 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Forgery Classifier On Multi-modality Face Forgery Clues
Dec 30, 2022
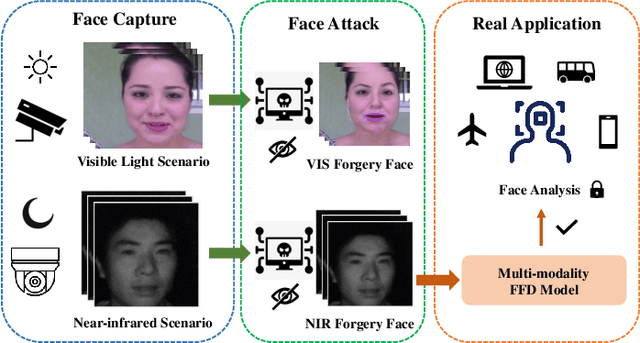
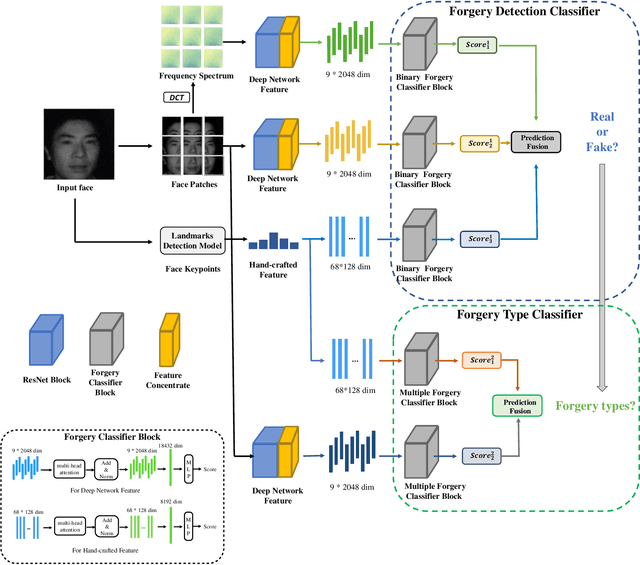


Face forgery detection plays an important role in personal privacy and social security. With the development of adversarial generative models, high-quality forgery images become more and more indistinguishable from real to humans. Existing methods always regard as forgery detection task as the common binary or multi-label classification, and ignore exploring diverse multi-modality forgery image types, e.g. visible light spectrum and near-infrared scenarios. In this paper, we propose a novel Hierarchical Forgery Classifier for Multi-modality Face Forgery Detection (HFC-MFFD), which could effectively learn robust patches-based hybrid domain representation to enhance forgery authentication in multiple-modality scenarios. The local spatial hybrid domain feature module is designed to explore strong discriminative forgery clues both in the image and frequency domain in local distinct face regions. Furthermore, the specific hierarchical face forgery classifier is proposed to alleviate the class imbalance problem and further boost detection performance. Experimental results on representative multi-modality face forgery datasets demonstrate the superior performance of the proposed HFC-MFFD compared with state-of-the-art algorithms. The source code and models are publicly available at https://github.com/EdWhites/HFC-MFFD.
A Two Step Approach for Whole Slide Image Registration
Aug 25, 2022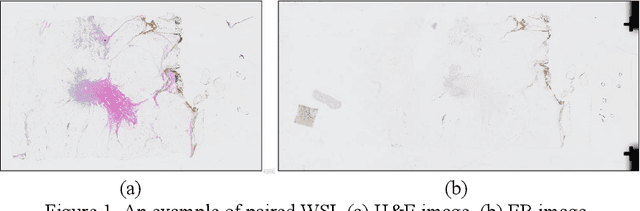
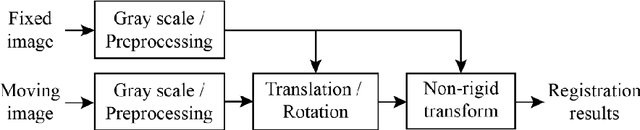
Multi-stain whole-slide-image (WSI) registration is an active field of research. It is unclear, however, how the current WSI registration methods would perform on a real-world data set. AutomatiC Registration Of Breast cAncer Tissue (ACROBAT) challenge is held to verify the performance of the current WSI registration methods by using a new dataset that originates from routine diagnostics to assess real-world applicability. In this report, we present our solution for the ACROBAT challenge. We employ a two-step approach including rigid and non-rigid transforms. The experimental results show that the median 90th percentile is 1,250 um for the validation dataset.
Backdoor Attack and Defense in Federated Generative Adversarial Network-based Medical Image Synthesis
Oct 19, 2022

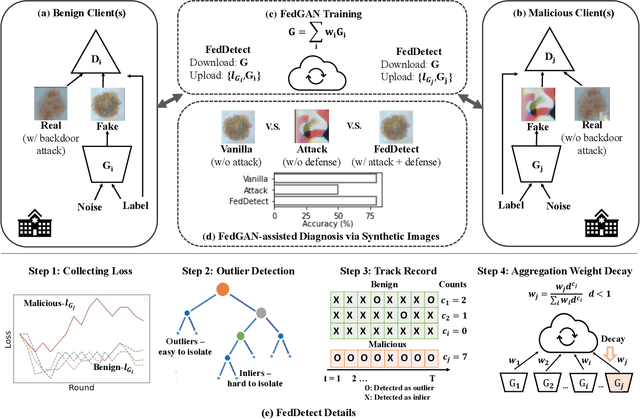
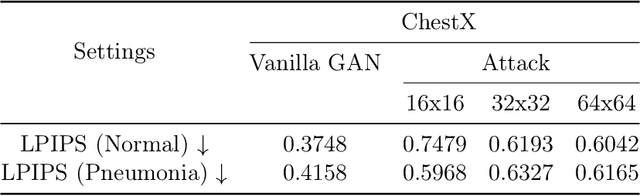
Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research and augment medical datasets. Training generative adversarial neural networks (GANs) usually require large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data while keeping raw data locally. However, given that the FL server cannot access the raw data, it is vulnerable to backdoor attacks, an adversarial by poisoning training data. Most backdoor attack strategies focus on classification models and centralized domains. It is still an open question if the existing backdoor attacks can affect GAN training and, if so, how to defend against the attack in the FL setting. In this work, we investigate the overlooked issue of backdoor attacks in federated GANs (FedGANs). The success of this attack is subsequently determined to be the result of some local discriminators overfitting the poisoned data and corrupting the local GAN equilibrium, which then further contaminates other clients when averaging the generator's parameters and yields high generator loss. Therefore, we proposed FedDetect, an efficient and effective way of defending against the backdoor attack in the FL setting, which allows the server to detect the client's adversarial behavior based on their losses and block the malicious clients. Our extensive experiments on two medical datasets with different modalities demonstrate the backdoor attack on FedGANs can result in synthetic images with low fidelity. After detecting and suppressing the detected malicious clients using the proposed defense strategy, we show that FedGANs can synthesize high-quality medical datasets (with labels) for data augmentation to improve classification models' performance.
ChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Aug 05, 2022
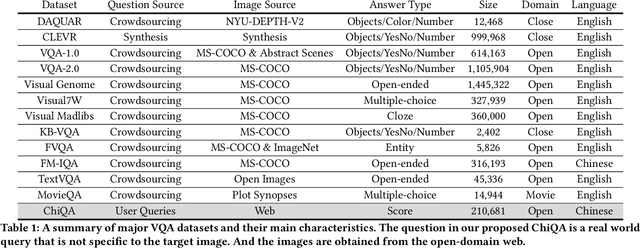

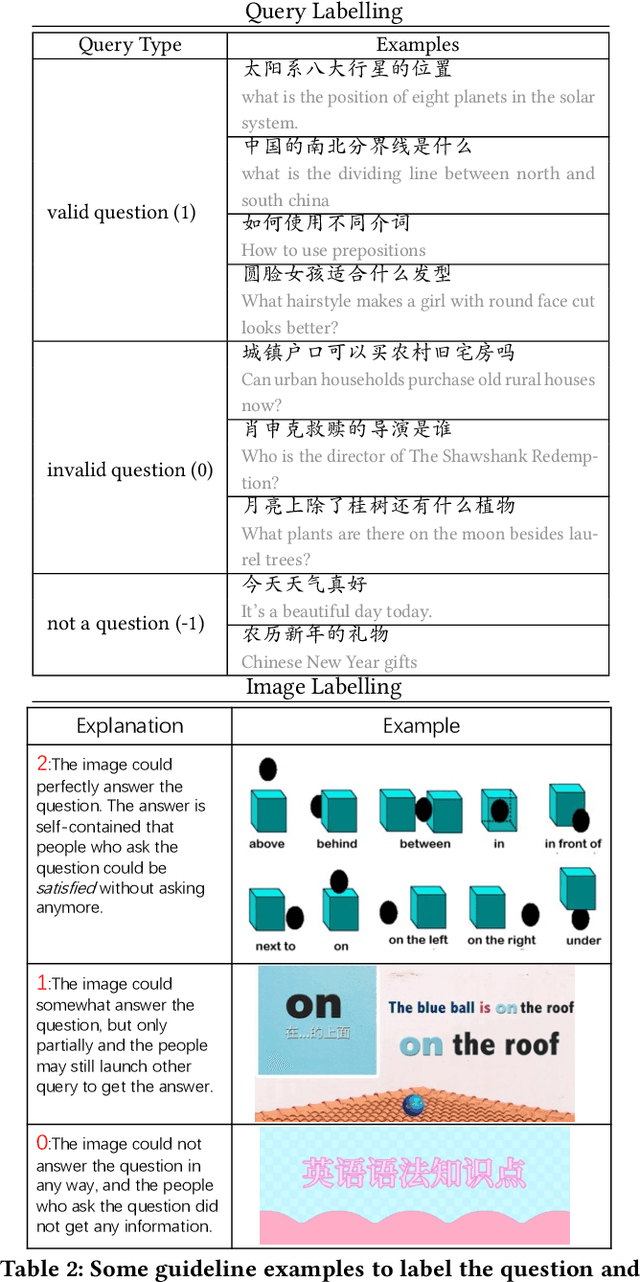
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.
Leveraging the Third Dimension in Contrastive Learning
Jan 27, 2023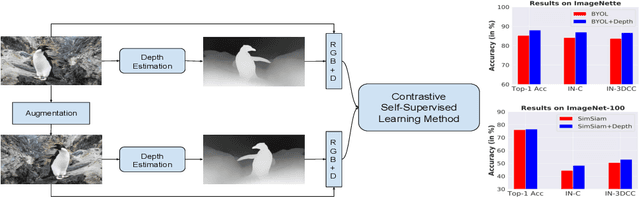
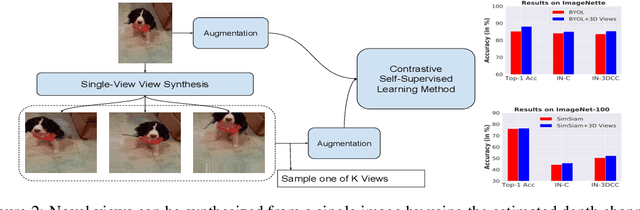
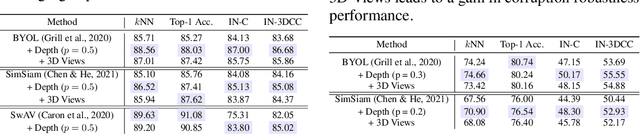
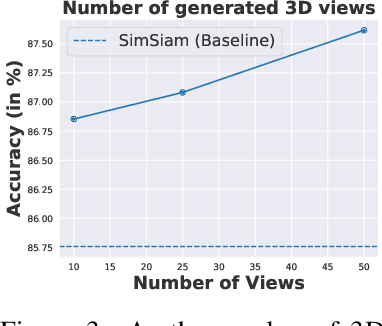
Self-Supervised Learning (SSL) methods operate on unlabeled data to learn robust representations useful for downstream tasks. Most SSL methods rely on augmentations obtained by transforming the 2D image pixel map. These augmentations ignore the fact that biological vision takes place in an immersive three-dimensional, temporally contiguous environment, and that low-level biological vision relies heavily on depth cues. Using a signal provided by a pretrained state-of-the-art monocular RGB-to-depth model (the \emph{Depth Prediction Transformer}, Ranftl et al., 2021), we explore two distinct approaches to incorporating depth signals into the SSL framework. First, we evaluate contrastive learning using an RGB+depth input representation. Second, we use the depth signal to generate novel views from slightly different camera positions, thereby producing a 3D augmentation for contrastive learning. We evaluate these two approaches on three different SSL methods -- BYOL, SimSiam, and SwAV -- using ImageNette (10 class subset of ImageNet), ImageNet-100 and ImageNet-1k datasets. We find that both approaches to incorporating depth signals improve the robustness and generalization of the baseline SSL methods, though the first approach (with depth-channel concatenation) is superior. For instance, BYOL with the additional depth channel leads to an increase in downstream classification accuracy from 85.3\% to 88.0\% on ImageNette and 84.1\% to 87.0\% on ImageNet-C.
When to Trust Aggregated Gradients: Addressing Negative Client Sampling in Federated Learning
Jan 25, 2023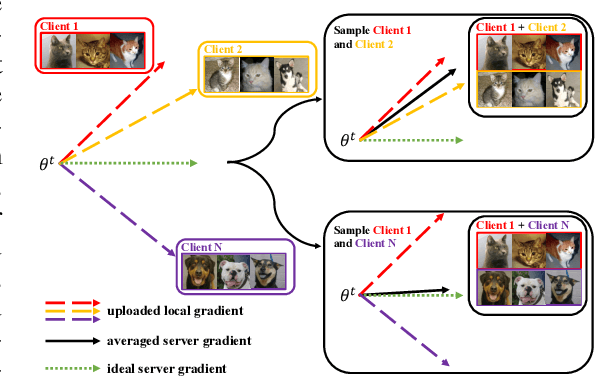
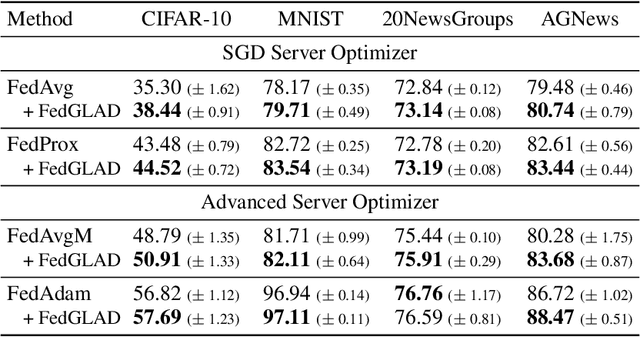
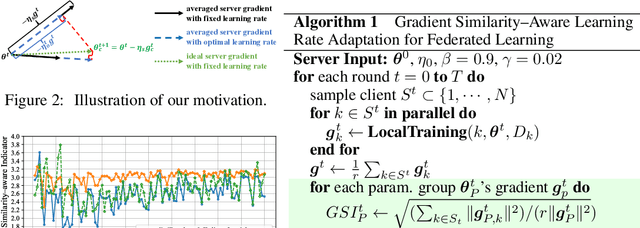
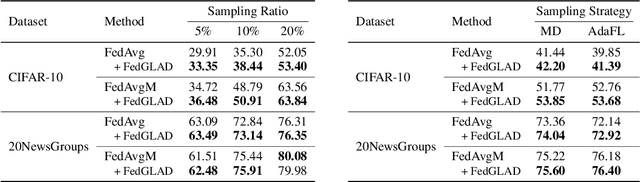
Federated Learning has become a widely-used framework which allows learning a global model on decentralized local datasets under the condition of protecting local data privacy. However, federated learning faces severe optimization difficulty when training samples are not independently and identically distributed (non-i.i.d.). In this paper, we point out that the client sampling practice plays a decisive role in the aforementioned optimization difficulty. We find that the negative client sampling will cause the merged data distribution of currently sampled clients heavily inconsistent with that of all available clients, and further make the aggregated gradient unreliable. To address this issue, we propose a novel learning rate adaptation mechanism to adaptively adjust the server learning rate for the aggregated gradient in each round, according to the consistency between the merged data distribution of currently sampled clients and that of all available clients. Specifically, we make theoretical deductions to find a meaningful and robust indicator that is positively related to the optimal server learning rate and can effectively reflect the merged data distribution of sampled clients, and we utilize it for the server learning rate adaptation. Extensive experiments on multiple image and text classification tasks validate the great effectiveness of our method.
DPFNet: A Dual-branch Dilated Network with Phase-aware Fourier Convolution for Low-light Image Enhancement
Sep 16, 2022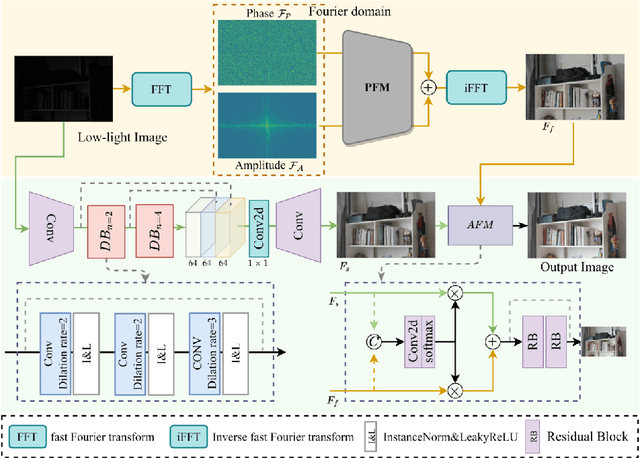
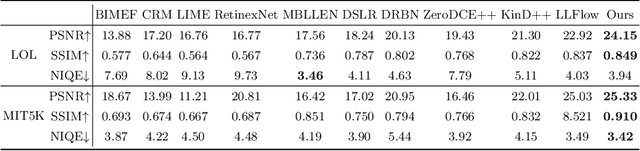
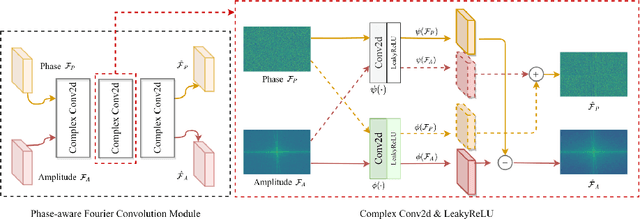
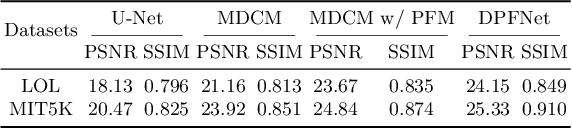
Low-light image enhancement is a classical computer vision problem aiming to recover normal-exposure images from low-light images. However, convolutional neural networks commonly used in this field are good at sampling low-frequency local structural features in the spatial domain, which leads to unclear texture details of the reconstructed images. To alleviate this problem, we propose a novel module using the Fourier coefficients, which can recover high-quality texture details under the constraint of semantics in the frequency phase and supplement the spatial domain. In addition, we design a simple and efficient module for the image spatial domain using dilated convolutions with different receptive fields to alleviate the loss of detail caused by frequent downsampling. We integrate the above parts into an end-to-end dual branch network and design a novel loss committee and an adaptive fusion module to guide the network to flexibly combine spatial and frequency domain features to generate more pleasing visual effects. Finally, we evaluate the proposed network on public benchmarks. Extensive experimental results show that our method outperforms many existing state-of-the-art ones, showing outstanding performance and potential.
Multiscale Metamorphic VAE for 3D Brain MRI Synthesis
Jan 09, 2023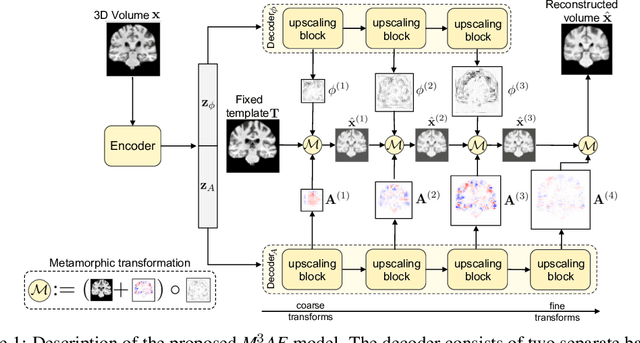
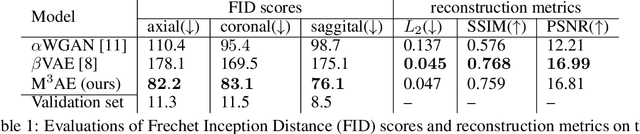
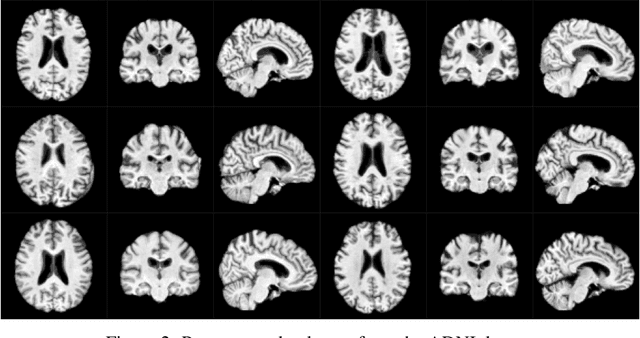
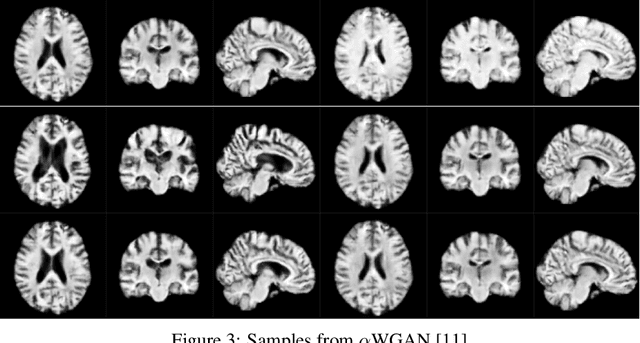
Generative modeling of 3D brain MRIs presents difficulties in achieving high visual fidelity while ensuring sufficient coverage of the data distribution. In this work, we propose to address this challenge with composable, multiscale morphological transformations in a variational autoencoder (VAE) framework. These transformations are applied to a chosen reference brain image to generate MRI volumes, equipping the model with strong anatomical inductive biases. We structure the VAE latent space in a way such that the model covers the data distribution sufficiently well. We show substantial performance improvements in FID while retaining comparable, or superior, reconstruction quality compared to prior work based on VAEs and generative adversarial networks (GANs).
A novel adversarial learning strategy for medical image classification
Jun 26, 2022
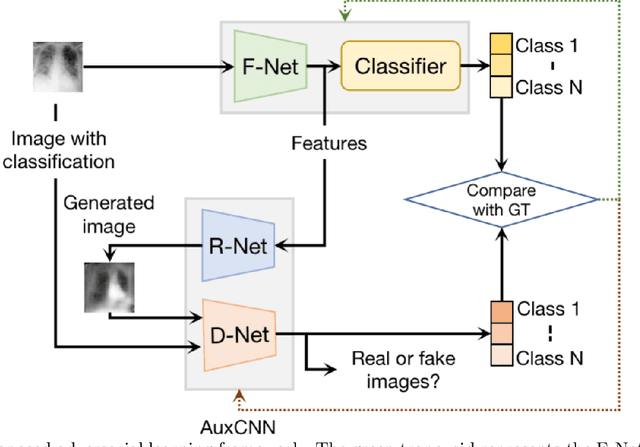
Deep learning (DL) techniques have been extensively utilized for medical image classification. Most DL-based classification networks are generally structured hierarchically and optimized through the minimization of a single loss function measured at the end of the networks. However, such a single loss design could potentially lead to optimization of one specific value of interest but fail to leverage informative features from intermediate layers that might benefit classification performance and reduce the risk of overfitting. Recently, auxiliary convolutional neural networks (AuxCNNs) have been employed on top of traditional classification networks to facilitate the training of intermediate layers to improve classification performance and robustness. In this study, we proposed an adversarial learning-based AuxCNN to support the training of deep neural networks for medical image classification. Two main innovations were adopted in our AuxCNN classification framework. First, the proposed AuxCNN architecture includes an image generator and an image discriminator for extracting more informative image features for medical image classification, motivated by the concept of generative adversarial network (GAN) and its impressive ability in approximating target data distribution. Second, a hybrid loss function is designed to guide the model training by incorporating different objectives of the classification network and AuxCNN to reduce overfitting. Comprehensive experimental studies demonstrated the superior classification performance of the proposed model. The effect of the network-related factors on classification performance was investigated.
An automated, geometry-based method for the analysis of hippocampal thickness
Feb 01, 2023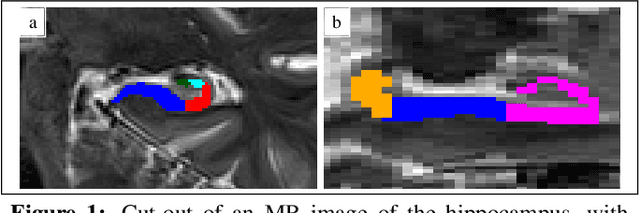
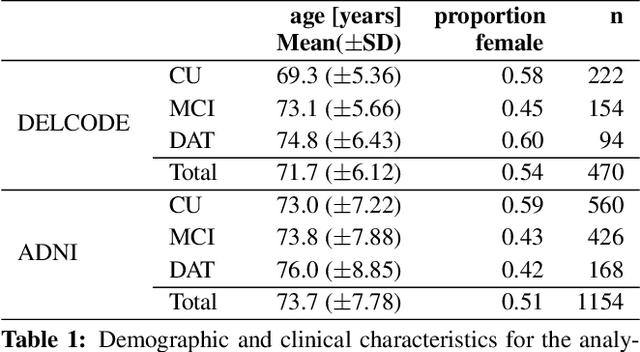
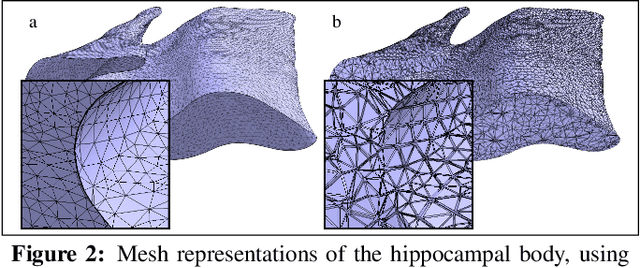
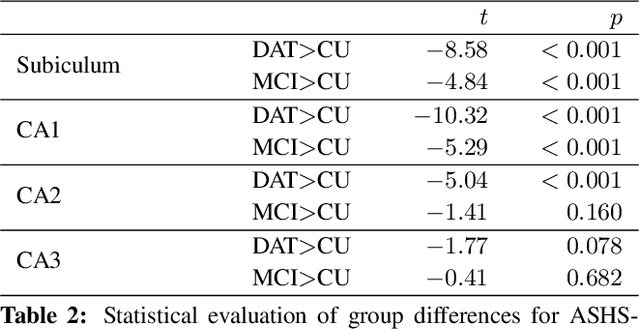
The hippocampus is one of the most studied neuroanatomical structures due to its involvement in attention, learning, and memory as well as its atrophy in ageing, neurological, and psychiatric diseases. Hippocampal shape changes, however, are complex and cannot be fully characterized by a single summary metric such as hippocampal volume as determined from MR images. In this work, we propose an automated, geometry-based approach for the unfolding, point-wise correspondence, and local analysis of hippocampal shape features such as thickness and curvature. Starting from an automated segmentation of hippocampal subfields, we create a 3D tetrahedral mesh model as well as a 3D intrinsic coordinate system of the hippocampal body. From this coordinate system, we derive local curvature and thickness estimates as well as a 2D sheet for hippocampal unfolding. We evaluate the performance of our algorithm with a series of experiments to quantify neurodegenerative changes in Mild Cognitive Impairment and Alzheimer's disease dementia. We find that hippocampal thickness estimates detect known differences between clinical groups and can determine the location of these effects on the hippocampal sheet. Further, thickness estimates improve classification of clinical groups and cognitively unimpaired controls when added as an additional predictor. Comparable results are obtained with different datasets and segmentation algorithms. Taken together, we replicate canonical findings on hippocampal volume/shape changes in dementia, extend them by gaining insight into their spatial localization on the hippocampal sheet, and provide additional, complementary information beyond traditional measures. We provide a new set of sensitive processing and analysis tools for the analysis of hippocampal geometry that allows comparisons across studies without relying on image registration or requiring manual intervention.