 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Task Bias in Vision-Language Models
Dec 08, 2022
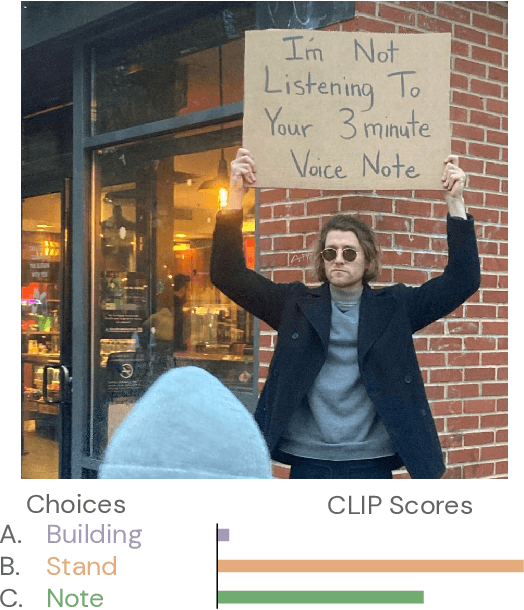
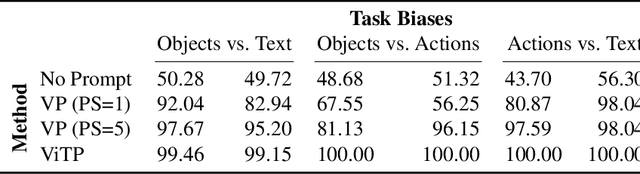
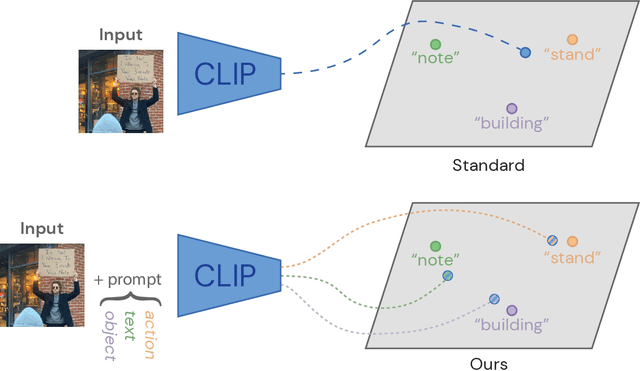
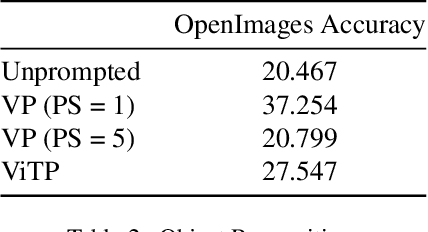
Incidental supervision from language has become a popular approach for learning generic visual representations that can be prompted to perform many recognition tasks in computer vision. We conduct an in-depth exploration of the CLIP model and show that its visual representation is often strongly biased towards solving some tasks more than others. Moreover, which task the representation will be biased towards is unpredictable, with little consistency across images. To resolve this task bias, we show how to learn a visual prompt that guides the representation towards features relevant to their task of interest. Our results show that these visual prompts can be independent of the input image and still effectively provide a conditioning mechanism to steer visual representations towards the desired task.
On the Benefit of Dual-domain Denoising in a Self-supervised Low-dose CT Setting
Nov 03, 2022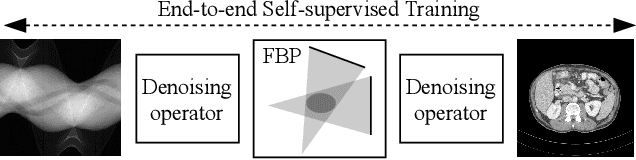
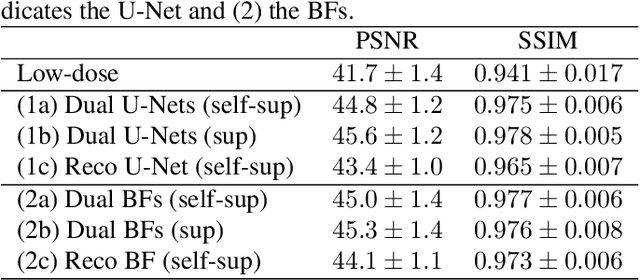
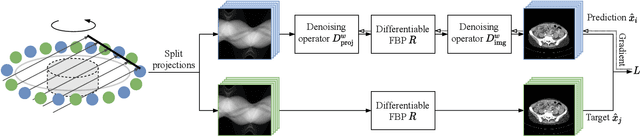
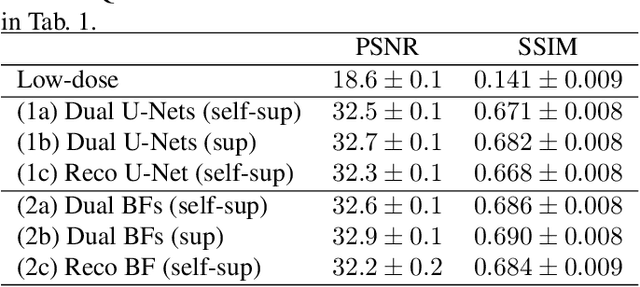
Computed tomography (CT) is routinely used for three-dimensional non-invasive imaging. Numerous data-driven image denoising algorithms were proposed to restore image quality in low-dose acquisitions. However, considerably less research investigates methods already intervening in the raw detector data due to limited access to suitable projection data or correct reconstruction algorithms. In this work, we present an end-to-end trainable CT reconstruction pipeline that contains denoising operators in both the projection and the image domain and that are optimized simultaneously without requiring ground-truth high-dose CT data. Our experiments demonstrate that including an additional projection denoising operator improved the overall denoising performance by 82.4-94.1%/12.5-41.7% (PSNR/SSIM) on abdomen CT and 1.5-2.9%/0.4-0.5% (PSNR/SSIM) on XRM data relative to the low-dose baseline. We make our entire helical CT reconstruction framework publicly available that contains a raw projection rebinning step to render helical projection data suitable for differentiable fan-beam reconstruction operators and end-to-end learning.
Mushroom image recognition and distance generation based on attention-mechanism model and genetic information
Jun 27, 2022
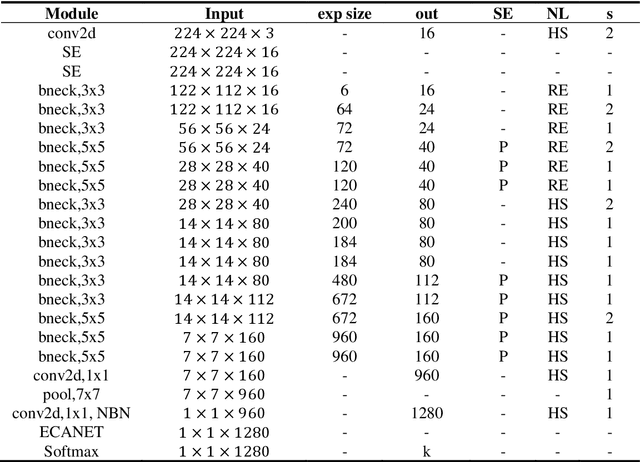

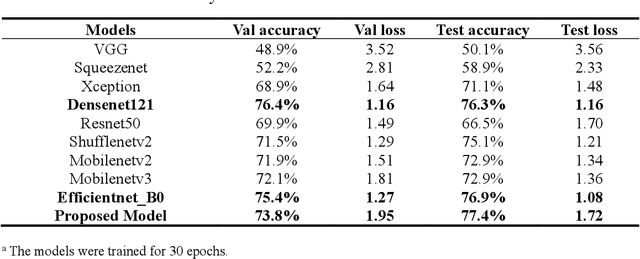
The species identification of Macrofungi, i.e. mushrooms, has always been a challenging task. There are still a large number of poisonous mushrooms that have not been found, which poses a risk to people's life. However, the traditional identification method requires a large number of experts with knowledge in the field of taxonomy for manual identification, it is not only inefficient but also consumes a lot of manpower and capital costs. In this paper, we propose a new model based on attention-mechanism, MushroomNet, which applies the lightweight network MobileNetV3 as the backbone model, combined with the attention structure proposed by us, and has achieved excellent performance in the mushroom recognition task. On the public dataset, the test accuracy of the MushroomNet model has reached 83.9%, and on the local dataset, the test accuracy has reached 77.4%. The proposed attention mechanisms well focused attention on the bodies of mushroom image for mixed channel attention and the attention heat maps visualized by Grad-CAM. Further, in this study, genetic distance was added to the mushroom image recognition task, the genetic distance was used as the representation space, and the genetic distance between each pair of mushroom species in the dataset was used as the embedding of the genetic distance representation space, so as to predict the image distance and species. identify. We found that using the MES activation function can predict the genetic distance of mushrooms very well, but the accuracy is lower than that of SoftMax. The proposed MushroomNet was demonstrated it shows great potential for automatic and online mushroom image and the proposed automatic procedure would assist and be a reference to traditional mushroom classification.
Sub-Image Histogram Equalization using Coot Optimization Algorithm for Segmentation and Parameter Selection
May 31, 2022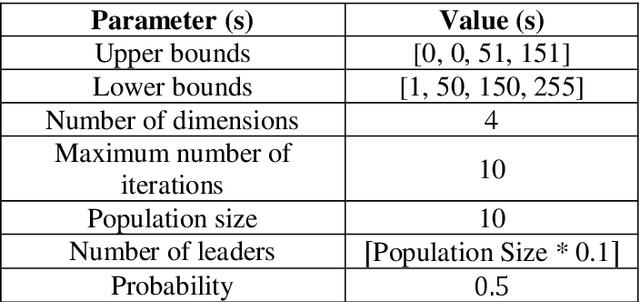

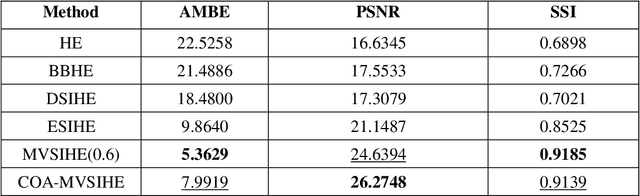
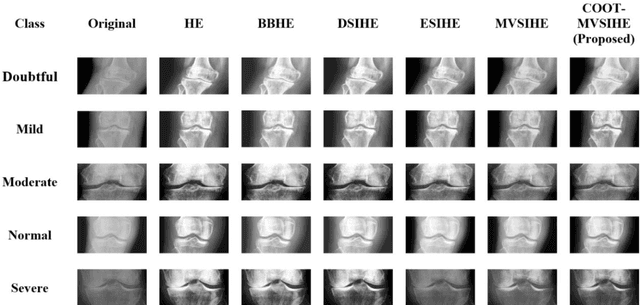
Contrast enhancement is very important in terms of assessing images in an objective way. Contrast enhancement is also significant for various algorithms including supervised and unsupervised algorithms for accurate classification of samples. Some contrast enhancement algorithms solve this problem by addressing the low contrast issue. Mean and variance based sub-image histogram equalization (MVSIHE) algorithm is one of these contrast enhancements methods proposed in the literature. It has different parameters which need to be tuned in order to achieve optimum results. With this motivation, in this study, we employed one of the most recent optimization algorithms, namely, coot optimization algorithm (COA) for selecting appropriate parameters for the MVSIHE algorithm. Blind/referenceless image spatial quality evaluator (BRISQUE) and natural image quality evaluator (NIQE) metrics are used for evaluating fitness of the coot swarm population. The results show that the proposed method can be used in the field of biomedical image processing.
Multi-frequency PolSAR Image Fusion Classification Based on Semantic Interactive Information and Topological Structure
Sep 05, 2022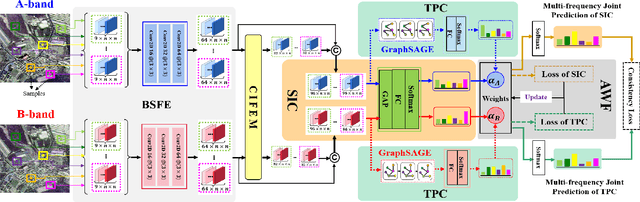
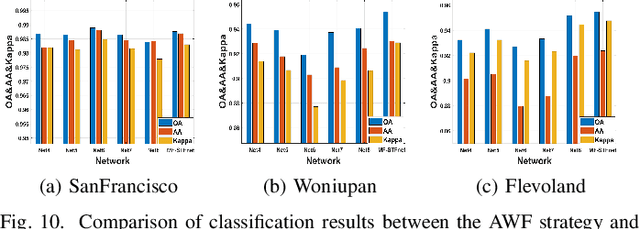
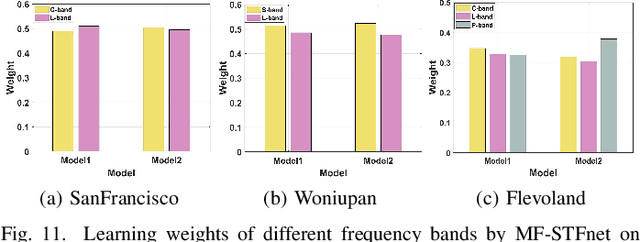
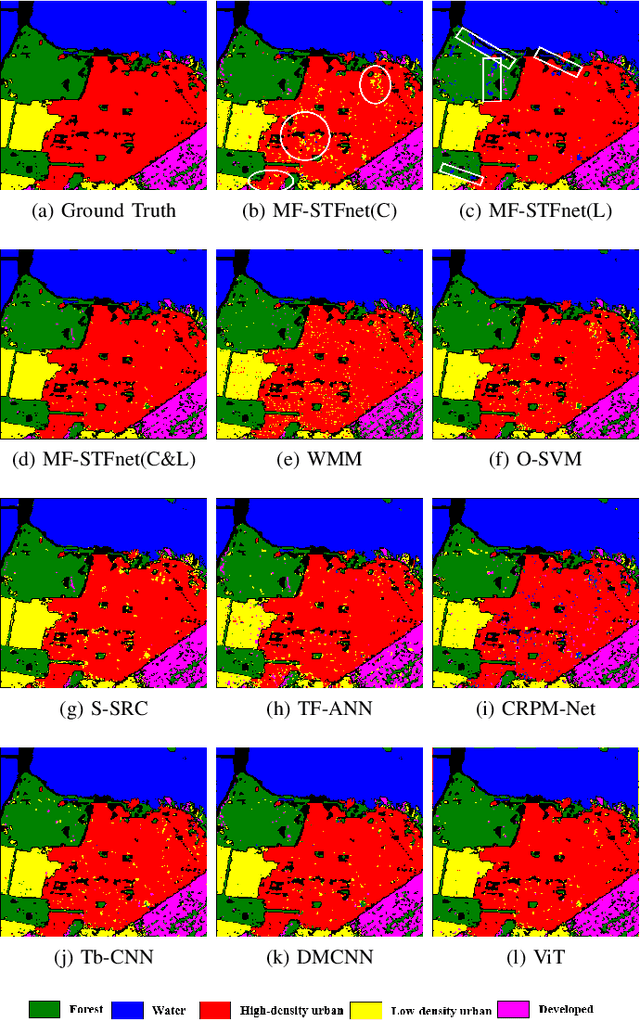
Compared with the rapid development of single-frequency multi-polarization SAR image classification technology, there is less research on the land cover classification of multifrequency polarimetric SAR (MF-PolSAR) images. In addition, the current deep learning methods for MF-PolSAR classification are mainly based on convolutional neural networks (CNNs), only local spatiality is considered but the nonlocal relationship is ignored. Therefore, based on semantic interaction and nonlocal topological structure, this paper proposes the MF semantics and topology fusion network (MF-STFnet) to improve MF-PolSAR classification performance. In MF-STFnet, two kinds of classification are implemented for each band, semantic information-based (SIC) and topological property-based (TPC). They work collaboratively during MF-STFnet training, which can not only fully leverage the complementarity of bands, but also combine local and nonlocal spatial information to improve the discrimination between different categories. For SIC, the designed crossband interactive feature extraction module (CIFEM) is embedded to explicitly model the deep semantic correlation among bands, thereby leveraging the complementarity of bands to make ground objects more separable. For TPC, the graph sample and aggregate network (GraphSAGE) is employed to dynamically capture the representation of nonlocal topological relations between land cover categories. In this way, the robustness of classification can be further improved by combining nonlocal spatial information. Finally, an adaptive weighting fusion (AWF) strategy is proposed to merge inference from different bands, so as to make the MF joint classification decisions of SIC and TPC. The comparative experiments show that MF-STFnet can achieve more competitive classification performance than some state-of-the-art methods.
Deep Learning-Based Attenuation and Scatter Correction of Brain 18F-FDG PET Images in the Image Domain
Jun 29, 2022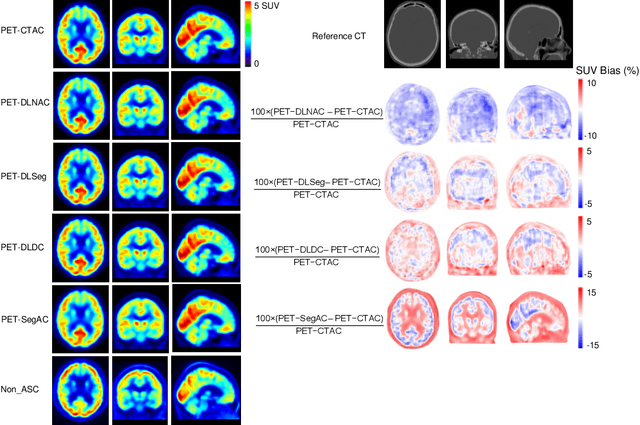
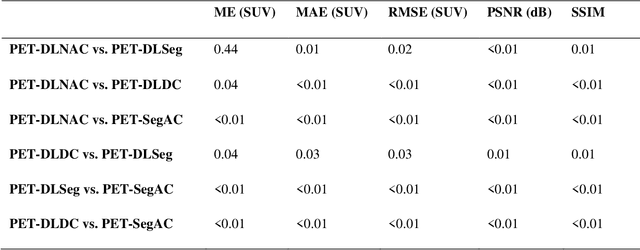
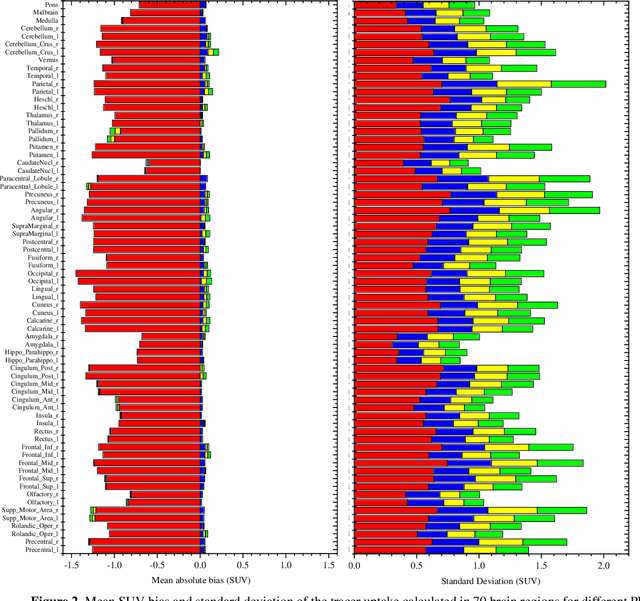
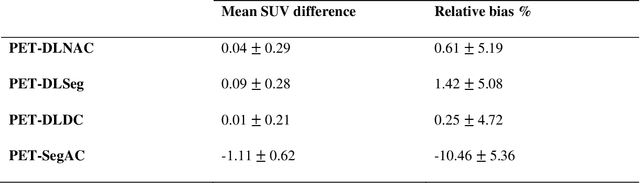
Attenuation and scatter correction (AC) is crucial for quantitative Positron Emission Tomography (PET) imaging. Recently, direct application of AC in the image domain using deep learning approaches has been proposed for the hybrid PET/MR and dedicated PET systems that lack accompanying transmission or anatomical imaging. This study set out to investigate deep learning-based AC in the image domain using different input settings.
Dunhuang murals contour generation network based on convolution and self-attention fusion
Dec 02, 2022
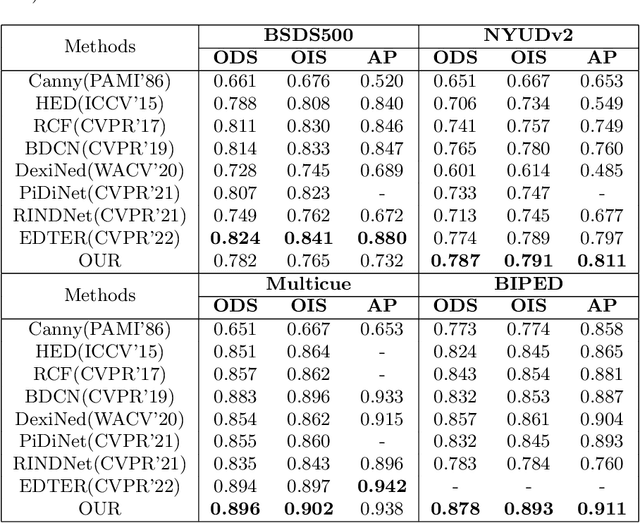
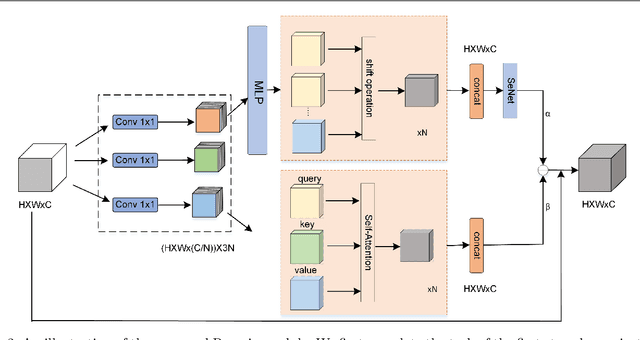
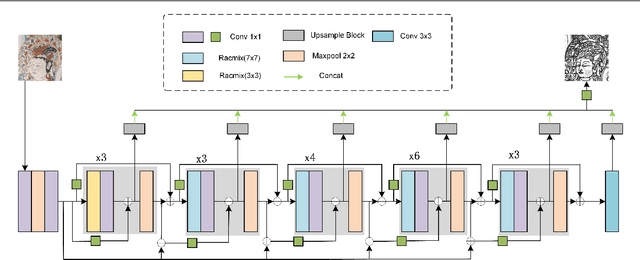
Dunhuang murals are a collection of Chinese style and national style, forming a self-contained Chinese-style Buddhist art. It has very high historical and cultural value and research significance. Among them, the lines of Dunhuang murals are highly general and expressive. It reflects the character's distinctive character and complex inner emotions. Therefore, the outline drawing of murals is of great significance to the research of Dunhuang Culture. The contour generation of Dunhuang murals belongs to image edge detection, which is an important branch of computer vision, aims to extract salient contour information in images. Although convolution-based deep learning networks have achieved good results in image edge extraction by exploring the contextual and semantic features of images. However, with the enlargement of the receptive field, some local detail information is lost. This makes it impossible for them to generate reasonable outline drawings of murals. In this paper, we propose a novel edge detector based on self-attention combined with convolution to generate line drawings of Dunhuang murals. Compared with existing edge detection methods, firstly, a new residual self-attention and convolution mixed module (Ramix) is proposed to fuse local and global features in feature maps. Secondly, a novel densely connected backbone extraction network is designed to efficiently propagate rich edge feature information from shallow layers into deep layers. Compared with existing methods, it is shown on different public datasets that our method is able to generate sharper and richer edge maps. In addition, testing on the Dunhuang mural dataset shows that our method can achieve very competitive performance.
Generative Adversarial Networks for Image Super-Resolution: A Survey
Apr 28, 2022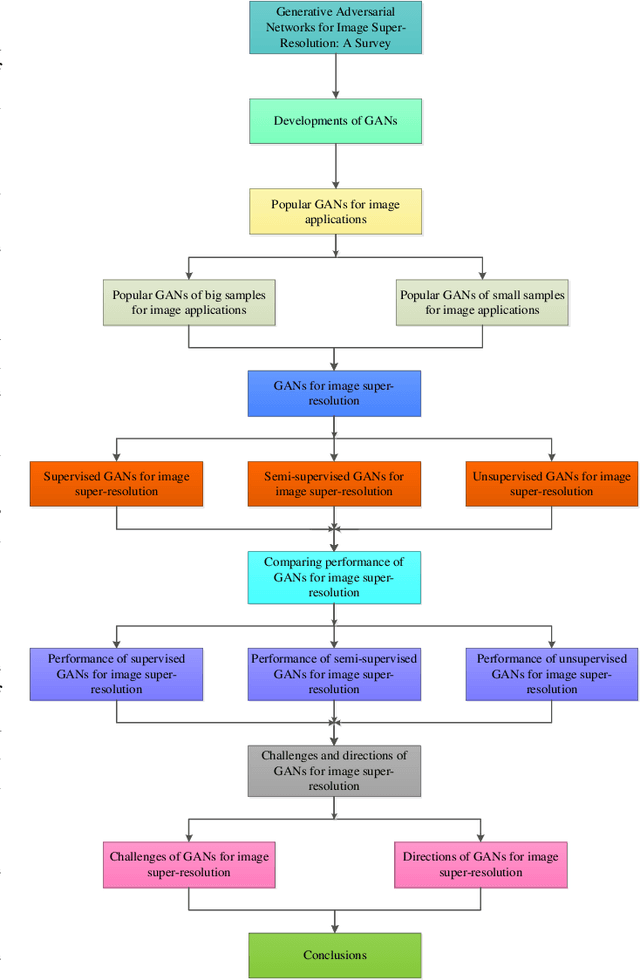
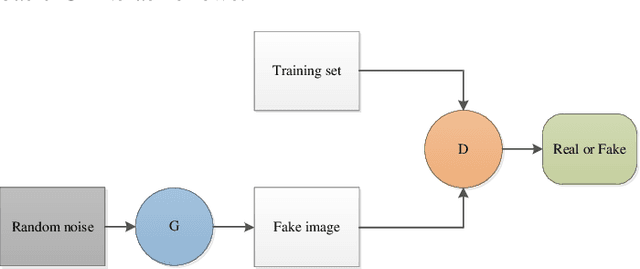
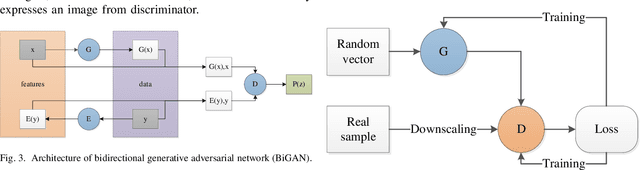
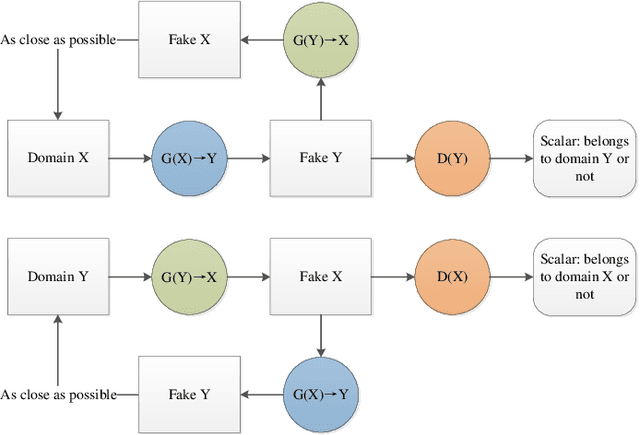
Single image super-resolution (SISR) has played an important role in the field of image processing. Recent generative adversarial networks (GANs) can achieve excellent results on low-resolution images with small samples. However, there are little literatures summarizing different GANs in SISR. In this paper, we conduct a comparative study of GANs from different perspectives. We first take a look at developments of GANs. Second, we present popular architectures for GANs in big and small samples for image applications. Then, we analyze motivations, implementations and differences of GANs based optimization methods and discriminative learning for image super-resolution in terms of supervised, semi-supervised and unsupervised manners. Next, we compare performance of these popular GANs on public datasets via quantitative and qualitative analysis in SISR. Finally, we highlight challenges of GANs and potential research points for SISR.
Reversible Column Networks
Dec 22, 2022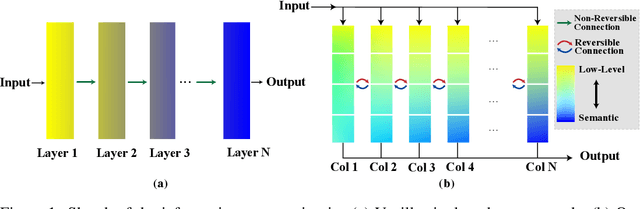
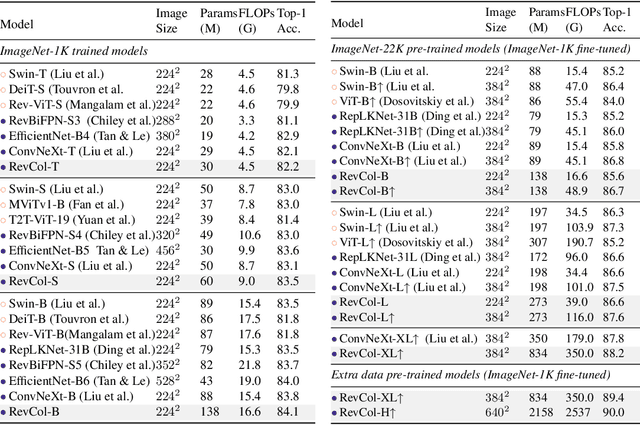
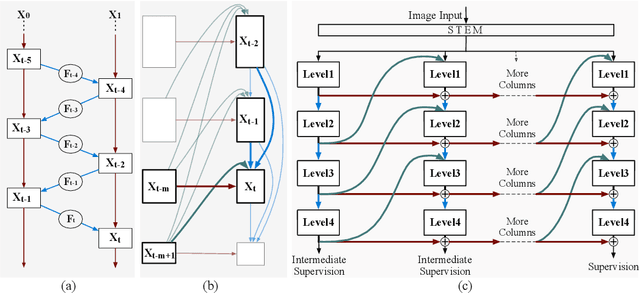
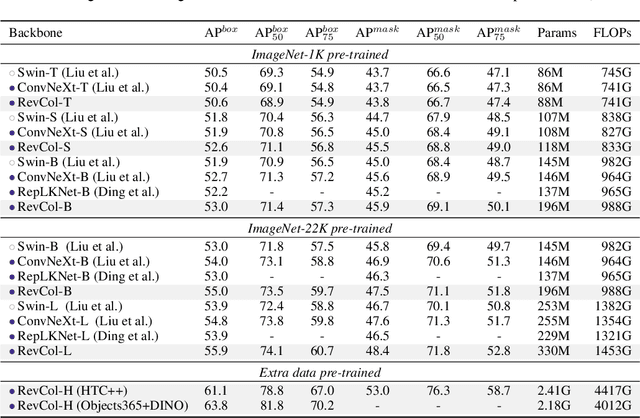
We propose a new neural network design paradigm Reversible Column Network (RevCol). The main body of RevCol is composed of multiple copies of subnetworks, named columns respectively, between which multi-level reversible connections are employed. Such architectural scheme attributes RevCol very different behavior from conventional networks: during forward propagation, features in RevCol are learned to be gradually disentangled when passing through each column, whose total information is maintained rather than compressed or discarded as other network does. Our experiments suggest that CNN-style RevCol models can achieve very competitive performances on multiple computer vision tasks such as image classification, object detection and semantic segmentation, especially with large parameter budget and large dataset. For example, after ImageNet-22K pre-training, RevCol-XL obtains 88.2% ImageNet-1K accuracy. Given more pre-training data, our largest model RevCol-H reaches 90.0% on ImageNet-1K, 63.8% APbox on COCO detection minival set, 61.0% mIoU on ADE20k segmentation. To our knowledge, it is the best COCO detection and ADE20k segmentation result among pure (static) CNN models. Moreover, as a general macro architecture fashion, RevCol can also be introduced into transformers or other neural networks, which is demonstrated to improve the performances in both computer vision and NLP tasks. We release code and models at https://github.com/megvii-research/RevCol
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022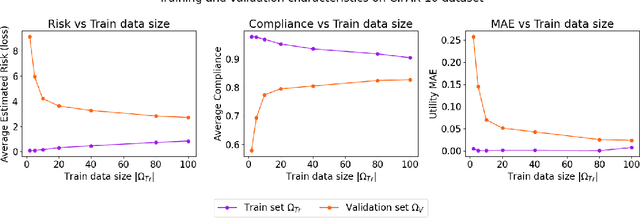
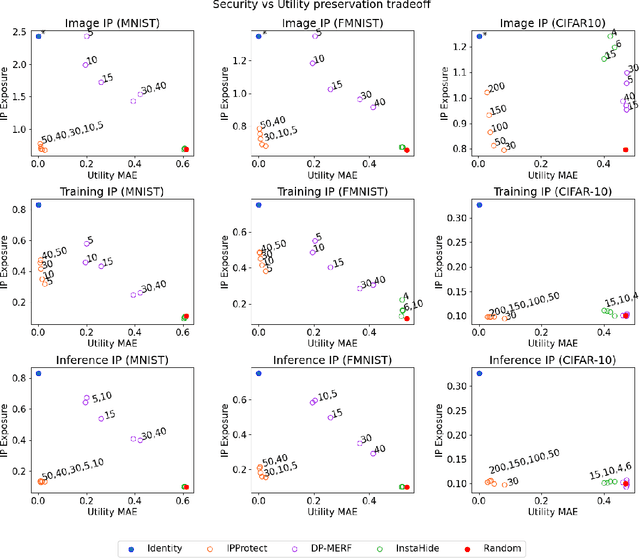
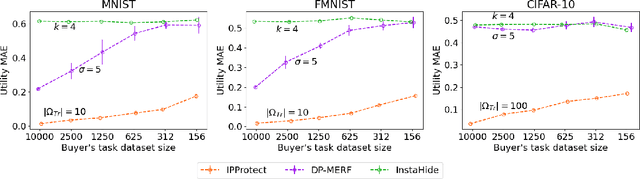
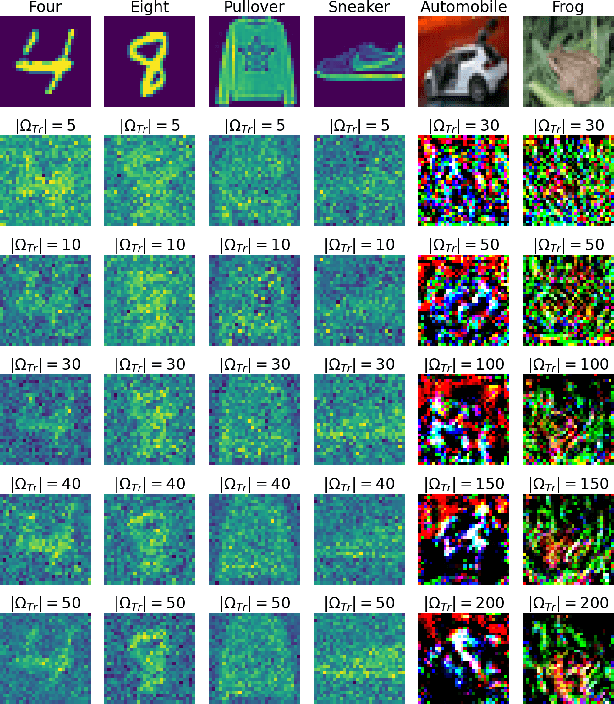
Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.