 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Robustness of MR Image Reconstruction under Realistic Perturbations
Aug 05, 2022
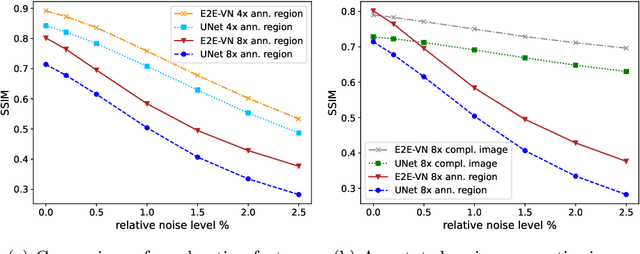
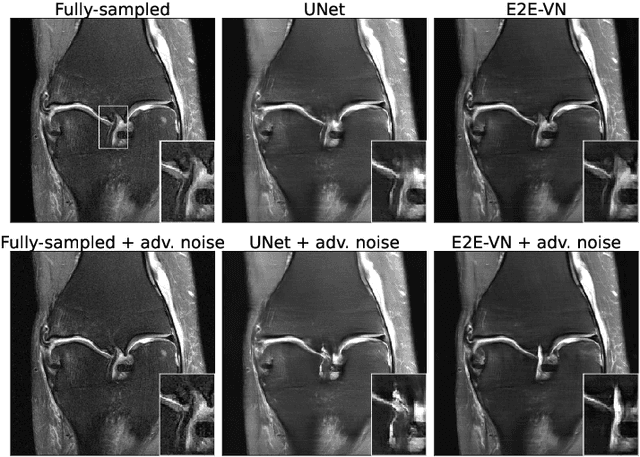
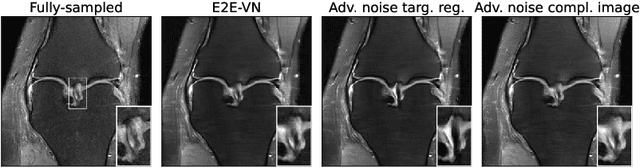
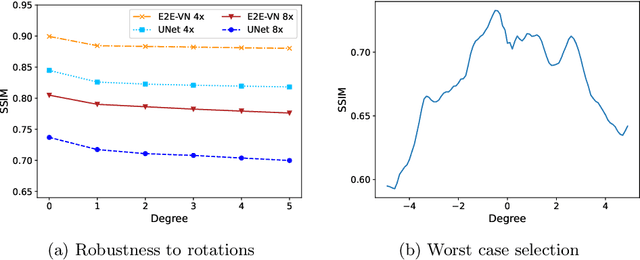
Deep Learning (DL) methods have shown promising results for solving ill-posed inverse problems such as MR image reconstruction from undersampled $k$-space data. However, these approaches currently have no guarantees for reconstruction quality and the reliability of such algorithms is only poorly understood. Adversarial attacks offer a valuable tool to understand possible failure modes and worst case performance of DL-based reconstruction algorithms. In this paper we describe adversarial attacks on multi-coil $k$-space measurements and evaluate them on the recently proposed E2E-VarNet and a simpler UNet-based model. In contrast to prior work, the attacks are targeted to specifically alter diagnostically relevant regions. Using two realistic attack models (adversarial $k$-space noise and adversarial rotations) we are able to show that current state-of-the-art DL-based reconstruction algorithms are indeed sensitive to such perturbations to a degree where relevant diagnostic information may be lost. Surprisingly, in our experiments the UNet and the more sophisticated E2E-VarNet were similarly sensitive to such attacks. Our findings add further to the evidence that caution must be exercised as DL-based methods move closer to clinical practice.
Cascade Luminance and Chrominance for Image Retouching: More Like Artist
May 31, 2022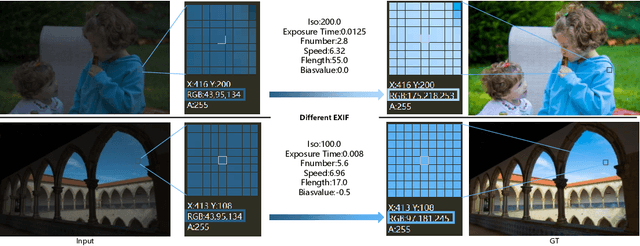

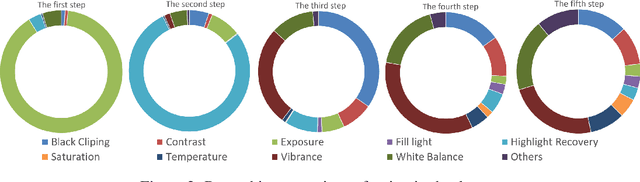
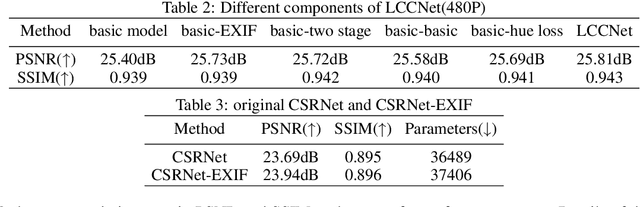
Photo retouching aims to adjust the luminance, contrast, and saturation of the image to make it more human aesthetically desirable. However, artists' actions in photo retouching are difficult to quantitatively analyze. By investigating their retouching behaviors, we propose a two-stage network that brightens images first and then enriches them in the chrominance plane. Six pieces of useful information from image EXIF are picked as the network's condition input. Additionally, hue palette loss is added to make the image more vibrant. Based on the above three aspects, Luminance-Chrominance Cascading Net(LCCNet) makes the machine learning problem of mimicking artists in photo retouching more reasonable. Experiments show that our method is effective on the benchmark MIT-Adobe FiveK dataset, and achieves state-of-the-art performance for both quantitative and qualitative evaluation.
Unconditional Image-Text Pair Generation with Multimodal Cross Quantizer
Apr 15, 2022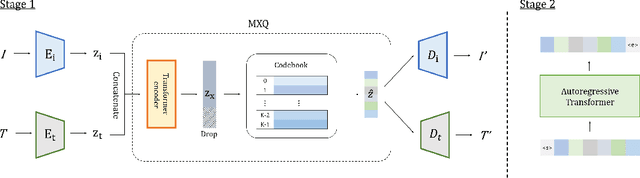
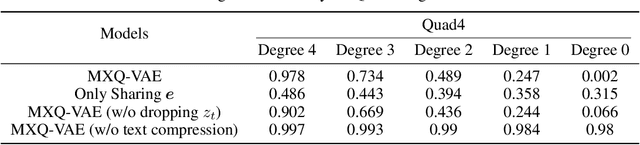
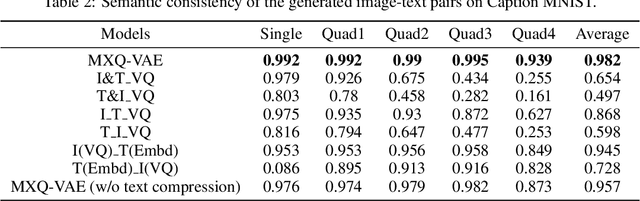

Though deep generative models have gained a lot of attention, most of the existing works are designed for the unimodal generation task. In this paper, we explore a new method for unconditional image-text pair generation. We propose MXQ-VAE, a vector quantization method for multimodal image-text representation. MXQ-VAE accepts a paired image and text as input, and learns a joint quantized representation space, so that the image-text pair can be converted to a sequence of unified indices. Then we can use autoregressive generative models to model the joint image-text representation, and even perform unconditional image-text pair generation. Extensive experimental results demonstrate that our approach effectively generates semantically consistent image-text pair and also enhances meaningful alignment between image and text.
REQA: Coarse-to-fine Assessment of Image Quality to Alleviate the Range Effect
Sep 05, 2022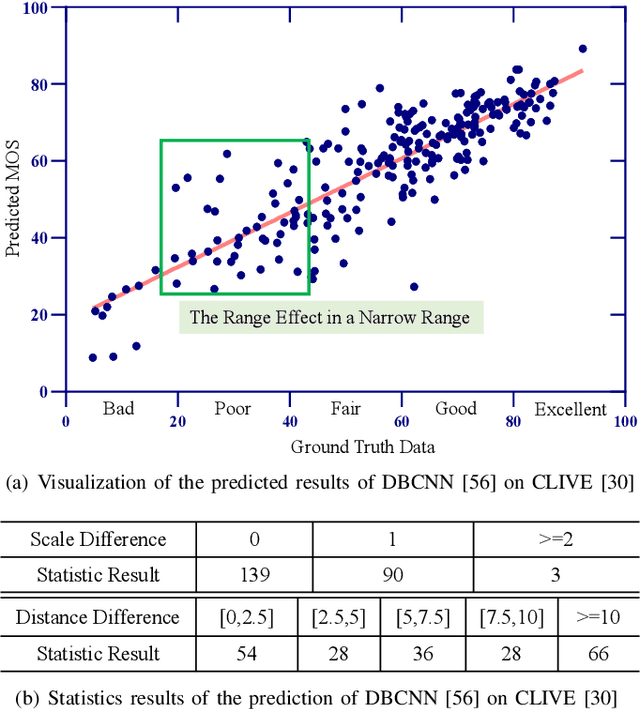
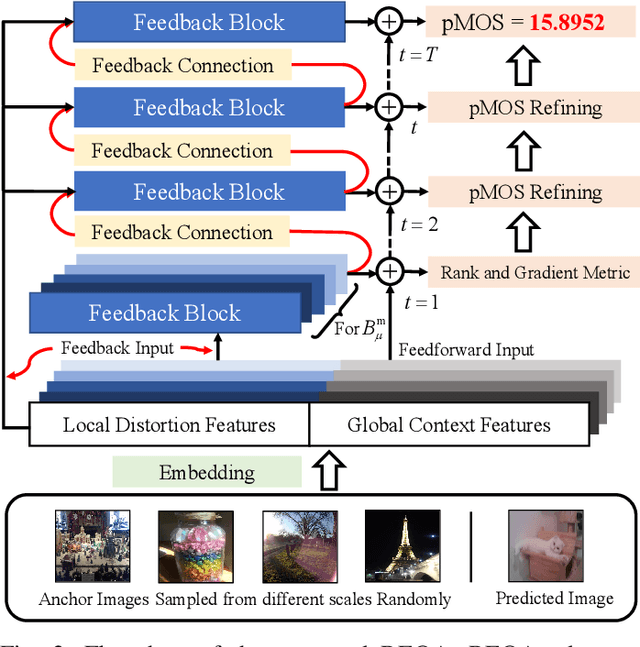
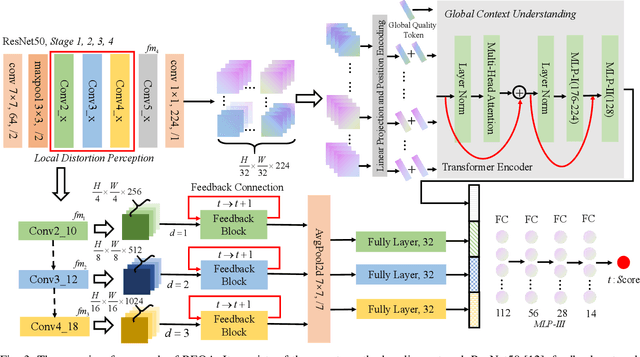
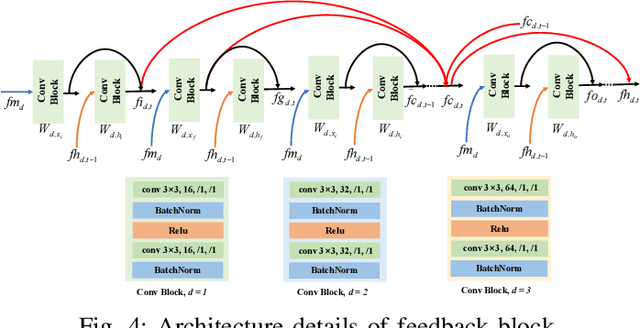
Blind image quality assessment (BIQA) of user generated content (UGC) suffers from the range effect which indicates that on the overall quality range, mean opinion score (MOS) and predicted MOS (pMOS) are well correlated; focusing on a particular range, the correlation is lower. The reason for the range effect is that the predicted deviations both in a wide range and in a narrow range destroy the uniformity between MOS and pMOS. To tackle this problem, a novel method is proposed from coarse-grained metric to fine-grained prediction. Firstly, we design a rank-and-gradient loss for coarse-grained metric. The loss keeps the order and grad consistency between pMOS and MOS, thereby reducing the predicted deviation in a wide range. Secondly, we propose multi-level tolerance loss to make fine-grained prediction. The loss is constrained by a decreasing threshold to limite the predicted deviation in narrower and narrower ranges. Finally, we design a feedback network to conduct the coarse-to-fine assessment. On the one hand, the network adopts feedback blocks to process multi-scale distortion features iteratively and on the other hand, it fuses non-local context feature to the output of each iteration to acquire more quality-aware feature representation. Experimental results demonstrate that the proposed method can alleviate the range effect compared to the state-of-the-art methods effectively.
GIT: A Generative Image-to-text Transformer for Vision and Language
May 31, 2022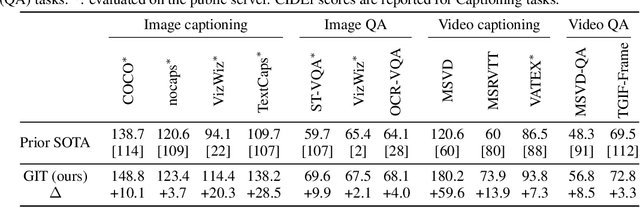

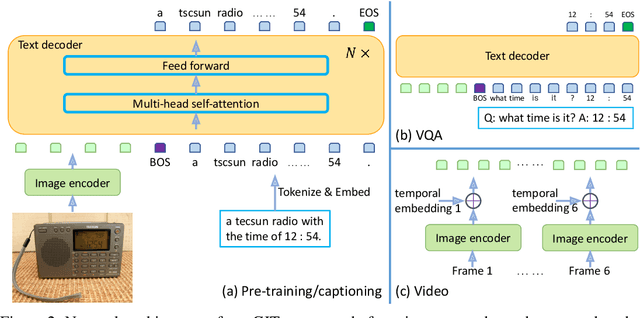
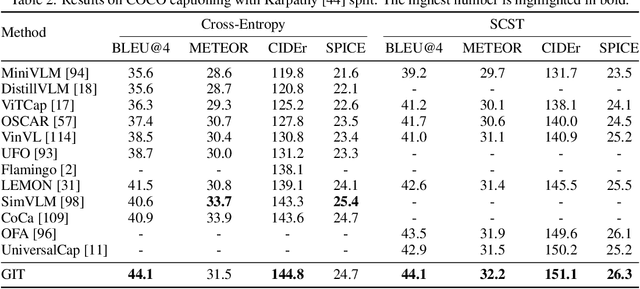
In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.
Interactive Visual Feature Search
Nov 28, 2022
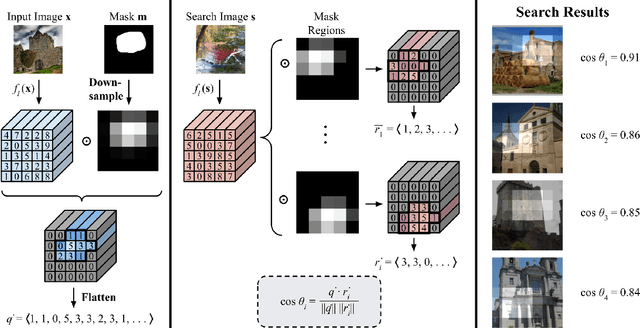


Many visualization techniques have been created to help explain the behavior of convolutional neural networks (CNNs), but they largely consist of static diagrams that convey limited information. Interactive visualizations can provide more rich insights and allow users to more easily explore a model's behavior; however, they are typically not easily reusable and are specific to a particular model. We introduce Visual Feature Search, a novel interactive visualization that is generalizable to any CNN and can easily be incorporated into a researcher's workflow. Our tool allows a user to highlight an image region and search for images from a given dataset with the most similar CNN features. It supports searching through large image datasets with an efficient cache-based search implementation. We demonstrate how our tool elucidates different aspects of model behavior by performing experiments on supervised, self-supervised, and human-edited CNNs. We also release a portable Python library and several IPython notebooks to enable researchers to easily use our tool in their own experiments. Our code can be found at https://github.com/lookingglasslab/VisualFeatureSearch.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022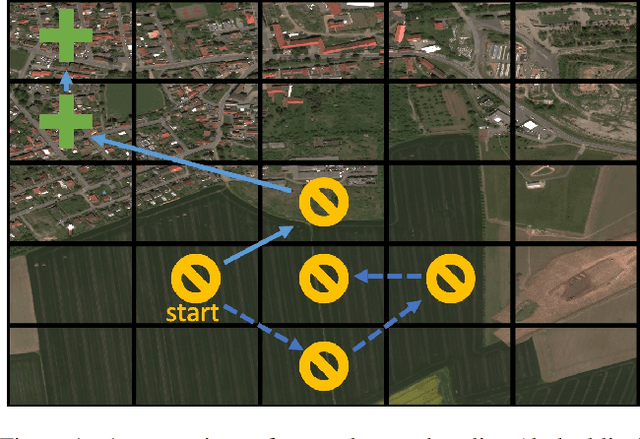
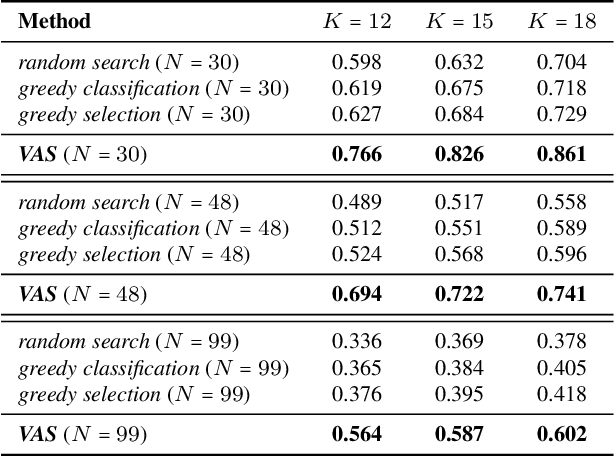
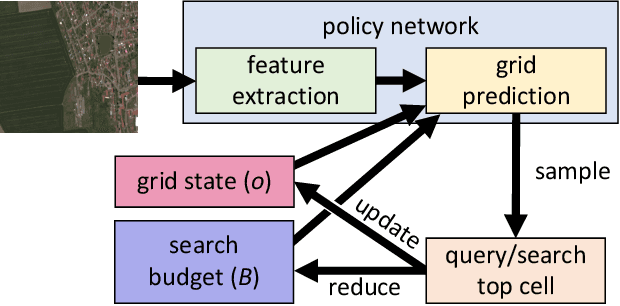
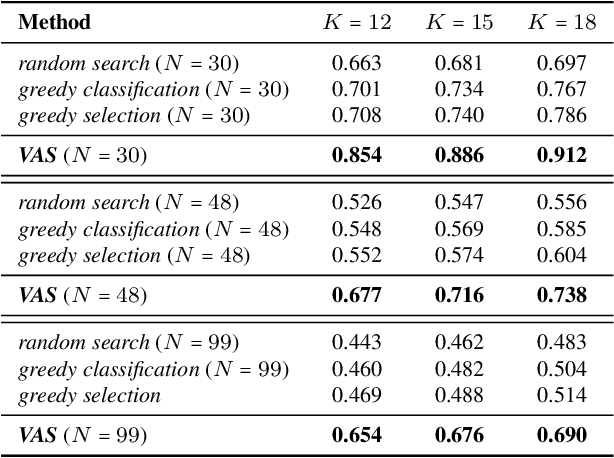
Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
Truncate-Split-Contrast: A Framework for Learning from Mislabeled Videos
Dec 29, 2022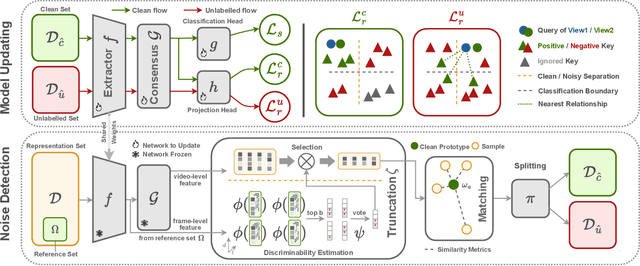
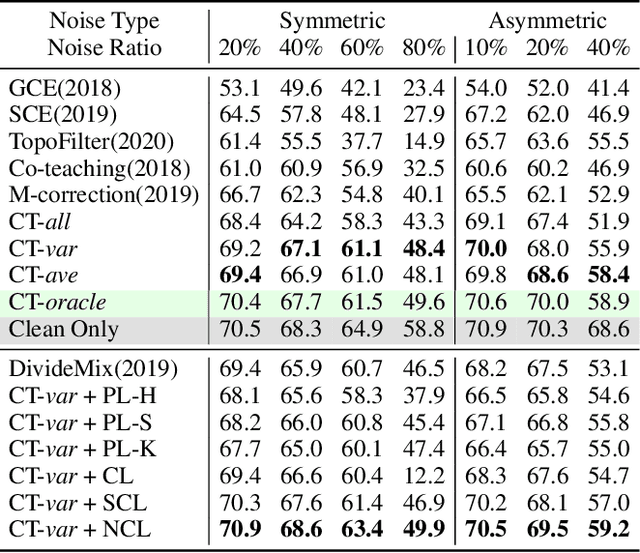
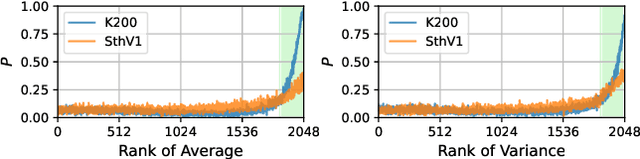
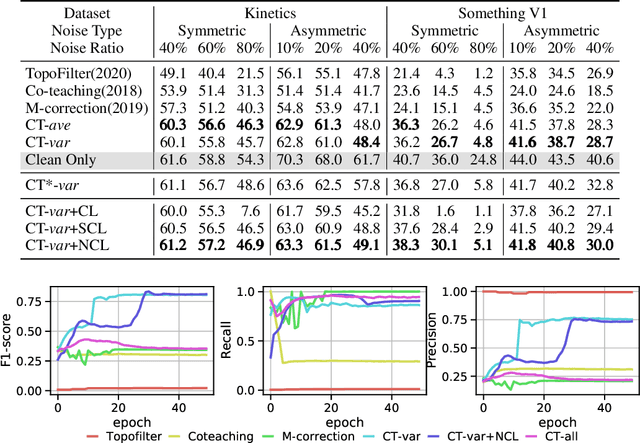
Learning with noisy label (LNL) is a classic problem that has been extensively studied for image tasks, but much less for video in the literature. A straightforward migration from images to videos without considering the properties of videos, such as computational cost and redundant information, is not a sound choice. In this paper, we propose two new strategies for video analysis with noisy labels: 1) A lightweight channel selection method dubbed as Channel Truncation for feature-based label noise detection. This method selects the most discriminative channels to split clean and noisy instances in each category; 2) A novel contrastive strategy dubbed as Noise Contrastive Learning, which constructs the relationship between clean and noisy instances to regularize model training. Experiments on three well-known benchmark datasets for video classification show that our proposed tru{\bf N}cat{\bf E}-split-contr{\bf A}s{\bf T} (NEAT) significantly outperforms the existing baselines. By reducing the dimension to 10\% of it, our method achieves over 0.4 noise detection F1-score and 5\% classification accuracy improvement on Mini-Kinetics dataset under severe noise (symmetric-80\%). Thanks to Noise Contrastive Learning, the average classification accuracy improvement on Mini-Kinetics and Sth-Sth-V1 is over 1.6\%.
A survey on text generation using generative adversarial networks
Dec 20, 2022

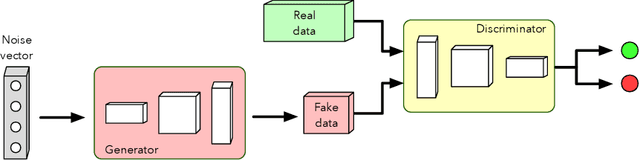
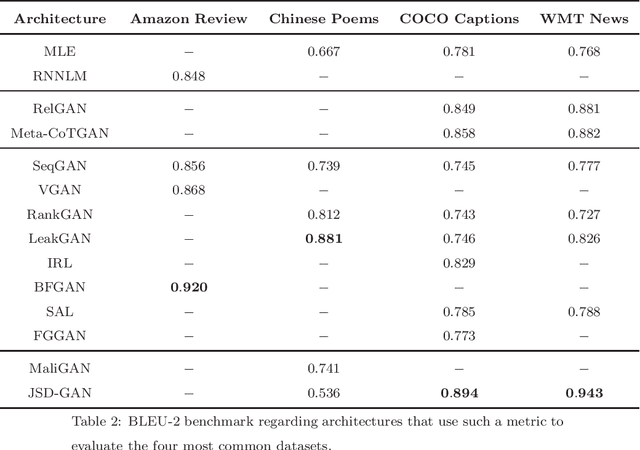
This work presents a thorough review concerning recent studies and text generation advancements using Generative Adversarial Networks. The usage of adversarial learning for text generation is promising as it provides alternatives to generate the so-called "natural" language. Nevertheless, adversarial text generation is not a simple task as its foremost architecture, the Generative Adversarial Networks, were designed to cope with continuous information (image) instead of discrete data (text). Thus, most works are based on three possible options, i.e., Gumbel-Softmax differentiation, Reinforcement Learning, and modified training objectives. All alternatives are reviewed in this survey as they present the most recent approaches for generating text using adversarial-based techniques. The selected works were taken from renowned databases, such as Science Direct, IEEEXplore, Springer, Association for Computing Machinery, and arXiv, whereas each selected work has been critically analyzed and assessed to present its objective, methodology, and experimental results.
Explaining Image Enhancement Black-Box Methods through a Path Planning Based Algorithm
Jul 14, 2022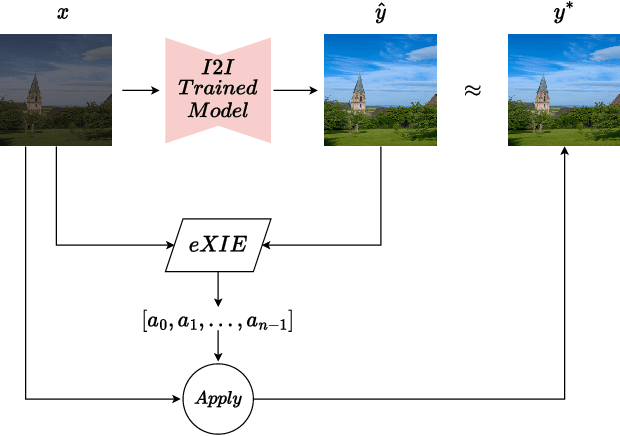
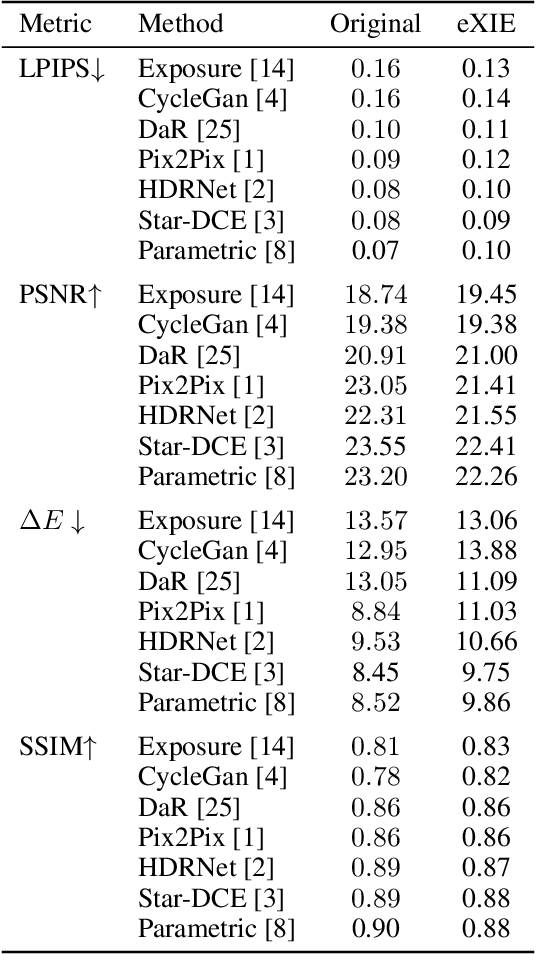
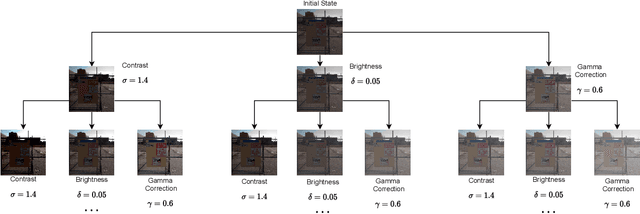
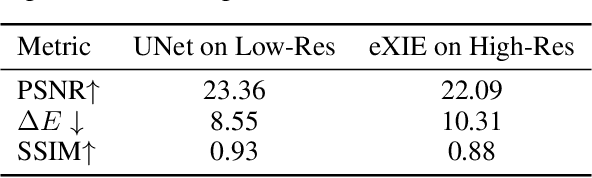
Nowadays, image-to-image translation methods, are the state of the art for the enhancement of natural images. Even if they usually show high performance in terms of accuracy, they often suffer from several limitations such as the generation of artifacts and the scalability to high resolutions. Moreover, their main drawback is the completely black-box approach that does not allow to provide the final user with any insight about the enhancement processes applied. In this paper we present a path planning algorithm which provides a step-by-step explanation of the output produced by state of the art enhancement methods, overcoming black-box limitation. This algorithm, called eXIE, uses a variant of the A* algorithm to emulate the enhancement process of another method through the application of an equivalent sequence of enhancing operators. We applied eXIE to explain the output of several state-of-the-art models trained on the Five-K dataset, obtaining sequences of enhancing operators able to produce very similar results in terms of performance and overcoming the huge limitation of poor interpretability of the best performing algorithms.