroscope Biopsy Histopathological H&E Image Dataset for Image Classification Evaluation
Feb 17, 2022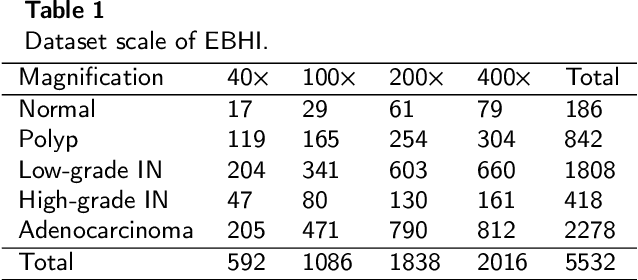
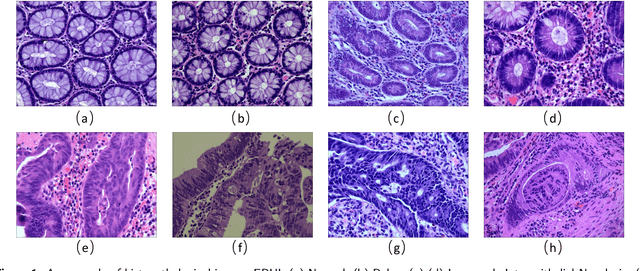
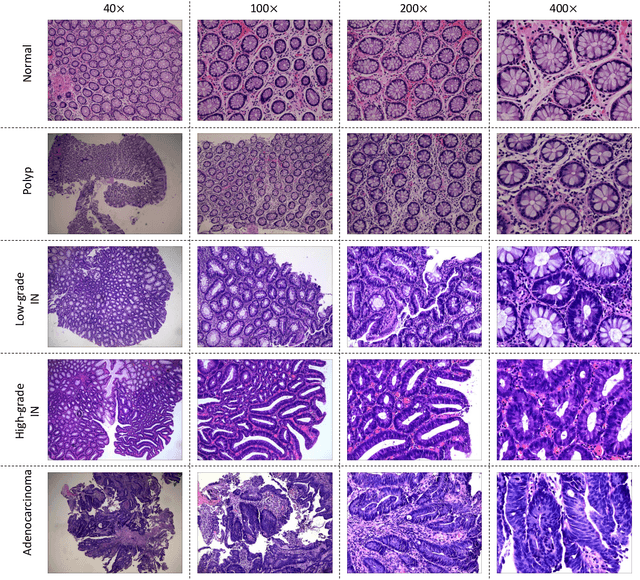
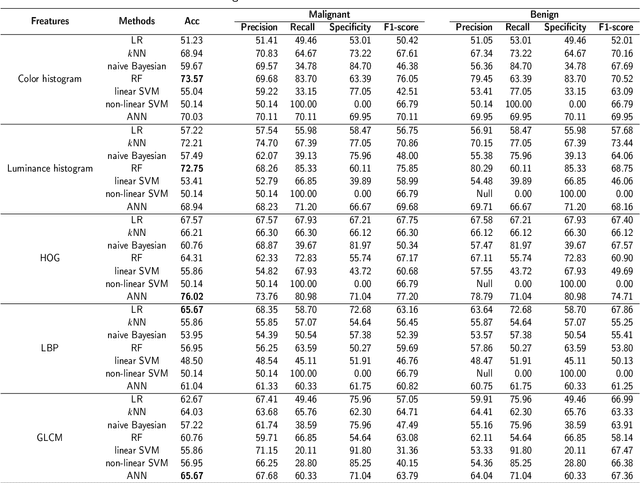
Background and purpose: Colorectal cancer has become the third most common cancer worldwide, accounting for approximately 10% of cancer patients. Early detection of the disease is important for the treatment of colorectal cancer patients. Histopathological examination is the gold standard for screening colorectal cancer. However, the current lack of histopathological image datasets of colorectal cancer, especially enteroscope biopsies, hinders the accurate evaluation of computer-aided diagnosis techniques. Methods: A new publicly available Enteroscope Biopsy Histopathological H&E Image Dataset (EBHI) is published in this paper. To demonstrate the effectiveness of the EBHI dataset, we have utilized several machine learning, convolutional neural networks and novel transformer-based classifiers for experimentation and evaluation, using an image with a magnification of 200x. Results: Experimental results show that the deep learning method performs well on the EBHI dataset. Traditional machine learning methods achieve maximum accuracy of 76.02% and deep learning method achieves a maximum accuracy of 95.37%. Conclusion: To the best of our knowledge, EBHI is the first publicly available colorectal histopathology enteroscope biopsy dataset with four magnifications and five types of images of tumor differentiation stages, totaling 5532 images. We believe that EBHI could attract researchers to explore new classification algorithms for the automated diagnosis of colorectal cancer, which could help physicians and patients in clinical settings.