 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
${S}^{2}$Net: Accurate Panorama Depth Estimation on Spherical Surface
Jan 14, 2023
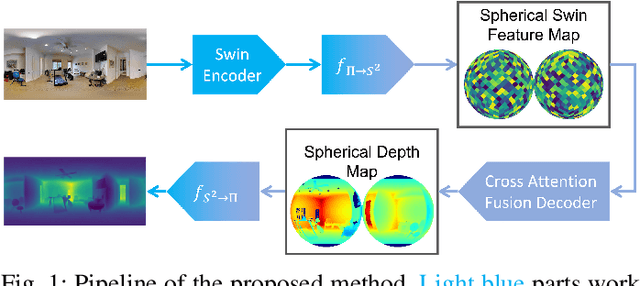

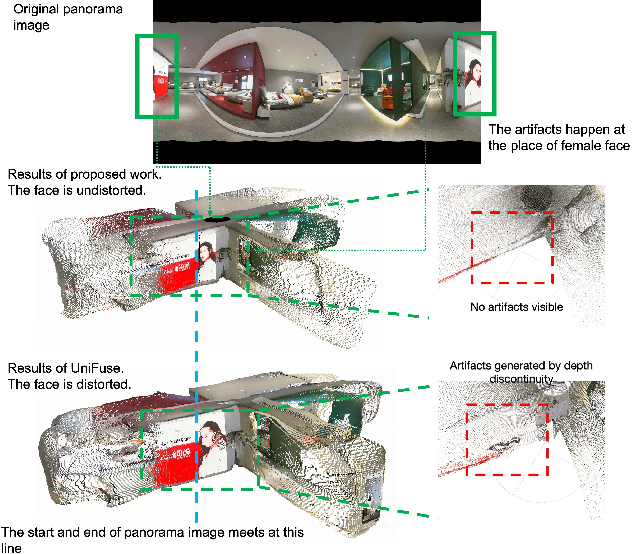
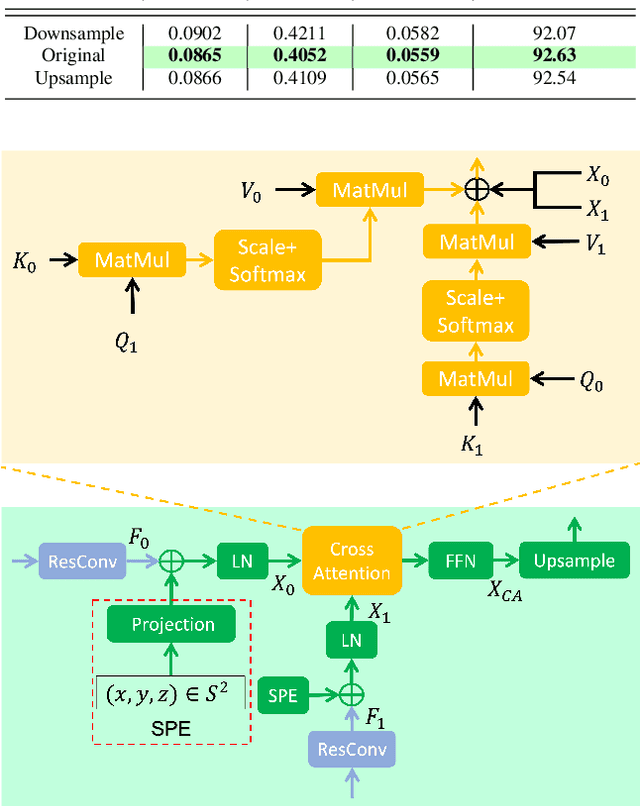
Monocular depth estimation is an ambiguous problem, thus global structural cues play an important role in current data-driven single-view depth estimation methods. Panorama images capture the complete spatial information of their surroundings utilizing the equirectangular projection which introduces large distortion. This requires the depth estimation method to be able to handle the distortion and extract global context information from the image. In this paper, we propose an end-to-end deep network for monocular panorama depth estimation on a unit spherical surface. Specifically, we project the feature maps extracted from equirectangular images onto unit spherical surface sampled by uniformly distributed grids, where the decoder network can aggregate the information from the distortion-reduced feature maps. Meanwhile, we propose a global cross-attention-based fusion module to fuse the feature maps from skip connection and enhance the ability to obtain global context. Experiments are conducted on five panorama depth estimation datasets, and the results demonstrate that the proposed method substantially outperforms previous state-of-the-art methods. All related codes will be open-sourced in the upcoming days.
Explicit and implicit models in infrared and visible image fusion
Jun 20, 2022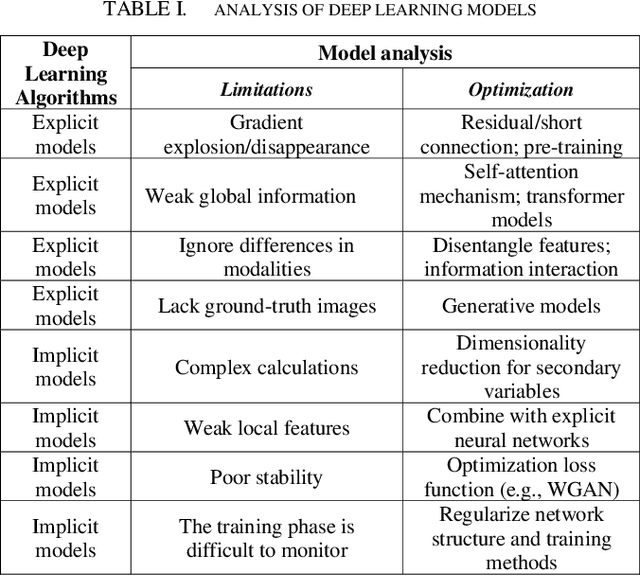
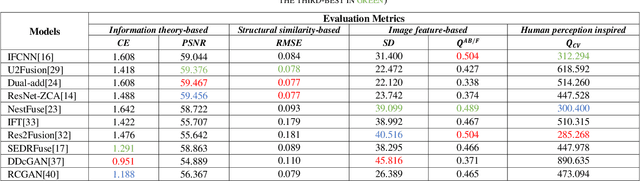
Infrared and visible images, as multi-modal image pairs, show significant differences in the expression of the same scene. The image fusion task is faced with two problems: one is to maintain the unique features between different modalities, and the other is to maintain features at various levels like local and global features. This paper discusses the limitations of deep learning models in image fusion and the corresponding optimization strategies. Based on artificially designed structures and constraints, we divide models into explicit models, and implicit models that adaptively learn high-level features or can establish global pixel associations. Ten models for comparison experiments on 21 test sets were screened. The qualitative and quantitative results show that the implicit models have more comprehensive ability to learn image features. At the same time, the stability of them needs to be improved. Aiming at the advantages and limitations to be solved by existing algorithms, we discuss the main problems of multi-modal image fusion and future research directions.
Self-Supervised Geometry-Aware Encoder for Style-Based 3D GAN Inversion
Dec 15, 2022
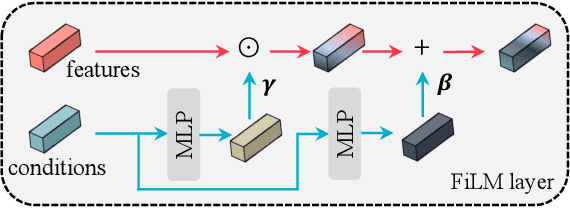

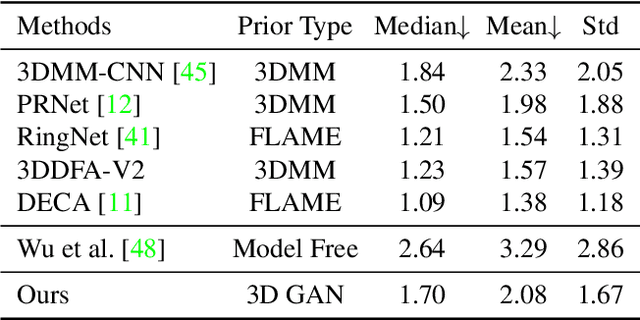
StyleGAN has achieved great progress in 2D face reconstruction and semantic editing via image inversion and latent editing. While studies over extending 2D StyleGAN to 3D faces have emerged, a corresponding generic 3D GAN inversion framework is still missing, limiting the applications of 3D face reconstruction and semantic editing. In this paper, we study the challenging problem of 3D GAN inversion where a latent code is predicted given a single face image to faithfully recover its 3D shapes and detailed textures. The problem is ill-posed: innumerable compositions of shape and texture could be rendered to the current image. Furthermore, with the limited capacity of a global latent code, 2D inversion methods cannot preserve faithful shape and texture at the same time when applied to 3D models. To solve this problem, we devise an effective self-training scheme to constrain the learning of inversion. The learning is done efficiently without any real-world 2D-3D training pairs but proxy samples generated from a 3D GAN. In addition, apart from a global latent code that captures the coarse shape and texture information, we augment the generation network with a local branch, where pixel-aligned features are added to faithfully reconstruct face details. We further consider a new pipeline to perform 3D view-consistent editing. Extensive experiments show that our method outperforms state-of-the-art inversion methods in both shape and texture reconstruction quality. Code and data will be released.
Blind Image Deblurring with Unknown Kernel Size and Substantial Noise
Aug 18, 2022

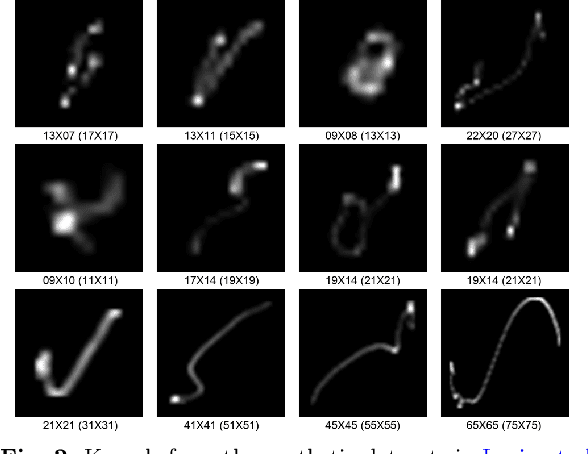

Blind image deblurring (BID) has been extensively studied in computer vision and adjacent fields. Modern methods for BID can be grouped into two categories: single-instance methods that deal with individual instances using statistical inference and numerical optimization, and data-driven methods that train deep-learning models to deblur future instances directly. Data-driven methods can be free from the difficulty in deriving accurate blur models, but are fundamentally limited by the diversity and quality of the training data -- collecting sufficiently expressive and realistic training data is a standing challenge. In this paper, we focus on single-instance methods that remain competitive and indispensable. However, most such methods do not prescribe how to deal with unknown kernel size and substantial noise, precluding practical deployment. Indeed, we show that several state-of-the-art (SOTA) single-instance methods are unstable when the kernel size is overspecified, and/or the noise level is high. On the positive side, we propose a practical BID method that is stable against both, the first of its kind. Our method builds on the recent ideas of solving inverse problems by integrating the physical models and structured deep neural networks, without extra training data. We introduce several crucial modifications to achieve the desired stability. Extensive empirical tests on standard synthetic datasets, as well as real-world NTIRE2020 and RealBlur datasets, show the superior effectiveness and practicality of our BID method compared to SOTA single-instance as well as data-driven methods. The code of our method is available at: \url{https://github.com/sun-umn/Blind-Image-Deblurring}.
Online Reflective Learning for Robust Medical Image Segmentation
Jul 01, 2022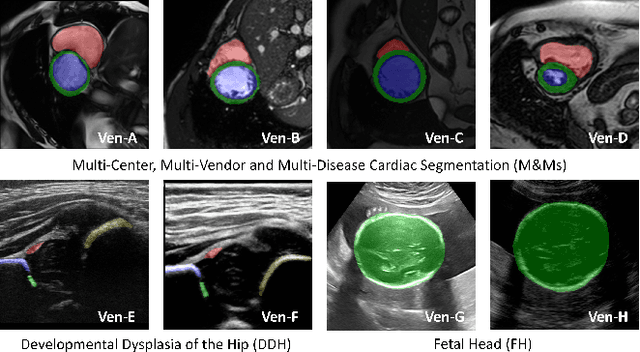
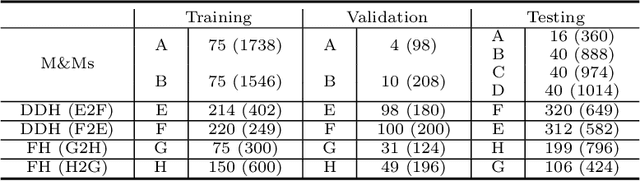
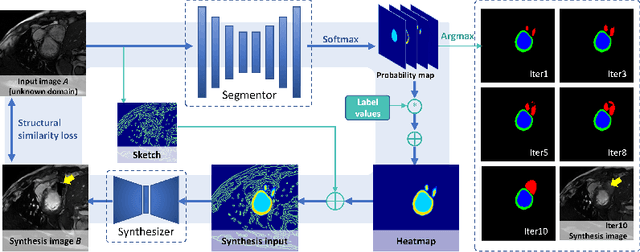
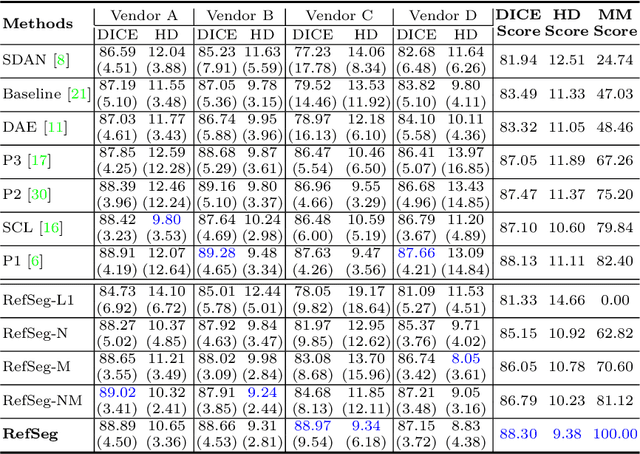
Deep segmentation models often face the failure risks when the testing image presents unseen distributions. Improving model robustness against these risks is crucial for the large-scale clinical application of deep models. In this study, inspired by human learning cycle, we propose a novel online reflective learning framework (RefSeg) to improve segmentation robustness. Based on the reflection-on-action conception, our RefSeg firstly drives the deep model to take action to obtain semantic segmentation. Then, RefSeg triggers the model to reflect itself. Because making deep models realize their segmentation failures during testing is challenging, RefSeg synthesizes a realistic proxy image from the semantic mask to help deep models build intuitive and effective reflections. This proxy translates and emphasizes the segmentation flaws. By maximizing the structural similarity between the raw input and the proxy, the reflection-on-action loop is closed with segmentation robustness improved. RefSeg runs in the testing phase and is general for segmentation models. Extensive validation on three medical image segmentation tasks with a public cardiac MR dataset and two in-house large ultrasound datasets show that our RefSeg remarkably improves model robustness and reports state-of-the-art performance over strong competitors.
Collaborative Semantic Communication at the Edge
Jan 10, 2023
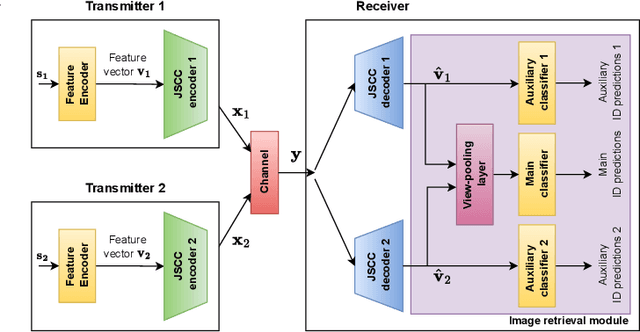
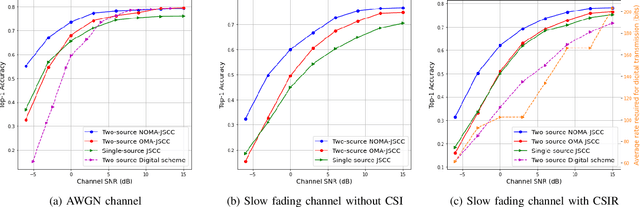
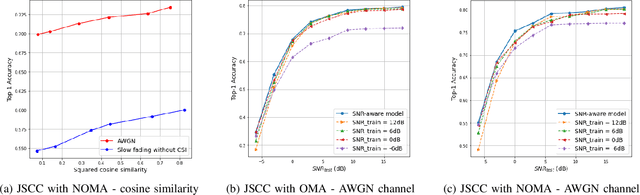
We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object from different angles and locations, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel (MAC). We propose two novel deep learning-based joint source and channel coding (JSCC) schemes for the task over both additive white Gaussian noise (AWGN) and Rayleigh slow fading channels, with the aim of maximizing the retrieval accuracy under a total bandwidth constraint. The proposed schemes are evaluated on a wide range of channel signal-to-noise ratios (SNRs), and shown to outperform the single-device JSCC and the separation-based multiple-access benchmarks. We also propose two novel SNR-aware JSCC schemes with attention modules to improve the performance in the case of channel mismatch between training and test instances.
An Event-based Algorithm for Simultaneous 6-DOF Camera Pose Tracking and Mapping
Jan 10, 2023
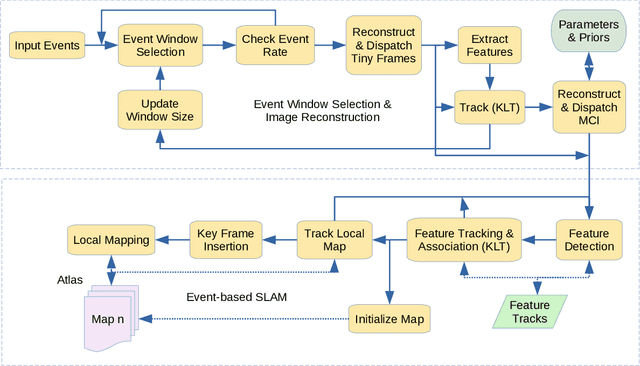
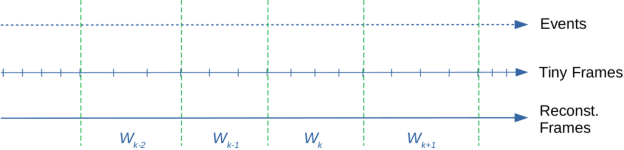
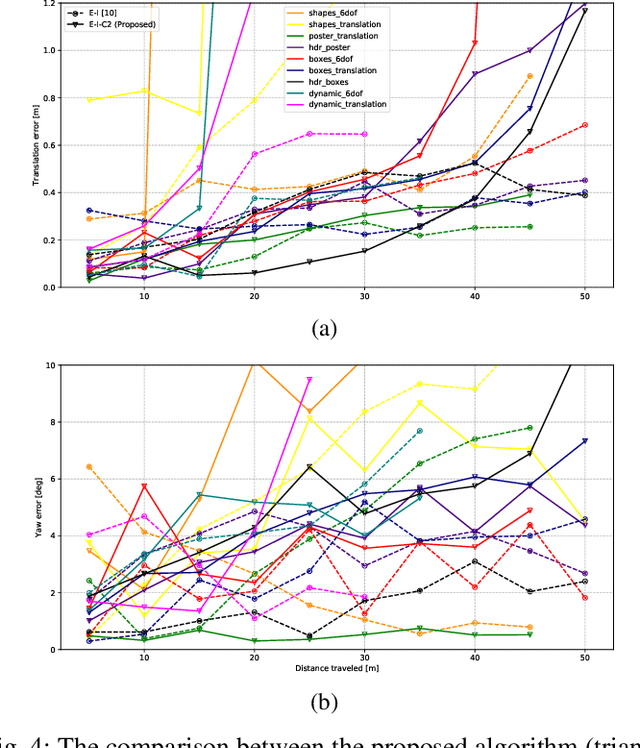
Compared to regular cameras, Dynamic Vision Sensors or Event Cameras can output compact visual data based on a change in the intensity in each pixel location asynchronously. In this paper, we study the application of current image-based SLAM techniques to these novel sensors. To this end, the information in adaptively selected event windows is processed to form motion-compensated images. These images are then used to reconstruct the scene and estimate the 6-DOF pose of the camera. We also propose an inertial version of the event-only pipeline to assess its capabilities. We compare the results of different configurations of the proposed algorithm against the ground truth for sequences of two publicly available event datasets. We also compare the results of the proposed event-inertial pipeline with the state-of-the-art and show it can produce comparable or more accurate results provided the map estimate is reliable.
ROBUSfT: Robust Real-Time Shape-from-Template, a C++ Library
Jan 10, 2023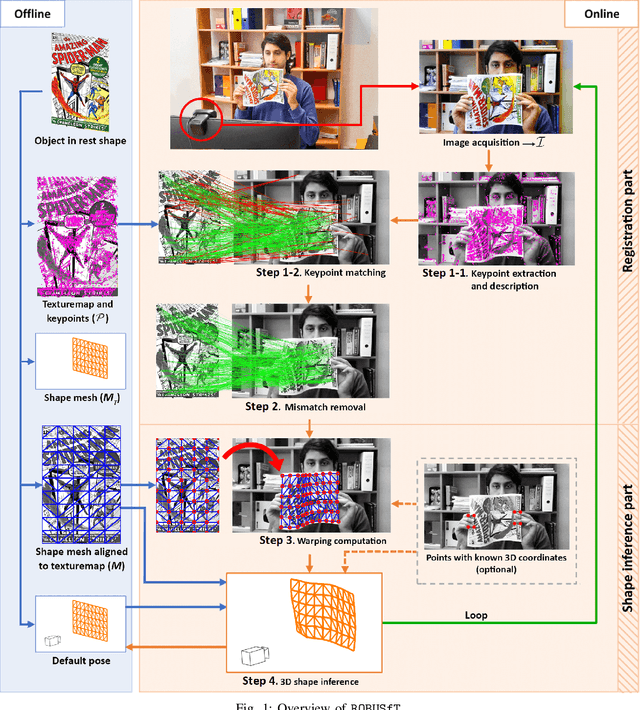
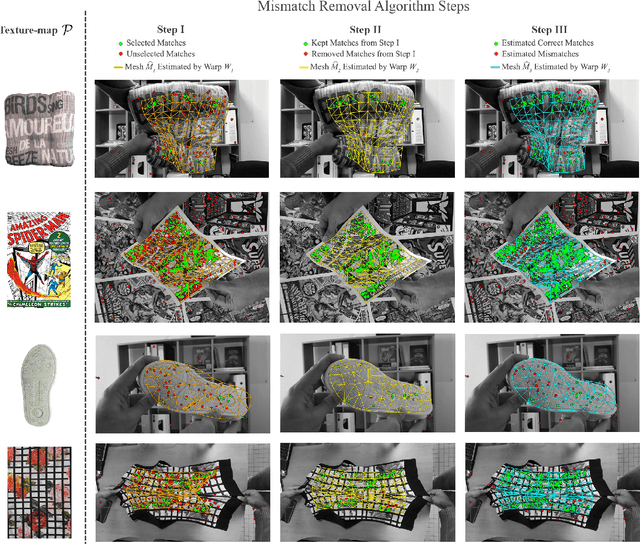
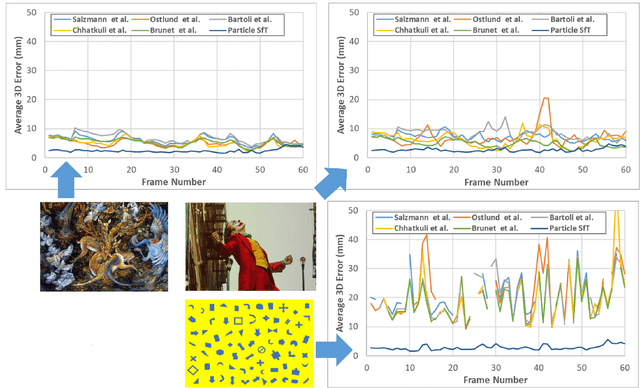
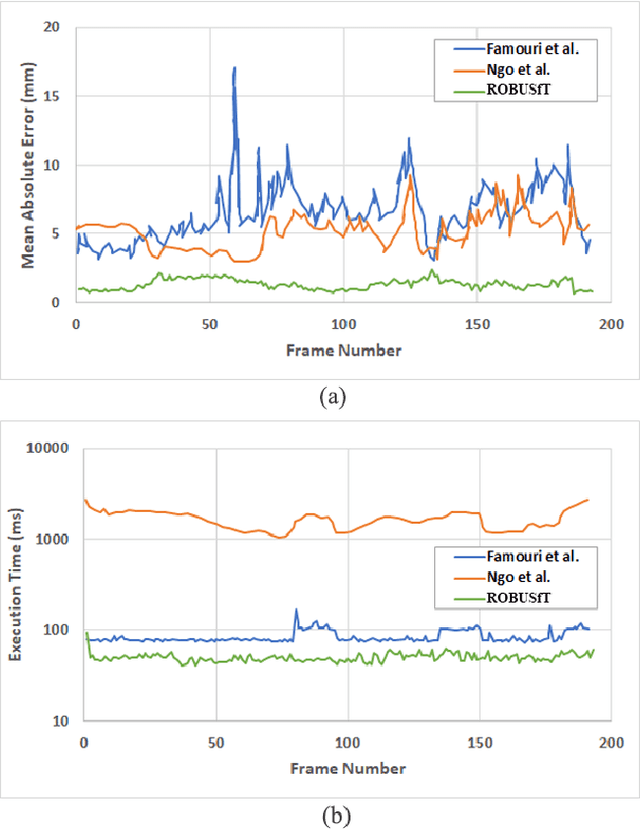
Tracking the 3D shape of a deforming object using only monocular 2D vision is a challenging problem. This is because one should (i) infer the 3D shape from a 2D image, which is a severely underconstrained problem, and (ii) implement the whole solution pipeline in real-time. The pipeline typically requires feature detection and matching, mismatch filtering, 3D shape inference and feature tracking algorithms. We propose ROBUSfT, a conventional pipeline based on a template containing the object's rest shape, texturemap and deformation law. ROBUSfT is ready-to-use, wide-baseline, capable of handling large deformations, fast up to 30 fps, free of training, and robust against partial occlusions and discontinuity in video frames. It outperforms the state-of-the-art methods in challenging datasets. ROBUSfT is implemented as a publicly available C++ library and we provide a tutorial on how to use it in https://github.com/mrshetab/ROBUSfT
Magnitude-image based data-consistent deep learning method for MRI super resolution
Sep 07, 2022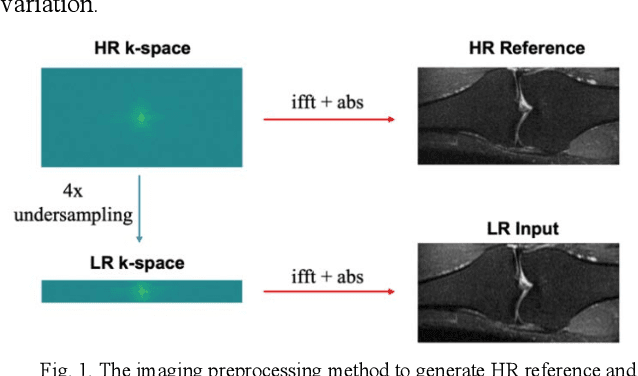
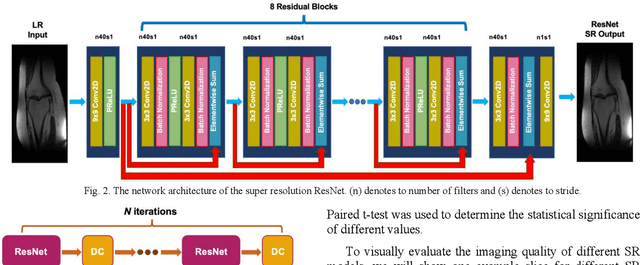
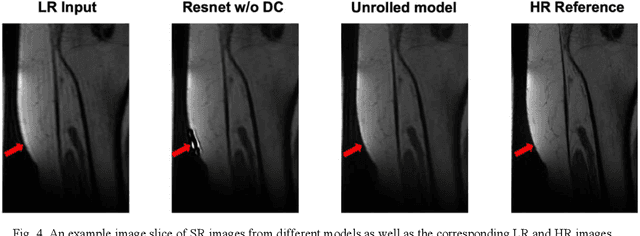
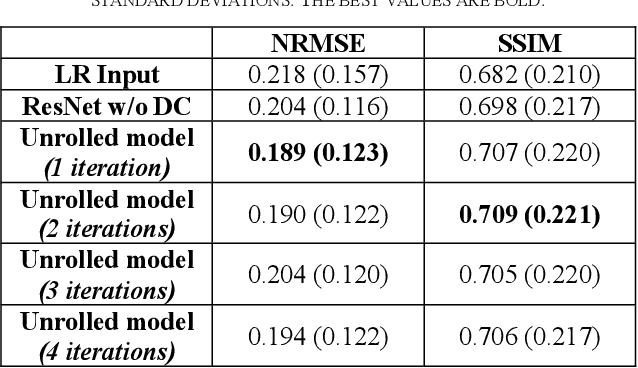
Magnetic Resonance Imaging (MRI) is important in clinic to produce high resolution images for diagnosis, but its acquisition time is long for high resolution images. Deep learning based MRI super resolution methods can reduce scan time without complicated sequence programming, but may create additional artifacts due to the discrepancy between training data and testing data. Data consistency layer can improve the deep learning results but needs raw k-space data. In this work, we propose a magnitude-image based data consistency deep learning MRI super resolution method to improve super resolution images' quality without raw k-space data. Our experiments show that the proposed method can improve NRMSE and SSIM of super resolution images compared to the same Convolutional Neural Network (CNN) block without data consistency module.
Self-Supervised Feature Learning for Long-Term Metric Visual Localization
Nov 30, 2022
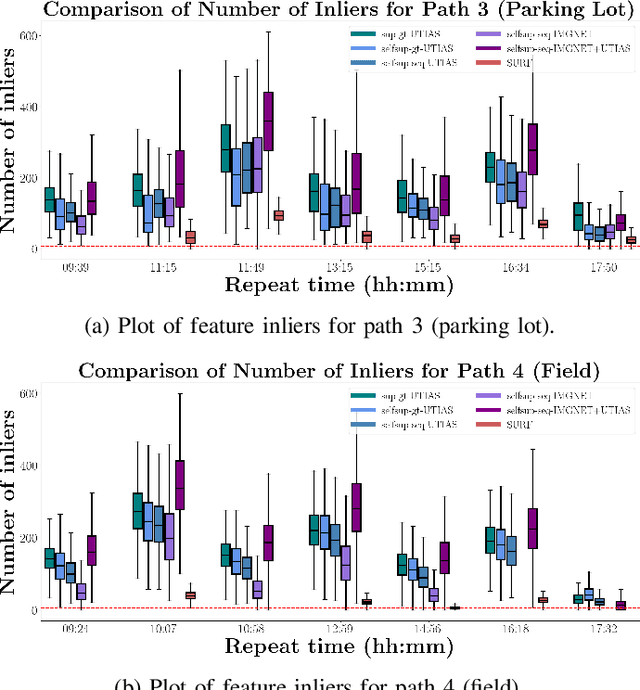
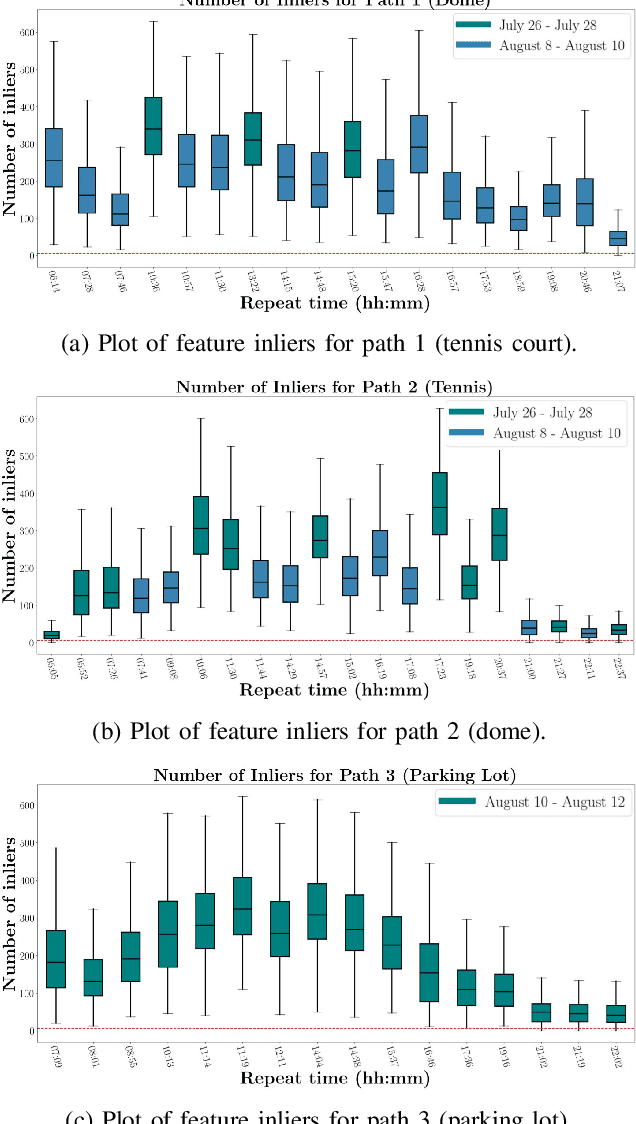
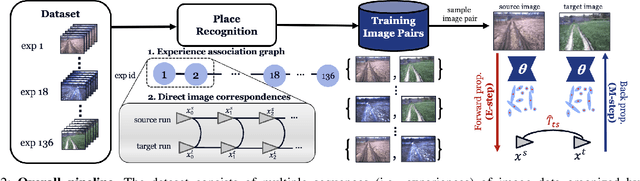
Visual localization is the task of estimating camera pose in a known scene, which is an essential problem in robotics and computer vision. However, long-term visual localization is still a challenge due to the environmental appearance changes caused by lighting and seasons. While techniques exist to address appearance changes using neural networks, these methods typically require ground-truth pose information to generate accurate image correspondences or act as a supervisory signal during training. In this paper, we present a novel self-supervised feature learning framework for metric visual localization. We use a sequence-based image matching algorithm across different sequences of images (i.e., experiences) to generate image correspondences without ground-truth labels. We can then sample image pairs to train a deep neural network that learns sparse features with associated descriptors and scores without ground-truth pose supervision. The learned features can be used together with a classical pose estimator for visual stereo localization. We validate the learned features by integrating with an existing Visual Teach & Repeat pipeline to perform closed-loop localization experiments under different lighting conditions for a total of 22.4 km.