 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing remotely sensed data for air pollution assessment
Feb 04, 2024Air pollution constitutes a global problem of paramount importance that affects not only human health, but also the environment. The existence of spatial and temporal data regarding the concentrations of pollutants is crucial for performing air pollution studies and monitor emissions. However, although observation data presents great temporal coverage, the number of stations is very limited and they are usually built in more populated areas. The main objective of this work is to create models capable of inferring pollutant concentrations in locations where no observation data exists. A machine learning model, more specifically the random forest model, was developed for predicting concentrations in the Iberian Peninsula in 2019 for five selected pollutants: $NO_2$, $O_3$ $SO_2$, $PM10$, and $PM2.5$. Model features include satellite measurements, meteorological variables, land use classification, temporal variables (month, day of year), and spatial variables (latitude, longitude, altitude). The models were evaluated using various methods, including station 10-fold cross-validation, in which in each fold observations from 10\% of the stations are used as testing data and the rest as training data. The $R^2$, RMSE and mean bias were determined for each model. The $NO_2$ and $O_3$ models presented good values of $R^2$, 0.5524 and 0.7462, respectively. However, the $SO_2$, $PM10$, and $PM2.5$ models performed very poorly in this regard, with $R^2$ values of -0.0231, 0.3722, and 0.3303, respectively. All models slightly overestimated the ground concentrations, except the $O_3$ model. All models presented acceptable cross-validation RMSE, except the $O_3$ and $PM10$ models where the mean value was a little higher (12.5934 $\mu g/m^3$ and 10.4737 $\mu g/m^3$, respectively).
LiDAR data acquisition and processing for ecology applications
Jan 11, 2024



The collection of ecological data in the field is essential to diagnose, monitor and manage ecosystems in a sustainable way. Since acquisition of this information through traditional methods are generally time-consuming, due to the capability of recording large volumes of data in short time periods, automation of data acquisition sees a growing trend. Terrestrial laser scanners (TLS), particularly LiDAR sensors, have been used in ecology, allowing to reconstruct the 3D structure of vegetation, and thus, infer ecosystem characteristics based on the spatial variation of the density of points. However, the low amount of information obtained per beam, lack of data analysis tools and the high cost of the equipment limit their use. This way, a low-cost TLS (<10k$) was developed along with data acquisition and processing mechanisms applicable in two case studies: an urban garden and a target area for ecological restoration. The orientation of LiDAR was modified to make observations in the vertical plane and a motor was integrated for its rotation, enabling the acquisition of 360 degree data with high resolution. Motion and location sensors were also integrated for automatic error correction and georeferencing. From the data generated, histograms of point density variation along the vegetation height were created, where shrub stratum was easily distinguishable from tree stratum, and maximum tree height and shrub cover were calculated. These results agreed with the field data, whereby the developed TLS has proved to be effective in calculating metrics of structural complexity of vegetation.
Image analysis for automatic measurement of crustose lichens
Mar 01, 2022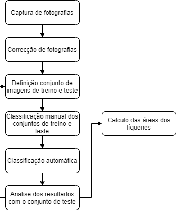
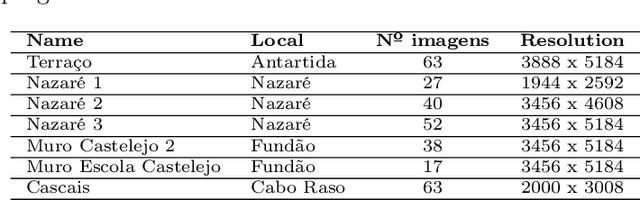


Lichens, organisms resulting from a symbiosis between a fungus and an algae, are frequently used as age estimators, especially in recent geological deposits and archaeological structures, using the correlation between lichen size and age. Current non-automated manual lichen and measurement (with ruler, calipers or using digital image processing tools) is a time-consuming and laborious process, especially when the number of samples is high. This work presents a workflow and set of image acquisition and processing tools developed to efficiently identify lichen thalli in flat rocky surfaces, and to produce relevant lichen size statistics (percentage cover, number of thalli, their area and perimeter). The developed workflow uses a regular digital camera for image capture along with specially designed targets to allow for automatic image correction and scale assignment. After this step, lichen identification is done in a flow comprising assisted image segmentation and classification based on interactive foreground extraction tool (GrabCut) and automatic classification of images using Simple Linear Iterative Clustering (SLIC) for image segmentation and Support Vector Machines (SV) and Random Forest classifiers. Initial evaluation shows promising results. The manual classification of images (for training) using GrabCut show an average speedup of 4 if compared with currently used techniques and presents an average precision of 95\%. The automatic classification using SLIC and SVM with default parameters produces results with average precision higher than 70\%. The developed system is flexible and allows a considerable reduction of processing time, the workflow allows it applicability to data sets of new lichen populations.